
以下内容所需要的环境 :hive 、beeline、Zeppelin(可视化界面如何操作表格)
一、准备表格
1、上传csv表格至linux目录中
百度网盘自取:链接:https://pan.baidu.com/s/1xd5MdXiBDLBUtP07kpgl5Q?pwd=2ema
提取码:2ema
2.、登录Zeppelin
启动命令:zeppelin-daemon.sh start
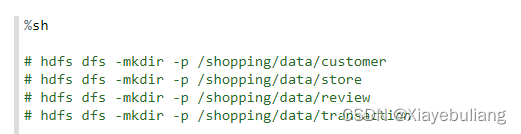
2.1、创建一个新的New Note ,使用命令创建hdfs对应表格文件夹
2.2、将表格上传到hdfs对应文件夹内

3、创建数据库,创建表格
小技巧:可以通过head命令查看文件表格的表头,便于创建表格元数据
tblproperties (“skip.header.line.count”=“1”) 是设置在读取文件插入数据时跳过文件的第一行
tblproperties (“skip.footer.line.count”=”2”) t跳过行尾两行
[root@reagan180 storetransaction]# head -n 1 ./customer_details.csv
customer_id,first_name,last_name,email,gender,address,country,language,job,credit_type,credit_no
root@reagan180 storetransaction]# head -n 1 ./transaction_details.csv
transaction_id,customer_id,store_id,price,product,date,time

创建 ext_customer_details表
create external table if not exists ext_customer_details(
customer_id string,
first_name string,
last_name string,
email string,
gender string,
address string,
country string,
language string,
job string,
credit_type string,
credit_no string )
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
location '/shopping/data/customer'
tblproperties('skip.header.line.count'='1');创建 ext_transaction_details表
create external table if not exists ext_transaction_details
(
transaction_id string,
customer_id string,
store_id string,
price decimal(8, 2),
product string,
purchase_date string,
purchase_time string
) row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
location '/shopping/data/transaction'
tblproperties ('skip.header.line.count' = '1');
创建 ext_store_details表
create external table if not exists ext_store_details(
store_id string,
store_name string,
employee_number int
) row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
location '/shopping/data/store'
tblproperties ('skip.header.line.count' = '1');创建 ext_store_revie
create external table if not exists ext_store_review(
transaction_id string,
store_id string,
review_score int
) row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
location '/shopping/data/review'
tblproperties ('skip.header.line.count' = '1');二、数据清洗
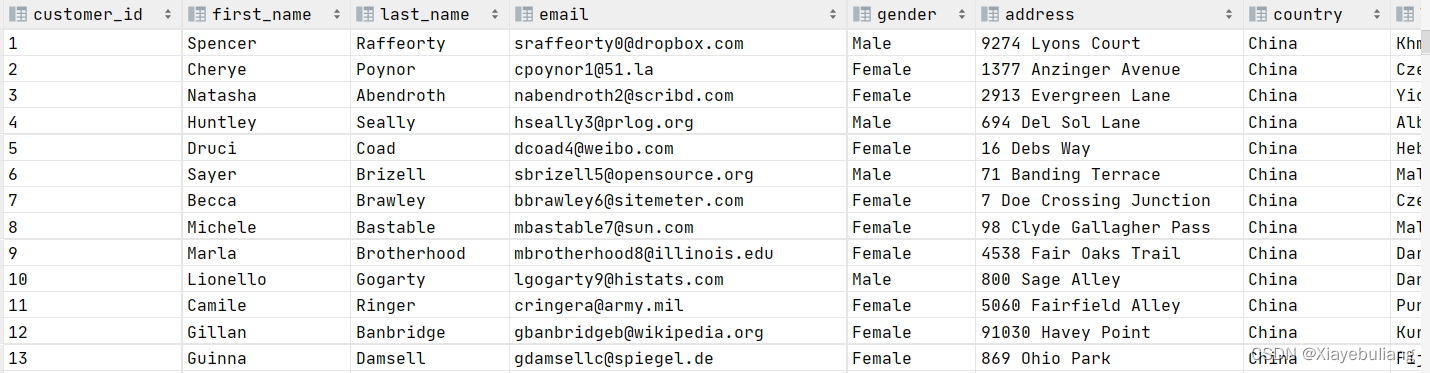
2.1 、敏感词一次加密和二次加密(可以采用试图创建另一个表)
drop view if exists vw_customer_details;
create view if not exists vw_customer_details as
select
customer_id,first_name,unbase64(last_name) as last_name,
unbase64(email) as email, gender,unbase64(address) as address,
country,job,credit_type,
unbase64(concat(unbase64(credit_no),'hello')) as credit_no
from ext_customer_details;加密前:
加密后:
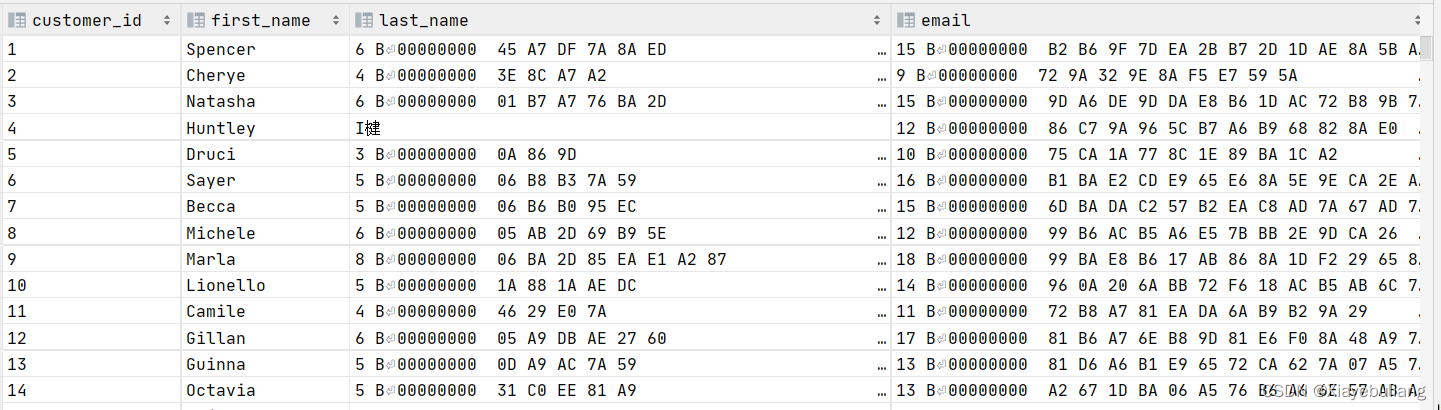
2.2、 对ext_transaction_details表中的重复数据生成新ID
with
basetb as (select row_number()over(partition by transaction_id) as rn,
transaction_id,customer_id,store_id,price,product,purchase_date,purchase_time,
substr(purchase_date,0,7) purchase_month from ext_transaction_details),
basetb2 as (select if(rn=1,transaction_id,concat(transaction_id,'_fix',rn)) transaction_id ,
customer_id,store_id,price,product,purchase_date,purchase_time,purchase_month from basetb)
select * from basetb2 where transaction_id like '%fix%' limit 100;
解析:主要依靠 窗口函数的排名函数并分组 和 if 语句
row_number()over(partition by transaction_id) as rnif(rn=1,transaction_id,concat(transaction_id,'_fix',rn))if 语句:如果排名为 1,为真则使用原来id,不为真则使用id+fix+排名;
2.3、 过滤掉store_review中没有评分的数据
create view if not exists vm_store_review as
select * from ext_store_review where review_score '';2.4 、可以把清洗好的数据放到另一个表或者用View表示
2.5、重新组织transaction数据按照日期YYYY-MM做分区
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
