
Go 函数的健壮性、panic异常处理、defer 机制

-
Go 函数的健壮性、panic异常处理、defer 机制
-
一、函数健壮性的“三不要”原则
- 1.1 原则一:不要相信任何外部输入的参数
- 1.2 原则二:不要忽略任何一个错误
- 1.3 原则三:不要假定异常不会发生
-
二、Go 语言中的异常:panic
- 2.1 panic 异常处理介绍
- 2.2 panicking 的过程
- 2.3 recover 函数介绍
-
三、如何应对 panic?
- 3.1 第一点:评估程序对 panic 的忍受度
- 3.2 第二点:提示潜在 bug
- 3.3 第三点:不要混淆异常与错误
-
四、defer 函数
- 4.1 defer 函数介绍
- 4.2 使用 defer 简化函数实现
-
五、defer 使用的几个注意事项
- 5.1 第一点:明确哪些函数可以作为 deferred 函数
- 5.2 第二点:注意 defer 关键字后面表达式的求值时机
- 5.3 第三点:知晓 defer 带来的性能损耗
-
一、函数健壮性的“三不要”原则
一、函数健壮性的“三不要”原则
1.1 原则一:不要相信任何外部输入的参数
函数的使用者可能是任何人,这些人在使用函数之前可能都没有阅读过任何手册或文档,他们会向函数传入你意想不到的参数。因此,为了保证函数的健壮性,函数需要对所有输入的参数进行合法性的检查。一旦发现问题,立即终止函数的执行,返回预设的错误值。
1.2 原则二:不要忽略任何一个错误
在我们的函数实现中,也会调用标准库或第三方包提供的函数或方法。对于这些调用,我们不能假定它一定会成功,我们一定要显式地检查这些调用返回的错误值。一旦发现错误,要及时终止函数执行,防止错误继续传播。
1.3 原则三:不要假定异常不会发生
这里,我们先要确定一个认知:异常不是错误。错误是可预期的,也是经常会发生的,我们有对应的公开错误码和错误处理预案,但异常却是少见的、意料之外的。通常意义上的异常,指的是硬件异常、操作系统异常、语言运行时异常,还有更大可能是代码中潜在 bug 导致的异常,比如代码中出现了以 0 作为分母,或者是数组越界访问等情况。
虽然异常发生是“小众事件”,但是我们不能假定异常不会发生。所以,函数设计时,我们就需要根据函数的角色和使用场景,考虑是否要在函数内设置异常捕捉和恢复的环节。
二、Go 语言中的异常:panic
2.1 panic 异常处理介绍
不同编程语言表示异常(Exception)这个概念的语法都不相同。在 Go 语言中,异常这个概念由 panic 表示。
panic 指的是 Go 程序在运行时出现的一个异常情况。如果异常出现了,但没有被捕获并恢复,Go 程序的执行就会被终止,即便出现异常的位置不在主 Goroutine 中也会这样。
在 Go 中,panic 主要有两类来源,一类是来自 Go 运行时,另一类则是 Go 开发人员通过 panic 函数主动触发的。无论是哪种,一旦 panic 被触发,后续 Go 程序的执行过程都是一样的,这个过程被 Go 语言称为 panicking。
2.2 panicking 的过程
Go 官方文档以手工调用 panic 函数触发 panic 为例,对 panicking 这个过程进行了诠释:当函数 F 调用 panic 函数时,函数 F 的执行将停止。不过,函数 F 中已进行求值的 deferred 函数都会得到正常执行,执行完这些 deferred 函数后,函数 F 才会把控制权返还给其调用者。
对于函数 F 的调用者而言,函数 F 之后的行为就如同调用者调用的函数是 panic 一样,该 panicking 过程将继续在栈上进行下去,直到当前 Goroutine 中的所有函数都返回为止,然后 Go 程序将崩溃退出。
package main
import "fmt"
func main() {
f()
fmt.Println("Returned normally from f.")
}
func f() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered in f", r)
}
}()
fmt.Println("Calling g.")
g(0)
fmt.Println("Returned normally from g.")
}
func g(i int) {
if i > 3 {
fmt.Println("Panicking!")
panic(fmt.Sprintf("%v", i))
}
defer fmt.Println("Defer in g", i)
fmt.Println("Printing in g", i)
g(i + 1)
}
下面,我们用一个例子来更直观地解释一下 panicking 这个过程:
func foo() {
println("call foo")
bar()
println("exit foo")
}
func bar() {
println("call bar")
panic("panic occurs in bar")
zoo()
println("exit bar")
}
func zoo() {
println("call zoo")
println("exit zoo")
}
func main() {
println("call main")
foo()
println("ex服务器托管网it main")
}
上面这个例子中,从 Go 应用入口开始,函数的调用次序依次为 main -> foo -> bar -> zoo。在 bar 函数中,我们调用 panic 函数手动触发了 panic。
我们执行这个程序的输出结果是这样的:
call main
call foo
call bar
panic: panic occurs in bar
根据前面对 panicking 过程的诠释,理解一下这个例子。
这里,程序从入口函数 main 开始依次调用了 foo、bar 函数,在 bar 函数中,代码在调用 zoo 函数之前调用了 panic 函数触发了异常。那示例的 panicking 过程就从这开始了。bar 函数调用 panic 函数之后,它自身的执行就此停止了,所以我们也没有看到代码继续进入 zoo 函数执行。并且,bar 函数没有捕捉这个 panic,这样这个 panic 就会沿着函数调用栈向上走,来到了 bar 函数的调用者 foo 函数中。
从 foo 函数的视角来看,这就好比将它对 bar 函数的调用,换成了对 panic 函数的调用一样。这样一来,foo 函数的执行也被停止了。由于 foo 函数也没有捕捉 panic,于是 panic 继续沿着函数调用栈向上走,来到了 foo 函数的调用者 main 函数中。
同理,从 main 函数的视角来看,这就好比将它对 foo 函数的调用,换成了对 panic 函数的调用一样。结果就是,main 函数的执行也被终止了,于是整个程序异常退出,日志”exit main”也没有得到输出的机会。
2.3 recover 函数介绍
recover 是Go语言中的一个内置函数,用于在发生 panic 时捕获并处理 panic,以便程序能够继续执行而不会完全崩溃。以下是有关 recover 函数的介绍:
-
用途:
recover用于恢复程序的控制权,防止程序因panic而崩溃。它通常与defer一起使用,用于在发生异常情况时执行一些清理操作、记录错误信息或者尝试恢复程序状态。 -
工作原理:当程序进入
panic状态时,recover可以用来停止panic的传播。它会返回导致panic的值(通常是一个错误信息),允许程序捕获这个值并采取适当的措施。如果recover在当前函数内没有找到可捕获的panic,它会返回nil。 -
与
panic配合使用:通常,recover会与defer一起使用。在defer中使用recover,可以确保在函数返回之前检查panic状态并采取适当的措施。 -
局限性:
recover只能用于捕获最近一次的panic,它不能用于捕获之前的panic。一旦recover成功捕获了一个panic,它会重置panic状态,因此无法继续捕获之前的panic。
接着,我们继续用上面这个例子分析,在触发 panic 的 bar 函数中,对 panic 进行捕捉并恢复,我们直接来看恢复后,整个程序的执行情况是什么样的。这里,我们只列出了变更后的 bar 函数代码,其他函数代码并没有改变,代码如下:
package main
import "fmt"
func foo() {
println("call foo")
bar()
println("exit foo")
}
// func bar() {
// println("call bar")
// panic("panic occurs in bar")
// zoo()
// println("exit bar")
// }
func bar() {
defer func() {
if e := recover(); e != nil {
fmt.Println("recover the panic:", e)
}
}()
println("call bar")
panic("panic occurs in bar")
zoo()
println("exit bar")
}
func zoo() {
println("call zoo")
println("exit zoo")
}
func main() {
println("call main")
foo()
println("exit main")
}
在更新版的 bar 函数中,我们在一个 defer 匿名函数中调用 recover 函数对 panic 进行了捕捉。recover 是 Go 内置的专门用于恢复 panic 的函数,它必须被放在一个 defer 函数中才能生效。如果 recover 捕捉到 panic,它就会返回以 panic 的具体内容为错误上下文信息的错误值。如果没有 panic 发生,那么 recover 将返回 nil。而且,如果 panic 被 recover 捕捉到,panic 引发的 panicking 过程就会停止。
我们执行更新后的程序,得到如下结果:
call main
call foo
call bar
recover the panic: panic occurs in bar
exit foo
exit main
我们可以看到 main 函数终于得以“善终”。那这个过程中究竟发生了什么呢?
在更新后的代码中,当 bar 函数调用 panic 函数触发异常后,bar 函数的执行就会被中断。但这一次,在代码执行流回到 bar 函数调用者之前,bar 函数中的、在 panic 之前就已经被设置成功的 derfer 函数就会被执行。这个匿名函数会调用 recover 把刚刚触发的 panic 恢复,这样,panic 还没等沿着函数栈向上走,就被消除了。
所以,这个时候,从 foo 函数的视角来看,bar 函数与正常返回没有什么差别。foo 函数服务器托管网依旧继续向下执行,直至 main 函数成功返回。这样,这个程序的 panic“危机”就解除了。
面对有如此行为特点的 panic,我们应该如何应对呢?是不是在所有 Go 函数或方法中,我们都要用 defer 函数来捕捉和恢复 panic 呢?
三、如何应对 panic?
其实大可不必。一来,这样做会徒增开发人员函数实现时的心智负担。二来,很多函数非常简单,根本不会出现 panic 情况,我们增加 panic 捕获和恢复,反倒会增加函数的复杂性。同时,defer 函数也不是“免费”的,也有带来性能开销。
日常情况下,我们应该采取以下3点经验。
3.1 第一点:评估程序对 panic 的忍受度
首先,我们应该知道一个事实:不同应用对异常引起的程序崩溃退出的忍受度是不一样的。比如,一个单次运行于控制台窗口中的命令行交互类程序(CLI),和一个常驻内存的后端 HTTP 服务器程序,对异常崩溃的忍受度就是不同的。
前者即便因异常崩溃,对用户来说也仅仅是再重新运行一次而已。但后者一旦崩溃,就很可能导致整个网站停止服务。所以,针对各种应用对 panic 忍受度的差异,我们采取的应对 panic 的策略也应该有不同。像后端 HTTP 服务器程序这样的任务关键系统,我们就需要在特定位置捕捉并恢复 panic,以保证服务器整体的健壮度。在这方面,Go 标准库中的 http server 就是一个典型的代表。
Go 标准库提供的 http server 采用的是,每个客户端连接都使用一个单独的 Goroutine 进行处理的并发处理模型。也就是说,客户端一旦与 http server 连接成功,http server 就会为这个连接新创建一个 Goroutine,并在这 Goroutine 中执行对应连接(conn)的 serve 方法,来处理这条连接上的客户端请求。
前面提到了 panic 的“危害”时,我们说过,无论在哪个 Goroutine 中发生未被恢复的 panic,整个程序都将崩溃退出。所以,为了保证处理某一个客户端连接的 Goroutine 出现 panic 时,不影响到 http server 主 Goroutine 的运行,Go 标准库在 serve 方法中加入了对 panic 的捕捉与恢复,下面是 serve 方法的部分代码片段:
// $GOROOT/src/net/http/server.go
// Serve a new connection.
func (c *conn) serve(ctx context.Context) {
c.remoteAddr = c.rwc.RemoteAddr().String()
ctx = context.WithValue(ctx, LocalAddrContextKey, c.rwc.LocalAddr())
defer func() {
if err := recover(); err != nil && err != ErrAbortHandler {
const size = 64 可以看到,serve 方法在一开始处就设置了 defer 函数,并在该函数中捕捉并恢复了可能出现的 panic。这样,即便处理某个客户端连接的 Goroutine 出现 panic,处理其他连接 Goroutine 以及 http server 自身都不会受到影响。
这种局部不要影响整体的异常处理策略,在很多并发程序中都有应用。并且,捕捉和恢复 panic 的位置通常都在子 Goroutine 的起始处,这样设置可以捕捉到后面代码中可能出现的所有 panic,就像 serve 方法中那样。
3.2 第二点:提示潜在 bug
有了对 panic 忍受度的评估,panic 也没有那么“恐怖”,而且,我们甚至可以借助 panic 来帮助我们快速找到潜在 bug。
Go 语言标准库中并没有提供断言之类的辅助函数,但我们可以使用 panic,部分模拟断言对潜在 bug 的提示功能。比如,下面就是标准库 encoding/json包使用 panic 指示潜在 bug 的一个例子:
// $GOROOT/src/encoding/json/decode.go
... ...
//当一些本不该发生的事情导致我们结束处理时,phasePanicMsg将被用作panic消息
//它可以指示JSON解码器中的bug,或者
//在解码器执行时还有其他代码正在修改数据切片。
const phasePanicMsg = "JSON decoder out of sync - data changing underfoot?"
func (d *decodeState) init(data []byte) *decodeState {
d.data = data
d.off = 0
d.savedError = nil
if d.errorContext != nil {
d.errorContext.Struct = nil
// Reuse the allocated space for the FieldStack slice.
d.errorContext.FieldStack = d.errorContext.FieldStack[:0]
}
return d
}
func (d *decodeState) valueQuoted() interface{} {
switch d.opcode {
default:
panic(phasePanicMsg)
case scanBeginArray, scanBeginObject:
d.skip()
d.scanNext()
case scanBeginLiteral:
v := d.literalInterface()
switch v.(type) {
case nil, string:
return v
}
}
return unquotedValue{}
}
我们看到,在 valueQuoted 这个方法中,如果程序执行流进入了 default 分支,那这个方法就会引发 panic,这个 panic 会提示开发人员:这里很可能是一个 bug。
同样,在 json 包的 encode.go 中也有使用 panic 做潜在 bug 提示的例子:
// $GOROOT/src/encoding/json/encode.go
func (w *reflectWithString) resolve() error {
... ...
switch w.k.Kind() {
case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
w.ks = strconv.FormatInt(w.k.Int(), 10)
return nil
case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
w.ks = strconv.FormatUint(w.k.Uint(), 10)
return nil
}
panic("unexpected map key type")
}
这段代码中,resolve 方法的最后一行代码就相当于一个“代码逻辑不会走到这里”的断言。一旦触发“断言”,这很可能就是一个潜在 bug。
我们也看到,去掉这行代码并不会对 resolve 方法的逻辑造成任何影响,但真正出现问题时,开发人员就缺少了“断言”潜在 bug 提醒的辅助支持了。在 Go 标准库中,大多数 panic 的使用都是充当类似断言的作用的。
3.3 第三点:不要混淆异常与错误
在日常编码中,一些 Go 语言初学者,尤其是一些有过Python,Java等语言编程经验的程序员,会因为习惯了 Python 那种基于try–except 的错误处理思维,而将 Go panic 当成Python 的“checked exception”去用,这显然是混淆了 Go 中的异常与错误,这是 Go 错误处理的一种反模式。
查看Python 标准类库,我们可以看到一些 Java 已预定义好的 checked exception 类,比较常见的有ValueError、TypeError等等。看到这里,这些 checked exception 都是预定义好的、代表特定场景下的错误状态。
那 Python 的 checked exception 和 Go 中的 panic 有啥差别呢?
Python 的 checked exception 用于一些可预见的、常会发生的错误场景,比如,针对 checked exception 的所谓“异常处理”,就是针对这些场景的“错误处理预案”。也可以说对 checked exception 的使用、捕获、自定义等行为都是“有意而为之”的。
如果它非要和 Go 中的某种语法对应来看,它对应的也是 Go 的错误处理,也就是基于 error 值比较模型的错误处理。所以,Python 中对 checked exception 处理的本质是错误处理,虽然它的名字用了带有“异常”的字样。
而 Go 中的 panic 呢,更接近于 Python 的 RuntimeException,而不是 checked exception 。我们前面提到过 Python 的 checked exception 是必须要被上层代码处理的,也就是要么捕获处理,要么重新抛给更上层。但是在 Go 中,我们通常会导入大量第三方包,而对于这些第三方包 API 中是否会引发 panic ,我们是不知道的。
因此上层代码,也就是 API 调用者根本不会去逐一了解 API 是否会引发panic,也没有义务去处理引发的 panic。一旦你在编写的 API 中,像 checked exception 那样使用 panic 作为正常错误处理的手段,把引发的 panic 当作错误,那么你就会给你的 API 使用者带去大麻烦!因此,在 Go 中,作为 API 函数的作者,你一定不要将 panic 当作错误返回给 API 调用者。
四、defer 函数
在Go语言中,defer 是一种用于延迟执行函数或方法调用的机制。它通常用于执行清理操作、资源释放、日志记录等,以确保在函数返回之前进行这些操作。下面是有关 defer 函数的介绍和如何使用它来简化函数实现的内容:
4.1 defer 函数介绍
-
延迟执行:
defer允许将一个函数或方法调用推迟到当前函数返回之前执行,无论是正常返回还是由于panic引起的异常返回。 -
执行顺序:多个
defer语句按照后进先出(LIFO)的顺序执行,即最后一个注册的defer最先执行,倒数第二个注册的defer在其后执行,以此类推。 -
常见用途:
defer常用于资源管理,例如文件关闭、互斥锁的释放、数据库连接的关闭等,也用于执行一些必要的清理工作或日志记录。 -
不仅限于函数调用:
defer不仅可以用于函数调用,还可以用于方法调用,匿名函数的执行等。
4.2 使用 defer 简化函数实现
对函数设计来说,如何实现简洁的目标是一个大话题。你可以从通用的设计原则去谈,比如函数要遵守单一职责,职责单一的函数肯定要比担负多种职责的函数更简单。你也可以从函数实现的规模去谈,比如函数体的规模要小,尽量控制在 80 行代码之内等。
Go 中提供了defer可以帮助我们简化 Go 函数的设计和实现。我们用一个具体的例子来理解一下。日常开发中,我们经常会编写一些类似下面示例中的伪代码:
func doSomething() error {
var mu sync.Mutex
mu.Lock()
r1, err := OpenResource1()
if err != nil {
mu.Unlock()
return err
}
r2, err := OpenResource2()
if err != nil {
r1.Close()
mu.Unlock()
return err
}
r3, err := OpenResource3()
if err != nil {
r2.Close()
r1.Close()
mu.Unlock()
return err
}
// 使用r1,r2, r3
err = doWithResources()
if err != nil {
r3.Close()
r2.Close()
r1.Close()
mu.Unlock()
return err
}
r3.Close()
r2.Close()
r1.Close()
mu.Unlock()
return nil
}
我们看到,这类代码的特点就是在函数中会申请一些资源,并在函数退出前释放或关闭这些资源,比如这里的互斥锁 mu 以及资源 r1~r3 就是这样。
函数的实现需要确保,无论函数的执行流是按预期顺利进行,还是出现错误,这些资源在函数退出时都要被及时、正确地释放。为此,我们需要尤为关注函数中的错误处理,在错误处理时不能遗漏对资源的释放。
但这样的要求,就导致我们在进行资源释放,尤其是有多个资源需要释放的时候,比如上面示例那样,会大大增加开发人员的心智负担。同时当待释放的资源个数较多时,整个代码逻辑就会变得十分复杂,程序可读性、健壮性也会随之下降。但即便如此,如果函数实现中的某段代码逻辑抛出 panic,传统的错误处理机制依然没有办法捕获它并尝试从 panic 恢复。
Go 语言引入 defer 的初衷,就是解决这些问题。那么,defer 具体是怎么解决这些问题的呢?或者说,defer 具体的运作机制是怎样的呢?
defer 是 Go 语言提供的一种延迟调用机制,defer 的运作离不开函数。怎么理解呢?这句话至少有以下两点含义:
- 在 Go 中,只有在函数(和方法)内部才能使用 defer;
- defer 关键字后面只能接函数(或方法),这些函数被称为 deferred 函数。defer 将它们注册到其所在 Goroutine 中,用于存放 deferred 函数的栈数据结构中,这些 deferred 函数将在执行 defer 的函数退出前,按后进先出(LIFO)的顺序被程序调度执行(如下图所示)。
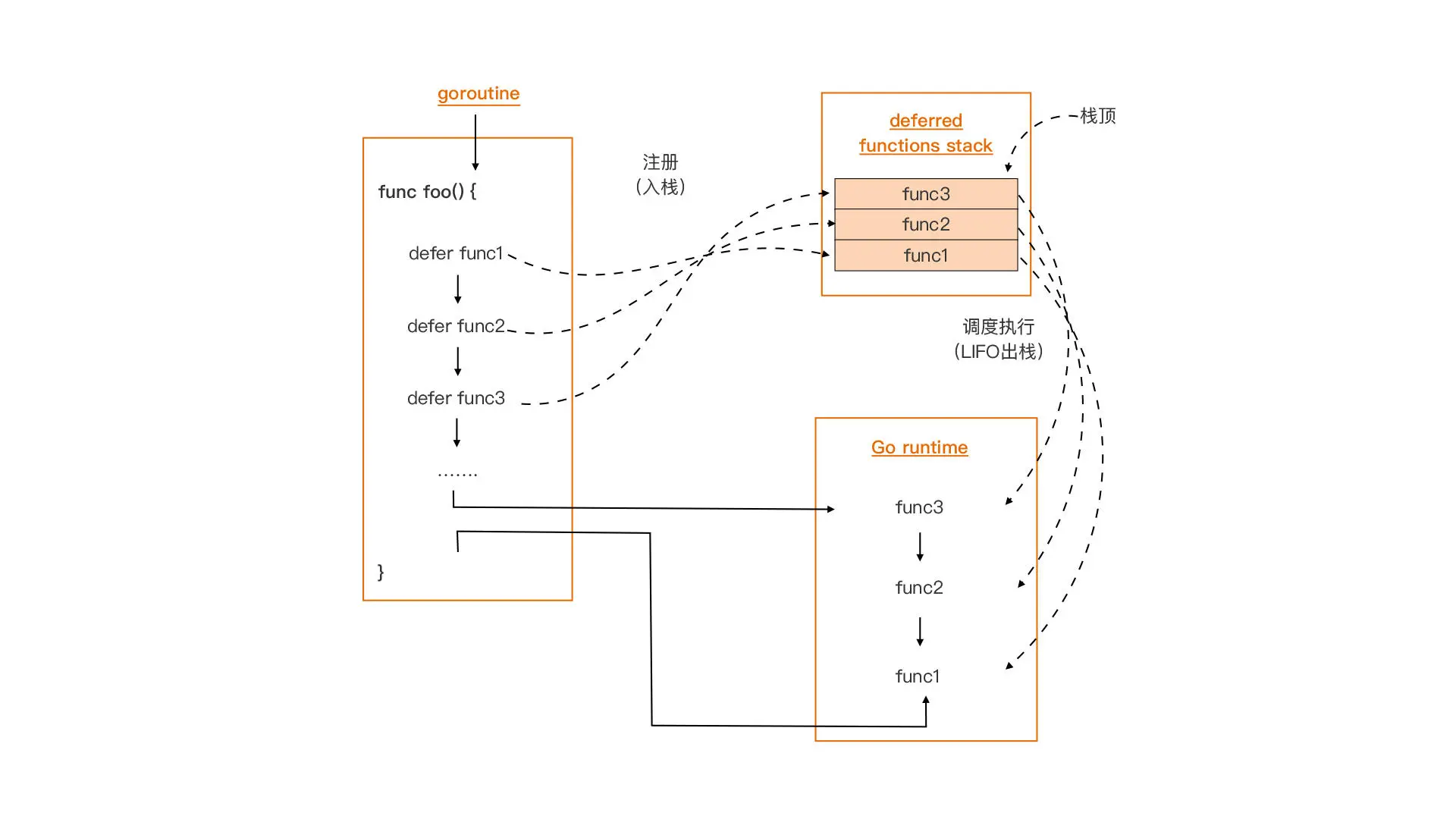
而且,无论是执行到函数体尾部返回,还是在某个错误处理分支显式 return,又或是出现 panic,已经存储到 deferred 函数栈中的函数,都会被调度执行。所以说,deferred 函数是一个可以在任何情况下为函数进行收尾工作的好“伙伴”。
我们回到刚才的那个例子,如果我们把收尾工作挪到 deferred 函数中,那么代码将变成如下这个样子:
func doSomething() error {
var mu sync.Mutex
mu.Lock()
defer mu.Unlock()
r1, err := OpenResource1()
if err != nil {
return err
}
defer r1.Close()
r2, err := OpenResource2()
if err != nil {
return err
}
defer r2.Close()
r3, err := OpenResource3()
if err != nil {
return err
}
defer r3.Close()
// 使用r1,r2, r3
return doWithResources()
}
我们看到,使用 defer 后对函数实现逻辑的简化是显而易见的。而且,这里资源释放函数的 defer 注册动作,紧邻着资源申请成功的动作,这样成对出现的惯例就极大降低了遗漏资源释放的可能性,我们开发人员也不用再小心翼翼地在每个错误处理分支中检查是否遗漏了某个资源的释放动作。同时,代码的简化也意味代码可读性的提高,以及代码健壮度的增强。
五、defer 使用的几个注意事项
大多数 Gopher 都喜欢 defer,因为它不仅可以用来捕捉和恢复 panic,还能让函数变得更简洁和健壮。但“工欲善其事,必先利其器“,一旦你要用 defer,有几个关于 defer 使用的注意事项是你一定要提前了解清楚的,可以避免掉进一些不必要的“坑”。
5.1 第一点:明确哪些函数可以作为 deferred 函数
这里,你要清楚,对于自定义的函数或方法,defer 可以给与无条件的支持,但是对于有返回值的自定义函数或方法,返回值会在 deferred 函数被调度执行的时候被自动丢弃。
而且,Go 语言中除了自定义函数 / 方法,还有 Go 语言内置的 / 预定义的函数,这里我给出了 Go 语言内置函数的完全列表:
Functions:
append cap close complex copy delete imag len
make new panic print println real recover
那么,Go 语言中的内置函数是否都能作为 deferred 函数呢?我们看下面的示例:
// defer1.go
func bar() (int, int) {
return 1, 2
}
func foo() {
var c chan int
var sl []int
var m = make(map[string]int, 10)
m["item1"] = 1
m["item2"] = 2
var a = complex(1.0, -1.4)
var sl1 []int
defer bar()
defer append(sl, 11)
defer cap(sl)
defer close(c)
defer complex(2, -2)
defer copy(sl1, sl)
defer delete(m, "item2")
defer imag(a)
defer len(sl)
defer make([]int, 10)
defer new(*int)
defer panic(1)
defer print("hello, defern")
defer println("hello, defer")
defer real(a)
defer recover()
}
func main() {
foo()
}
运行这个示例代码,我们可以得到:
$go run defer1.go
# command-line-arguments
./defer1.go:17:2: defer discards result of append(sl, 11)
./defer1.go:18:2: defer discards result of cap(sl)
./defer1.go:20:2: defer discards result of complex(2, -2)
./defer1.go:23:2: defer discards result of imag(a)
./defer1.go:24:2: defer discards result of len(sl)
./defer1.go:25:2: defer discards result of make([]int, 10)
./defer1.go:26:2: defer discards result of new(*int)
./defer1.go:30:2: defer discards result of real(a)
我们看到,Go 编译器居然给出一组错误提示!
从这组错误提示中我们可以看到,append、cap、len、make、new、imag 等内置函数都是不能直接作为 deferred 函数的,而 close、copy、delete、print、recover 等内置函数则可以直接被 defer 设置为 deferred 函数。
不过,对于那些不能直接作为 deferred 函数的内置函数,我们可以使用一个包裹它的匿名函数来间接满足要求,以 append 为例是这样的:
defer func() {
_ = append(sl, 11)
}()
5.2 第二点:注意 defer 关键字后面表达式的求值时机
这里,一定要牢记一点:defer 关键字后面的表达式,是在将 deferred 函数注册到 deferred 函数栈的时候进行求值的。
我们同样用一个典型的例子来说明一下 defer 后表达式的求值时机:
func foo1() {
for i := 0; i 这里,我们一个个分析 foo1、foo2 和 foo3 中 defer 后的表达式的求值时机。
首先是 foo1。foo1 中 defer 后面直接用的是 fmt.Println 函数,每当 defer 将 fmt.Println 注册到 deferred 函数栈的时候,都会对 Println 后面的参数进行求值。根据上述代码逻辑,依次压入 deferred 函数栈的函数是:
fmt.Println(0)
fmt.Println(1)
fmt.Println(2)
fmt.Println(3)
因此,当 foo1 返回后,deferred 函数被调度执行时,上述压入栈的 deferred 函数将以 LIFO 次序出栈执行,这时的输出的结果为:
3
2
1
0
然后我们再看 foo2。foo2 中 defer 后面接的是一个带有一个参数的匿名函数。每当 defer 将匿名函数注册到 deferred 函数栈的时候,都会对该匿名函数的参数进行求值。根据上述代码逻辑,依次压入 deferred 函数栈的函数是:
func(0)
func(1)
func(2)
func(3)
因此,当 foo2 返回后,deferred 函数被调度执行时,上述压入栈的 deferred 函数将以 LIFO 次序出栈执行,因此输出的结果为:
3
2
1
0
最后我们来看 foo3。foo3 中 defer 后面接的是一个不带参数的匿名函数。根据上述代码逻辑,依次压入 deferred 函数栈的函数是:
func()
func()
func()
func()
所以,当 foo3 返回后,deferred 函数被调度执行时,上述压入栈的 deferred 函数将以 LIFO 次序出栈执行。匿名函数会以闭包的方式访问外围函数的变量 i,并通过 Println 输出 i 的值,此时 i 的值为 4,因此 foo3 的输出结果为:
4
4
4
4
通过这些例子,我们可以看到,无论以何种形式将函数注册到 defer 中,deferred 函数的参数值都是在注册的时候进行求值的。
5.3 第三点:知晓 defer 带来的性能损耗
通过前面的分析,我们可以看到,defer 让我们进行资源释放(如文件描述符、锁)的过程变得优雅很多,也不易出错。但在性能敏感的应用中,defer 带来的性能负担也是我们必须要知晓和权衡的问题。
这里,我们用一个性能基准测试(Benchmark),直观地看看 defer 究竟会带来多少性能损耗。基于 Go 工具链,我们可以很方便地为 Go 源码写一个性能基准测试,只需将代码放在以“_test.go”为后缀的源文件中,然后利用 testing 包提供的“框架”就可以了,我们看下面代码:
// defer_test.go
package main
import "testing"
func sum(max int) int {
total := 0
for i := 0; i 这个基准测试包含了两个测试用例,分别是 BenchmarkFooWithDefer 和 BenchmarkFooWithoutDefer。前者测量的是带有 defer 的函数执行的性能,后者测量的是不带有 defer 的函数的执行的性能。
在 Go 1.13 前的版本中,defer 带来的开销还是很大的。我们先用 Go 1.12.7 版本来运行一下上述基准测试,我们会得到如下结果:
$go test -bench . defer_test.go
goos: darwin
goarch: amd64
BenchmarkFooWithDefer-8 30000000 42.6 ns/op
BenchmarkFooWithoutDefer-8 300000000 5.44 ns/op
PASS
ok command-line-arguments 3.511s
从这个基准测试结果中,我们可以清晰地看到:使用 defer 的函数的执行时间是没有使用 defer 函数的 8 倍左右。
如果我们要用好 defer,前提就是要了解 defer 的运作机制,这里你要把握住两点:
- 函数返回前,deferred 函数是按照后入先出(LIFO)的顺序执行的;
- defer 关键字是在注册函数时对函数的参数进行求值的。
最后,在最新 Go 版本 Go1.17 中,使用 defer 带来的开销几乎可以忽略不计了,你可以放心使用。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
实际工作中很多时候需要将多个文件中的内容合并到一个文件中。这里分享一个实现方法。 import os def merge_file(source_dir,target_file): data_dir=source_dir contents=[] for fil…
