
1、前言
HiveServer2 属于 Hive 组件的一个服务,主要提供 Hive 访问接口,例如可通过 JDBC 的方式提交 Hive 作业,HiveServer2 基于 Java 开发,整个服务运行过程中,内存的管理回收均由 JVM 进行控制。在 JVM 语言中的内存泄漏与 C/C++ 语言的内存泄漏会有些差异,JVM 的内存泄漏更多的是业务代码逻辑错误引起大量对象引用被持有,导致多次 GC 均无法被回收,或者部分对象占用内存过大,直接超过 JVM 分配的内存上限,导致 JVM 内存耗尽,引起 JVM 的 OOM。这种情况下该 JVM 服务会停止响应并且退出,但是并不会引起操作系统的崩溃。
2、产生背景
近期收到反馈,一套开启高可用的 EMR 集群中的 HiveServer2 一段时间后便会停止服务,此集群的 HiveServer2 一共有3个节点,状态信息注册至 Zookeeper 中,提供 HA 的能力,一段时间后几乎3个节点都会停止服务,通过对 HiveServer2 的日志查看发现是大量的 FULL GC后出现 OOM:
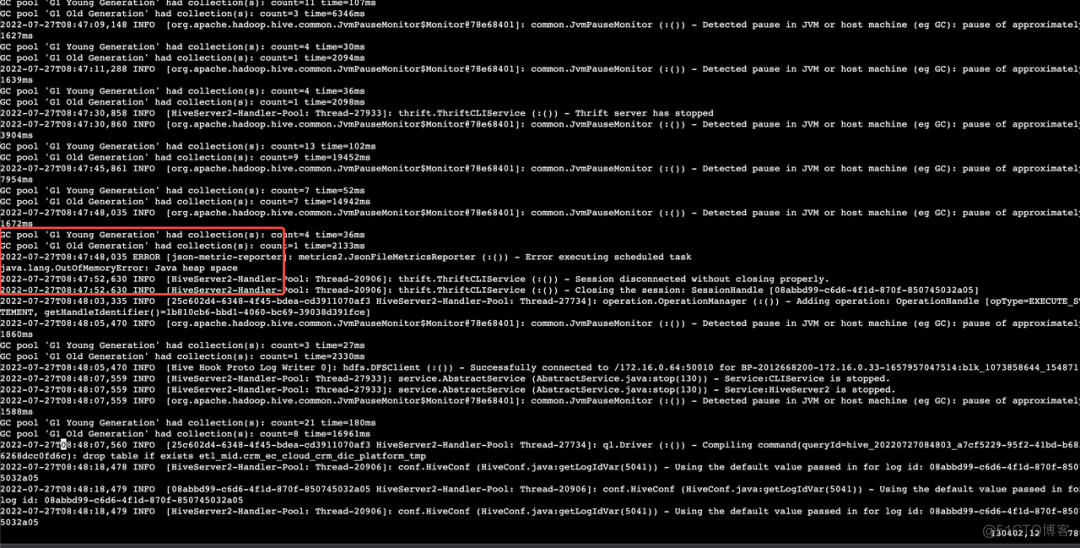
了解到该集群是一套从线下私有化部署的集群迁移而来,迁移前的集群中 HiveServer2 的 heapsize 为 2G,于是为了对齐业务参数将 heapsize 调整至 2G,间隔一天后,再次收到反馈,OOM 的问题依旧存在,查看日志,问题依旧是 HiveServer2 发生了 OOM,由于参数已经对齐之前的配置,那么问题可能不单纯是内存不足,可能会有其他问题。于是首先将 HiveServer2 的 heapsize 调整为 4G,确保可以在一定时间内稳定运行,留下定位时间。
3、问题定位
定位方向为两个方向:一个是分析 dump file,查看在内存不足的时候,内存消耗在哪些地方;第二个方向是针对日志进行细粒度分析,确保整个流程执行顺序是合理的。
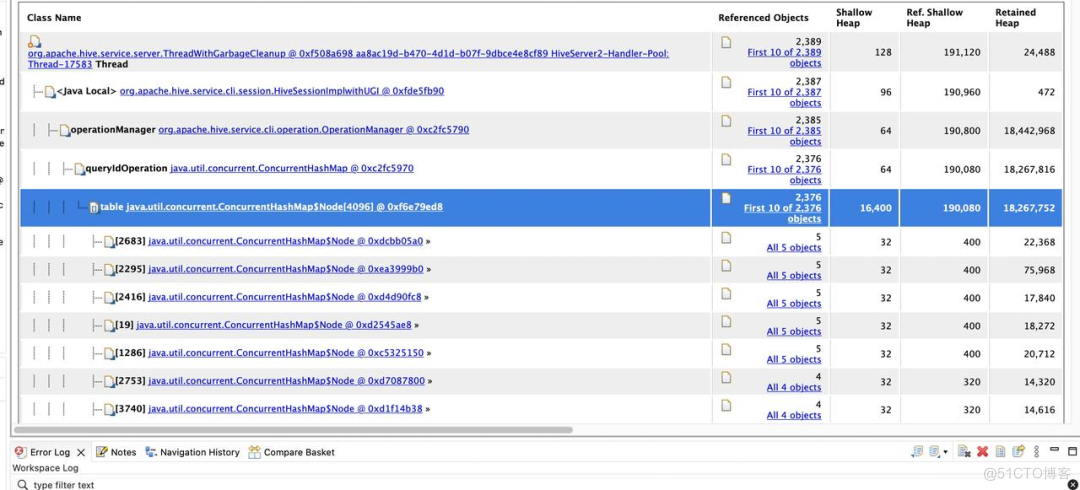
通过对 JVM 的 dump 文件进行分析,定位到在发生 HiveServer2 的 OOM 的时候,queryIdOperation 这个 ConcurrentHashMap 占据了大量的内存,而此时 HiveServer2 的负载非常低。

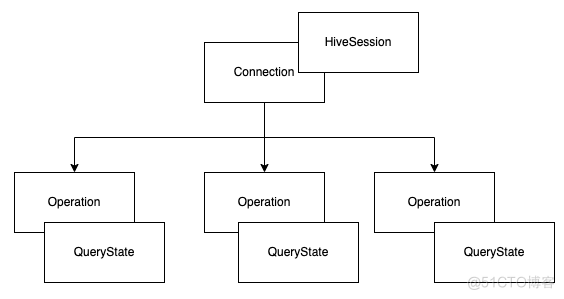
再基于具体的 QueryId 进行跟踪日志,HiveServer2 对作业处理的逻辑为在建立 Connection 的时候会调用一次 OpenSession,拿到一个HiveConnection 对象,此后便通过 HiveConnection 对象调用 ExecuteStatement 执行 SQL,后台每接收到一个 SQL 作业便生成一个 Operation 对象用来对 SQL 作业实现隔离。
每一个 Operation 有自己独立的 QueryId,每条 SQL 作业会经历编译,执行,关闭环节,注意此关闭指的是关闭当前执行的 SQL 作业,而不是关闭整个 HiveServer2 的连接,基于此思路追踪日志,发现部分 QueryId 没有执行 Close operation 方法。

有了这个思路后,再对 Hive 的源码进行查阅,发现 Close operation 方法被调用的前提是在一个名称为 queryIdOperation 的 Map 对象中可以找出 QueryId,如果没有从 queryIdOperation 找到合法的 QueryId,则不会触发 Close 方法。
再结合前面的堆栈图,其中 queryIdOperation 占据了大量的内存,于是基本可以确定定位出问题的原因,为当 SQL 执行结束后,有一个 queryIdOperation 的 Map 对象,没有成功的移除内部的内容,导致该 Map 越来越大,最后导致 HiveServer2 内存耗尽,出现 OOM,有了这个大概的思路,就需要仔细分析为什么会出现这个问题,从而找到具体的解决方案。
4、问题分析
在解决这个问题之前,先对 HiveServer2 本身做一个分析,HiveServer2 不同于一般的数据库服务,HiveServer2 是由一系列的 RPC 接口组成,具体的接口定义在 org.apache.hive.service.rpc.thrift 包下的 TCLIService.Iface 中,部分接口如下:
public TOpenSessionResp OpenSession(TOpenSessionReq req) throws org.apache.thrift.TException;
public TCloseSessionResp CloseSession(TCloseSessionReq req) throws org.apache.thrift.TException;
public TGetInfoResp GetInfo(TGetInfoReq req) throws org.apache.thrift.TException;
public TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req) throws org.apache.thrift.TException;
public TGetTypeInfoResp GetTypeInfo(TGetTypeInfoReq req) throws org.apache.thrift.TException;
public TGetCatalogsResp GetCatalogs(TGetCatalogsReq req) throws org.apache.thrift.TException;
public TGetSchemasResp GetSchemas(TGetSchemasReq req) throws org.apache.thrift.TException;
public TGetTablesResp GetTables(TGetTablesReq req) throws org.apache.thrift.TException;
public TGetTableTypesResp GetTableTypes(TGetTableTypesReq req) throws org.apache.thrift.TException;
public TGetColumnsResp GetColumns(TGetColumnsReq req) throws org.apache.thrift.TException;
更多关于接口和服务器的知识可查看:干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
每一个 RPC 接口之间相互独立,一个作业从连接到执行 SQL 再到作业结束,会调用一系列的 RPC 接口组合完成这个动作,中间通过 OperationHandle 中的 THandleIdentifier 作为唯一 session id,由客户端每次执行的时候进行传递,THandleIdentifier 在 OpenSession 的时候被创建。
HiveServer2 基于此对整个作业的执行进行管理。具体的调用顺序,以及调用何种接口,对于使用者是透明的,常用的客户端例如 Hive JDBC Driver 或者 PyHive 等已经封装了对应的调用顺序,使用者只需要关心正常的打开连接,执行 SQL,关闭连接即可,与标准的数据库操作逻辑保持一致。
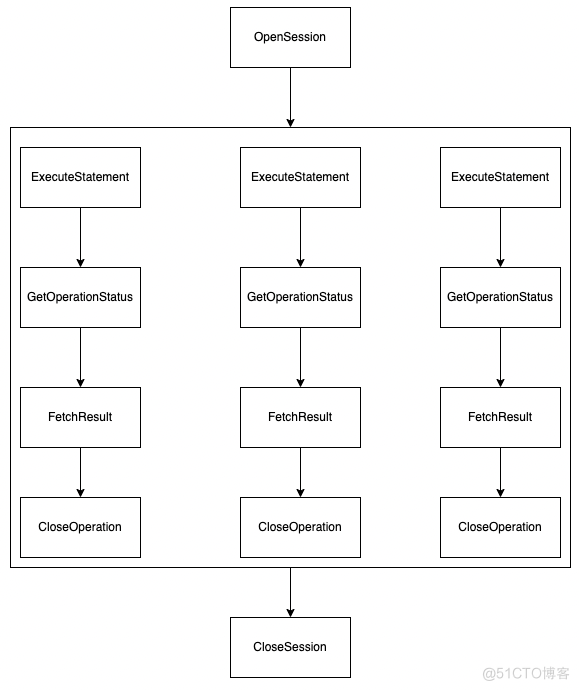
一个简单的调用逻辑如上图所示,当一个 Connection 执行多条 SQL 后,每一条 SQL 都是一个 Operation 进行记录,并且各自拥有各自的 Query Id,HiveServer 基于此 Query Id 做一些状态的管理,当连接结束后,调用 CloseOperation 清理所有内容。
每一条 SQL 执行结束后,都会调用 CloseOperation 进行相关的状态清除,如果清除失败,当 connection 被 close 的时候,也会循环调用 CloseOperation 去清理状态,确保状态的一致性。这里需要注意的是,既然 HiveServer2 是一系列的独立 RPC 接口,那么必然会出现万一用户不调用某些接口怎么办,例如不调用 CloseSession,HiveServer2 为了解决这个问题内置了一个超时机制,当 Connection 达到超时的阈值后,会执行 close 动作,清除 Session 和 Operation 的状态,具体的实现在 SessionManager 中的 startTimeoutChecker 方法中:
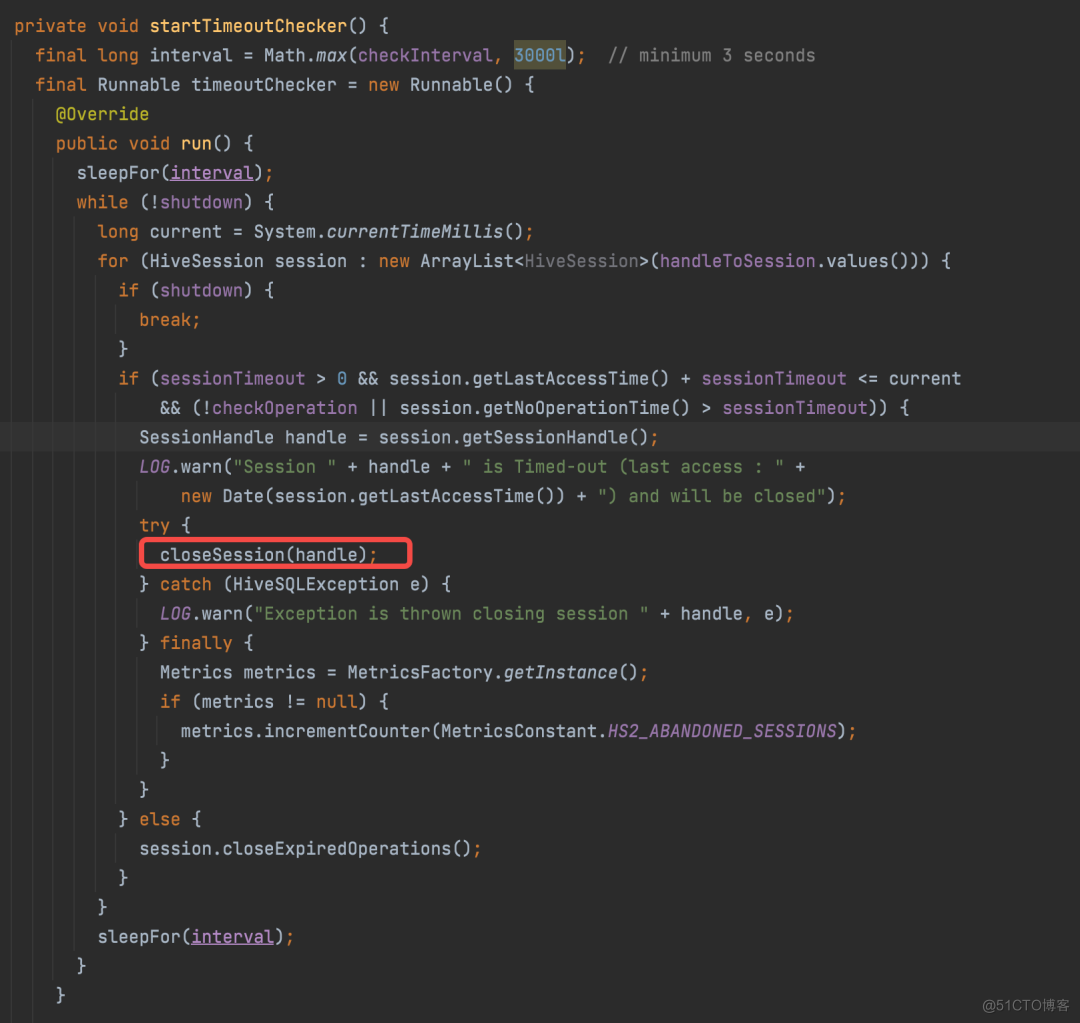
有了这些知识,再来分析前面出现 OOM 的问题,出现 OOM 是一个名叫 queryIdOperation 的 ConcurrentHashMap 对象占据了大量的内存,对这个对象分析会发现这个对象位于:
一个 Hive Connection 被打开后,可以执行多条 SQL,每一条 SQL 都是一个独立的 Operation,此 Map 维护一个 queryId 和 Operation 的关系。
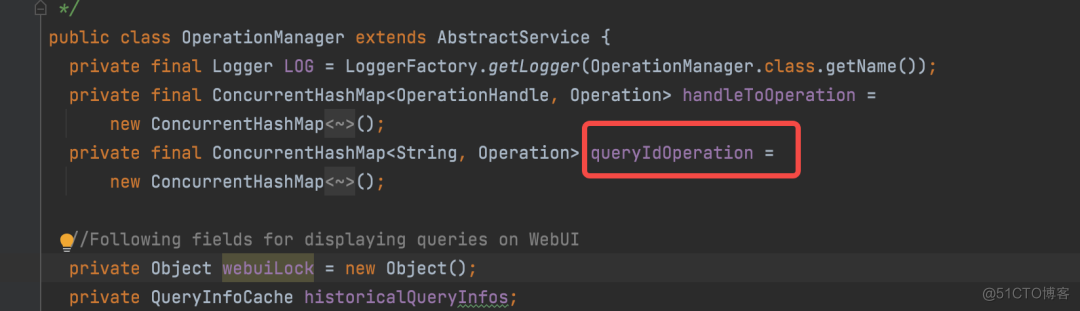
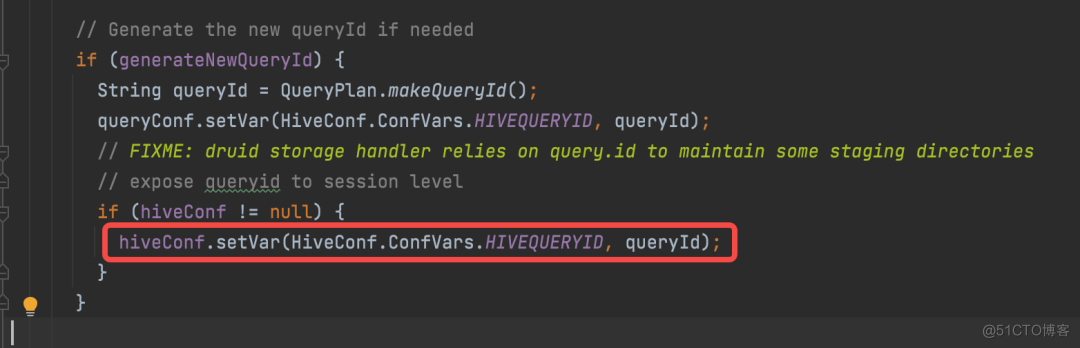
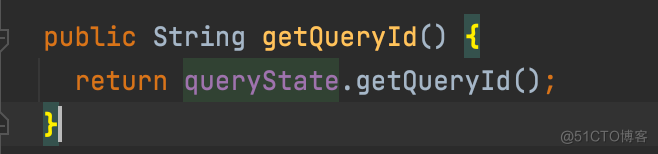
当一个新的 SQL 作业到达的时候,QueryState 对象的 build 方法会构建出一个 queryState,在这里生成此 SQL 的唯一标记,也就是 QueryId:
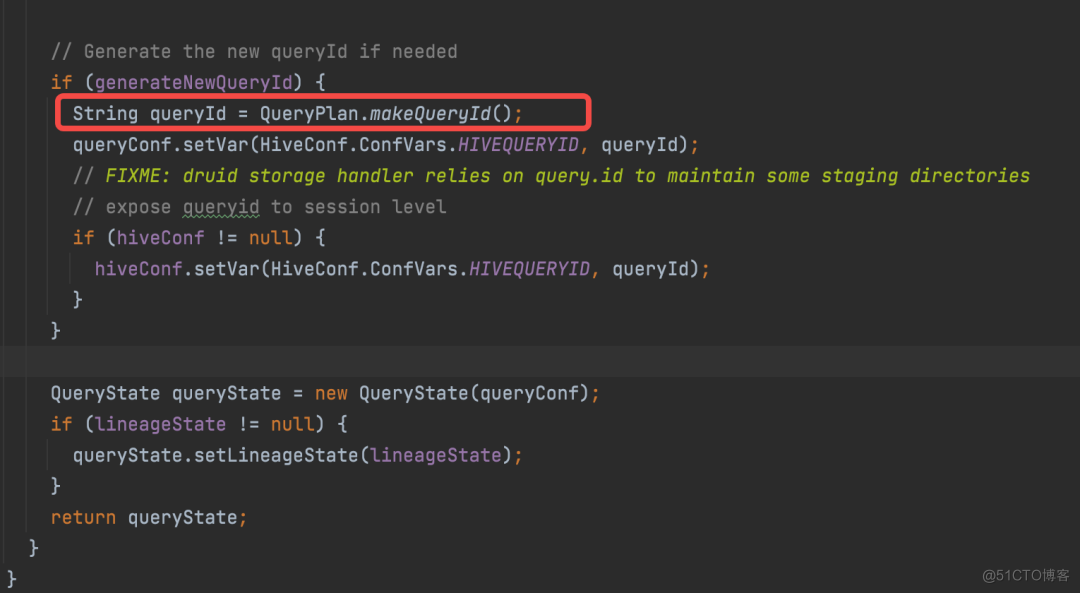
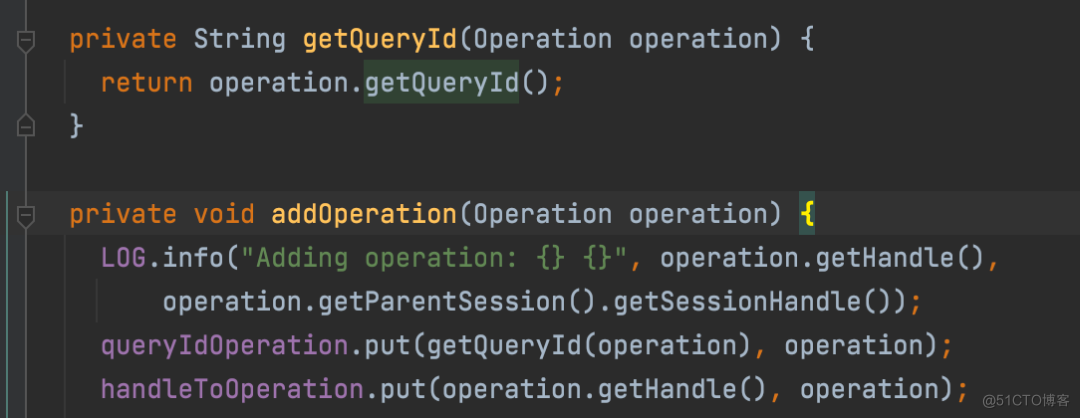
并且将该 QueryId 添加至 Connection 对象持有的 Hive Session,同时调用 OperationManager 的 addOperation 方法将此对象添加至 Map 中:
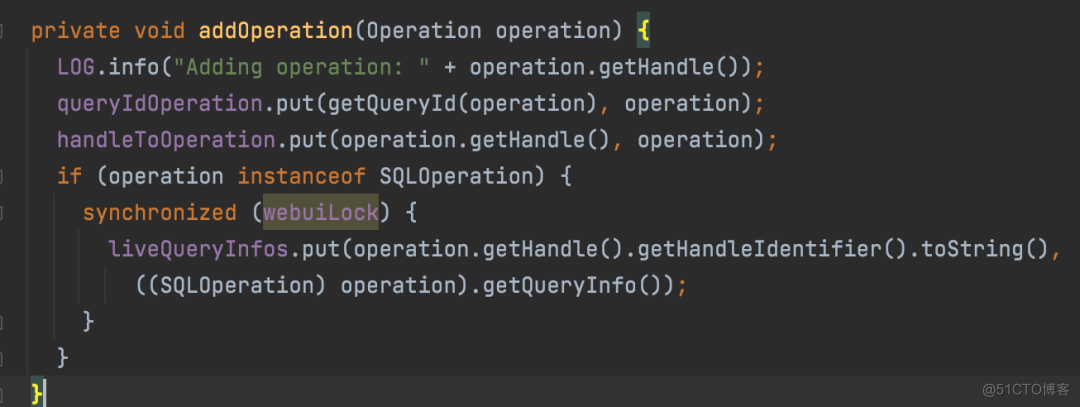
当作业执行结束后,通过 OperationManager.closeOperation 调用 removeOperation 移除该 Map 中的映射:
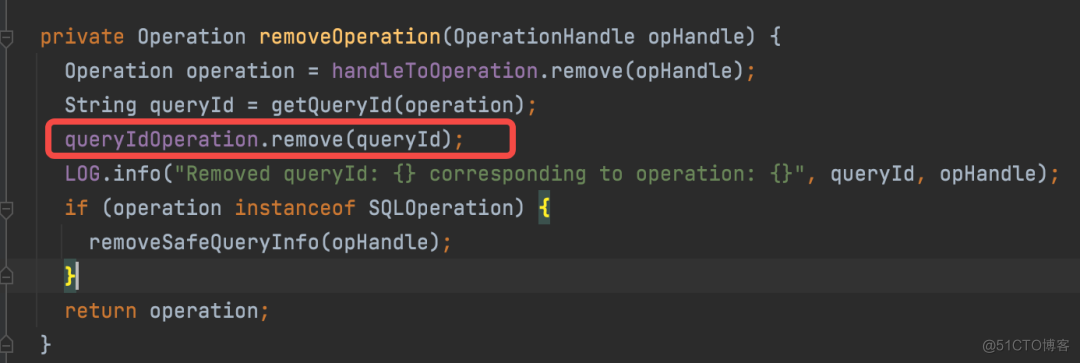
而 Query Id 是通过顶层的 Connection 中的 HiveSession 中去获取:

即使这里 removeOperation 失败了,在 CloseSession,或者 HiveServer2 触发超时动作后,都会再次回收该 Map 对象中的内容。
有了这个思路,于是再去对日志进行深度分析,发现:
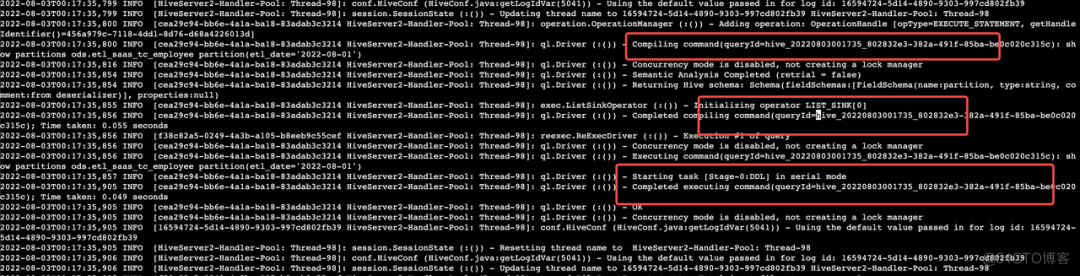
很多 SQL 作业在执行后,并没有调用 removeOperation 的行为,可以看到也就自然没有触发移除 queryIdOperation 的内容,那么内存被耗尽自然就可以理解,同时在 SQL 执行后会紧接着产生一个非法 Operation 的堆栈:
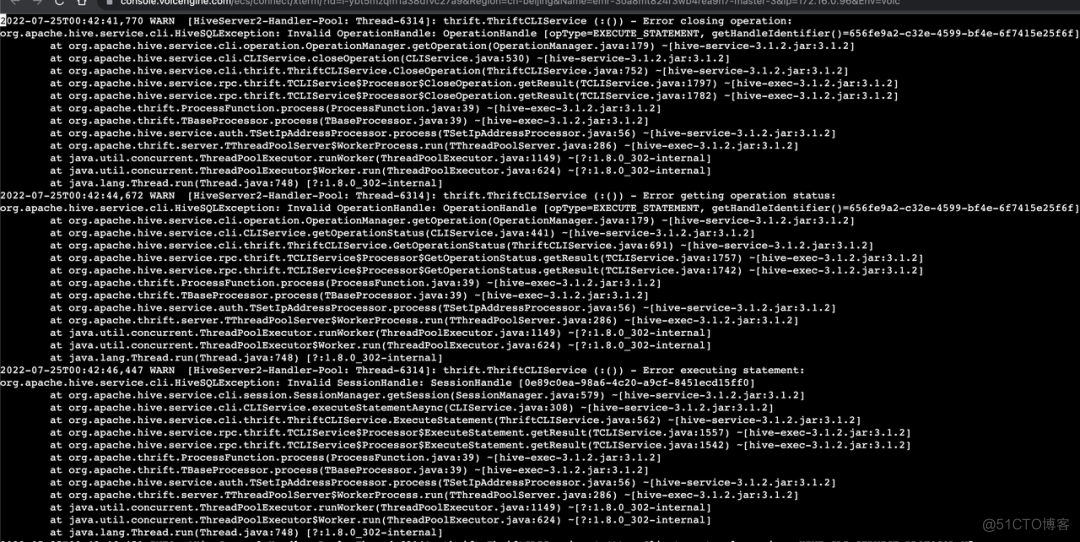
思路理到这里,需要想的问题是:为什么没有触发 removeOperation 的行为,或者说 removeOperation 没有执行成功,基于前面的理解来看,removeOperation 会有3种触发时机,分别是:
- SQL 作业执行结束调用 CloseOperatipn。
- Connection 断开调用 CloseSession。
- HiveServer2 自身的状态判断 Connection 超时发起 Close。
所以没有被调用的可能性不大,那么只剩下调用了,但是没有执行成功,没有执行成功也有2种情况:
- 执行了,但是失败了。
- 执行成功了,但是没有移除。
失败可能性不大,因为失败了,那么一定会留下堆栈信息,于是只剩下执行了但是没有移除,出现这样的情况基本就是只能是:

里面查询出的 QueryId 并不是当前作业的 QueryId,这个 ID 发生了篡改,那么什么样的情况下会发生篡改?再来理一理 HiveServer 的状态逻辑:
一个 Connection 执行 SQL 的时候,会先产生一个 Operation,并且生成一个 Query Id,将这个 Query Id 设置成全局 HiveSession的内容:
同时把这些信息存储到这两个 Map 中:

在 close 的时候再从 HiveSession 中去查询出来,由于 HiveServer2 是一系列的独立 RPC 请求,因此不能保证整个流程的原子性,那么想一种情况,假设 N 个并行线程,同时持有一个 Hive Connection,且同时开始发送 SQL 会怎样?
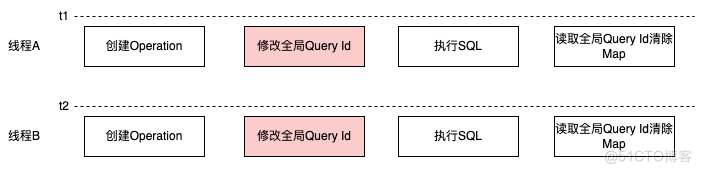
可以看到如果两个子线程同时使用同一个 Connection 执行 SQL,于是会出现一个线程把另一个线程的 Query Id 进行覆盖,导致其中一个线程丢失自己的 Query Id,导致无法成功的从 Map 中移除对象,具体的执行思路为:
- t1: 线程 A 将 conf 中的 queryId 设成 A;
- t2: 线程 B 将 conf 中的 queryId 设成 B;
- t3: 线程 A 从 conf 中拿到 queryId 为 B,并 close B;
- t4: 线程 B 从 conf 中拿到 queryId 为 B,并 close B,出现异常。
于是一直遗留了 queryId A,因为两个线程同时变成了相同的 Query Id,当其中一个线程执行了 remove 动作后,另一个线程要基于当前 Query Id 再去查询内容的时候,便会出现紧接着的第二个错误,也就是非法的 Session Id。
由于本次出现问题的使用场景是 Airflow 进行调用,Airflow 具有工作流的能力可同时在一个 Dag 中并发开启 N 个并行节点,而这些并行节点在同一个 Dag 下,因此共享同一个 Connection,于是触发了这个问题。
但是我们要知道,多个线程使用同一个 Connection 是非常常见的现场,特别是在数据库的连接池的概念中,那么为什么没有出问题呢?这里也就涉及到 HiveServer2 本身的架构问题,HiveServer2 本身不是一个数据库,仅仅提供了兼容 JDBC 接口的协议和 Driver 而已,因此相比传统的数据库的连接池,它并不能保证串行,也就是不具有排它效果,当然这只是次要问题,主要还是 HiveServer2 实现的缺陷。
对于此问题的复现,只需要创建一个 HiveConnection,同时并行开启多个线程同时使用该 Connection 对象执行 SQL,便可复现这个问题。执行过程中观察 HiveServer2 内存变化,可以发现 HiveServer2 的内存上升后,并没有发生下降,随着使用时间的增加,最后直至 OOM。
5、问题解决
既然找到了问题,那么解决方案就清楚了,那便是将 Query Id 这个值设置成 Operation 级别,而不是 HiveSession 级别,此问题影响 Hive3.x 版本,2.x 暂时没有这个特性,因此不受影响。再对照官方已知的 issue,此问题是已知 issue,目前 Hive 已经将此问题修复,且合入了4.0的版本,具体可查看:http://issues.apache.org/jira/browse/HIVE-22275
但是由于该 issue 是针对 4.0.0 的代码修复的,对于 3.x 系列并没有 patch,直接 cherry-pick 将会有大量的代码不兼容,因此需要自行参考进行修复,修复的思路为给 Operation 新增:
将 Query Id 从 HiveSession 级别移除,存入 Operation 级别,同时更新 Query Id 的获取和设置:
对 Hive 进行重新打包,在现有集群上对 hive-service-x.x.x.jar 进行替换,即可修复此问题。
6、结尾
虽然有些问题在官方 issue 上已经有发布,但是实际业务过程中我们依旧需要仔细定位,确保当前的问题,与已知问题是一致的,尽可能少的留下隐患,同时也有助于更加掌握引擎本身的原理和实现逻辑。只有对问题有清晰的认知,且对解决方案的逻辑有足够的了解,才能保证整个集群在生产环境下的稳定。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
