
文章目录
- (126)基础架构
- (127)YARN的工作机制
- (1服务器托管网28)作业全流程
- 参考文献
(126)基础架构
之前基本介绍完了Hadoop的几个核心组件,接下来可以思考下,在MR程序运行过程中,整个集群的资源是如何管理的,以及每个任务该分配多少资源才合适?
这就是YARN需要考虑的问题。
YARN是一个资源调度平台,负责为各个任务提供运行资源。可以简单理解成YARN是windows系统,而MR等程序就是运行在这个操作系统之上的应用进程。
YARN中的组件,包括ResourceManager、NodeManager、Container、ApplicationMaster等。
关于YARN的运行流程,我们之前在”概念”一节里也有简单介绍了。
如图:
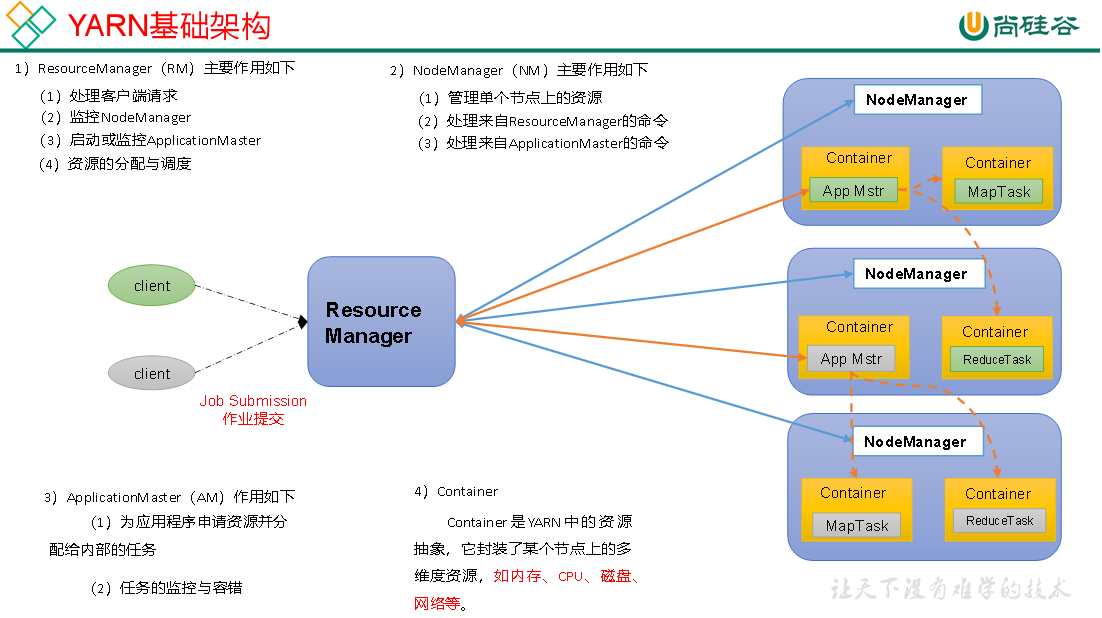
ResourceManager,整个YARN中最重要的组件,老大哥,领导角色,基本每个组件都会跟它做交互,负责:
- 接收、处理客户端传过来的请求(提交的作业);
- 监控NodeManager;
- 启动、监控ApplicationMaster(如果任务挂了,会协调切换到其他节点继续执行);
- 资源的分配与调度。
按我的理解,RM更多的是做的是整个集群的资源管理,一般不会实际落地去分配资源,具体的落地工作,都是由对应的NodeManager来实现的。
NodeManager,单个节点(一般是指单台服务器)上的老大,负责:
- 管理自己节点上的资源;
- 处理来自ResourceManage的命令(比如说RM告诉NM,需要从你的节点上运行个任务,那么NM就需要实际分配资源,来做配合);
- 处理来自ApplicationMaster的命令(如App Mstr要求申请资源)。
ApplicationMaster,是单个job的老大,负责:
- 为应用申请资源(向RM提申请),并分配给内部的任务;
- 对内部的任务,进行监控和容错。
Container,是YARN中对资源的一个抽象概念,它封装了某个节点上的多维度资源,如内存、CPU、磁盘和网络。如果要类比的话,相当于是每个节点上的一台台虚拟机?
(127)YARN的工作机制
即YARN在底层是怎么运行的,是面试中经常会被问到的一类面试题。
图形化展示下步骤:
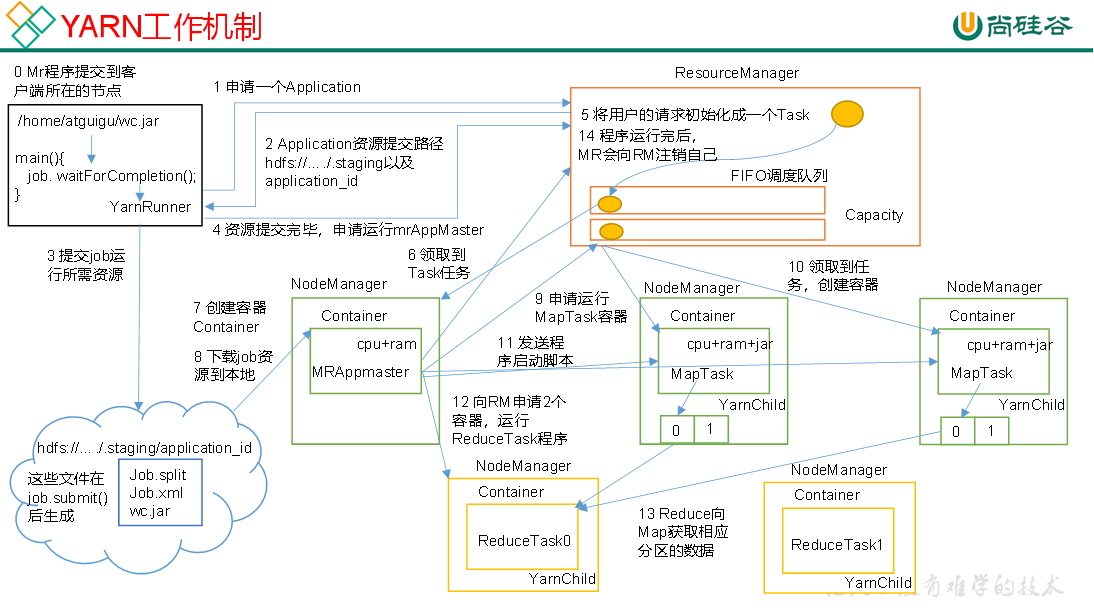
-
Mr程序首先被提交到客户端所在的节点,客户端会启动一个YarnRunner来做对内外的交互;
-
YarnRunner会向ResourceManager发出请求,申请一个Application,来执行自己的job;
-
接着RM确认可以创建Application之后,会把这个Application的id和资源提交路径等返回给客户端,告知其可以将资源提交至这个路径;
-
客户端的YarnRunner在接收到反馈后,就开始提交job运行所需的资源到指定路径,重点提交三个文件:
- job.split:即数据的切片文件,关系到后续的切片流程以及MapTask数量;
- job.xml:即任务执行的参数配置等
- xx.jar:即任务本身的程序代码
这些都会在job.submit()之后生成;
-
资源提交完毕后,客户端向RM提出申请,申请运行对应的ApplicationMaster;
-
RM接收到申请,然后将申请初始化成一个Task,放进自己的调度队列里,如FIFO调度队列;
-
当一个Task可以被调度时(即资源允许),RM会根据情况,选择一个NodeManager,将Task分配给它;
-
NM收到任务,会在自己内部创建一个Container,分配好资源,来执行这个Task。接着,Container内部会再启动一个MrAppMaster,来管理整个任务,或者说整个job的运行。
-
MrAppMaster会去当前job的资源路径,去读取切片信息,即job.split,下载到节点本地;
-
拿到切片后,MrAppMaster会再向RM申请,申请资源来运行MapTask。RM会将申请先放进队列,等调度到的时候,就会去挑选并通知对应的NodeManager们,准备分配资源来做MapTask;
-
对应的NodeManager接收到通知,然后在自己内部创建好对应的Container;
-
MrAppMaster直接发送程序的启动脚本给刚创建好的Container们,让它们启动MapTask,开始正式运行代码,这个过程里,每个MapTask会生成一个YarnChild,负责对外的交流;待MapTask执行完,数据会按照分区持久化到磁盘;
-
待MapTask执行完后,MrAppMaster会再向RM申请几个Container,来运行ReduceTask。流程跟刚才介绍的MapTask启动基本一致,开启Container、启动ReduceTask、启动YarnChild等;
-
ReduceTask启动后,会向MapTask里去获取对应分区的数据;
-
ReduceTask执行完后,标志着整个MR基本运行完成,MrAppMaster会向RM提出申请,任务完成,请求注销掉自己,并回收资源等;
-
RM接收申请,并开始收尾工作。
(128)作业全流程
主要讲解下,HDFS、YARN、MapReduce三者的关系。
HDFS里有DataNode、NameNode和SecondaryNameNode,其中DataNode用来存储,NameNode则是用来管理DataNode的,比如说记录DataNode的一些元数据等。至于SecondNameNode,是辅助NameNode工作的。
然后YARN的话,是有一个ResourceManage,负责管理全局的资源,一至多个NodeManager用来管理单节点的资源。
教程里没有详细展开说,我只做个简单总结吧。
还是以服务器托管网上一节YARN的工作流程为例,那里清晰展示了YARN跟MapReduce的交互,至于HDFS在哪儿起作用,其实也好理解,HDFS就可以简单理解成磁盘。
比如说第3步里,client需要提交资源至指定的路径,其实就是提交到HDFS的路径下。另外,每个MapTask启动之后要去资源路径拿数据,其实也是跟HDFS的DataNode交互的过程。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: The server time zone value ‘�й���ʱ��’ is unrecognized 错误详解
今天搭建一个SpringBoot 环境出现 “The server time zone value ‘������’ “错误 首先,先把大家的问题解决了,将JDBC连接的URL修改为如下: jdbc:mysql://127.0.0.1:3306/DBName?…
