
首先准备好三台服务器或者虚拟机,我本机安装了三个虚拟机,安装虚拟机的步骤参考我之前的一篇
virtualBox虚拟机安装多个+主机访问虚拟机+虚拟机访问外网配置-CSDN博客

jdk安装
参考文档:Linux 环境下安装JDK1.8并配置环境变量_linux安装jdk1.8并配置环境变量_Xi-Yuan的博客-CSDN博客
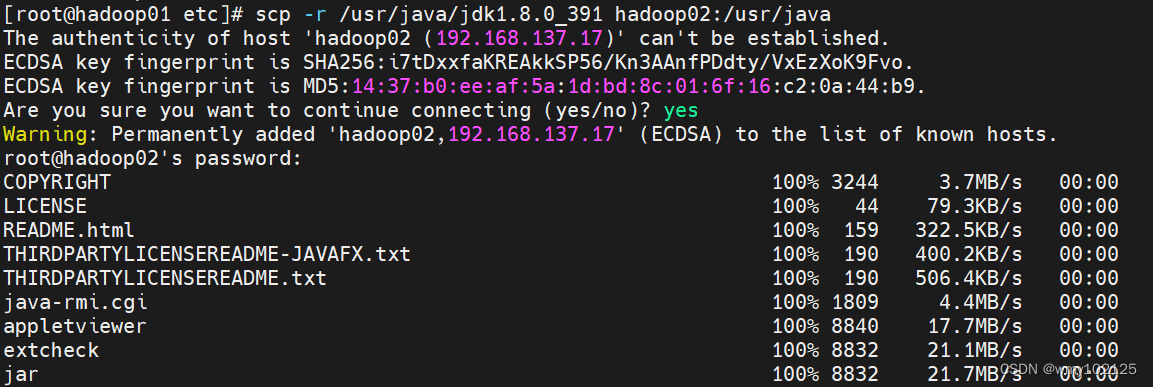
一台机器配置完成jdk之后,我们将已经解压完成的jdk分发到另外两台虚拟机上
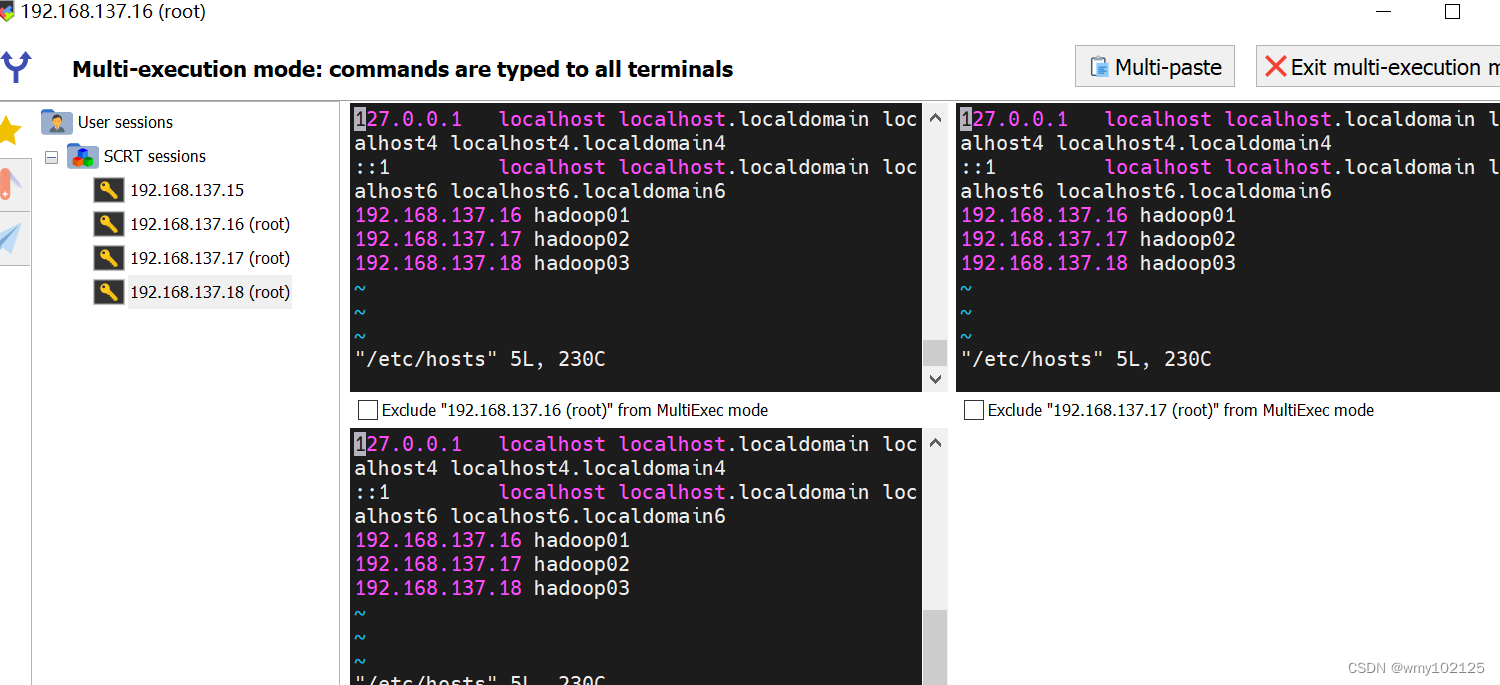
我们的hosts中ip和域名没有映射
或者通过ip分发,不用配置域名映射了
scp -r /usr/java/jdk1.8.0_391 192.168.137.16:/usr/java
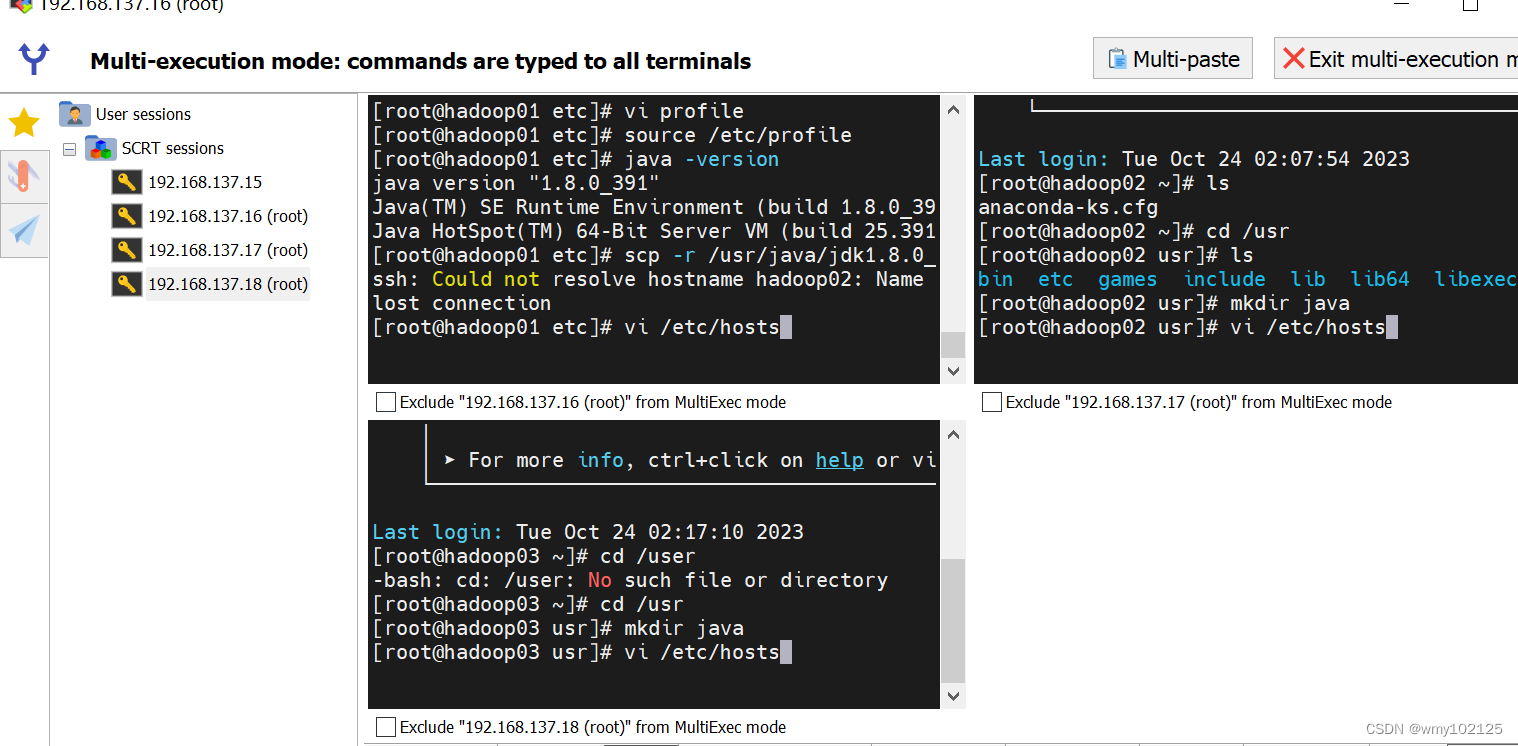
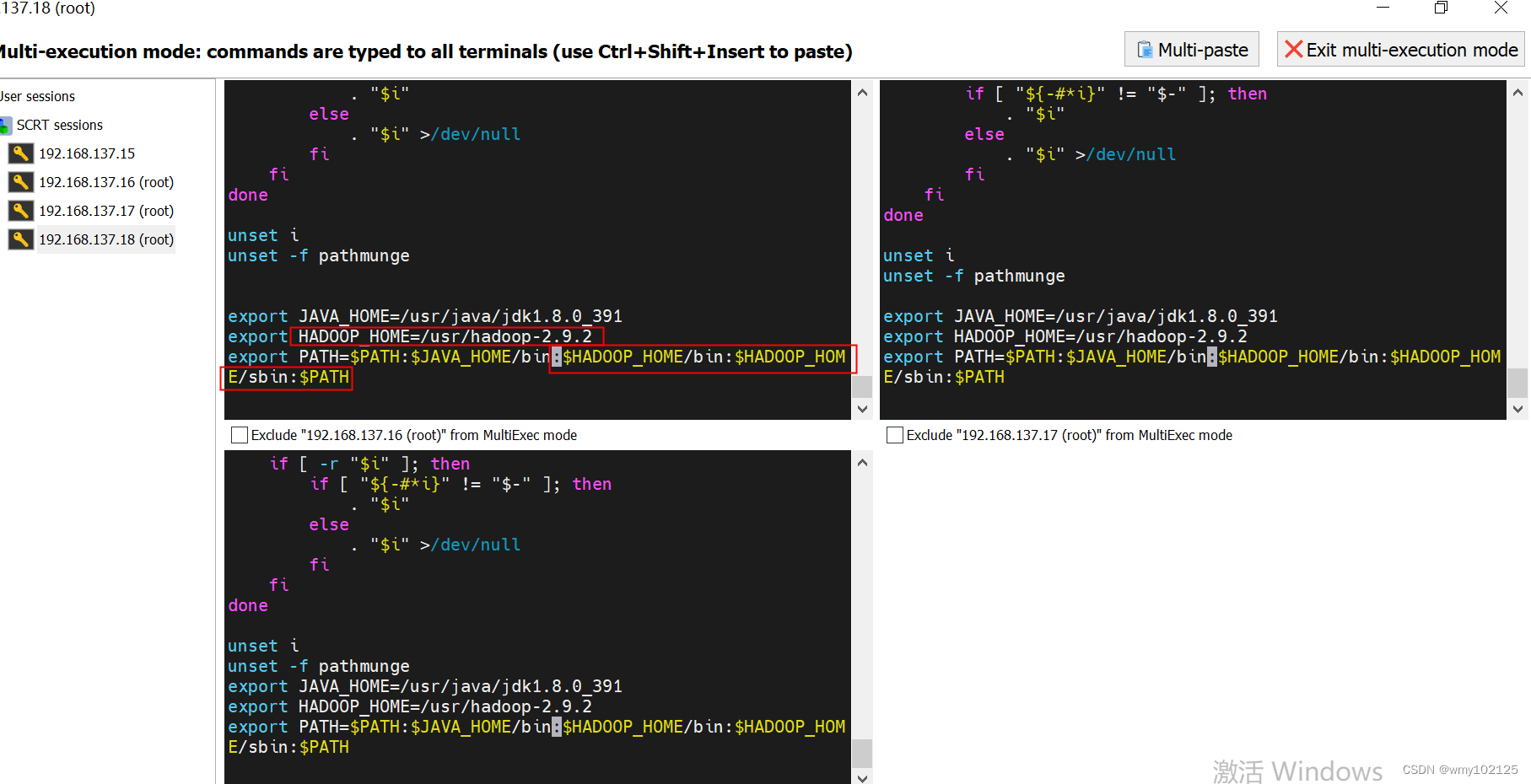
hosts配置,点击多屏同时编辑
vi /etc/hosts
scp -r /usr/java/jdk1.8.0_391 hadoop02:/usr/java
分发完成之后记得其它两台机器的java配置一下
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_391
export PATH=$PATH:$JAVA_HOME/binsource /etc/profile

hadoop包提前下载好,官网的下载速度实在太慢,我的下载地址如下:
We Transfer Gratuit. Envoi scuris de gros fichiers. (sw服务器托管网isstransfer.com)
解压缩到/usr目录下
tar -zxvfhadoop-2.9.2.tar.gz -C /usr
hadoop配置工作
cd /usr/hadoop-2.9.2/etc/hadoop
vi hadoop-env.sh
更改如下配置
JAVA_HOME=/usr/java/jdk1.8.0_391
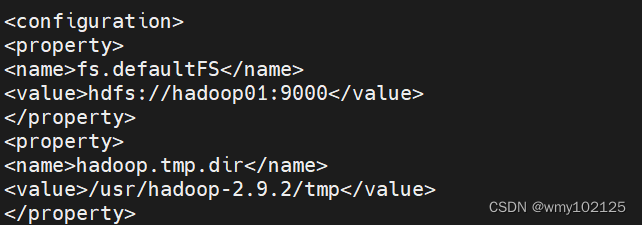
vi core-site.xml
fs.defaultFS
hdfs://hadoop01:9000hadoop.tmp.dir
/usr/hadoop-2.9.2/tmp
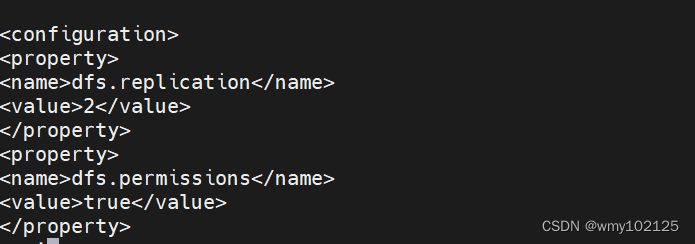
vi hdfs-site.xml
dfs.replication
2dfs.permissions
true
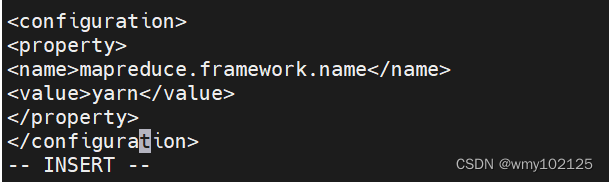
mv mapred-site.xml.template mapred-site.xml
vimapred-site.xml
mapreduce.framework.name
yarn
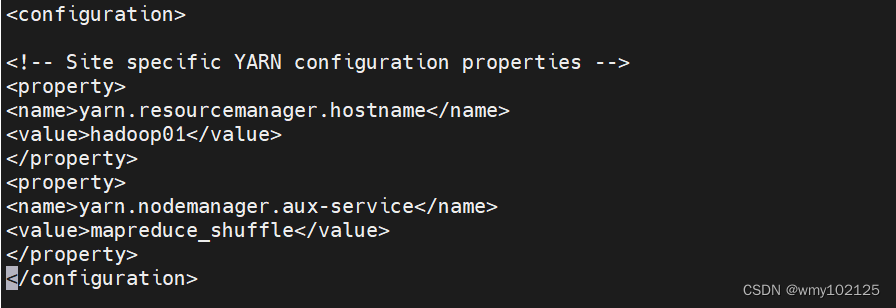
vi yarn-site.xml
yarn.resourcemanager.hostname
hadoop01yarn.nodemanager.aux-service
mapreduce_shuffle
vi slaves
删除已有的localhost
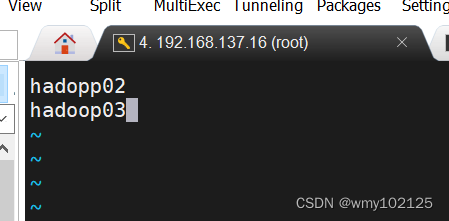
添加从节点域名
hadoop02
hadoop03
将hadoop01虚拟机上hadoop的文件分发到其它两台虚拟机
scp -r /usr/hadoop-2.9.2 hadoop02:/usr
scp -r /usr/hadoop-2.9.2 hadoop03:/usr

hadoop启动
#HADDOOP_HOME配置
source /ect/profile
#初始化
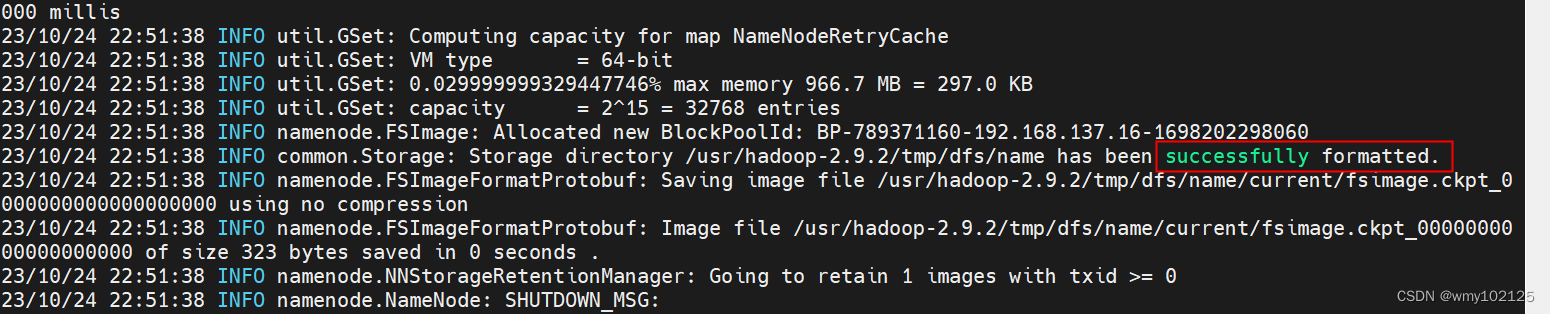
hdfs namenode -format
#一键启动之前配置好免密登录功能,否则启动和停止时需要n次输入密码
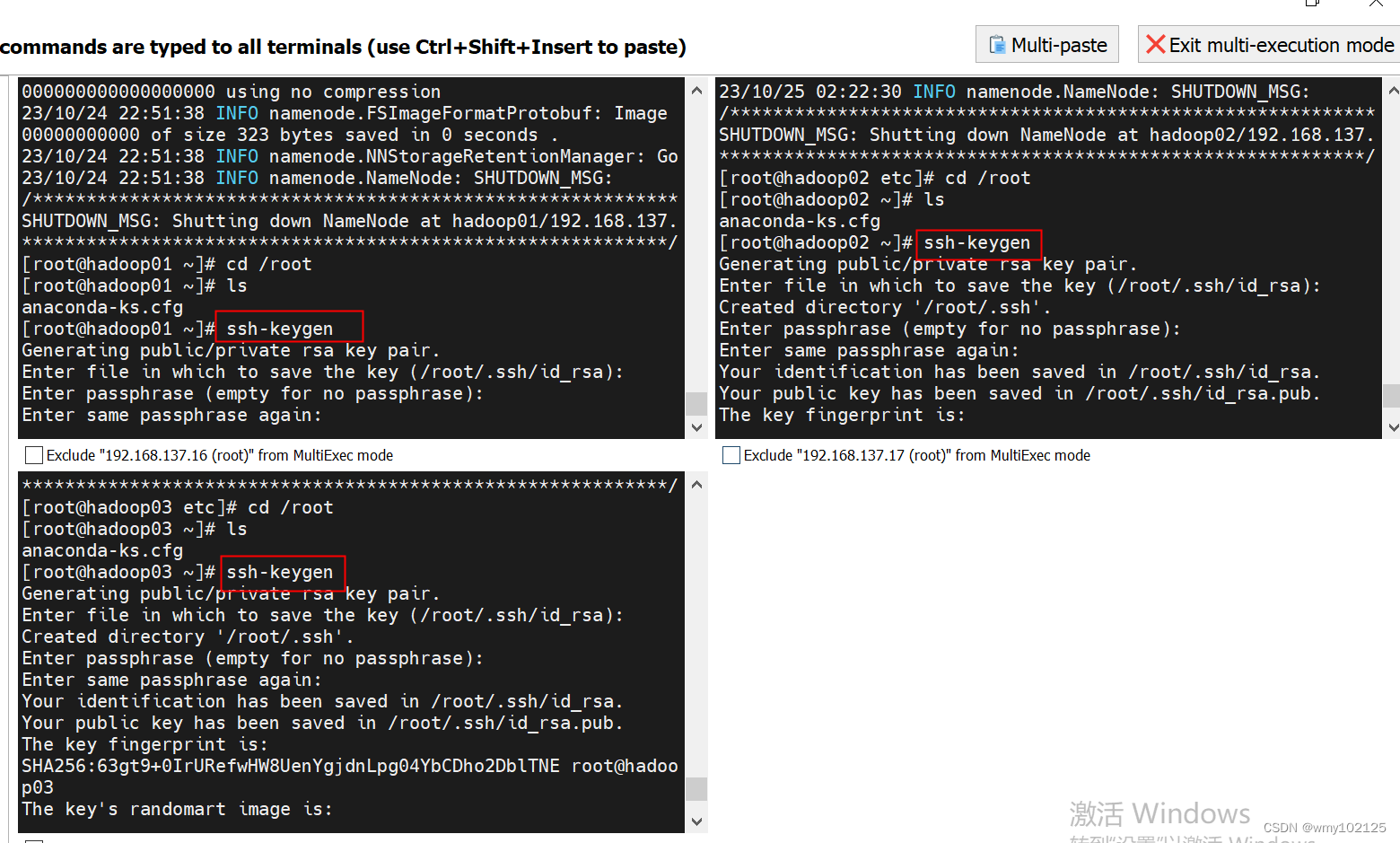
cd /root
ssh-keygen
遇到需要输入的直接回车即可
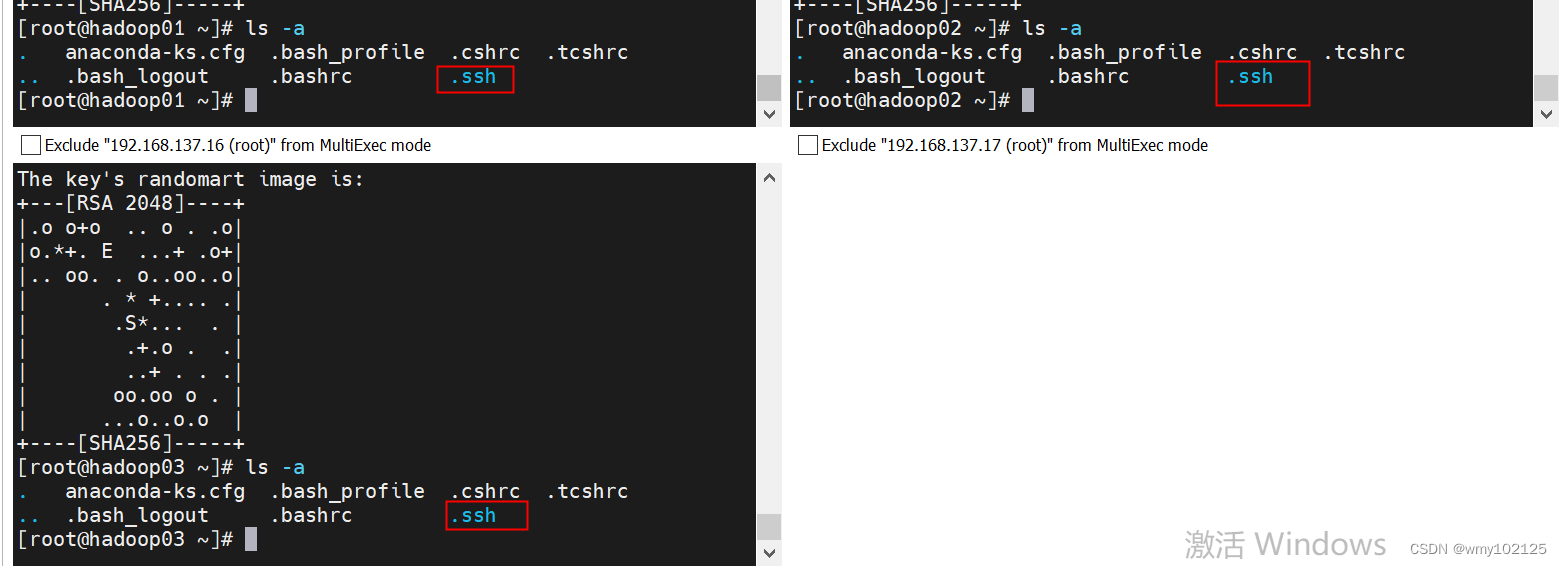
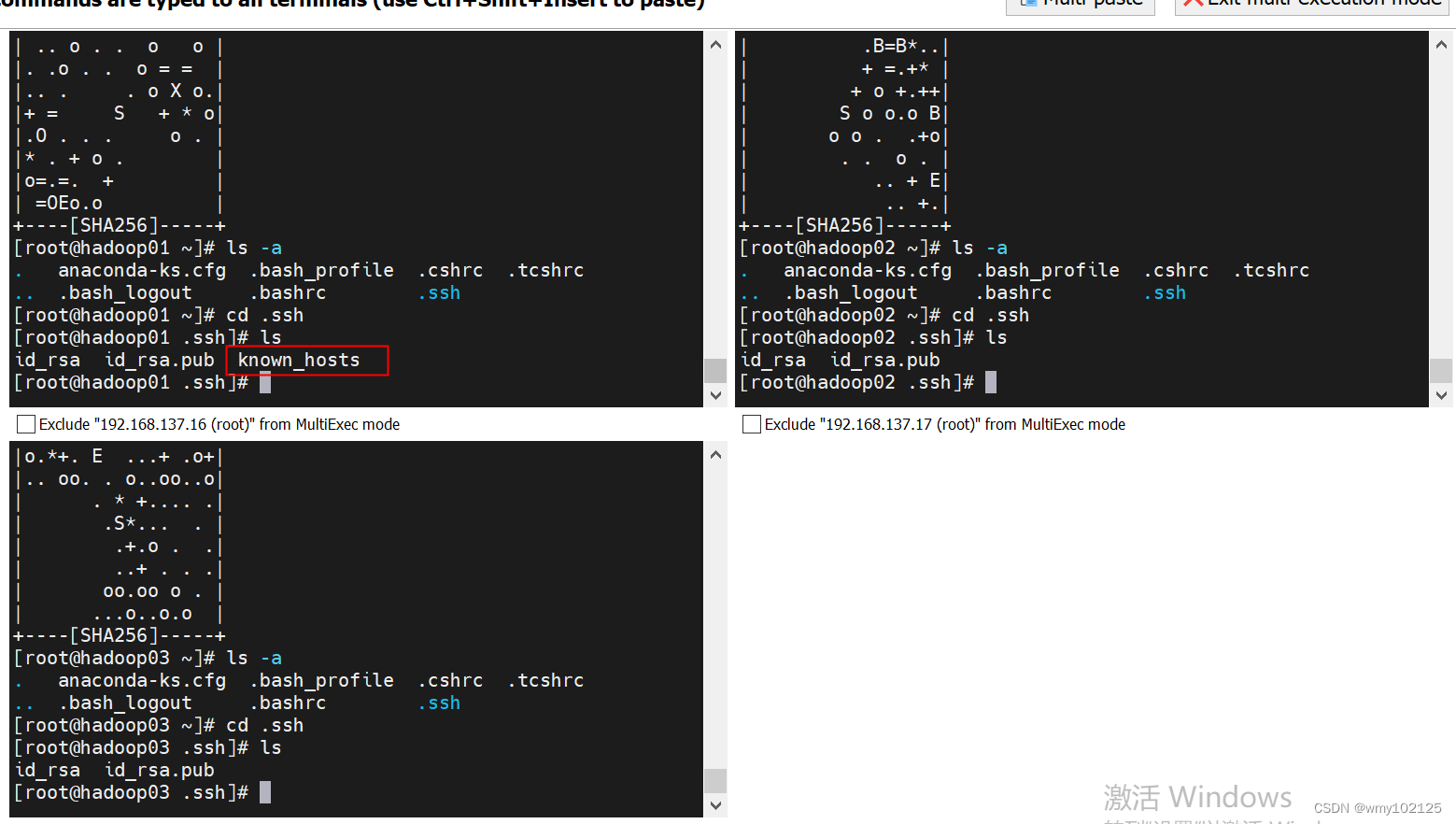
#查看.ssh目录是否服务器托管网已经生成
第一台机器有known_hosts,因为我们之前在第一台虚拟机上scp -r分发过文件给其他两台机器,所以建立过ssh连接,查看known_hosts
现在还没有应用出去
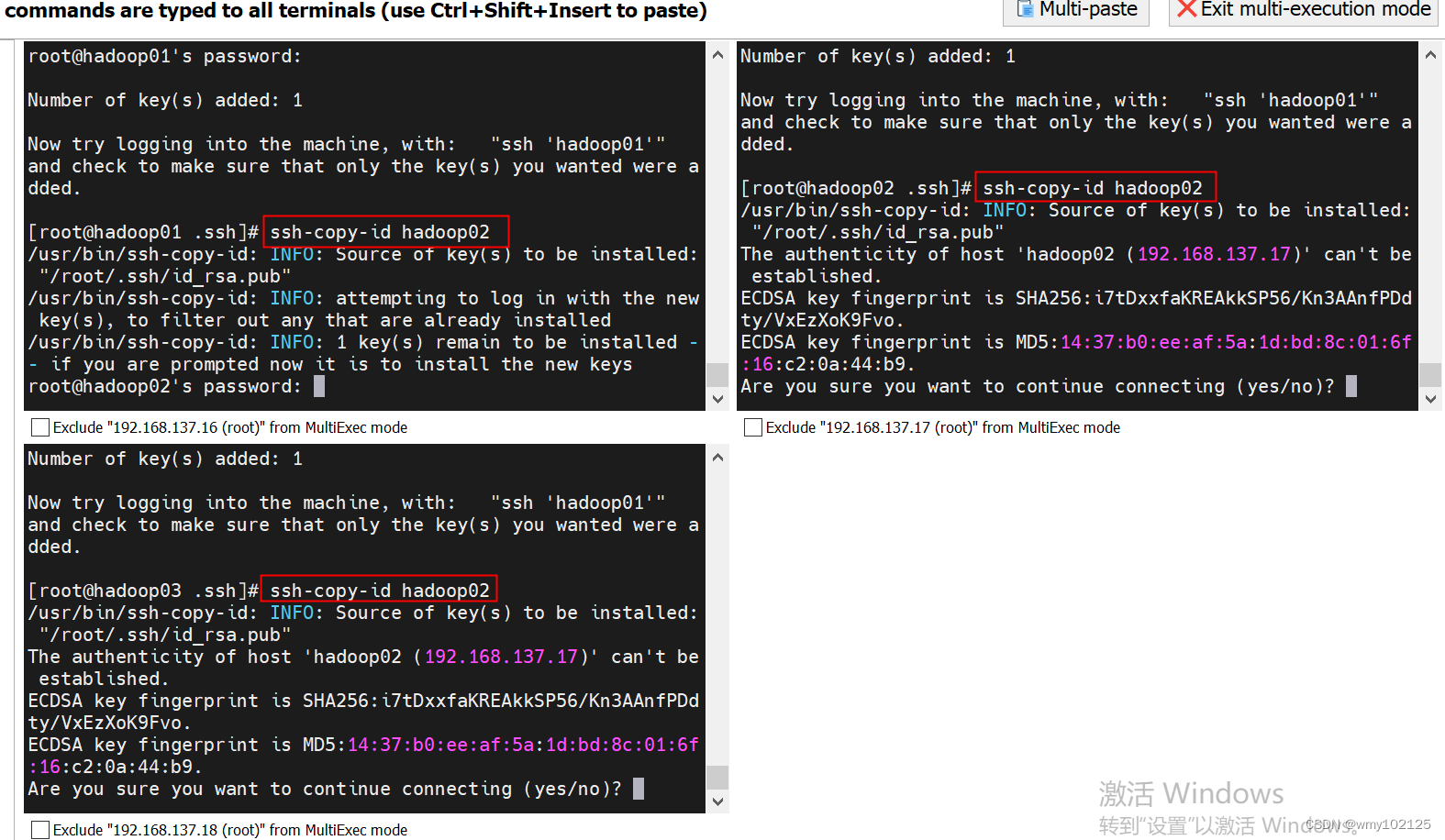
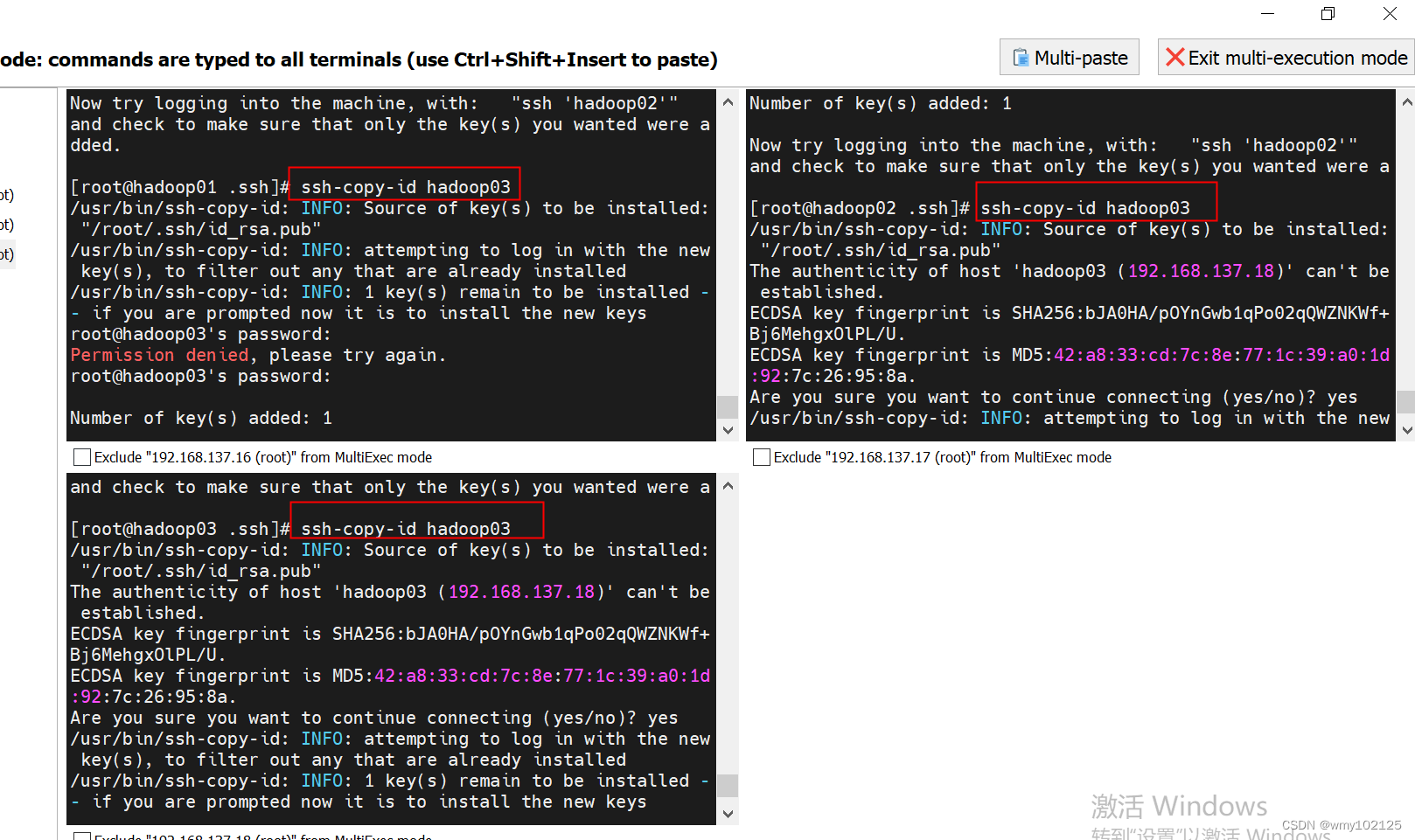
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
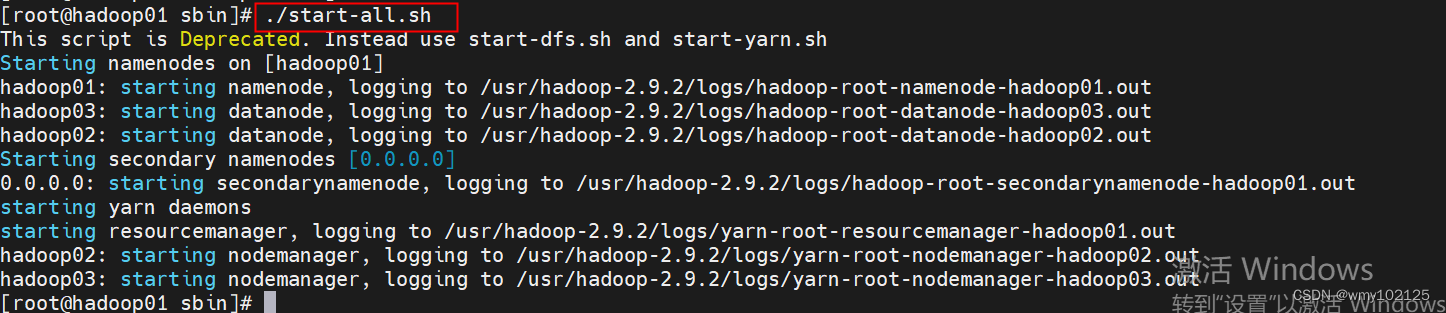
#一键启动,只在hadoop01机器上一键启动即可
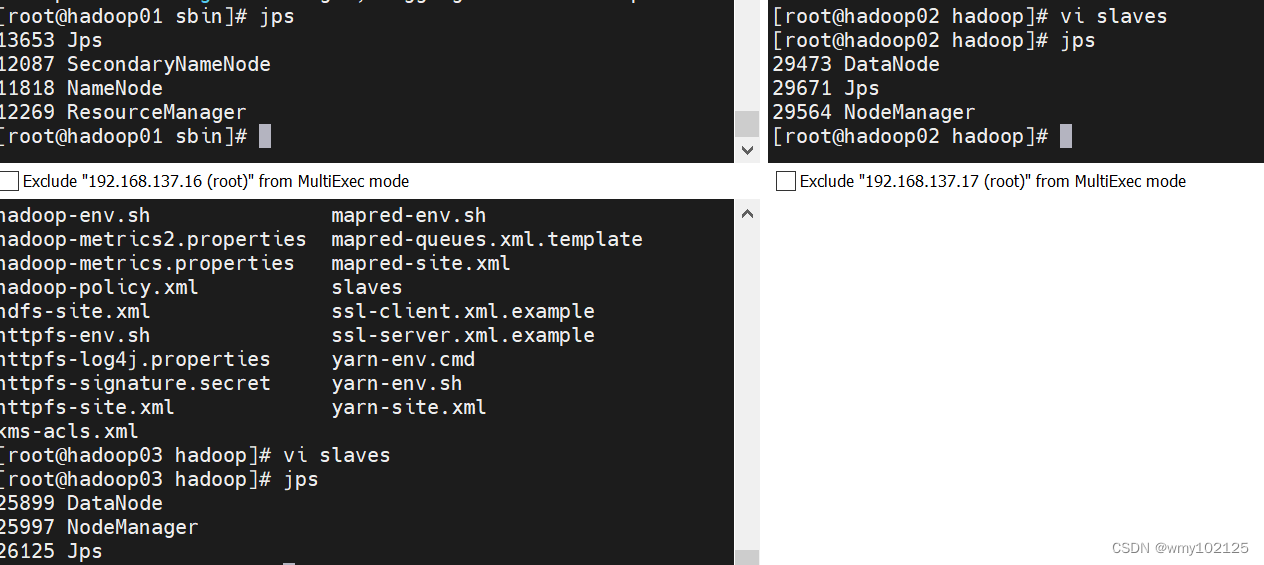
#jps查看已经启动起来的服务
至此hadoop分布式搭建完成


hadoop集群的web端访问
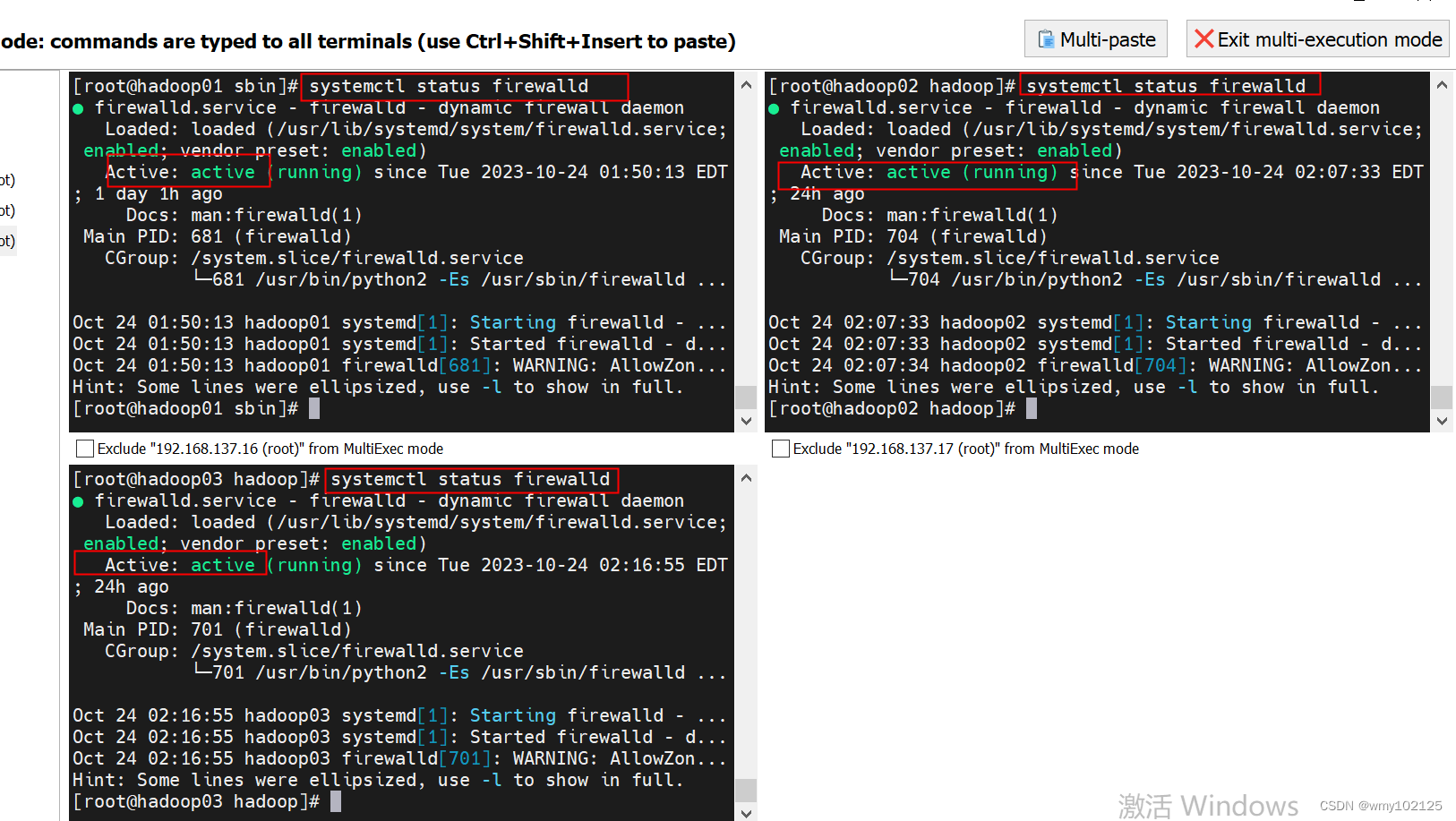
#关闭防火墙
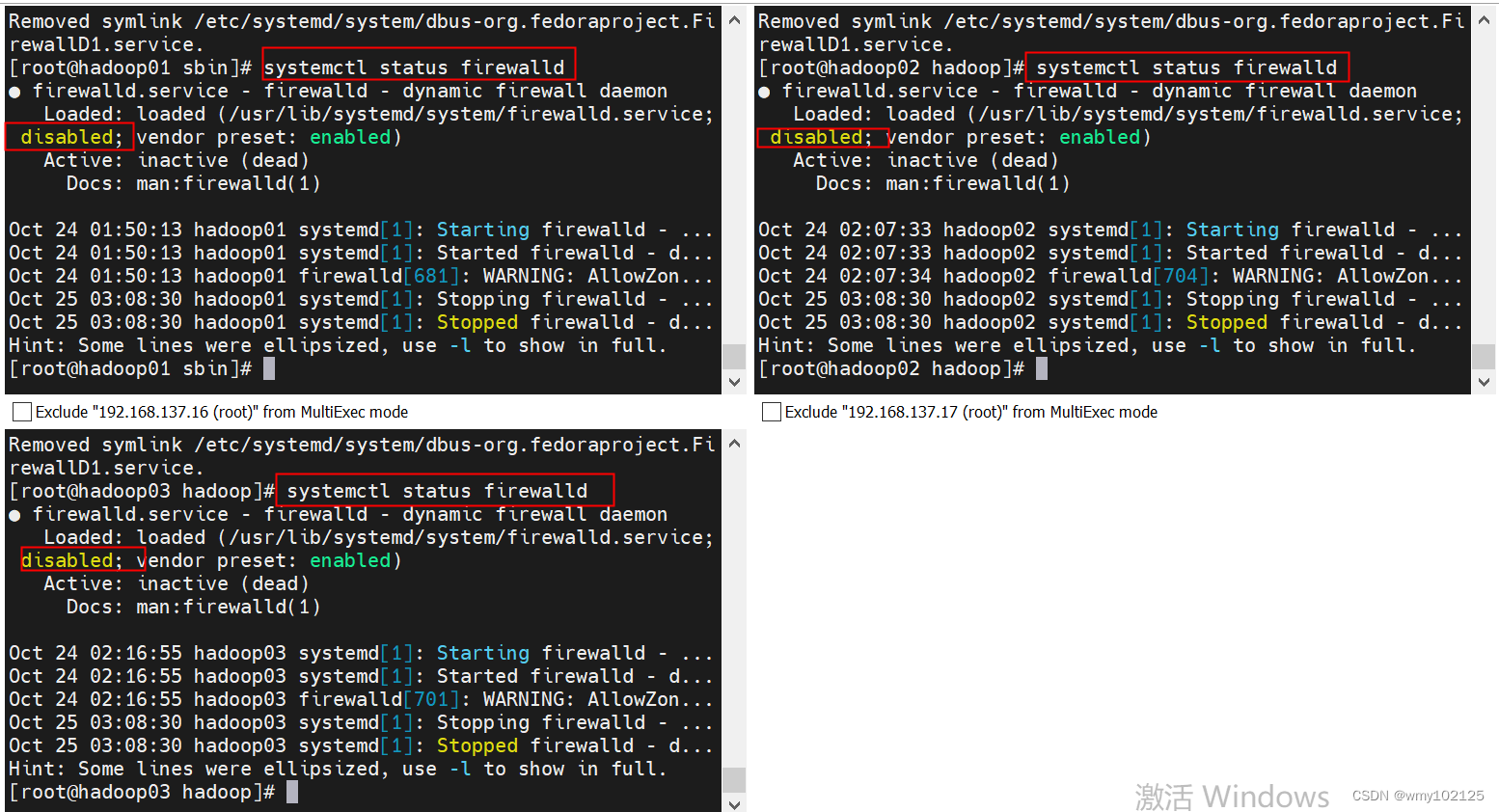
查看当前防火墙状态:systemctl status firewalld
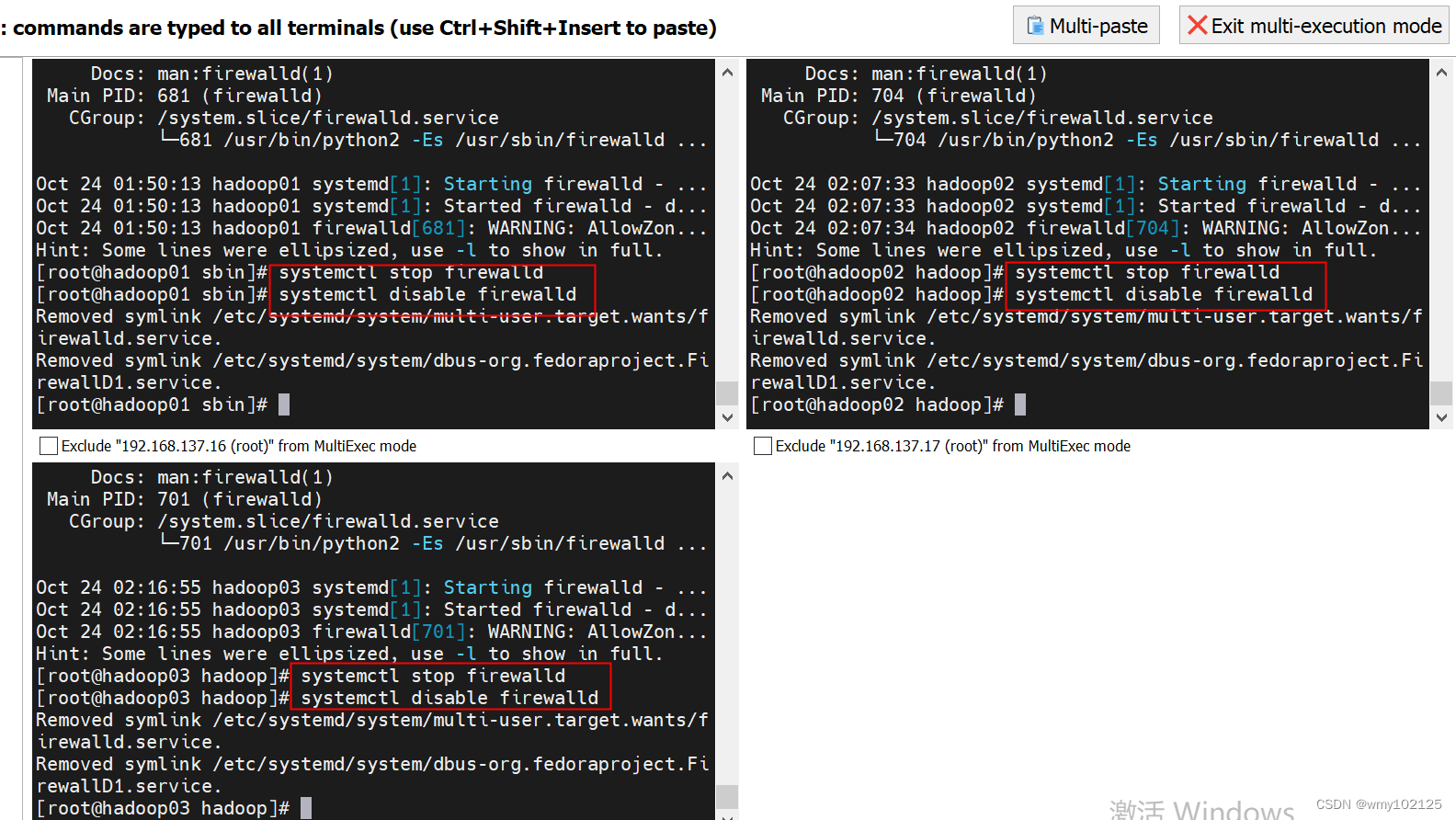
临时关闭防火墙:systemctl stop firewalld
永久关闭防火墙:systemctl disable firewalld
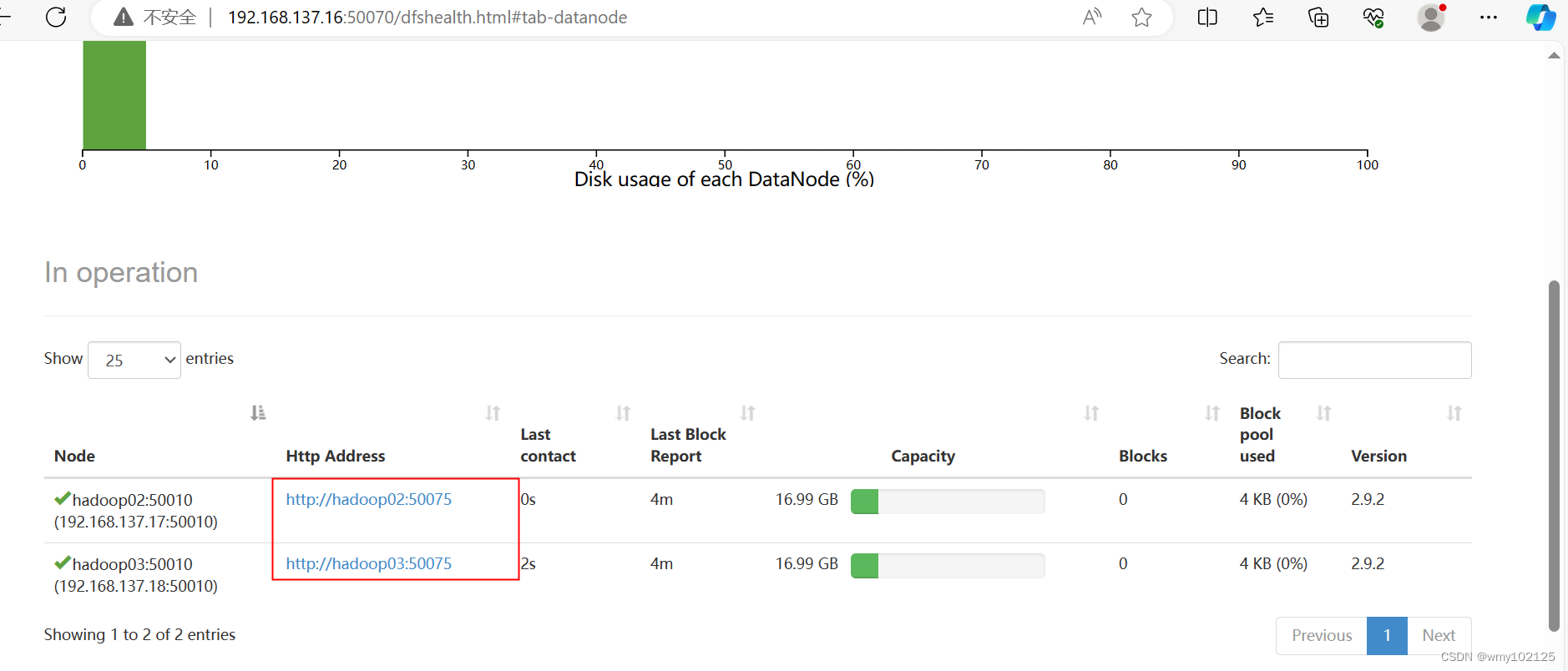
#HDFS web页面访问
第一台虚拟机ip
http://192.168.137.16:50070/
可以看到其他两个节点
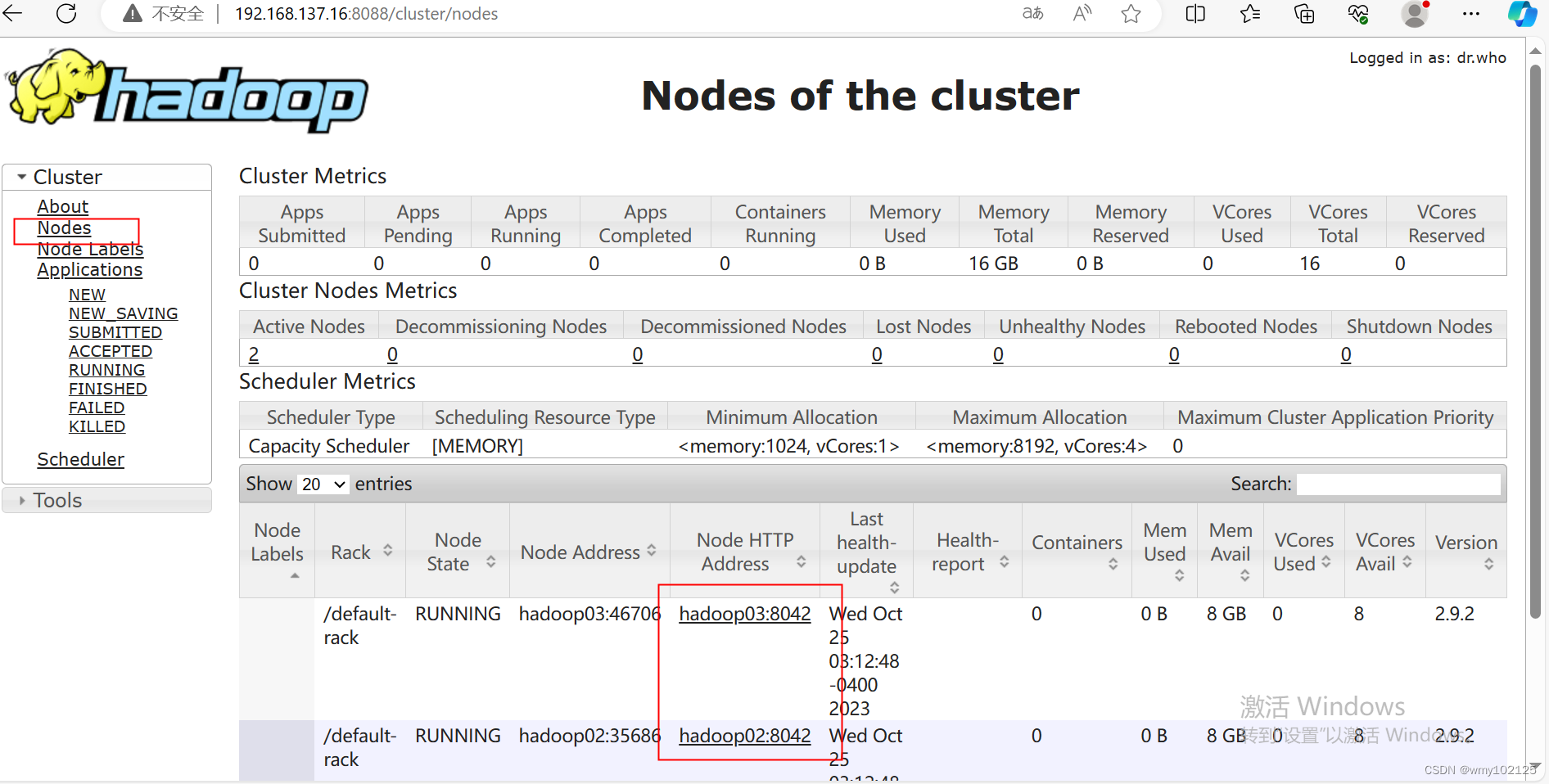
yarn集群web页面
http://192.168.137.16:8088/
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
