

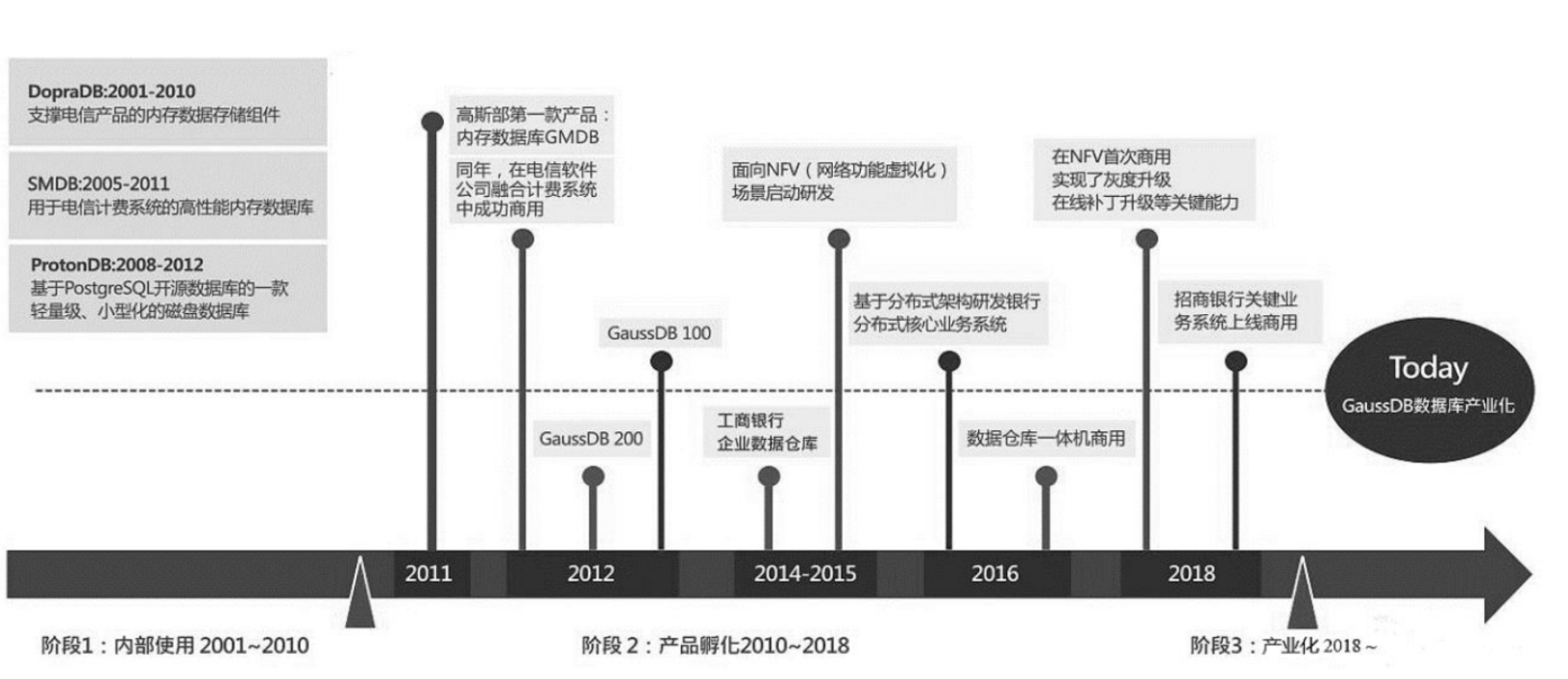
1.GaussDB的发展
2.GaussDB的生态
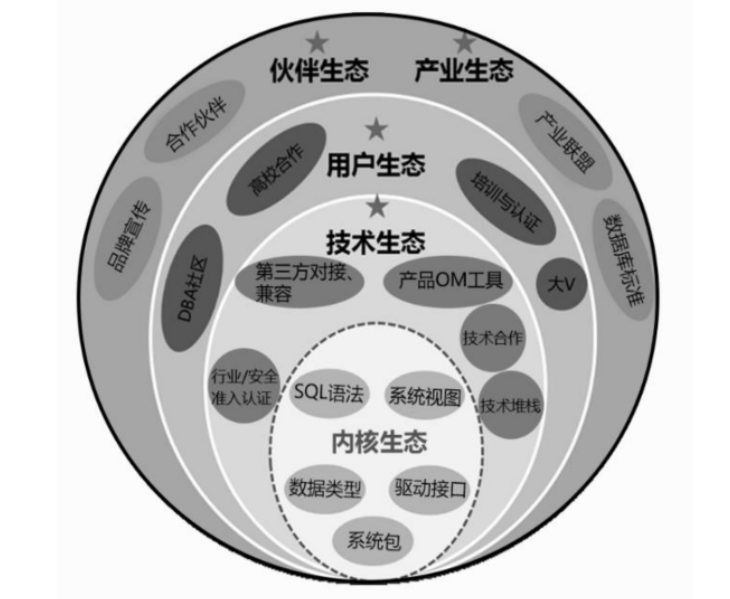
- 内部:
云化+自动化方案。通过数据库运行基础设施的云化将DBA(数据库管理员)和运维人员的日常工作
自动化。 - 外部:
采用与数据库周边生态服务器托管网伙伴对接与认证的生态连接融合方案,解决开发者/DBA难获取、应用难对接等生态难题。
3.GaussDB特征及技术竞争力
- 分布式:
分布式事务能力+跨DC(Data Center,数据中心)高可用能力,解决传统关系型数据库的扩展性、可用性不足等瓶颈。 - 云化架构:
满足公有云、私有云和混合云场景的云化架构,满足多元需求场景的云数据库诉求。 - 混合负载:
在一套数据库中运行多种负载,简化系统部署,消除数据复制或搬迁带来的数据一致性问题,同时也提升了系统的可靠性和实时性。 - 多模异构:
构建管理移动互联网、物联网、人工智能、时序、图像等多模数据的新型数据库,通过改造优化数据库架构,实现充分利用“通用处理器+异构加速器”算力优势。 - AI+DB:
借助A算法的精度和适用范围,支持在数据库参数调优、SQL执行优化等特定场景下解决问题,支持从图像,语言、文本等非结构化数据抽取结构化信息。
4.设计思想与用户对象
设计思想:利用云技术和A技术,提供空间管理作用范围极为广大的、云部署的数据库系统服务的甚础设施,以实现对计算机资源的共享。
- 公有云数据库系统服务:面向中小型企业的数据库需求。针对中小型企业提供公有云数据库系统服务,大幅降低这类实体的运营成本。
- 私有云数据库系统服务:面向中大型企业的数据库服务需求。在实体内部购买大量设备,同时构筑相关的PaS层和SaS层,数据库服务是其中非常关键一类服务。使得内部和各个部门的信息新系统可以共享相关资源,同时实现数据共享,并降低整体的维护成本,最终降低总体拥有成本。
- 据库系统服务
选择公有云服务,哪些数据库系统服务选择私有云服务,主要从降低系统的总体拥有成本(Total Cost of Ownership,TCO)考虑,包括构建成本、运维成本、折旧费用等。
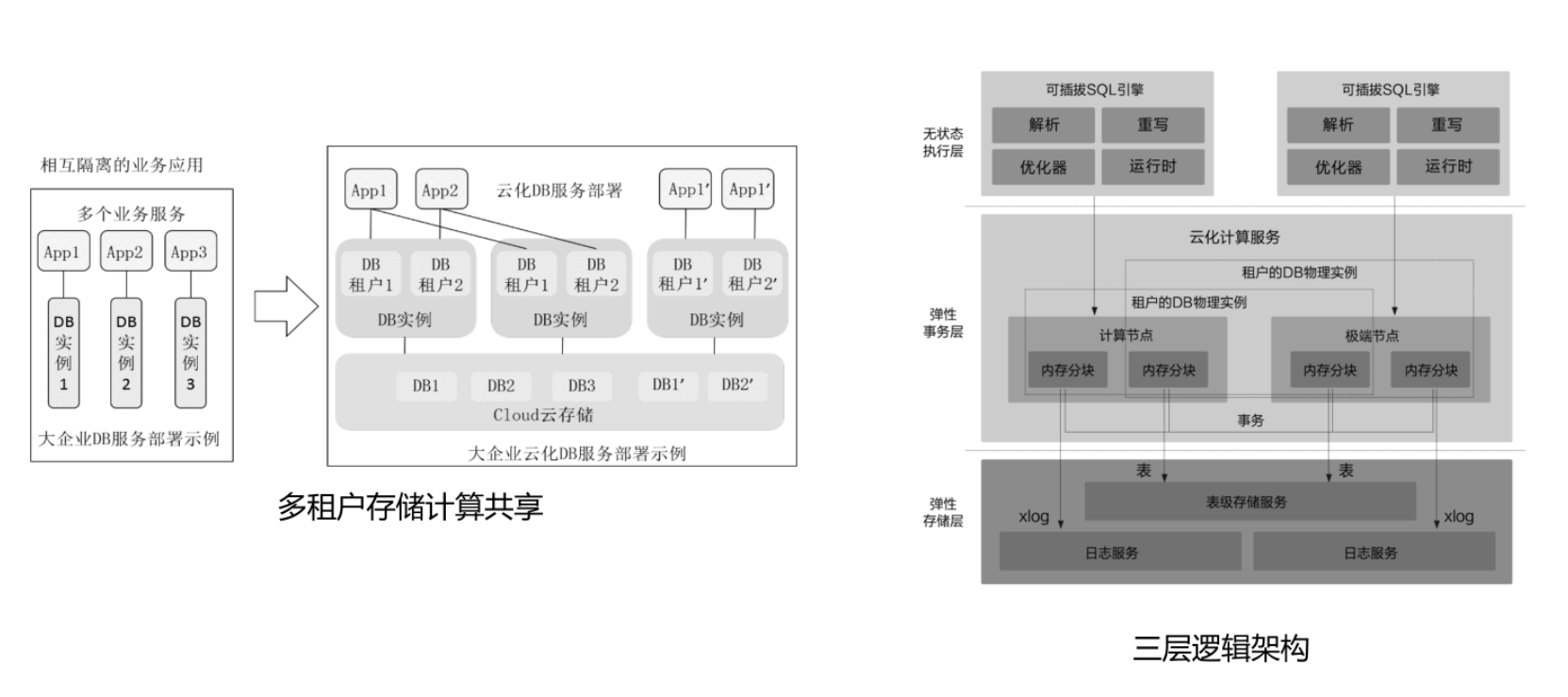
5.弹性伸缩的多租户数据库架构
6.云数据库的克隆复制
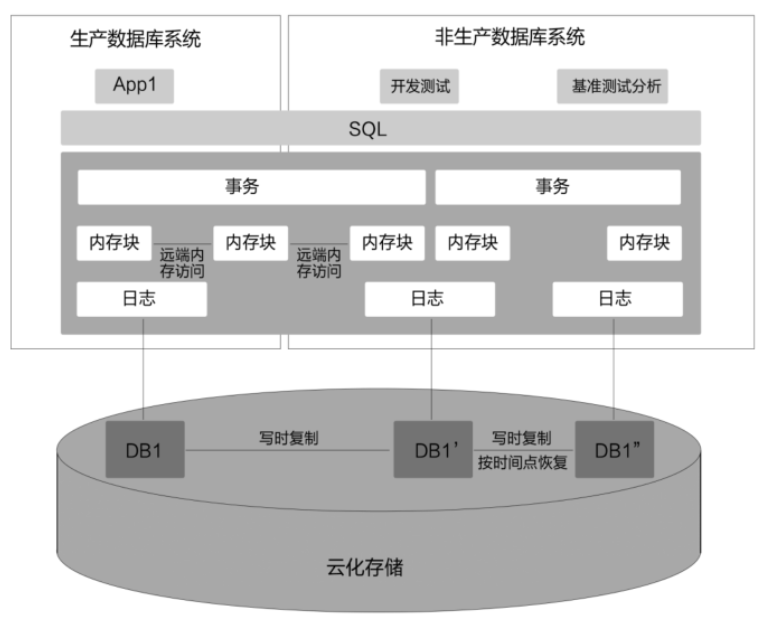
对生产数据库系统进行克隆、复制等操作。克隆、复制出来的数据库系统可以用于非生产系统,并用于
开发、测试流程或参与到基准测试中。
用户非生产系统的数据库系统保持了和生产系统当前一致的数据,同时生产系统中更新的一部分数据也可以实时同步到非生产数据库系统中,进而保持这两部分数据之间的一致性。
7.多模数据库的设计思想
设计思想:在数据库系统之上提供统一的多模数据管理、处理能力,以及统一运维能力。
- 多模数据的存储:对于一个统一的多模数据库系统而言,需要提供多种数据模型的存储能力,包括关系、时序、流图、空间等。
- 多模数据的处理:对于一个统一的多模数据库系统而言,需要提供多种数据库模型的处理能力,包括关系、时序、流图、空间等。
- 多模数据之间的相关转换:大多数情况下,客户的数据产生源只有一个,即数据产生源的数据模型是单一的,但是后续处理可能需要使用多种模型来表征物理世界,进而进行数据处理,或者需要通过多种模型之间的相互协作来完成单一任务。因此,不同模型之间的数据转换也是极为重要的。
8.多模数据库系统架构
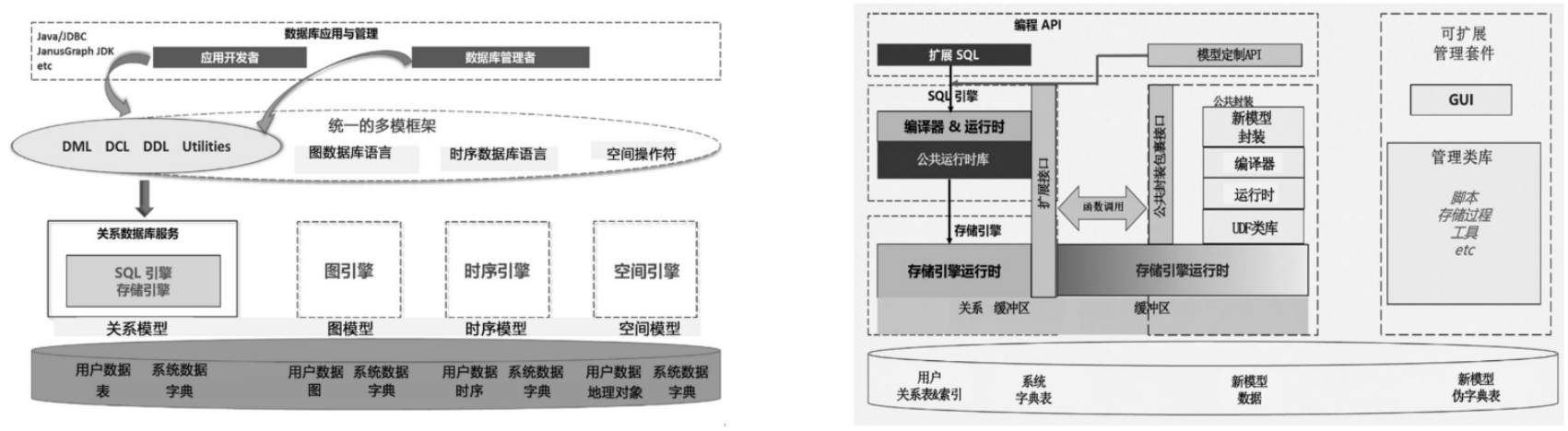
引入多模数据库统一框架(Multi–Model Database Uniform Framework),为用户提供关
系数据库、图数据库、时序数据库等多模数据库统一数据访问和维护接口,简化运维和应用开发人
员的学习和使用成本,提升了数据使用安全性(数据无须在多个系统之间进行倒换,减少了数据在
网络上暴露的时间)。
9.GaussDB数据库整体架构
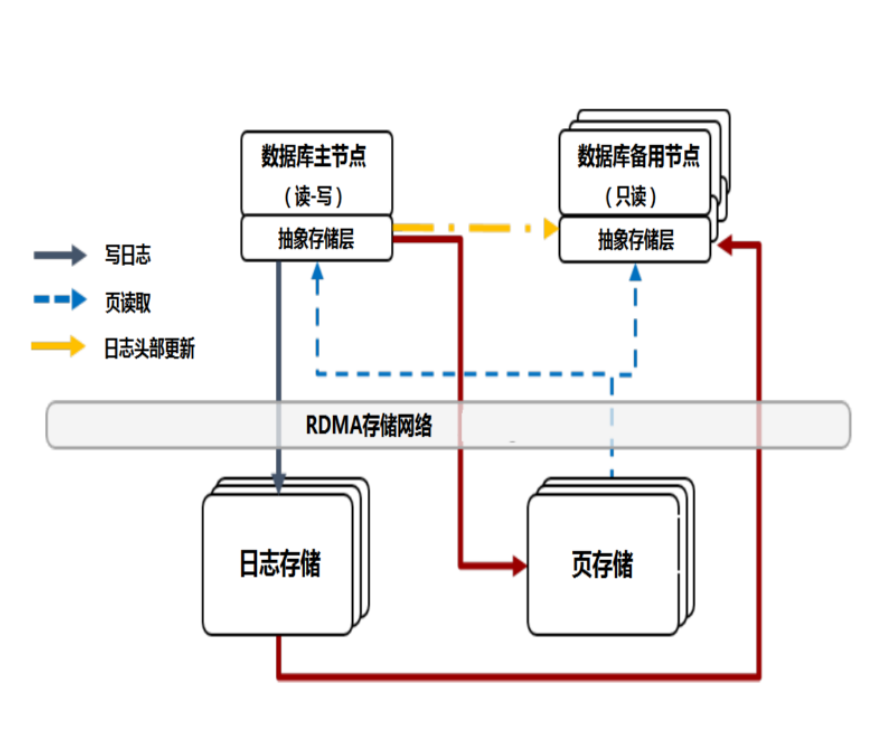
GaussDB主要包括四个逻辑模块:
9.1 数据库前端
提交事务,基于MySQL8.0,100%兼容。
9.2 存储抽象层(SAL)
数据分片、故障恢复、远程数据存储。
9.3 Log Store(日志存储)
日志存储是在存储层中执行的一个服务,负责存储日志记录。一旦
属于事务的所有日志记录都持久化了,就可以向客户端确认事务完
成。
9.4 Page Store(页存储)
Page Store服务器是存储层另外一个服务。GaussDB的数据库被
划分为固定大小(10GB)的分区,这些分区被称为slice。每服务器托管网个
Page Store服务器处理来自不同数据库的多个slices,接收属于它
负责的slices的日志。一个数据库可以有多个slices,每个slice都复
制到3个Page Store,以保证持久性和可用性。
10.部署模式

10.1 单AZ部署
- 3副本:副本在不同节点。
- Log Store:3副本全部持久化,事务才可提交;从任何一个副本即可读取数据,
- Page Store:3副本任何一个持久化,即成功:副本之间可进行同步数据。
。
10.2 多AZ
- 6副本:每个AZ包含两个副本。
- Log Store:6个副本,对于写需要4个成功写入,对于读需要3个副本有效。
- Page Store:6副本任何一个持久化,即成功:副本之间可进行同步数据。
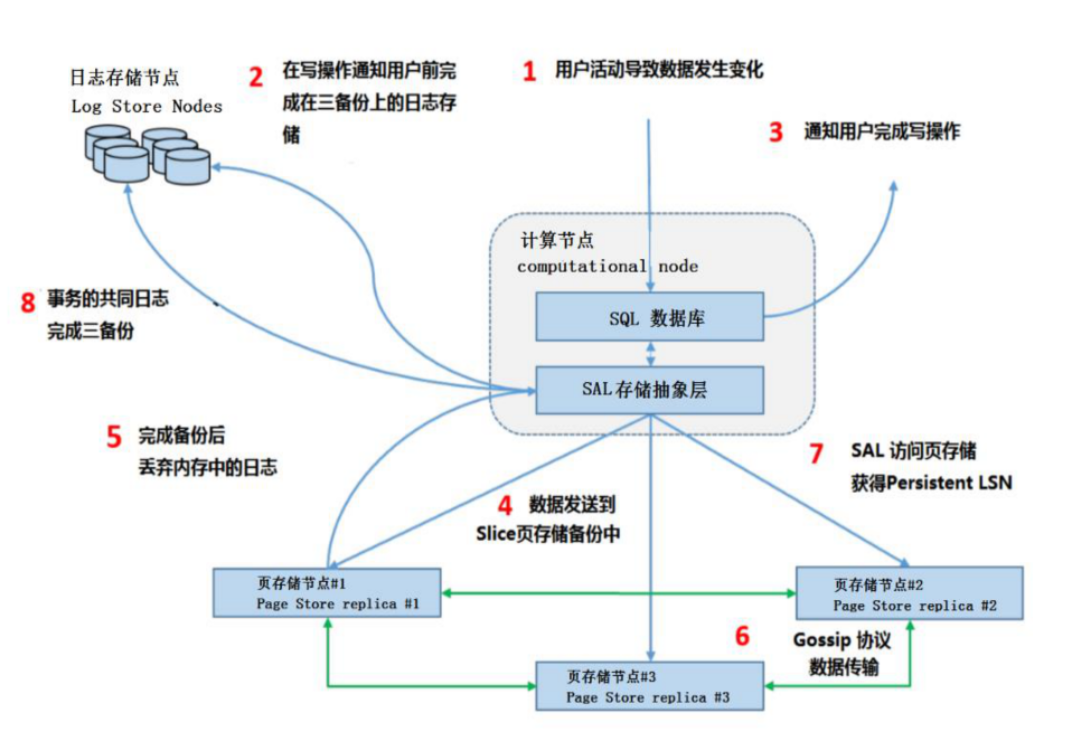
11.写入流程
12.读流程
数据库前端以页为单位读取数据。读取或修改数据时,数据库前端需要把对应的页面读取到
buffer pool中。当需要读取一个新的页面,但ouffer pooli已经满的时候,系统必须淘汰掉一个
页面来置换。
- GaussDB修改了页面淘汰算法,保证脏页对应的所有日志记录成功写入到至少一个Page Store,之后才会
淘汰该页面。因此,GaussDB保证了在日志记录到达Page Store之前,对应页面可以从ouffer pool中
访问。淘汰后,立即就可以从Page Store中读取。 - 对于每个slice,SAL记录发送到slicel的最后的日志记录的LSN。当master节点读取页面时,读操作到达
SAL,SAL会发出一个读请求,并附带上述LSN。读请求被系统发送到已知的时延低的Page Store节点。
如果所选的节点不可用,或者它没有接收到所指定LSN之前的所有日志记录,则返回读异常,SAL将尝试
访问下一个存有该slicel的Page Store节点,直到找到能够满足该请求的节点为止。
13.Log Store日志存储故障恢复
- 临时故障:
Log Store变为Read-only模式,不会有新的请求,该节点设为临时故障状态。恢复后,不需要Recovery, 丢失数据可从其他副本拉取。 - 永久故障:
故障节点从集群中剔除,该节点上所丢失的数据,会通过其他副本上进行重构。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
