
文章目录
-
-
- 小文件归档 HAR
- 小文件优化 Uber 模式
-
小文件归档 HAR
小文件归档是指将大量小文件合并成较大的文件,从而减少存储开销、元数据管理的开销以及处理时的任务调度开销。
这里我们通过 Hadoop Archive (HAR) 来进行实现,它是一种归档格式,可以将多个小文件和目录归档成单个 HAR 文件。
在进行下面的操作前,请先启动集群。
对小文件进行归档
当前,在 /input 目录下存储了 3 个小文件,如下所示:
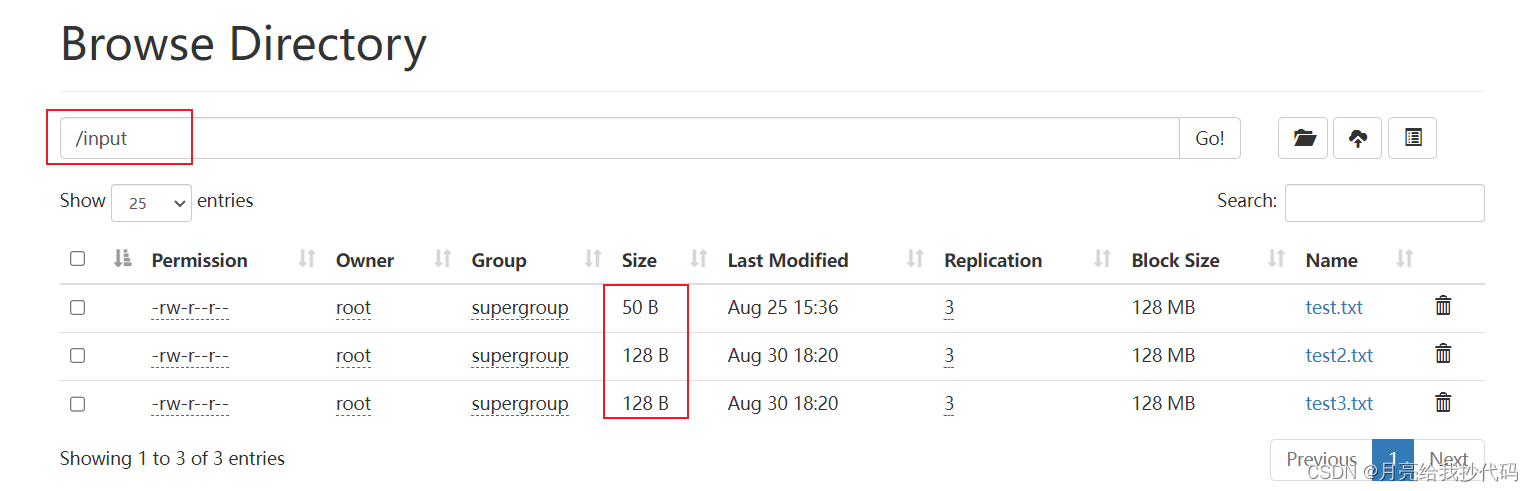
现在我们对这三个文件进行归档,命令如下:
hadoop archive -archiveName input.har -p /input /result
这里将目录 /input 下的所有文件都进行归档,并保存在 /result 目录下,取名为 input.har。
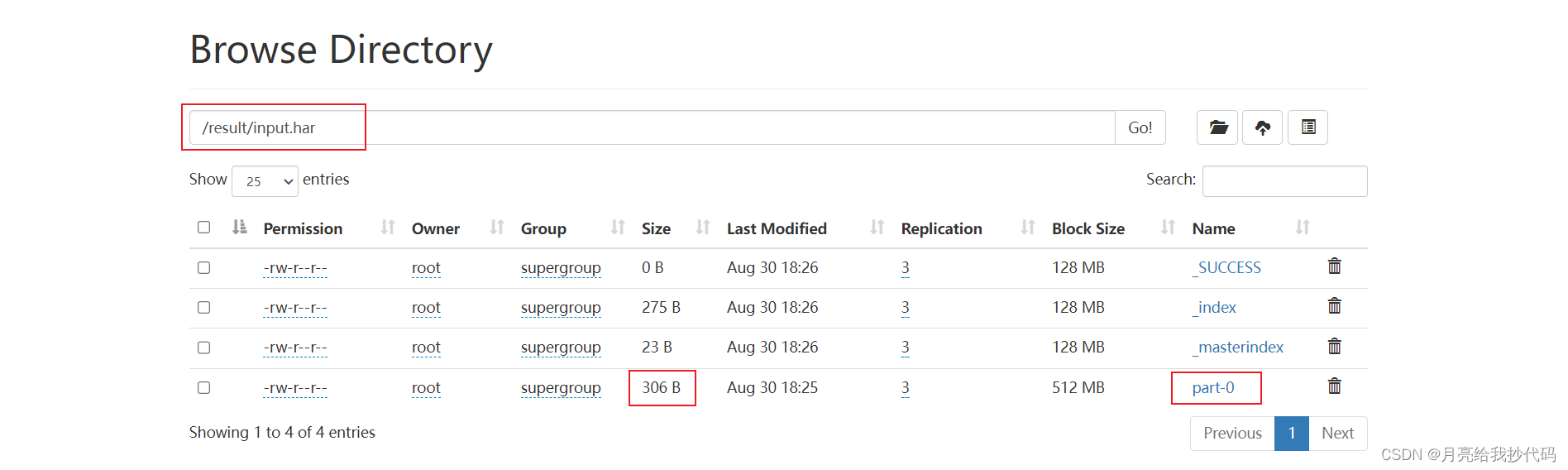
进入归档结果目录中,可以发现归档文件的目录结构,其中 part-0 中存储的就是真正的文件内容,它包含了三个文件的所有内容;其余的文件都是归档相关的文件记录信息。
查看已经归档的文件
hadoop fs -ls har:///result/input.har

解档文件
hadoop fs -cp har:///result/input.har/* /
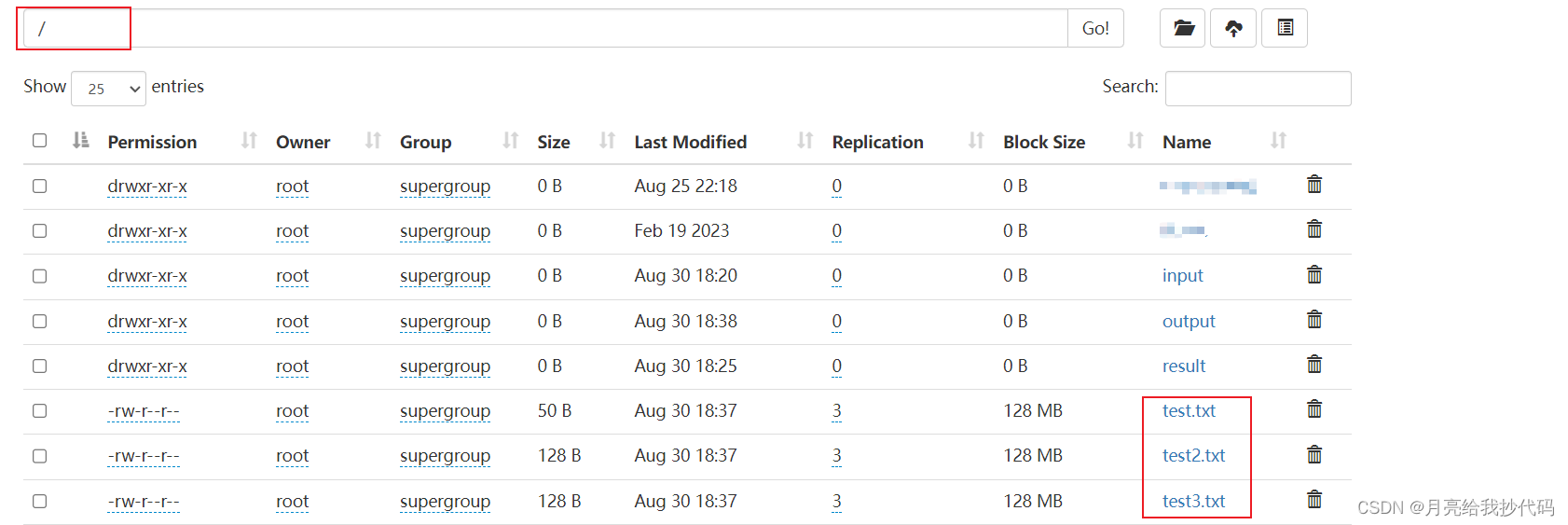
注意,解档指定的目录必须提前创建。
小文件优化 Uber 模式
什么是 Uber 模式?
“Uber 模式” 是指在 Hadoop 中运行 MapReduce 任务时,将所有的任务(Mapper 和 Reducer)都运行在一个单独的 JVM 进程中,而不是在集群的不同节点上分别启动多个 JVM 进程来运行任务。
这个模式的名称来自于 Uber 公司,他们在其 Hadoop 集群上采用了这种方式来运行任务。
优点
-
减少资源开销: Uber 模式可以减少任务启动的开销,因为不需要为每个任务都启动一个单独的 JVM 进程,这样可以节省内存和CPU资源。
-
提高局部性: 由于所有任务在同一个 JVM 中运行,数据的局部性更高,因为不需要在不同节点之间传输数据。
-
避免任务调度开销: 在分布式环境中,任务的调度也会带来一定的开销,Uber 模式可以避免这些开销,从而提高任务的执行效率。
缺点
-
单点故障: 如果运行任务的 JVM 发生故障,所有的任务都会受到影响,而不是像分布式模式下那样只影响一个节点上的任务。
-
资源限制: 由于所有任务共享一个 JVM,可能会受到 JVM 内存限制的影响,特别是对于需要大量内存的任务。
-
性能不适用于所有场景: Uber 模式在某些情况下可能会导致性能下降,特别是当任务需要大量的并行计算时,由于共享一个 JVM,可能无法充分利用多核处理器。
当开启 Uber 模式后,Hadoop 会根据一定的规则和条件来自动判断是否使用 Uber 模式运行任务,还是使用分布式模式。
Uber 模式的配置
编辑 Hadoop 中的 mapred-site.xml 配置文件,添加下列内容:
property>
name>mapreduce.job.ubertask.enablename>
value>truevalue>
property>
property>
name>mapreduce.job.ubertask.maxmapsname>
value>9value>
property>
property>
name>mapreduce.job.ubertask.maxreducesname>
value>1value>
property>
property>
name>mapreduce.job.ubertask.maxbytesname>
value>value>
property>
分发文件同步配置到其它机器,无需重启集群。
测试
当前,在 /input 目录下存储了 3 个小文件,如下所示:
我们来运行 Hadoop 官方案例 wordcount 来测试 Uber 服务器托管网模式是否设置成功。
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
如果配置成功,在案例执行过程中会打印提示,正在使用 Uber 模式运行:

我们进入 Yarn 中查看案例运行记录:
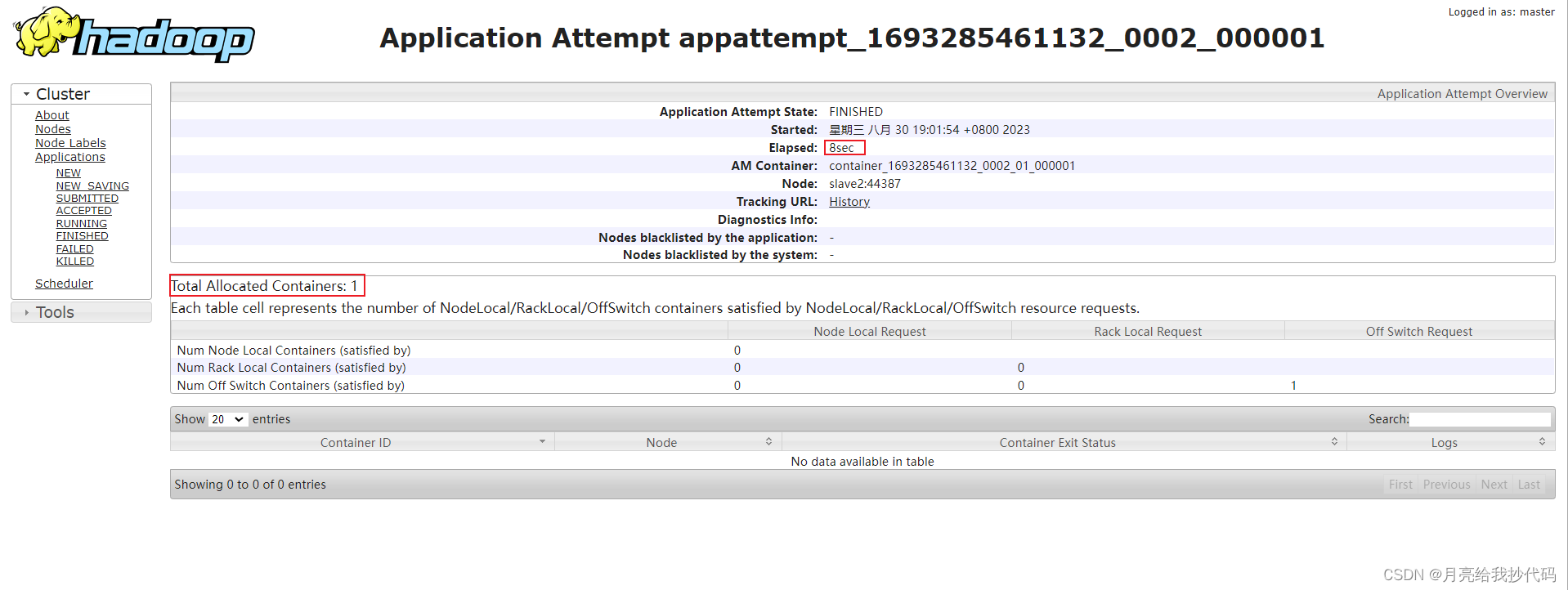
可以看到只启动了 1 个容器进行处理,并且只花费了 8 秒,读者可以关闭 Uber 模式来对比前后的速度差别。
未开启 Uber 模式执行效率
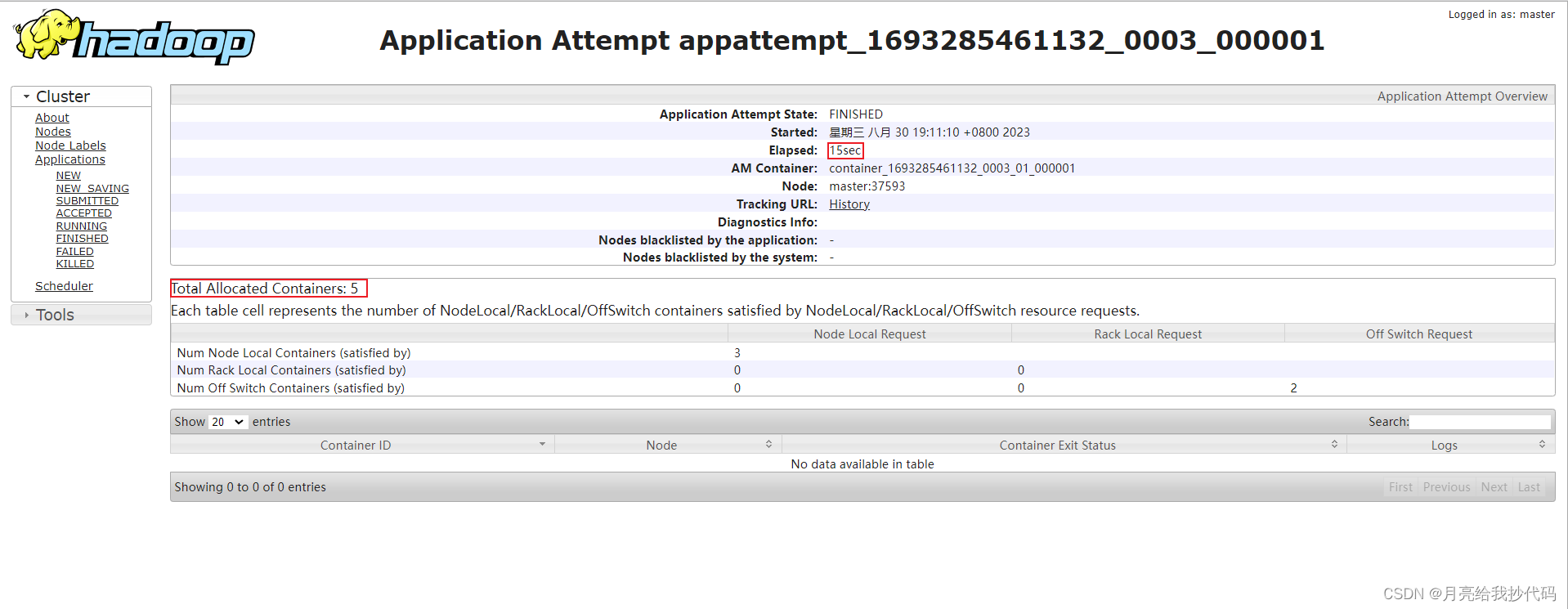
启动了 5 个容器进行处理,花费了 15 秒。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
