
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构)
Flink1.17实战教程(第二篇:DataStream API)
Flink1.17实战教程(第三篇:时间和窗口)
Flink1.17实战教程(第四篇:处理函数)
Flink1.17实战教程(第五篇:状态管理)
Flink1.17实战教程(第六篇:容错机制)
Flink1.17实战教程(第七篇:Flink SQL)
文章目录
- 系列文章目录
- 1. 检查点(Checkpoint)
-
- 1.1 检查点的保存
- 1.2 从检查点恢复状态
- 1.3 检查点算法
-
- 1.3.1 检查点分界线(Barrier)
- 1.3.2 分布式快照算法(Barrier对齐的精准一次)
- 1.3.3 分布式快照算法(Barrier对齐的至少一次)
- 1.3.4 分布式快照算法(非Barrier对齐的精准一次)
- 1.4 检查点配置
-
- 1.4.1 启用检查点
- 1.4.2 检查点存储
- 1.4.3 其它高级配置
- 1.4.4 通用增量 checkpoint (changelog)
- 1.4.5 最终检查点
- 1.5 保存点(Savepoint)
-
- 1.5.1 保存点的用途
- 1.5.2 使用保存点
- 1.5.3 使用保存点切换状态后端
- 2. 状态一致性
-
- 2.1 一致性的概念和级别
- 2.2 端到端的状态一致性
- 3. 端到端精确一次(End-To-End Exactly-Once)
-
- 3.1 输入端保证
- 3.2 输出端保证
- 3.3 Flink和Kafka连接时的精确一次保证
1. 检查点(Checkpoint)
在Flink中,有一套完整的容错机制来保证故障后的恢复,其中最重要的就是检查点。
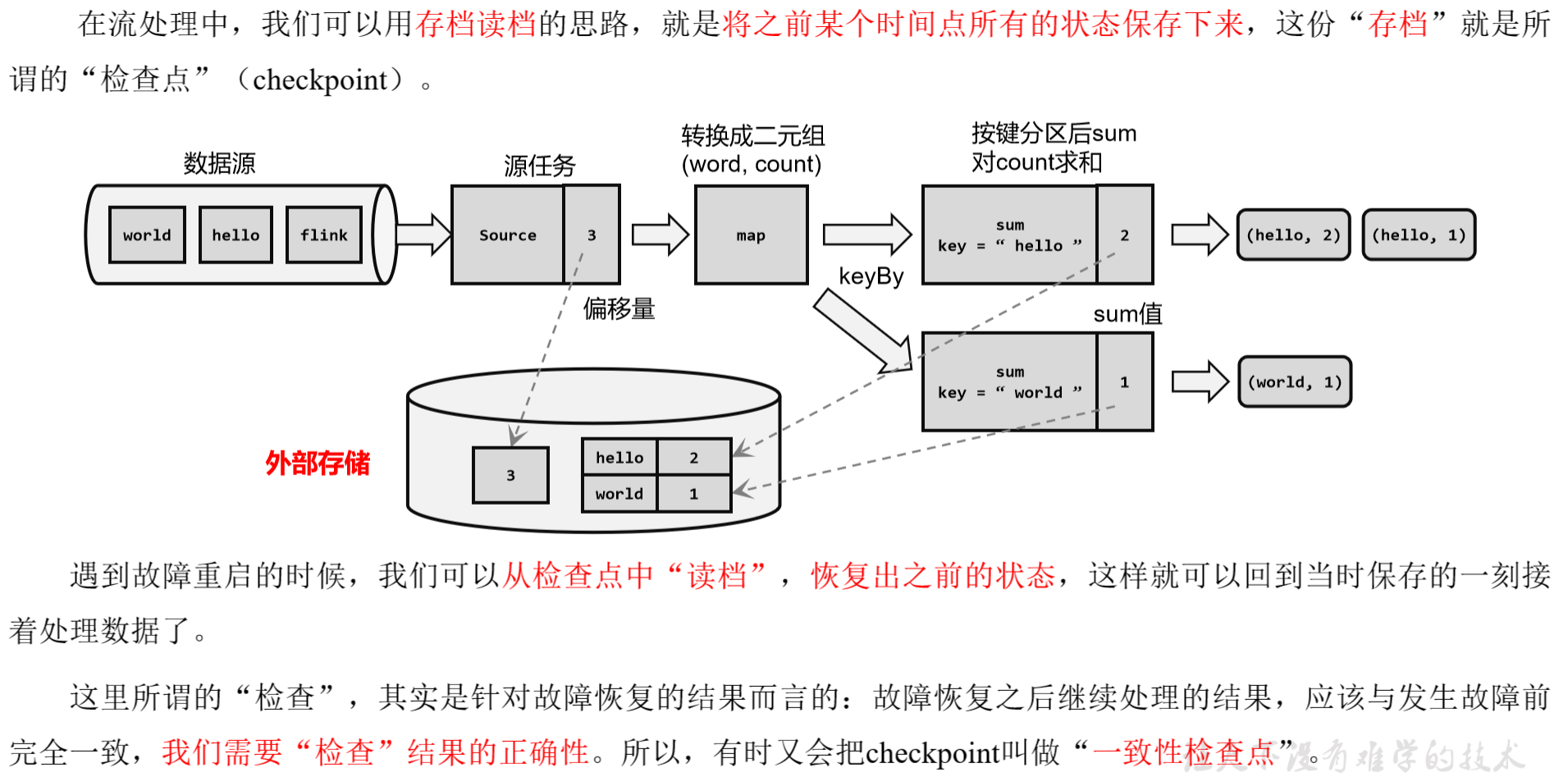
1.1 检查点的保存
1)周期性的触发保存
“随时存档”确实恢复起来方便,可是需要我们不停地做存档操作。如果每处理一条数据就进行检查点的保存,当大量数据同时到来时,就会耗费很多资源来频繁做检查点,数据处理的速度就会受到影响。所以在Flink中,检查点的保存是周期性触发的,间隔时间可以进服务器托管网行设置。
2)保存的时间点
我们应该在所有任务(算子)都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。
这样做可以实现一个数据被所有任务(算子)完整地处理完,状态得到了保存。
如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理;我们只需要让源(source)任务向数据源重新提交偏移量、请求重放数据就可以了。当然这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量;kafka就是满足这些要求的一个最好的例子。
3)保存的具体流程
检查点的保存,最关键的就是要等所有任务将“同一个数据”处理完毕。下面我们通过一个具体的例子,来详细描述一下检查点具体的保存过程。
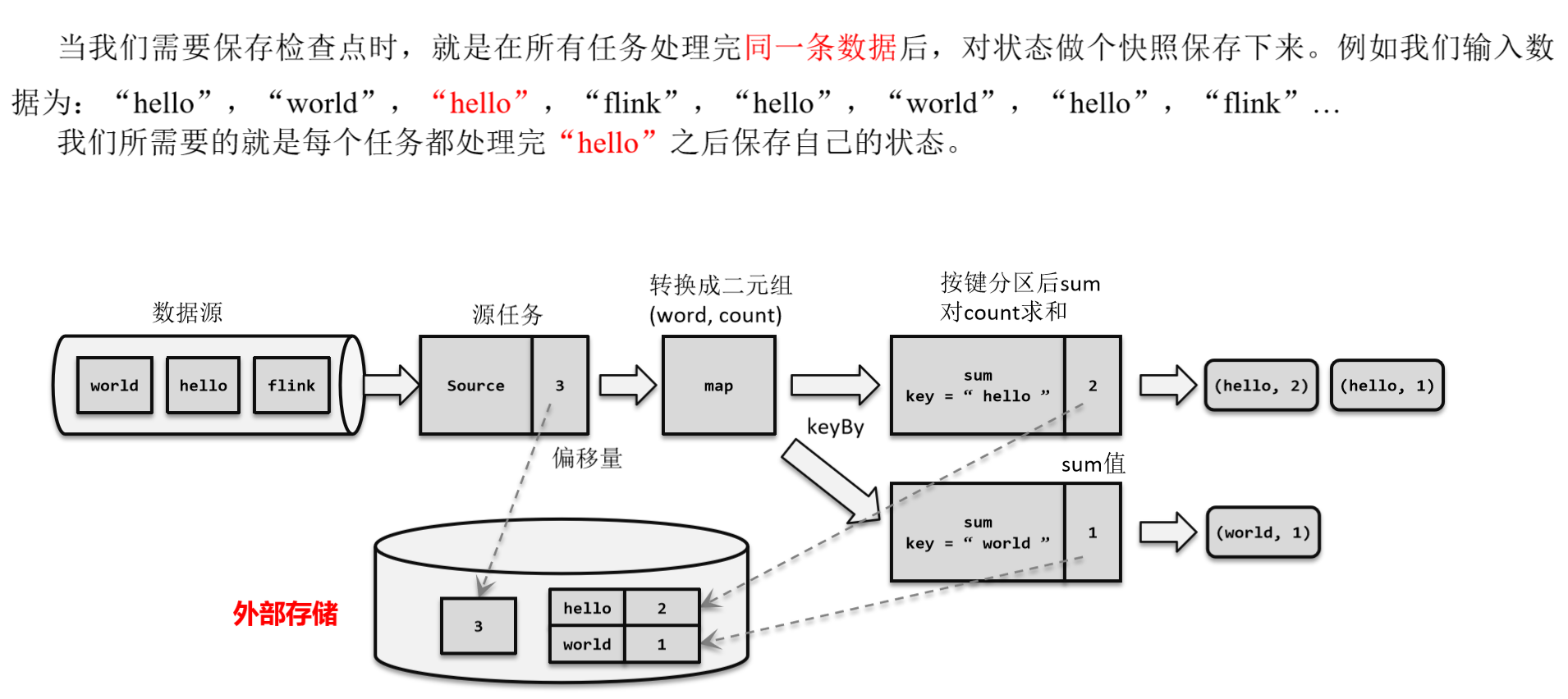
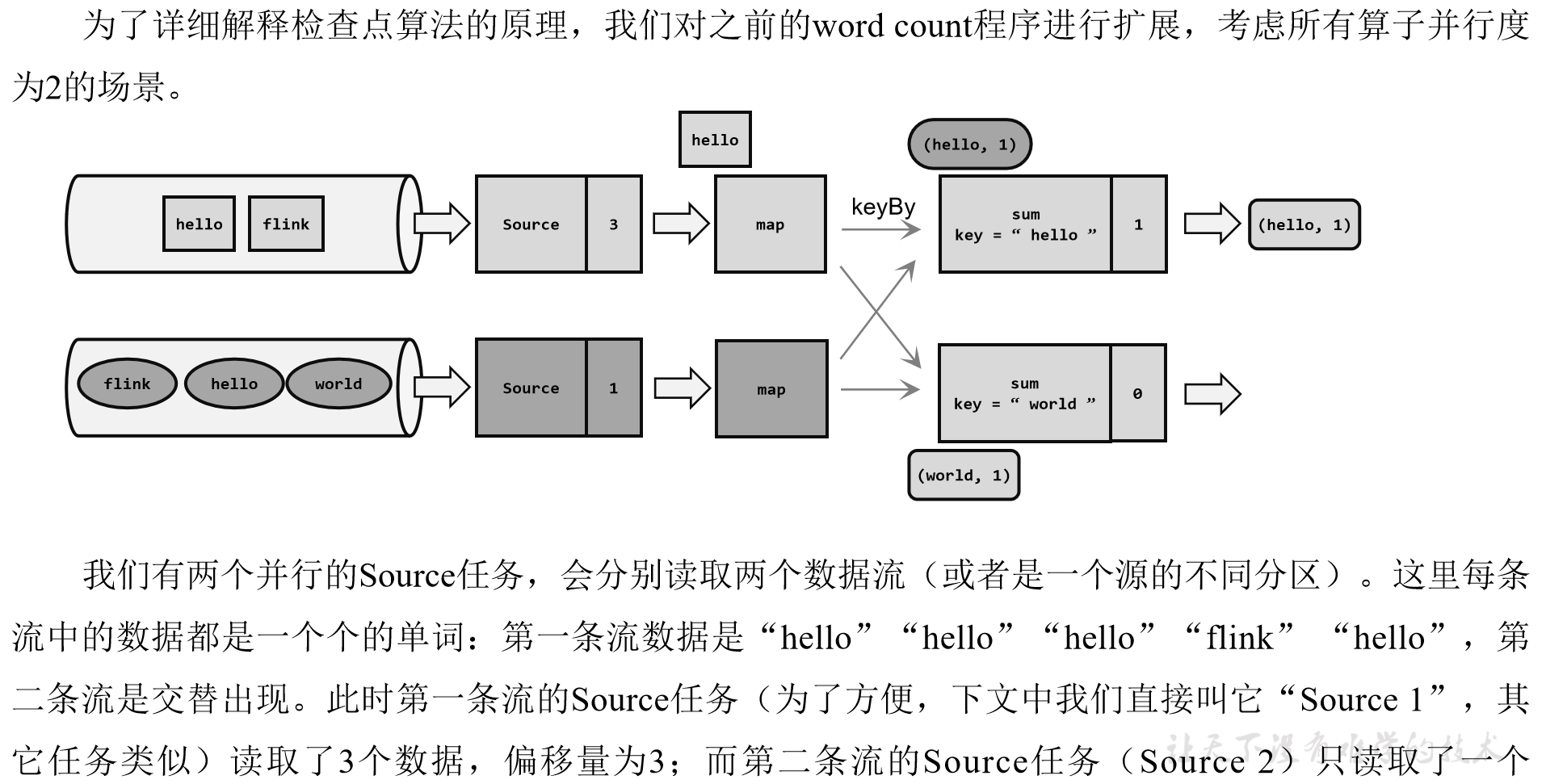
回忆一下我们最初实现的统计词频的程序——word count。这里为了方便,我们直接从数据源读入已经分开的一个个单词,例如这里输入的是:
“hello”,“world”,“hello”,“flink”,“hello”,“world”,“hello”,“flink”…
我们所需要的就是每个任务都处理完“hello”之后保存自己的状态。
1.2 从检查点恢复状态
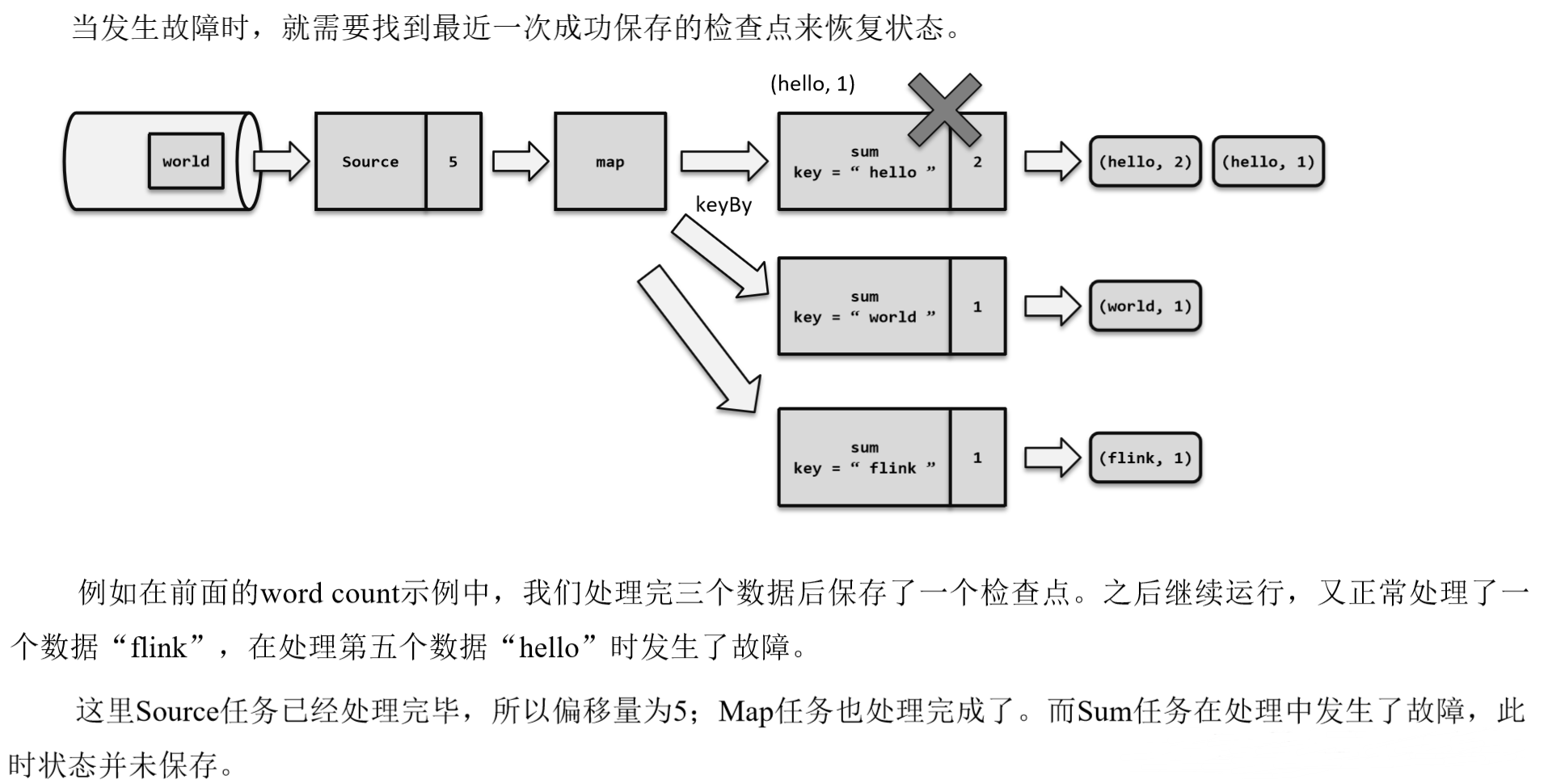
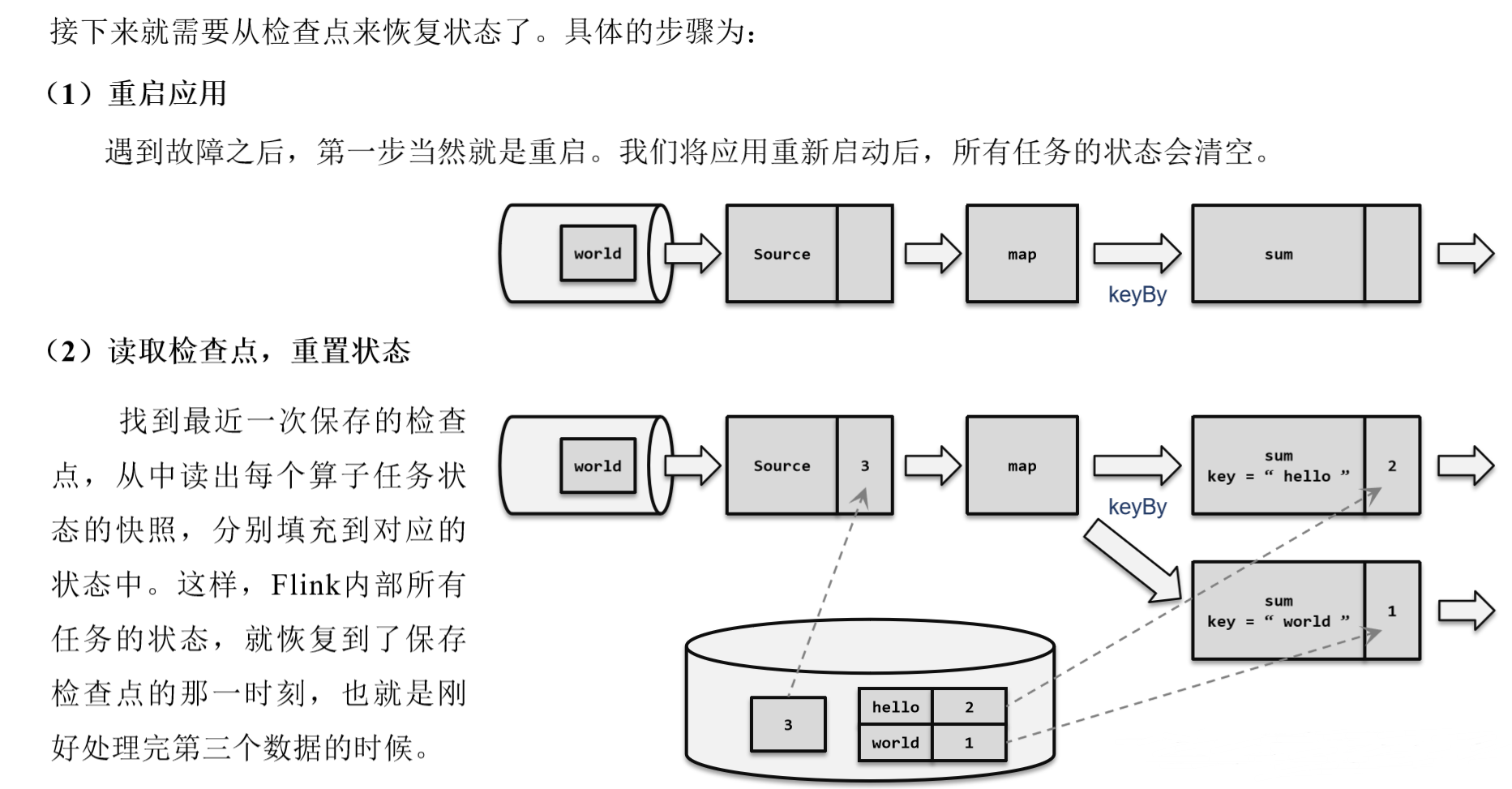
检查点的保存具体流程:
处理数据过程发生故障
重启应用 ==>> 读取检查点,重置状态
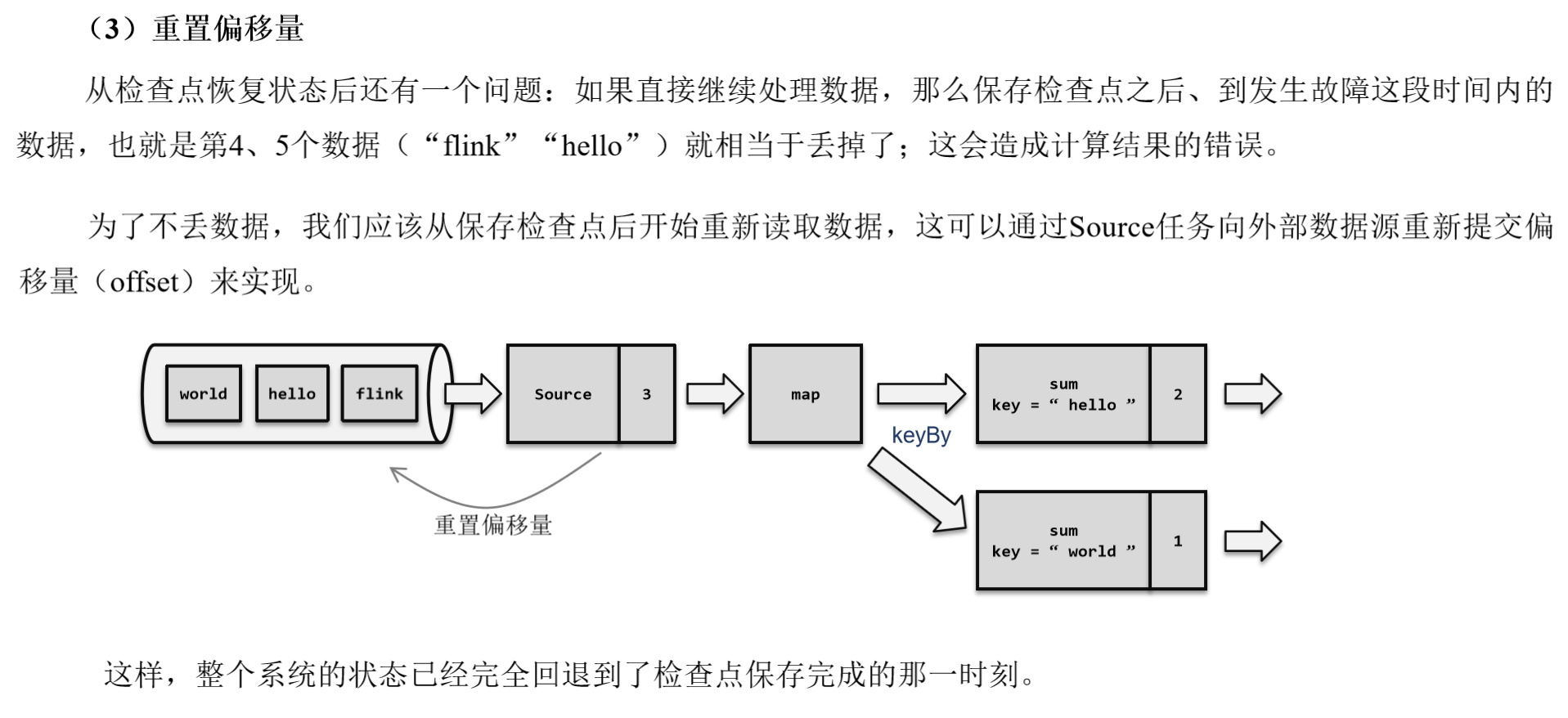
重置偏移量
继续处理数据
1.3 检查点算法
在Flink中,采用了基于Chandy-Lamport算法的分布式快照,可以在不暂停整体流处理的前提下,将状态备份保存到检查点。
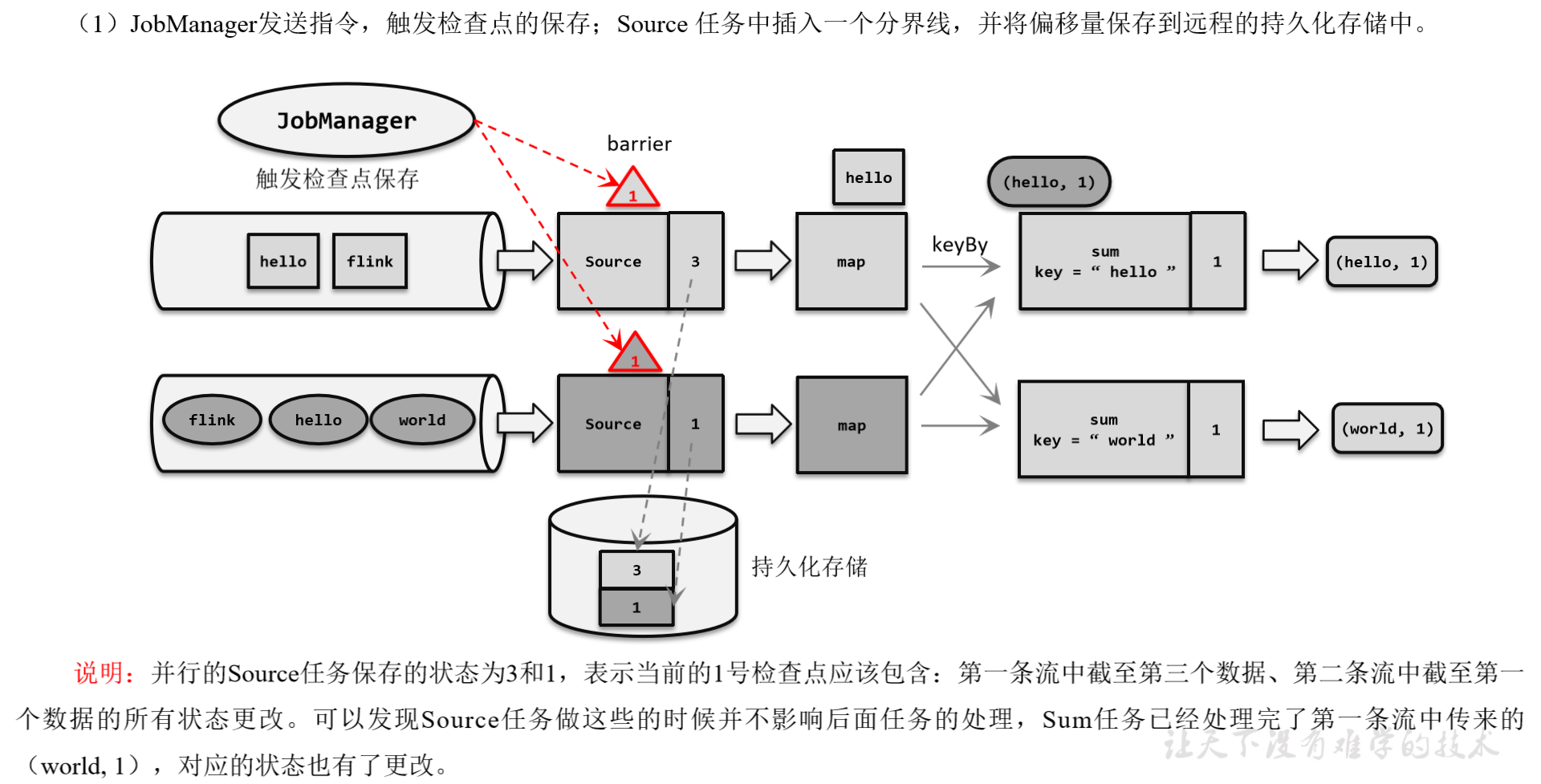
1.3.1 检查点分界线(Barrier)
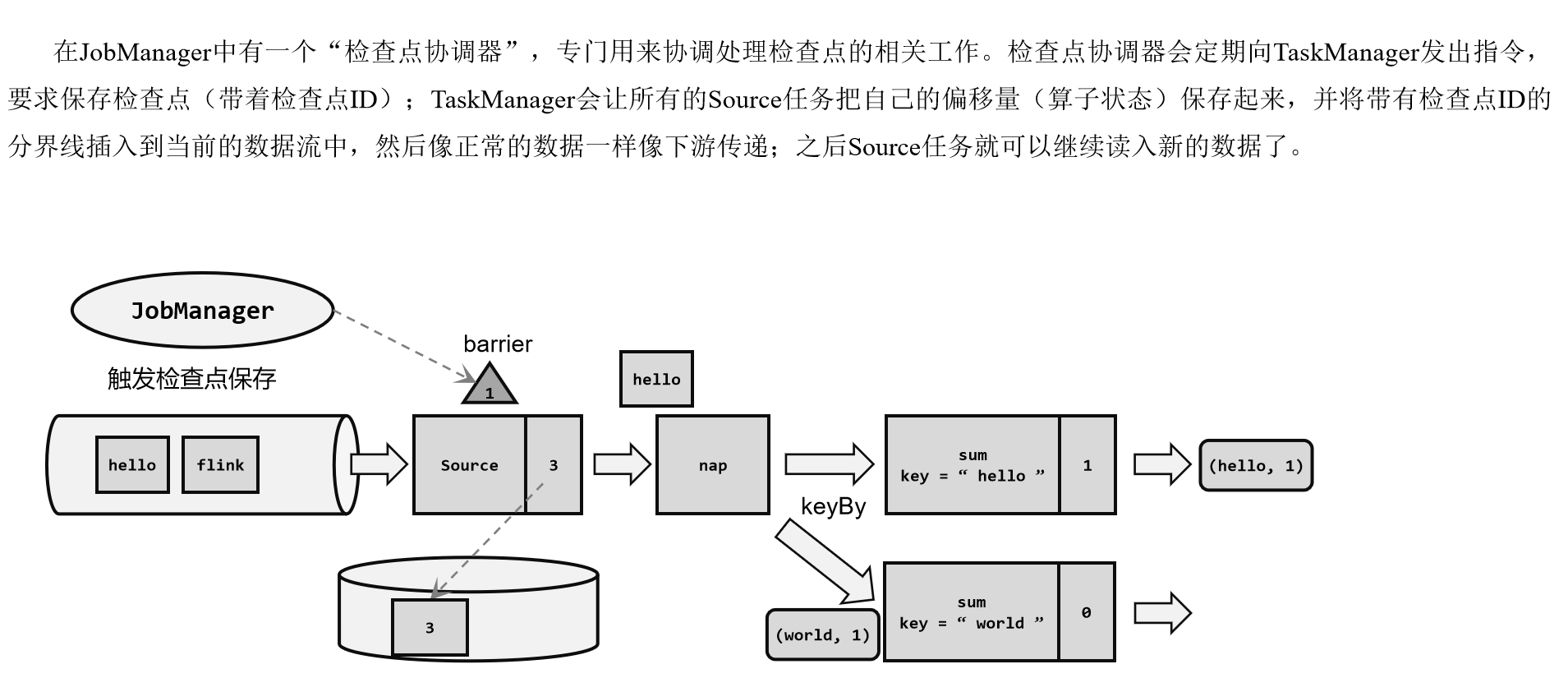
借鉴水位线的设计,在数据流中插入一个特殊的数据结构,专门用来表示触发检查点保存的时间点。收到保存检查点的指令后,Source任务可以在当前数据流中插入这个结构;之后的所有任务只要遇到它就开始对状态做持久化快照保存。由于数据流是保持顺序依次处理的,因此遇到这个标识就代表之前的数据都处理完了,可以保存一个检查点;而在它之后的数据,引起的状态改变就不会体现在这个检查点中,而需要保存到下一个检查点。
这种特殊的数据形式,把一条流上的数据按照不同的检查点分隔开,所以就叫做检查点的“分界线”(Checkpoint Barrier)。
1.3.2 分布式快照算法(Barrier对齐的精准一次)
watermark指示的是“之前的数据全部到齐了”,而barrier服务器托管网指示的是“之前所有数据的状态更改保存入当前检查点”:它们都是一个“截止时间”的标志。所以在处理多个分区的传递时,也要以是否还会有数据到来作为一个判断标准。
具体实现上,Flink使用了Chandy-Lamport算法的一种变体,被称为“异步分界线快照”算法。算法的核心就是两个原则:
当上游任务向多个并行下游任务发送barrier时,需要广播出去;
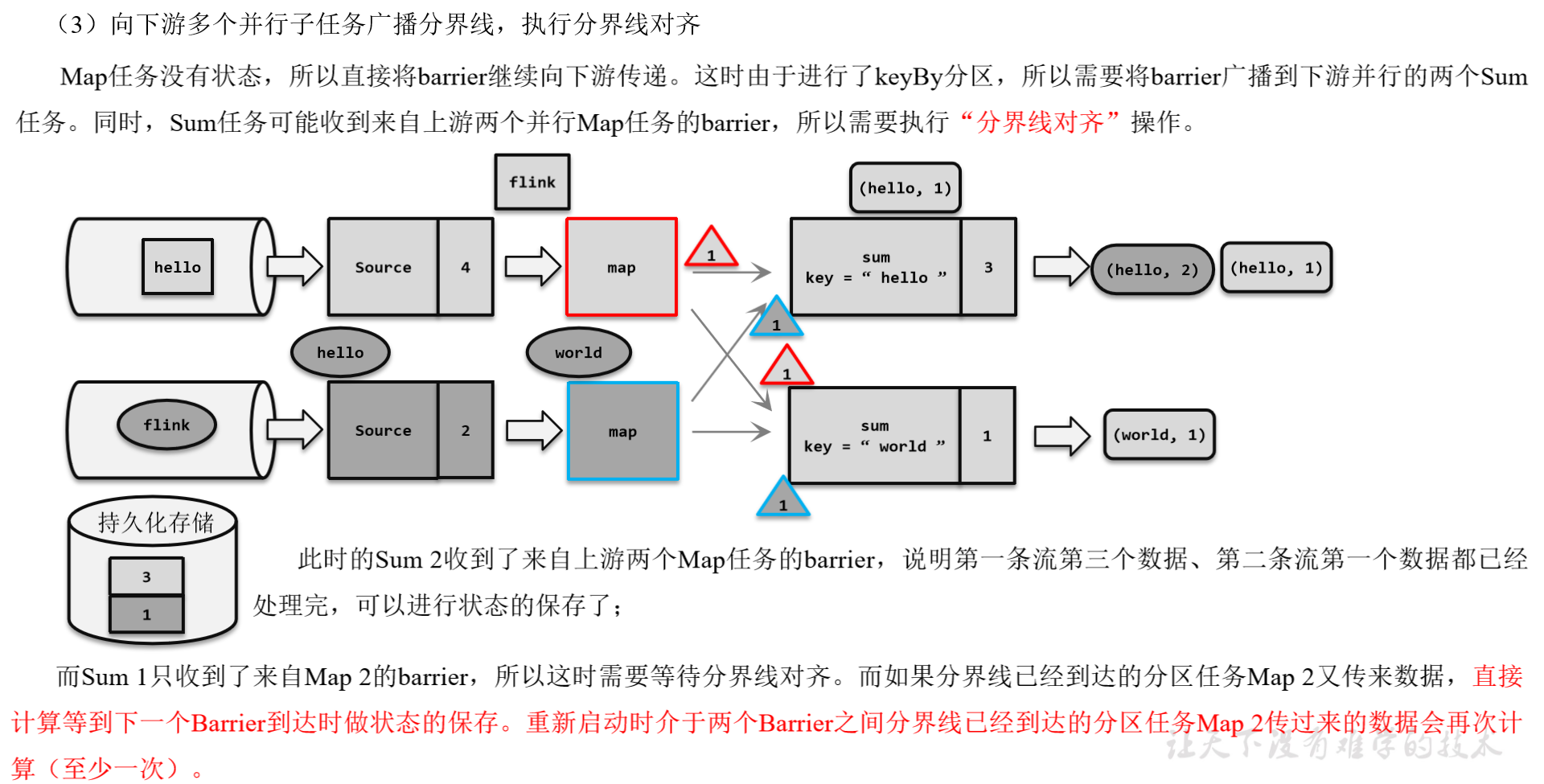
而当多个上游任务向同一个下游任务传递分界线时,需要在下游任务执行“分界线对齐”操作,也就是需要等到所有并行分区的barrier都到齐,才可以开始状态的保存。
1)场景说明
2)检查点保存算法具体过程为:
1.触发检查点保存
2.分界线向下游传递
3.分界线对齐
4.有状态算子将状态保存至持久化存储
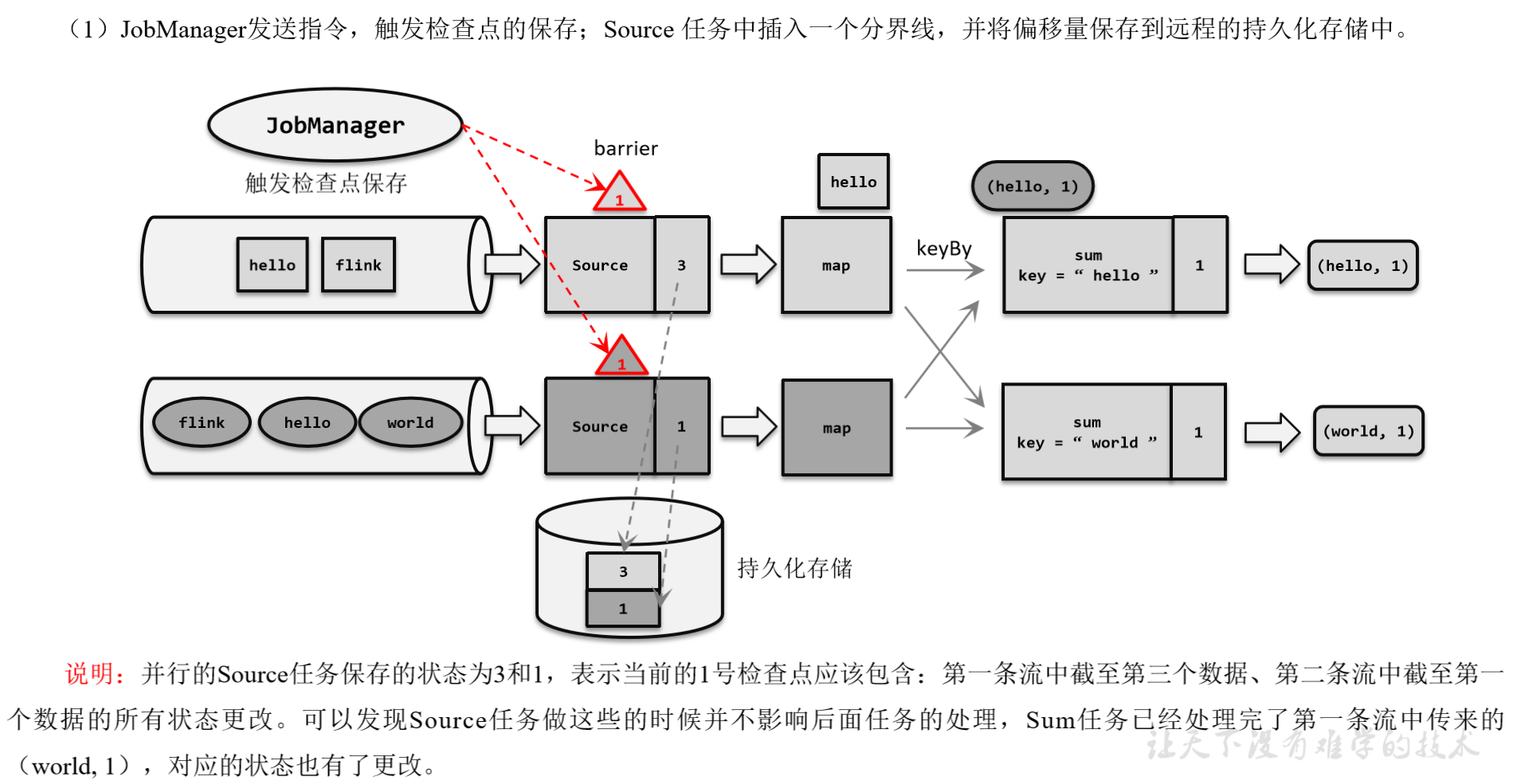
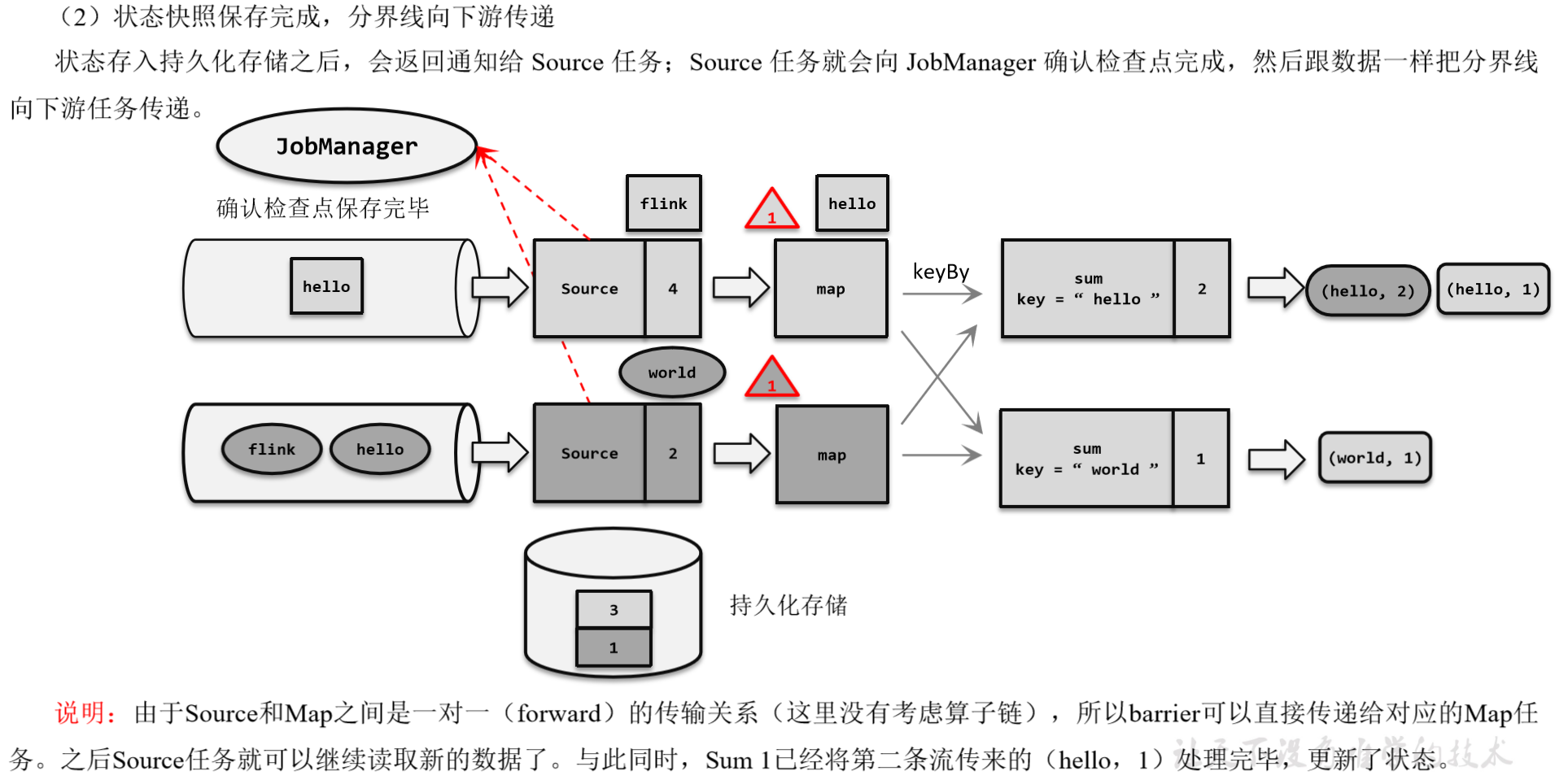
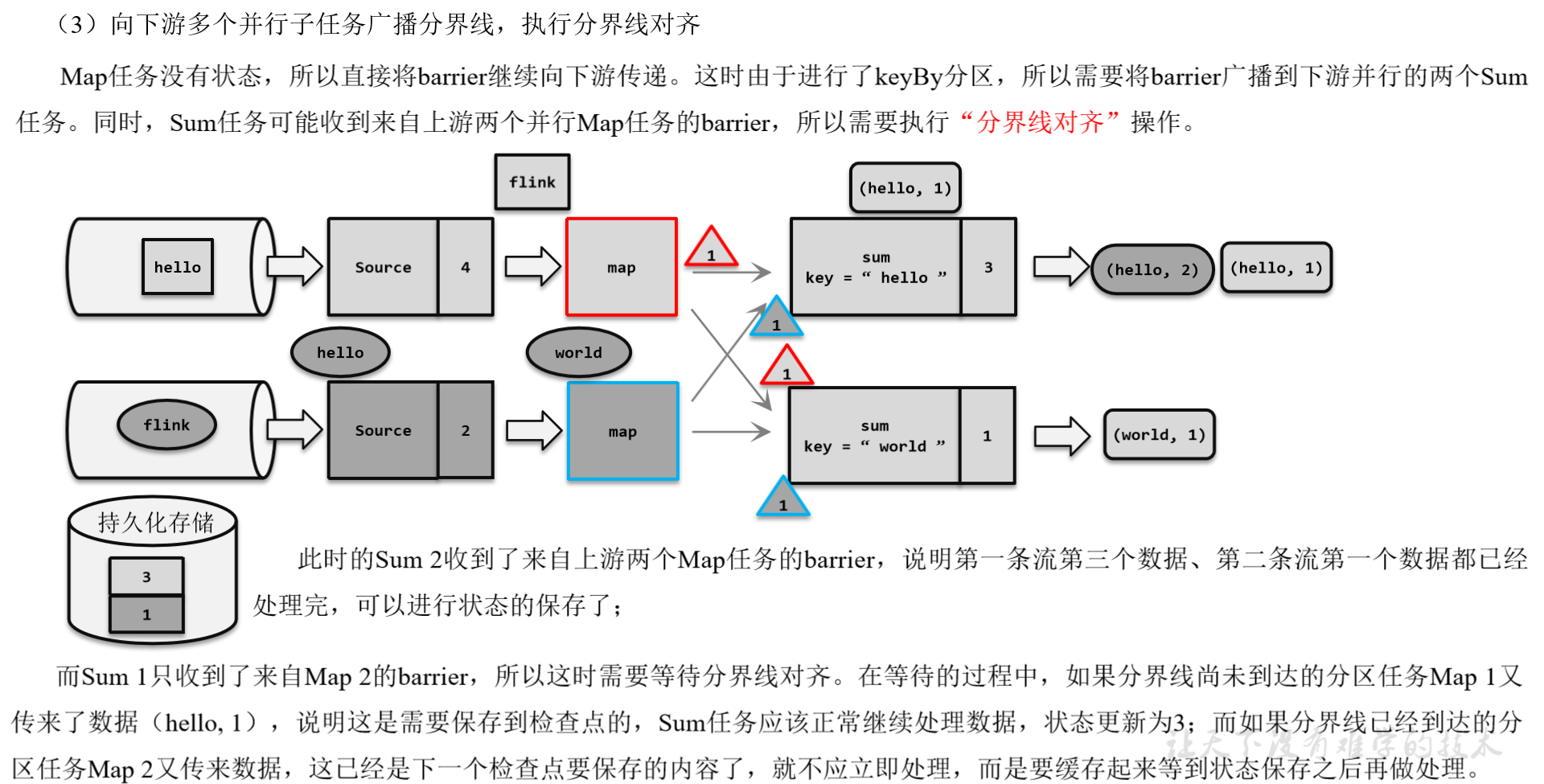
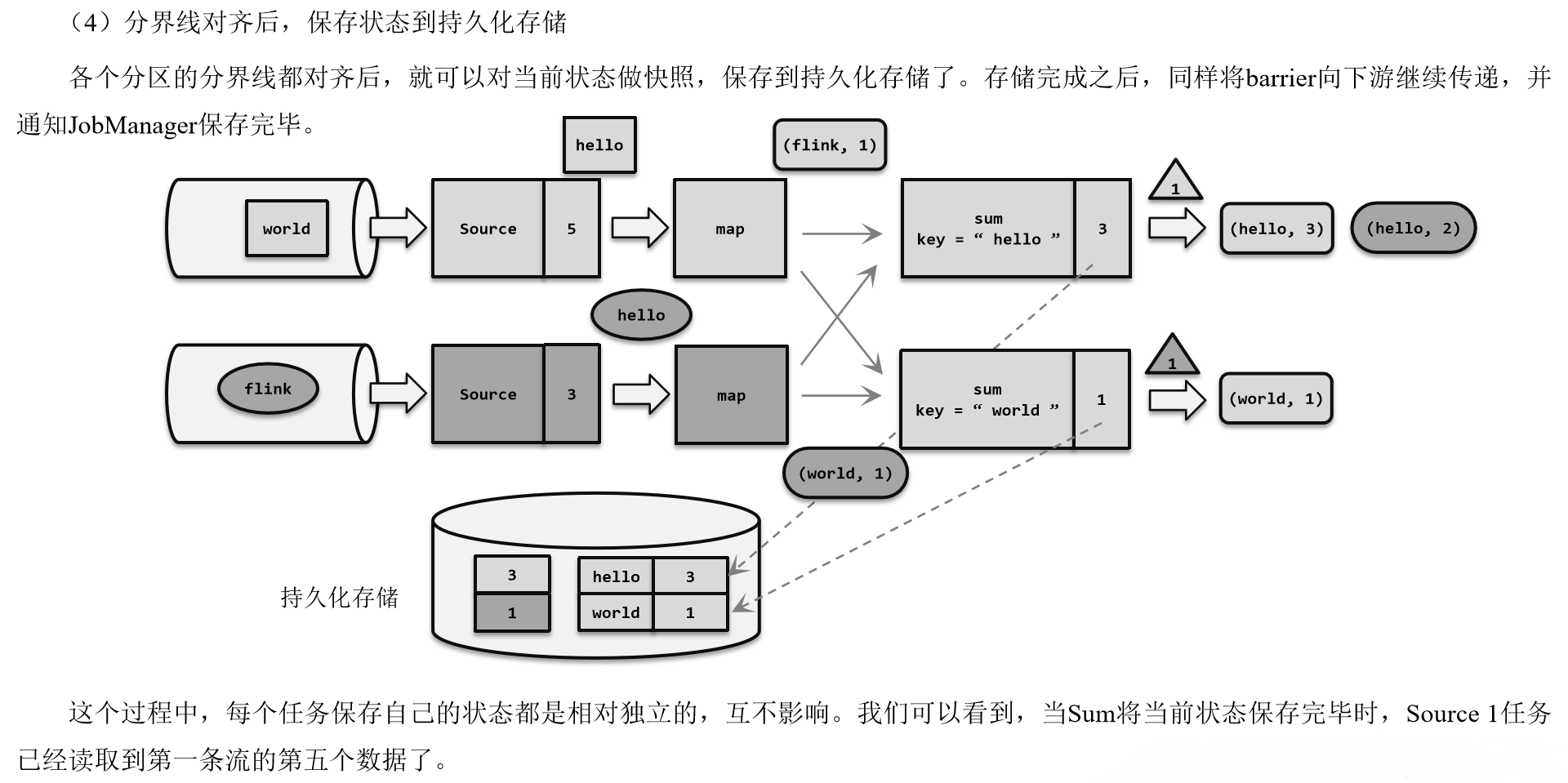
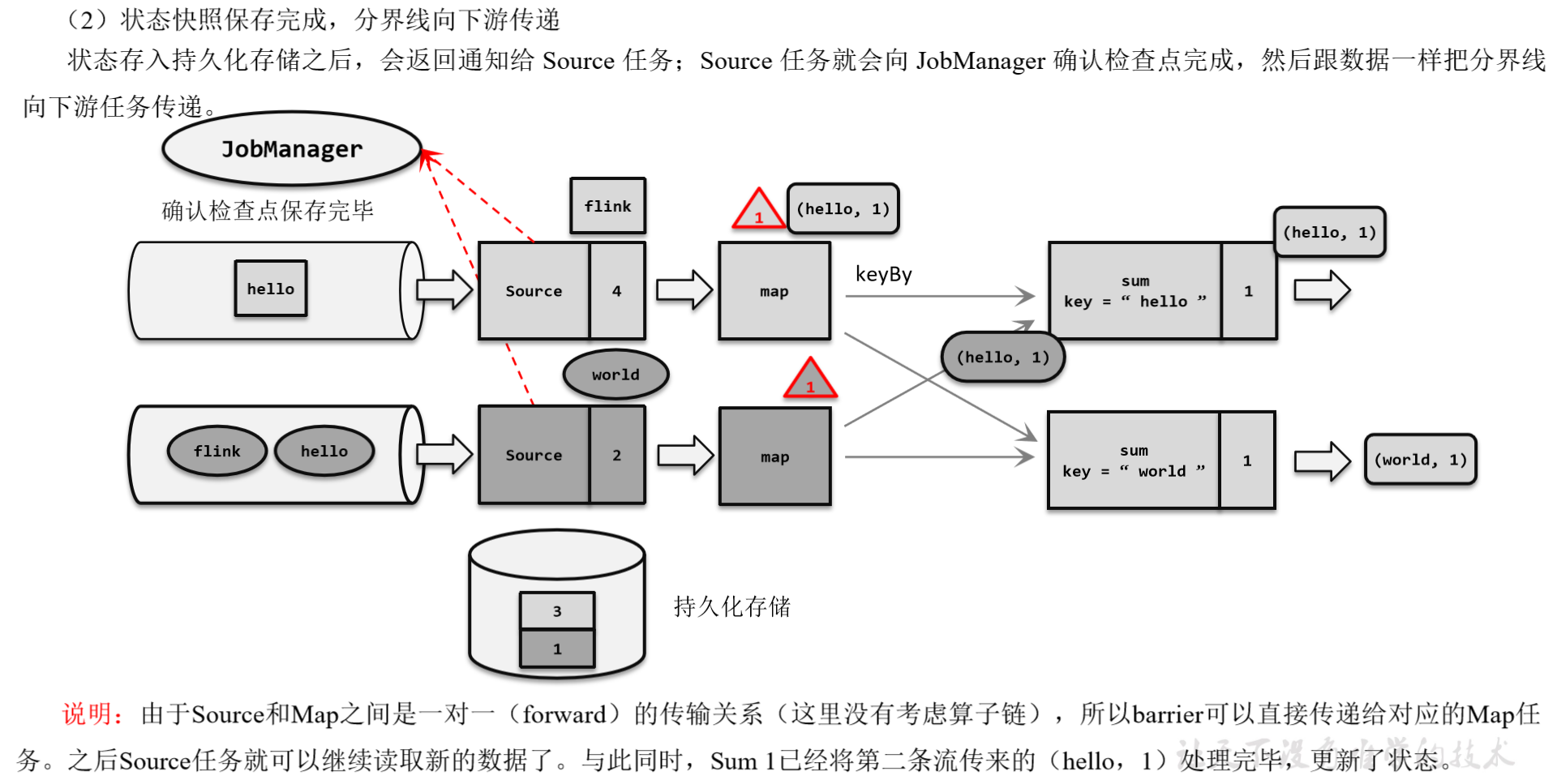
(1)触发检查点:JobManager向Source发送Barrier;
(2)Barrier发送:向下游广播发送;
(3)Barrier对齐:下游需要收到上游所有并行度传递过来的Barrier才做自身状态的保存;
(4)状态保存:有状态的算子将状态保存至持久化。
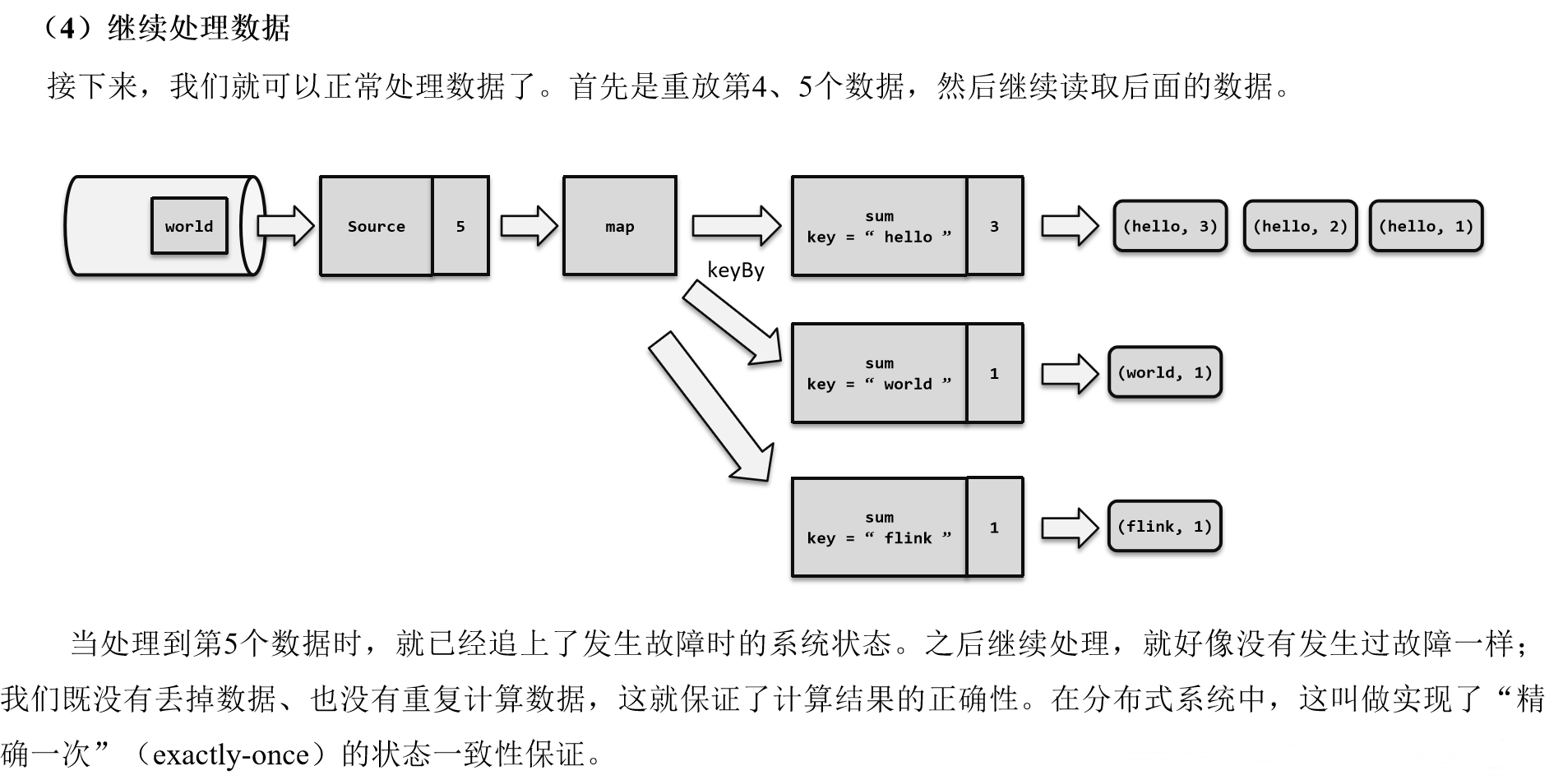
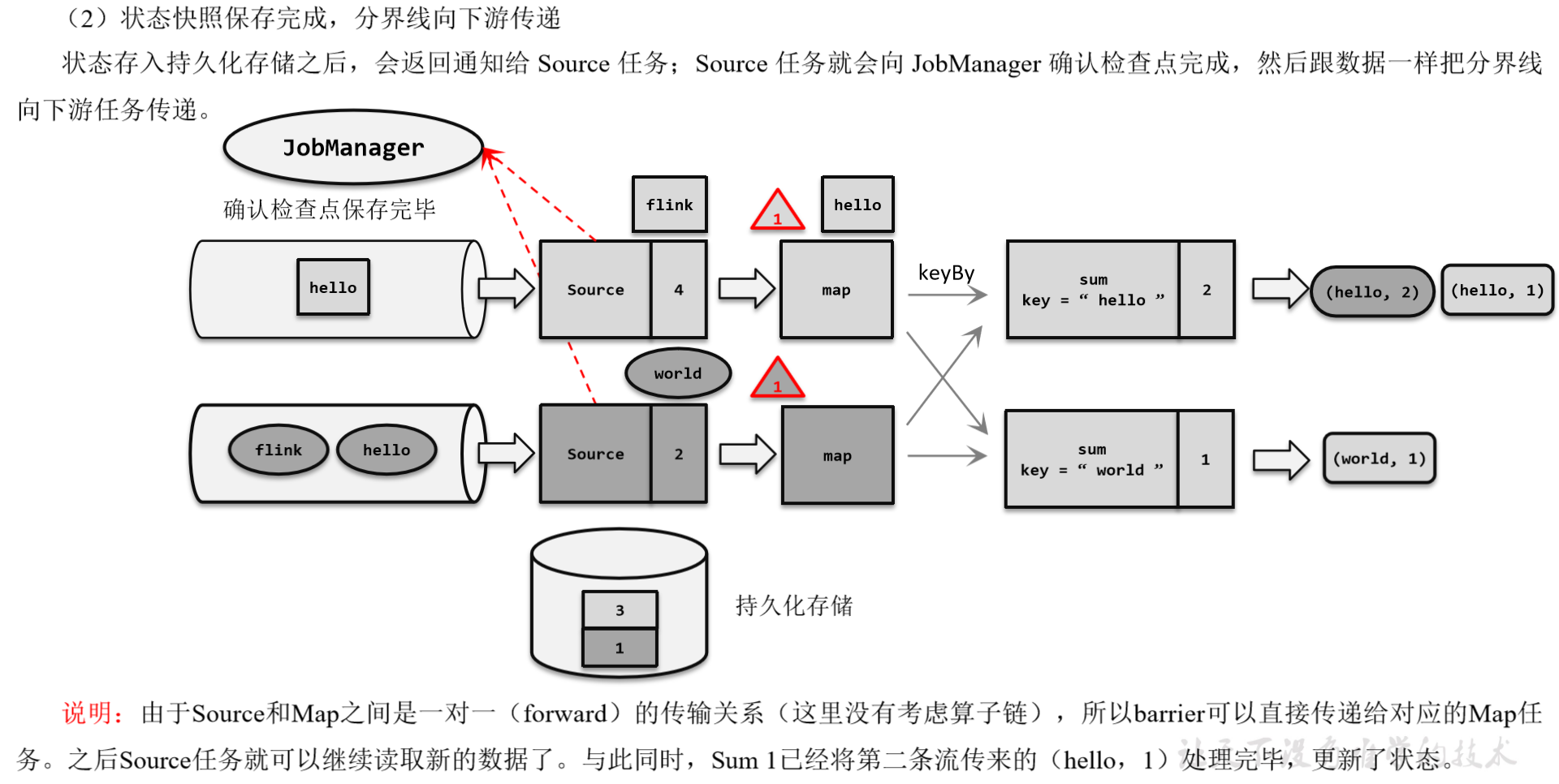
(5)先处理缓存数据,然后正常继续处理
完成检查点保存之后,任务就可以继续正常处理数据了。这时如果有等待分界线对齐时缓存的数据,需要先做处理;然后再按照顺序依次处理新到的数据。当JobManager收到所有任务成功保存状态的信息,就可以确认当前检查点成功保存。之后遇到故障就可以从这里恢复了。
(补充)由于分界线对齐要求先到达的分区做缓存等待,一定程度上会影响处理的速度;当出现背压时,下游任务会堆积大量的缓冲数据,检查点可能需要很久才可以保存完毕。
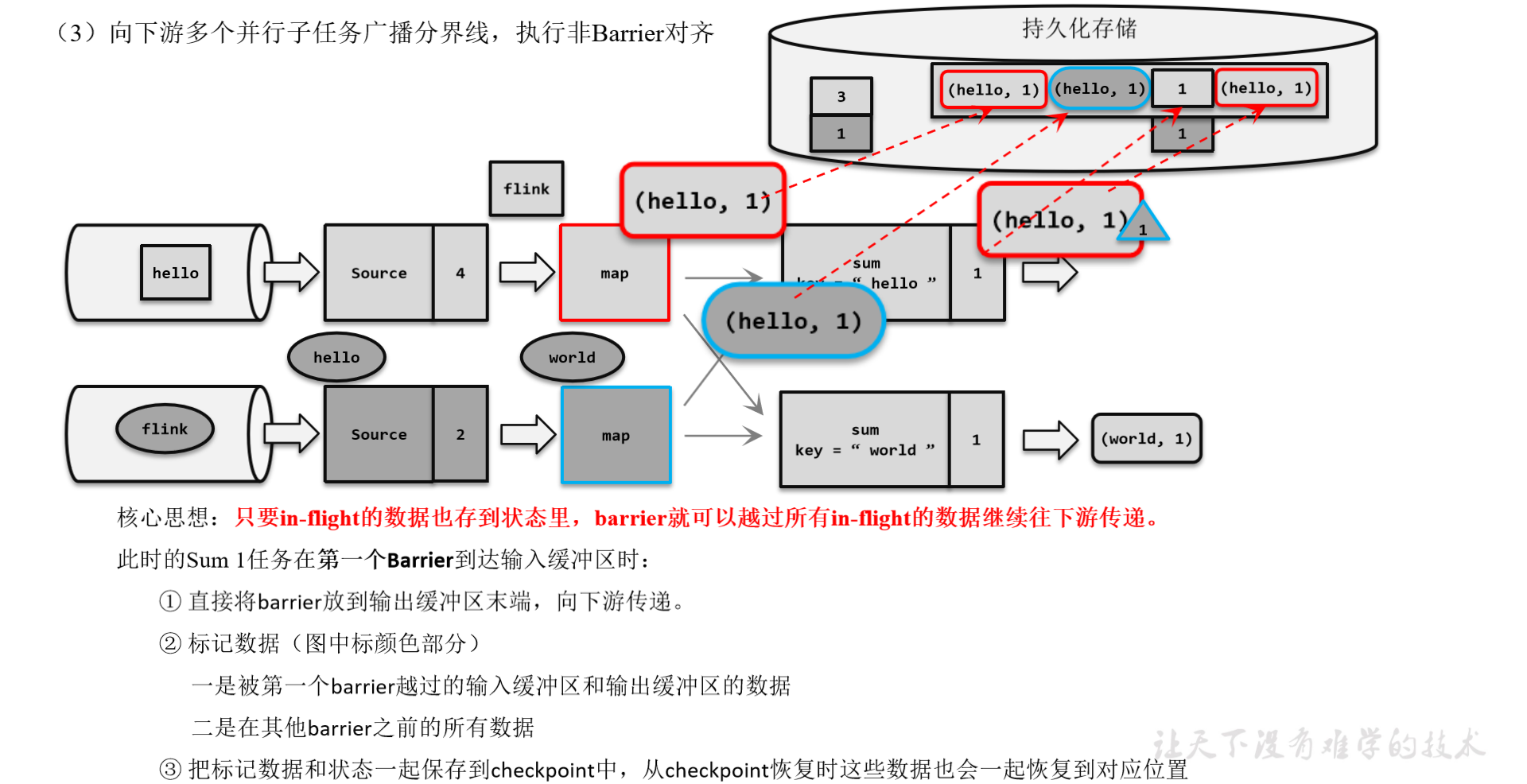
为了应对这种场景,Barrier对齐中提供了至少一次语义以及Flink 1.11之后提供了不对齐的检查点保存方式,可以将未处理的缓冲数据也保存进检查点。这样,当我们遇到一个分区barrier时就不需等待对齐,而是可以直接启动状态的保存了。
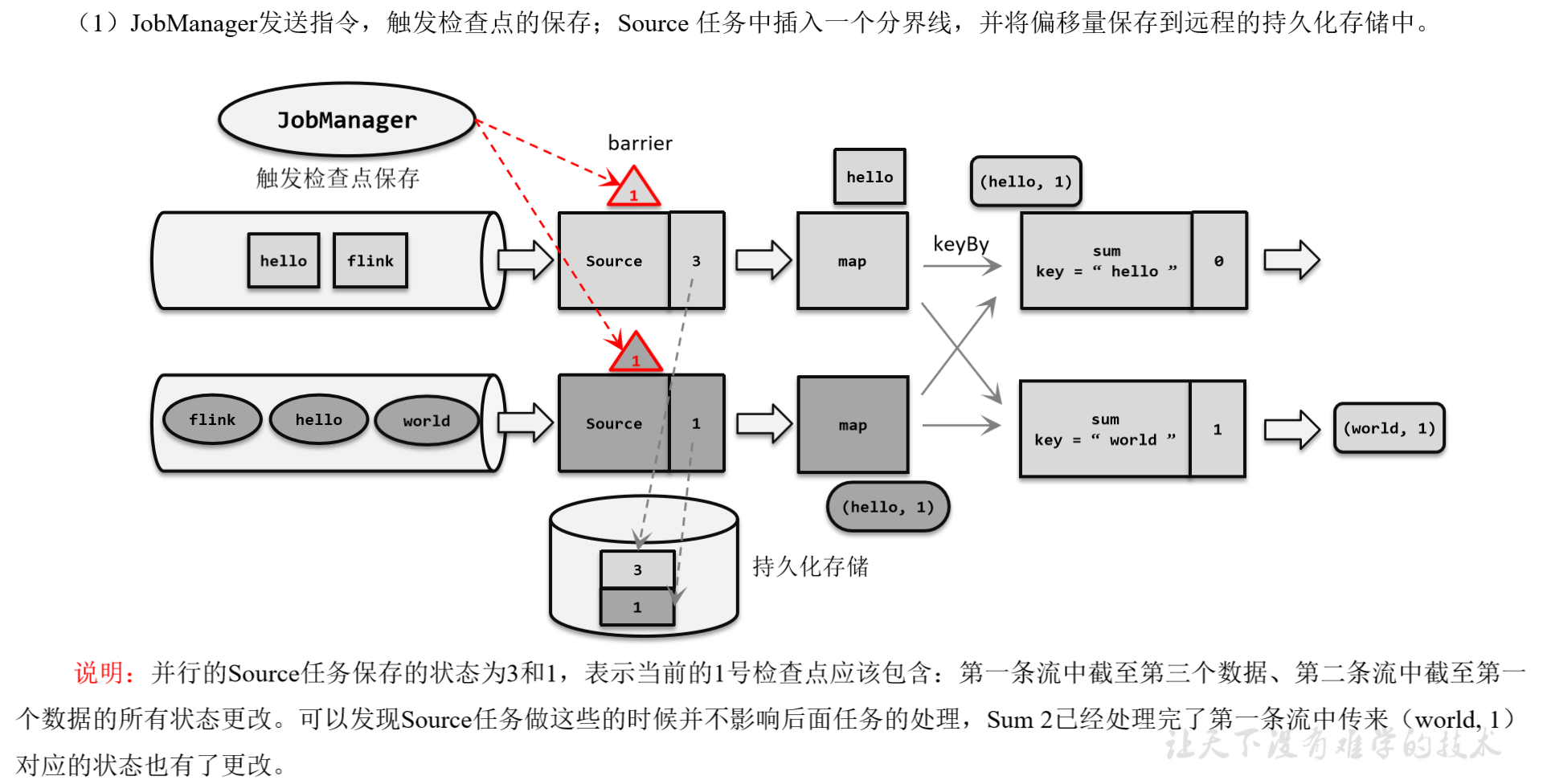
1.3.3 分布式快照算法(Barrier对齐的至少一次)
1.触发检查点保存
2.分界线向下游传递
3.分界线对齐
4.有状态算子将状态保存至持久化存储

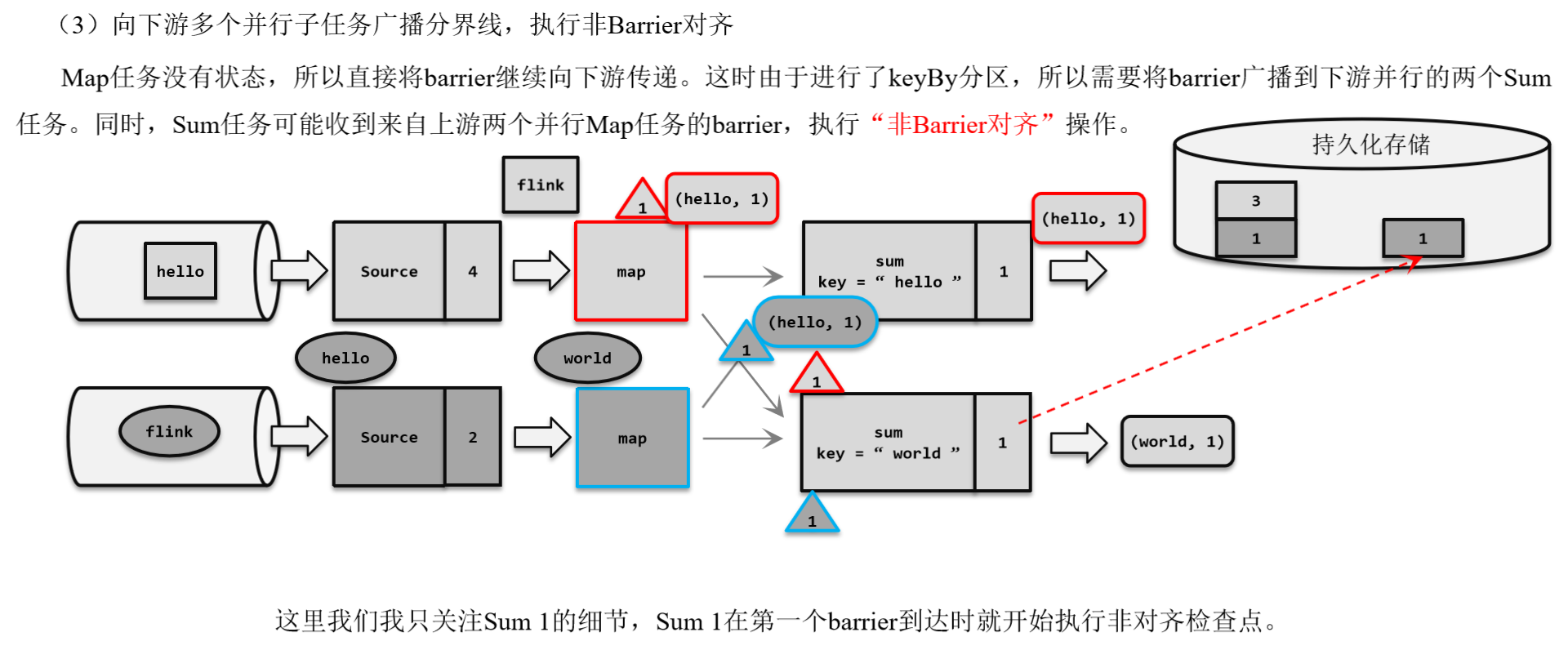
1.3.4 分布式快照算法(非Barrier对齐的精准一次)
1.触发检查点保存
2.分界线向下游传递
3.非Barrier对齐
1.4 检查点配置
检查点的作用是为了故障恢复,我们不能因为保存检查点占据了大量时间、导致数据处理性能明显降低。为了兼顾容错性和处理性能,我们可以在代码中对检查点进行各种配置。
1.4.1 启用检查点
默认情况下,Flink程序是禁用检查点的。如果想要为Flink应用开启自动保存快照的功能,需要在代码中显式地调用执行环境的.enableCheckpointing()方法:
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 每隔1秒启动一次检查点保存
env.enableCheckpointing(1000);
这里需要传入一个长整型的毫秒数,表示周期性保存检查点的间隔时间。如果不传参数直接启用检查点,默认的间隔周期为500毫秒,这种方式已经被弃用。
检查点的间隔时间是对处理性能和故障恢复速度的一个权衡。如果我们希望对性能的影响更小,可以调大间隔时间;而如果希望故障重启后迅速赶上实时的数据处理,就需要将间隔时间设小一些。
1.4.2 检查点存储
检查点具体的持久化存储位置,取决于“检查点存储”的设置。默认情况下,检查点存储在JobManager的堆内存中。而对于大状态的持久化保存,Flink也提供了在其他存储位置进行保存的接口。
具体可以通过调用检查点配置的.setCheckpointStorage()来配置,需要传入一个CheckpointStorage的实现类。Flink主要提供了两种CheckpointStorage:作业管理器的堆内存和文件系统。
// 配置存储检查点到JobManager堆内存
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());
// 配置存储检查点到文件系统
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://namenode:40010/flink/checkpoints"));
对于实际生产应用,我们一般会将CheckpointStorage配置为高可用的分布式文件系统(HDFS,S3等)。
1.4.3 其它高级配置
检查点还有很多可以配置的选项,可以通过获取检查点配置(CheckpointConfig)来进行设置。
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
1)常用高级配置
- 检查点模式(CheckpointingMode)
设置检查点一致性的保证级别,有“精确一次”(exactly-once)和“至少一次”(at-least-once)两个选项。默认级别为exactly-once,而对于大多数低延迟的流处理程序,at-least-once就够用了,而且处理效率会更高。 - 超时时间(checkpointTimeout)
用于指定检查点保存的超时时间,超时没完成就会被丢弃掉。传入一个长整型毫秒数作为参数,表示超时时间。 - 最小间隔时间(minPauseBetweenCheckpoints)
用于指定在上一个检查点完成之后,检查点协调器最快等多久可以出发保存下一个检查点的指令。这就意味着即使已经达到了周期触发的时间点,只要距离上一个检查点完成的间隔不够,就依然不能开启下一次检查点的保存。这就为正常处理数据留下了充足的间隙。当指定这个参数时,实际并发为1。 - 最大并发检查点数量(maxConcurrentCheckpoints)
用于指定运行中的检查点最多可以有多少个。由于每个任务的处理进度不同,完全可能出现后面的任务还没完成前一个检查点的保存、前面任务已经开始保存下一个检查点了。这个参数就是限制同时进行的最大数量。 - 开启外部持久化存储(enableExternalizedCheckpoints)
用于开启检查点的外部持久化,而且默认在作业失败的时候不会自动清理,如果想释放空间需要自己手工清理。里面传入的参数ExternalizedCheckpointCleanup指定了当作业取消的时候外部的检查点该如何清理。
DELETE_ON_CANCELLATION:在作业取消的时候会自动删除外部检查点,但是如果是作业失败退出,则会保留检查点。
RETAIN_ON_CANCELLATION:作业取消的时候也会保留外部检查点。 - 检查点连续失败次数(tolerableCheckpointFailureNumber)
用于指定检查点连续失败的次数,当达到这个次数,作业就失败退出。默认为0,这意味着不能容忍检查点失败,并且作业将在第一次报告检查点失败时失败。
2)开启非对齐检查点
- 非对齐检查点(enableUnalignedCheckpoints)
不再执行检查点的分界线对齐操作,启用之后可以大大减少产生背压时的检查点保存时间。这个设置要求检查点模式(CheckpointingMode)必须为exctly-once,并且最大并发的检查点个数为1。 - 对齐检查点超时时间(alignedCheckpointTimeout)
该参数只有在启用非对齐检查点的时候有效。参数默认是0,表示一开始就直接用非对齐检查点。如果设置大于0,一开始会使用对齐的检查点,当对齐时间超过该参数设定的时间,则会自动切换成非对齐检查点。
代码中具体设置如下:
public class CheckpointConfigDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(1);
// 代码中用到hdfs,需要导入hadoop依赖、指定访问hdfs的用户名
System.setProperty("HADOOP_USER_NAME", "atguigu");
// TODO 检查点配置
// 1、启用检查点: 默认是barrier对齐的,周期为5s, 精准一次
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
// 2、指定检查点的存储位置
checkpointConfig.setCheckpointStorage("hdfs://hadoop102:8020/chk");
// 3、checkpoint的超时时间: 默认10分钟
checkpointConfig.setCheckpointTimeout(60000);
// 4、同时运行中的checkpoint的最大数量
checkpointConfig.setMaxConcurrentCheckpoints(1);
// 5、最小等待间隔: 上一轮checkpoint结束 到 下一轮checkpoint开始 之间的间隔,设置了>0,并发就会变成1
checkpointConfig.setMinPauseBetweenCheckpoints(1000);
// 6、取消作业时,checkpoint的数据 是否保留在外部系统
// DELETE_ON_CANCELLATION:主动cancel时,删除存在外部系统的chk-xx目录 (如果是程序突然挂掉,不会删)
// RETAIN_ON_CANCELLATION:主动cancel时,外部系统的chk-xx目录会保存下来
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 7、允许 checkpoint 连续失败的次数,默认0--》表示checkpoint一失败,job就挂掉
checkpointConfig.setTolerableCheckpointFailureNumber(10);
// TODO 开启 非对齐检查点(barrier非对齐)
// 开启的要求: Checkpoint模式必须是精准一次,最大并发必须设为1
checkpointConfig.enableUnalignedCheckpoints();
// 开启非对齐检查点才生效: 默认0,表示一开始就直接用 非对齐的检查点
// 如果大于0, 一开始用 对齐的检查点(barrier对齐), 对齐的时间超过这个参数,自动切换成 非对齐检查点(barrier非对齐)
checkpointConfig.setAlignedCheckpointTimeout(Duration.ofSeconds(1));
env
.socketTextStream("hadoop102", 7777)
.flatMap(
(String value, CollectorTuple2String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
)
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(value -> value.f0)
.sum(1)
.print();
env.execute();
}
}
1.4.4 通用增量 checkpoint (changelog)
在 1.15 之前,只有RocksDB 支持增量快照。不同于产生一个包含所有数据的全量备份,增量快照中只包含自上一次快照完成之后被修改的记录,因此可以显著减少快照完成的耗时。
Rocksdb状态后端启用增量checkpoint:
EmbeddedRocksDBStateBackend backend = new EmbeddedRocksDBStateBackend(true);
从 1.15 开始,不管hashmap还是rocksdb 状态后端都可以通过开启changelog实现通用的增量checkpoint。
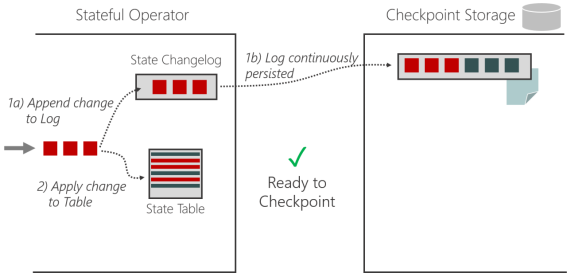
1)执行过程
(1)带状态的算子任务将状态更改写入变更日志(记录状态)
(2)状态物化:状态表定期保存,独立于检查点
(3)状态物化完成后,状态变更日志就可以被截断到相应的点
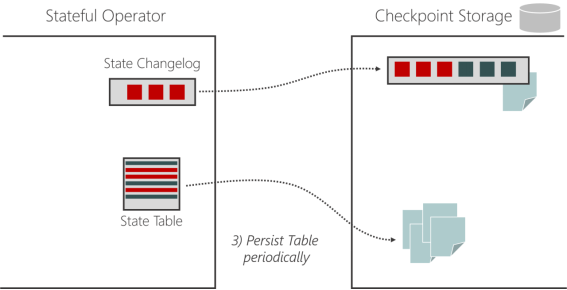
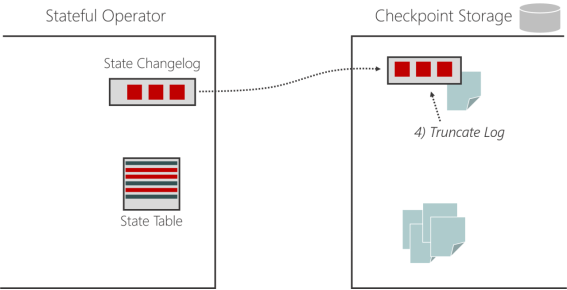
2)注意事项
(1)目前标记为实验性功能,开启后可能会造成资源消耗增大:
HDFS上保存的文件数变多
消耗更多的IO带宽用于上传变更日志
更多的CPU用于序列化状态更改
TaskManager使用更多内存来缓存状态更改
(2)使用限制:
Checkpoint的最大并发必须为1
从 Flink 1.15 开始,只有文件系统的存储类型实现可用(memory测试阶段)
不支持 NO_CLAIM 模式
3)使用方式
(1)方式一:配置文件指定
state.backend.changelog.enabled: true
state.backend.changelog.storage: filesystem
# 存储 changelog 数据
dstl.dfs.base-path: hdfs://hadoop102:8020/changelog
execution.checkpointing.max-concurrent-checkpoints: 1
execution.savepoint-restore-mode: CLAIM
(2)方式二:在代码中设置
需要引入依赖:
dependency>
groupId>org.apache.flink/groupId>
artifactId>flink-statebackend-changelog/artifactId>
version>${flink.version}/version>
scope>runtime/scope>
/dependency>
开启changelog:
env.enableChangelogStateBackend(true);
1.4.5 最终检查点
如果数据源是有界的,就可能出现部分Task已经处理完所有数据,变成finished状态,不继续工作。从 Flink 1.14 开始,这些finished状态的Task,也可以继续执行检查点。自 1.15 起默认启用此功能,并且可以通过功能标志禁用它:
Configuration config = new Configuration();
config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, false);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(config);
1.5 保存点(Savepoint)
除了检查点外,Flink还提供了另一个非常独特的镜像保存功能——保存点(savepoint)。
从名称就可以看出,这也是一个存盘的备份,它的原理和算法与检查点完全相同,只是多了一些额外的元数据。
1.5.1 保存点的用途
保存点与检查点最大的区别,就是触发的时机。检查点是由Flink自动管理的,定期创建,发生故障之后自动读取进行恢复,这是一个“自动存盘”的功能;而保存点不会自动创建,必须由用户明确地手动触发保存操作,所以就是“手动存盘”。
保存点可以当作一个强大的运维工具来使用。我们可以在需要的时候创建一个保存点,然后停止应用,做一些处理调整之后再从保存点重启。它适用的具体场景有:
- 版本管理和归档存储
- 更新Flink版本
- 更新应用程序
- 调整并行度
- 暂停应用程序
需要注意的是,保存点能够在程序更改的时候依然兼容,前提是状态的拓扑结构和数据类型不变。我们知道保存点中状态都是以算子ID-状态名称这样的key-value组织起来的,算子ID可以在代码中直接调用SingleOutputStreamOperator的.uid()方法来进行指定:
DataStreamString> stream = env
.addSource(new StatefulSource()).uid("source-id")
.map(new StatefulMapper()).uid("mapper-id")
.print();
对于没有设置ID的算子,Flink默认会自动进行设置,所以在重新启动应用后可能会导致ID不同而无法兼容以前的状态。所以为了方便后续的维护,强烈建议在程序中为每一个算子手动指定ID。
1.5.2 使用保存点
保存点的使用非常简单,我们可以使用命令行工具来创建保存点,也可以从保存点恢复作业。
(1)创建保存点
要在命令行中为运行的作业创建一个保存点镜像,只需要执行:
bin/flink savepoint :jobId [:targetDirectory]
这里jobId需要填充要做镜像保存的作业ID,目标路径targetDirectory可选,表示保存点存储的路径。
对于保存点的默认路径,可以通过配置文件flink-conf.yaml中的state.savepoints.dir项来设定:
state.savepoints.dir: hdfs:///flink/savepoints
当然对于单独的作业,我们也可以在程序代码中通过执行环境来设置:
env.setDefaultSavepointDir("hdfs:///flink/savepoints");
由于创建保存点一般都是希望更改环境之后重启,所以创建之后往往紧接着就是停掉作业的操作。除了对运行的作业创建保存点,我们也可以在停掉一个作业时直接创建保存点:
bin/flink stop --savepointPath [:targetDirectory] :jobId
(2)从保存点重启应用
我们已经知道,提交启动一个Flink作业,使用的命令是flink run;现在要从保存点重启一个应用,其实本质是一样的:
bin/flink run -s :savepointPath [:runArgs]
这里只要增加一个-s参数,指定保存点的路径就可以了,其它启动时的参数还是完全一样的,如果是基于yarn的运行模式还需要加上 -yid application-id。我们在第三章使用web UI进行作业提交时,可以填入的参数除了入口类、并行度和运行参数,还有一个“Savepoint Path”,这就是从保存点启动应用的配置。
1.5.3 使用保存点切换状态后端
使用savepoint恢复状态的时候,也可以更换状态后端。但是有一点需要注意的是,不要在代码中指定状态后端了, 通过配置文件来配置或者-D 参数配置。
打包时,服务器上有的就provided,可能遇到依赖问题,报错:javax.annotation.Nullable找不到,可以导入如下依赖:
dependency>
groupId>com.google.code.findbugs/groupId>
artifactId>jsr305/artifactId>
version>1.3.9/version>
/dependency>
(1)提交flink作业
bin/flink run-application -d -t yarn-application -Dstate.backend=hashmap -c com.atguigu.checkpoint.SavepointDemo FlinkTutorial-1.0-SNAPSHOT.jar
(2)停止flink作业时,触发保存点
方式一:stop优雅停止并触发保存点,要求source实现StoppableFunction接口
bin/flink stop -p savepoint路径 job-id -yid application-id
方式二:cancel立即停止并触发保存点
bin/flink cancel -s savepoint路径 job-id -yid application-id
案例中source是socket,不能用stop
bin/flink cancel -s hdfs://hadoop102:8020/sp cffca338509ea04f38f03b4b77c8075c -yid application_1681871196375_0001
(3)从savepoint恢复作业,同时修改状态后端
bin/flink run-application -d -t yarn-application -s hdfs://hadoop102:8020/sp/savepoint-267cc0-47a214b019d5 -Dstate.backend=rocksdb -c com.atguigu.checkpoint.SavepointDemo FlinkTutorial-1.0-SNAPSHOT.jar
(4)从保存下来的checkpoint恢复作业
bin/flink run-application -d -t yarn-application -Dstate.backend=rocksdb -s hdfs://hadoop102:8020/chk/532f87ef4146b2a2968a1c137d33d4a6/chk-175 -c com.atguigu.checkpoint.SavepointDemo ./FlinkTutorial-1.0-SNAPSHOT.jar
如果停止作业时,忘了触发保存点也不用担心,现在版本的flink支持从保留在外部系统的checkpoint恢复作业,但是恢复时不支持切换状态后端。
2. 状态一致性
2.1 一致性的概念和级别
一致性其实就是结果的正确性,一般从数据丢失、数据重复来评估。
流式计算本身就是一个一个来的,所以正常处理的过程中结果肯定是正确的;但在发生故障、需要恢复状态进行回滚时就需要更多的保障机制了。我们通过检查点的保存来保证状态恢复后结果的正确,所以主要讨论的就是“状态的一致性”。
一般说来,状态一致性有三种级别:
- 最多一次(At-Most-Once)
- 至少一次(At-Least-Once)
- 精确一次(Exactly-Once)
2.2 端到端的状态一致性
我们已经知道检查点可以保证Flink内部状态的一致性,而且可以做到精确一次。那是不是说,只要开启了检查点,发生故障进行恢复,结果就不会有任何问题呢?
没那么简单。在实际应用中,一般要保证从用户的角度看来,最终消费的数据是正确的。而用户或者外部应用不会直接从Flink内部的状态读取数据,往往需要我们将处理结果写入外部存储中。这就要求我们不仅要考虑Flink内部数据的处理转换,还涉及到从外部数据源读取,以及写入外部持久化系统,整个应用处理流程从头到尾都应该是正确的。
所以完整的流处理应用,应该包括了数据源、流处理器和外部存储系统三个部分。这个完整应用的一致性,就叫做“端到端(end-to-end)的状态一致性”,它取决于三个组件中最弱的那一环。一般来说,能否达到at-least-once一致性级别,主要看数据源能够重放数据;而能否达到exactly-once级别,流处理器内部、数据源、外部存储都要有相应的保证机制。
3. 端到端精确一次(End-To-End Exactly-Once)
实际应用中,最难做到、也最希望做到的一致性语义,无疑就是端到端(end-to-end)的“精确一次”。我们知道,对于Flink内部来说,检查点机制可以保证故障恢复后数据不丢(在能够重放的前提下),并且只处理一次,所以已经可以做到exactly-once的一致性语义了。
所以端到端一致性的关键点,就在于输入的数据源端和输出的外部存储端。
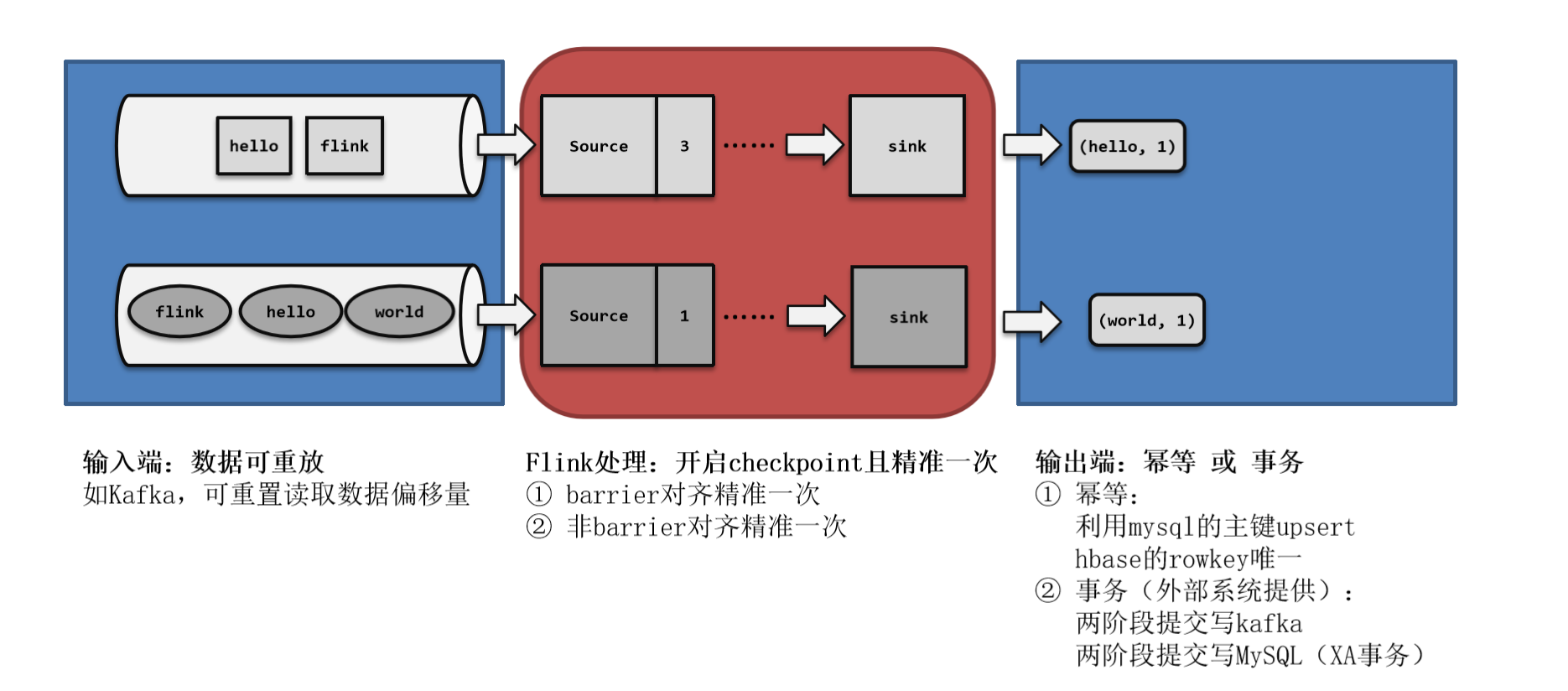
3.1 输入端保证
输入端主要指的就是Flink读取的外部数据源。对于一些数据源来说,并不提供数据的缓冲或是持久化保存,数据被消费之后就彻底不存在了,例如socket文本流。对于这样的数据源,故障后我们即使通过检查点恢复之前的状态,可保存检查点之后到发生故障期间的数据已经不能重发了,这就会导致数据丢失。所以就只能保证at-most-once的一致性语义,相当于没有保证。
想要在故障恢复后不丢数据,外部数据源就必须拥有重放数据的能力。常见的做法就是对数据进行持久化保存,并且可以重设数据的读取位置。一个最经典的应用就是Kafka。在Flink的Source任务中将数据读取的偏移量保存为状态,这样就可以在故障恢复时从检查点中读取出来,对数据源重置偏移量,重新获取数据。
数据源可重放数据,或者说可重置读取数据偏移量,加上Flink的Source算子将偏移量作为状态保存进检查点,就可以保证数据不丢。这是达到at-least-once一致性语义的基本要求,当然也是实现端到端exactly-once的基本要求。
3.2 输出端保证
有了Flink的检查点机制,以及可重放数据的外部数据源,我们已经能做到at-least-once了。但是想要实现exactly-once却有更大的困难:数据有可能重复写入外部系统。
因为检查点保存之后,继续到来的数据也会一一处理,任务的状态也会更新,最终通过Sink任务将计算结果输出到外部系统;只是状态改变还没有存到下一个检查点中。这时如果出现故障,这些数据都会重新来一遍,就计算了两次。我们知道对Flink内部状态来说,重复计算的动作是没有影响的,因为状态已经回滚,最终改变只会发生一次;但对于外部系统来说,已经写入的结果就是泼出去的水,已经无法收回了,再次执行写入就会把同一个数据写入两次。
所以这时,我们只保证了端到端的at-least-once语义。
为了实现端到端exactly-once,我们还需要对外部存储系统、以及Sink连接器有额外的要求。能够保证exactly-once一致性的写入方式有两种:
- 幂等写入
- 事务写入
我们需要外部存储系统对这两种写入方式的支持,而Flink也为提供了一些Sink连接器接口。接下来我们进行展开讲解。
1)幂等(Idempotent)写入
所谓“幂等”操作,就是说一个操作可以重复执行很多次,但只导致一次结果更改。也就是说,后面再重复执行就不会对结果起作用了。
这相当于说,我们并没有真正解决数据重复计算、写入的问题;而是说,重复写入也没关系,结果不会改变。所以这种方式主要的限制在于外部存储系统必须支持这样的幂等写入:比如Redis中键值存储,或者关系型数据库(如MySQL)中满足查询条件的更新操作。
需要注意,对于幂等写入,遇到故障进行恢复时,有可能会出现短暂的不一致。因为保存点完成之后到发生故障之间的数据,其实已经写入了一遍,回滚的时候并不能消除它们。如果有一个外部应用读取写入的数据,可能会看到奇怪的现象:短时间内,结果会突然“跳回”到之前的某个值,然后“重播”一段之前的数据。不过当数据的重放逐渐超过发生故障的点的时候,最终的结果还是一致的。
2)事务(Transactional)写入
如果说幂等写入对应用场景限制太多,那么事务写入可以说是更一般化的保证一致性的方式。
输出端最大的问题,就是写入到外部系统的数据难以撤回。而利用事务就可以实现对已写入数据的撤回。
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。事务有四个基本特性:原子性、一致性、隔离性和持久性,这就是著名的ACID。
在Flink流处理的结果写入外部系统时,如果能够构建一个事务,让写入操作可以随着检查点来提交和回滚,那么自然就可以解决重复写入的问题了。所以事务写入的基本思想就是:用一个事务来进行数据向外部系统的写入,这个事务是与检查点绑定在一起的。当Sink任务遇到barrier时,开始保存状态的同时就开启一个事务,接下来所有数据的写入都在这个事务中;待到当前检查点保存完毕时,将事务提交,所有写入的数据就真正可用了。如果中间过程出现故障,状态会回退到上一个检查点,而当前事务没有正常关闭(因为当前检查点没有保存完),所以也会回滚,写入到外部的数据就被撤销了。
具体来说,又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)
(1)预写日志(write-ahead-log,WAL)
我们发现,事务提交是需要外部存储系统支持事务的,否则没有办法真正实现写入的回撤。那对于一般不支持事务的存储系统,能够实现事务写入呢?
预写日志(WAL)就是一种非常简单的方式。具体步骤是:
①先把结果数据作为日志(log)状态保存起来
②进行检查点保存时,也会将这些结果数据一并做持久化存储
③在收到检查点完成的通知时,将所有结果一次性写入外部系统。
④在成功写入所有数据后,在内部再次确认相应的检查点,将确认信息也进行持久化保存。这才代表着检查点的真正完成。
我们会发现,这种方式类似于检查点完成时做一个批处理,一次性的写入会带来一些性能上的问题;而优点就是比较简单,由于数据提前在状态后端中做了缓存,所以无论什么外部存储系统,理论上都能用这种方式一批搞定。在Flink中DataStream API提供了一个模板类GenericWriteAheadSink,用来实现这种事务型的写入方式。
需要注意的是,预写日志这种一批写入的方式,有可能会写入失败;所以在执行写入动作之后,必须等待发送成功的返回确认消息。在成功写入所有数据后,在内部再次确认相应的检查点,这才代表着检查点的真正完成。这里需要将确认信息也进行持久化保存,在故障恢复时,只有存在对应的确认信息,才能保证这批数据已经写入,可以恢复到对应的检查点位置。
但这种“再次确认”的方式,也会有一些缺陷。如果我们的检查点已经成功保存、数据也成功地一批写入到了外部系统,但是最终保存确认信息时出现了故障,Flink最终还是会认为没有成功写入。于是发生故障时,不会使用这个检查点,而是需要回退到上一个;这样就会导致这批数据的重复写入。
(2)两阶段提交(two-phase-commit,2PC)
前面提到的各种实现exactly-once的方式,多少都有点缺陷;而更好的方法就是传说中的两阶段提交(2PC)。
顾名思义,它的想法是分成两个阶段:先做“预提交”,等检查点完成之后再正式提交。这种提交方式是真正基于事务的,它需要外部系统提供事务支持。
具体的实现步骤为:
①当第一条数据到来时,或者收到检查点的分界线时,Sink任务都会启动一个事务。
②接下来接收到的所有数据,都通过这个事务写入外部系统;这时由于事务没有提交,所以数据尽管写入了外部系统,但是不可用,是“预提交”的状态。
③当Sink任务收到JobManager发来检查点完成的通知时,正式提交事务,写入的结果就真正可用了。
当中间发生故障时,当前未提交的事务就会回滚,于是所有写入外部系统的数据也就实现了撤回。这种两阶段提交(2PC)的方式充分利用了Flink现有的检查点机制:分界线的到来,就标志着开始一个新事务;而收到来自JobManager的checkpoint成功的消息,就是提交事务的指令。每个结果数据的写入,依然是流式的,不再有预写日志时批处理的性能问题;最终提交时,也只需要额外发送一个确认信息。所以2PC协议不仅真正意义上实现了exactly-once,而且通过搭载Flink的检查点机制来实现事务,只给系统增加了很少的开销。
Flink提供了TwoPhaseCommitSinkFunction接口,方便我们自定义实现两阶段提交的SinkFunction的实现,提供了真正端到端的exactly-once保证。新的Sink架构,使用的是TwoPhaseCommittingSink接口。
不过两阶段提交虽然精巧,却对外部系统有很高的要求。这里将2PC对外部系统的要求列举如下:
- 外部系统必须提供事务支持,或者Sink任务必须能够模拟外部系统上的事务。
- 在检查点的间隔期间里,必须能够开启一个事务并接受数据写入。
- 在收到检查点完成的通知之前,事务必须是“等待提交”的状态。在故障恢复的情况下,这可能需要一些时间。如果这个时候外部系统关闭事务(例如超时了),那么未提交的数据就会丢失。
- Sink任务必须能够在进程失败后恢复事务。
- 提交事务必须是幂等操作。也就是说,事务的重复提交应该是无效的。
可见,2PC在实际应用同样会受到比较大的限制。具体在项目中的选型,最终还应该是一致性级别和处理性能的权衡考量。
3.3 Flink和Kafka连接时的精确一次保证
在流处理的应用中,最佳的数据源当然就是可重置偏移量的消息队列了;它不仅可以提供数据重放的功能,而且天生就是以流的方式存储和处理数据的。所以作为大数据工具中消息队列的代表,Kafka可以说与Flink是天作之合,实际项目中也经常会看到以Kafka作为数据源和写入的外部系统的应用。在本小节中,我们就来具体讨论一下Flink和Kafka连接时,怎样保证端到端的exactly-once状态一致性。
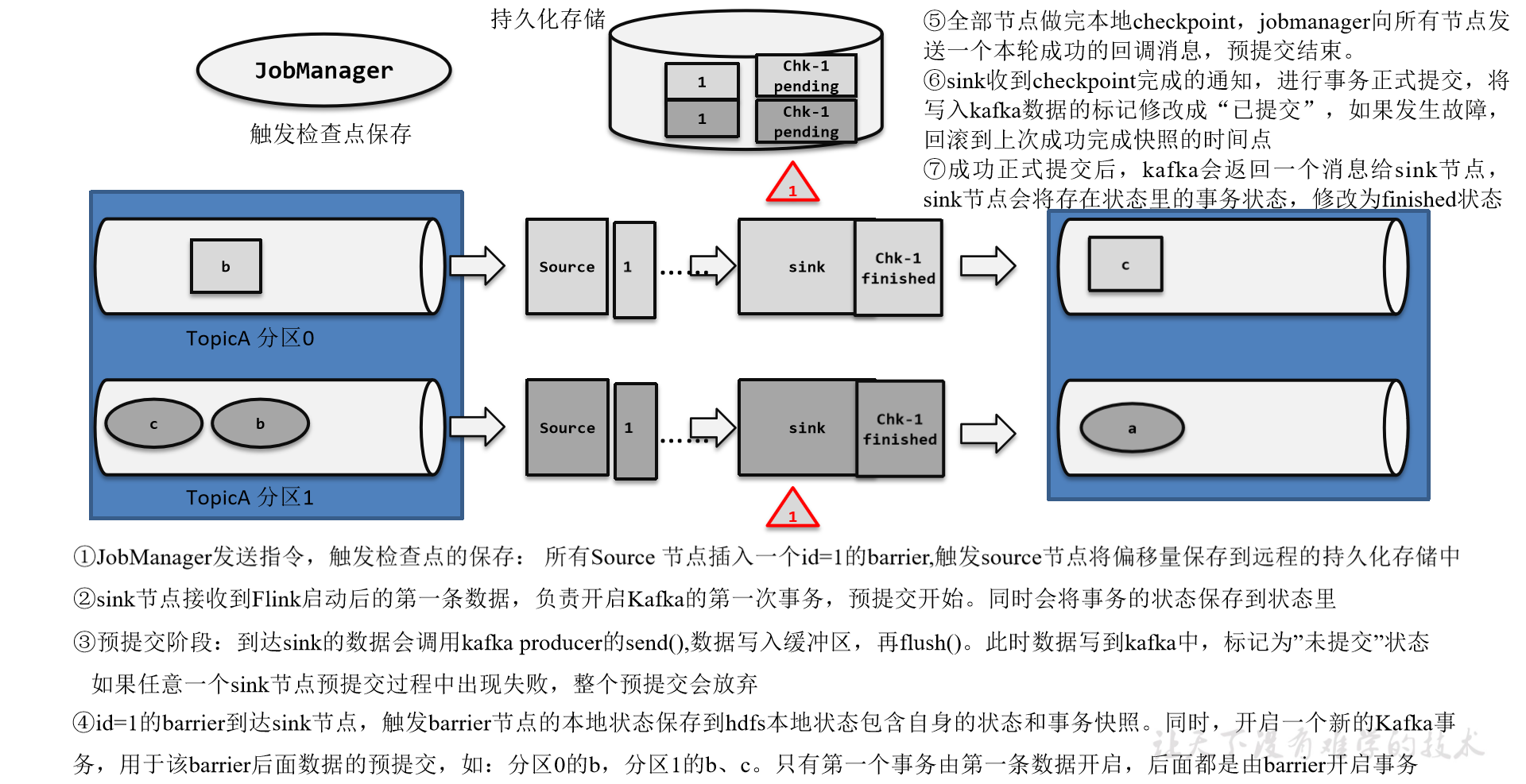
1)整体介绍
既然是端到端的exactly-once,我们依然可以从三个组件的角度来进行分析:
(1)Flink内部
Flink内部可以通过检查点机制保证状态和处理结果的exactly-once语义。
(2)输入端
输入数据源端的Kafka可以对数据进行持久化保存,并可以重置偏移量(offset)。所以我们可以在Source任务(FlinkKafkaConsumer)中将当前读取的偏移量保存为算子状态,写入到检查点中;当发生故障时,从检查点中读取恢复状态,并由连接器FlinkKafkaConsumer向Kafka重新提交偏移量,就可以重新消费数据、保证结果的一致性了。
(3)输出端
输出端保证exactly-once的最佳实现,当然就是两阶段提交(2PC)。作为与Flink天生一对的Kafka,自然需要用最强有力的一致性保证来证明自己。
也就是说,我们写入Kafka的过程实际上是一个两段式的提交:处理完毕得到结果,写入Kafka时是基于事务的“预提交”;等到检查点保存完毕,才会提交事务进行“正式提交”。如果中间出现故障,事务进行回滚,预提交就会被放弃;恢复状态之后,也只能恢复所有已经确认提交的操作。
2)需要的配置
在具体应用中,实现真正的端到端exactly-once,还需要有一些额外的配置:
(1)
必须启用检查点
(2)指定KafkaSink的发送级别为DeliveryGuarantee.EXACTLY_ONCE
(3)配置Kafka读取数据的消费者的隔离级别
这里所说的Kafka,是写入的外部系统。预提交阶段数据已经写入,只是被标记为“未提交”(uncommitted),而Kafka中默认的隔离级别isolation.level是read_uncommitted,也就是可以读取未提交的数据。这样一来,外部应用就可以直接消费未提交的数据,对于事务性的保证就失效了。所以应该将隔离级别配置
为read_committed,表示消费者遇到未提交的消息时,会停止从分区中消费数据,直到消息被标记为已提交才会再次恢复消费。当然,这样做的话,外部应用消费数据就会有显著的延迟。
(4)事务超时配置
Flink的Kafka连接器中配置的事务超时时间transaction.timeout.ms默认是1小时,而Kafka集群配置的事务最大超时时间transaction.max.timeout.ms默认是15分钟。所以在检查点保存时间很长时,有可能出现Kafka已经认为事务超时了,丢弃了预提交的数据;而Sink任务认为还可以继续等待。如果接下来检查点保存成功,发生故障后回滚到这个检查点的状态,这部分数据就被真正丢掉了。所以这两个超时时间,前者应该小于等于后者。
public class KafkaEOSDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 代码中用到hdfs,需要导入hadoop依赖、指定访问hdfs的用户名
System.setProperty("HADOOP_USER_NAME", "atguigu");
// TODO 1、启用检查点,设置为精准一次
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
checkpointConfig.setCheckpointStorage("hdfs://hadoop102:8020/chk");
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// TODO 2.读取kafka
KafkaSourceString> kafkaSource = KafkaSource.String>builder()
.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
.setGroupId("atguigu")
.setTopics("topic_1")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
.build();
DataStreamSourceString> kafkasource = env
.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "kafkasource");
/**
* TODO 3.写出到Kafka
* 精准一次 写入Kafka,需要满足以下条件,缺一不可
* 1、开启checkpoint
* 2、sink设置保证级别为 精准一次
* 3、sink设置事务前缀
* 4、sink设置事务超时时间: checkpoint间隔
KafkaSinkString> kafkaSink = KafkaSink.String>builder()
// 指定 kafka 的地址和端口
.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
// 指定序列化器:指定Topic名称、具体的序列化
.setRecordSerializer(
KafkaRecordSerializationSchema.String>builder()
.setTopic("ws")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
// TODO 3.1 精准一次,开启 2pc
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// TODO 3.2 精准一次,必须设置 事务的前缀
.setTransactionalIdPrefix("atguigu-")
// TODO 3.3 精准一次,必须设置 事务超时时间: 大于checkpoint间隔,小于 max 15分钟
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10*60*1000+"")
.build();
kafkasource.sinkTo(kafkaSink);
env.execute();
}
}
后续读取“ws”这个topic的消费者,要设置事务的隔离级别为“读已提交”,如下:
public class KafkaEOSDemo2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 消费 在前面使用两阶段提交写入的Topic
KafkaSourceString> kafkaSource = KafkaSource.String>builder()
.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
.setGroupId("atguigu")
.setTopics("ws")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
// TODO 作为 下游的消费者,要设置 事务的隔离级别 = 读已提交
.setProperty(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed")
.build();
env
.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "kafkasource")
.print();
env.execute();
}
}
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
