
最近项目中有关 JSON 的序列化和反序列化中,我们遇到了一个问题就是category_id我们在定义对象的时候使用的是categoryId。
当程序进行反序列化的时候,我们获得的对象值为 NULL。
这是因为 jackson 提供了一个命名规则,如果你是希望进行这种类型的映射的话,那么需要把命名映射规则设置为:SNAKE_CASE
objectMapper 对象初始化的时候设置
有 2 种设置方法,如果你希望你在 objectMapper 对象初始化的时候进行设服务器托管网置,那么需要添加下面的代码:
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
objectMapper.setPropertyNamingStrategy(PropertyNamingStrategy.SNAKE_CASE);那么这样,我们就等于告诉 objectMapper 在对对象进行序列化和反序列化的时候,使用 SNAKE_CASE 命名方式。
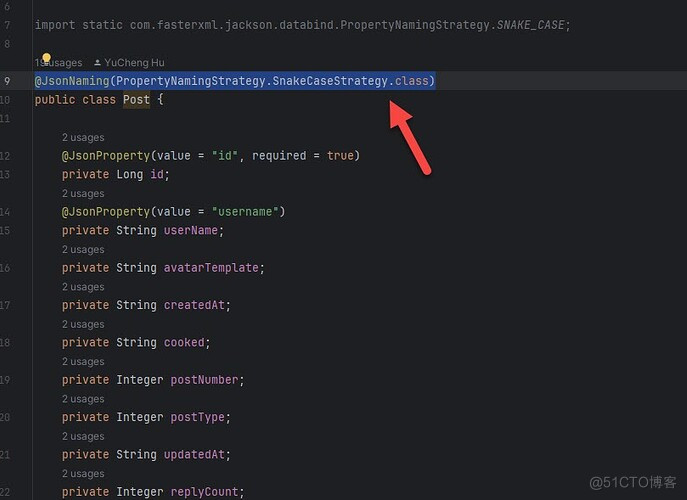
@JsonNaming
可以在直接需要进行序列化和反序列化的类中使用:
@JsonNaming(PropertyNamingStrategy.SnakeCaseStrategy.class)
上面的代码就可以了。
这样的意思就是不管是不是全局设置了命名规则,只要用到了这个类的序列化和反序列化都会使用上面的规则来进行字段映射。
那种方式更好
对我们当前的项目来说,我们可能更加倾向使用注解的方式。
需要知道的是 objectMapper 对象的初始化可能在不同的服务类中被初始化多次。
当然如果你使用的是 Spring 的配置文件,那么可以一次配置完成。
延伸阅读
Jackson 中的配置方式,不仅仅只有上面我们提到的,还有下面的几种方式。
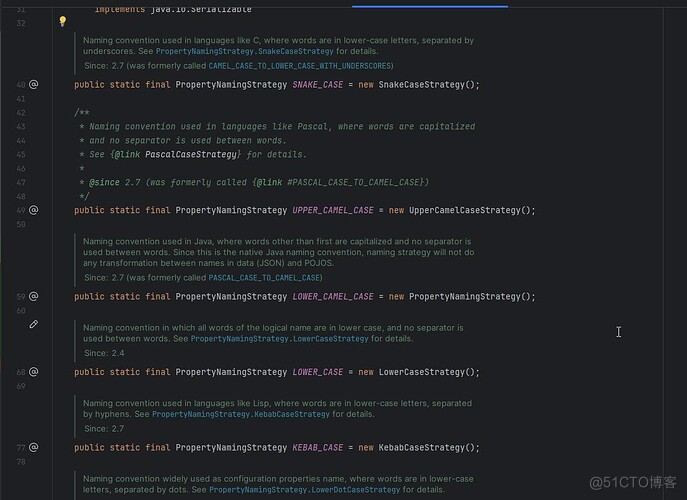
SNAKE_CASE:所有字母均为小写,并在名称元素之间使用下划线作为分隔符,例如 snake_case。
UPPER_CAMEL_CASE: 所有名称元素,包括第一个,都以大写字母开头,后跟小写字母,并且没有分隔符,例如 UpperCamelCase。
LOWER_CAMEL_CASE: 所有名称元素,包括第一个,都以小写字母开头,后跟小写字母,并且没有分隔符,例如 UpperCamelCase。
这个配置方式是默认的配置方式。
LOWER_CASE:所有字母均为小写字母,没有分隔符,例如 lowercase。
KEBAB_CASE:名称元素之间用连字符分隔,例如 kebab-case。
LOWER_DOT_CASE:所有字母均为小写字母,用点连接字符,例如 lower.case。
根据 Java 和 Json 的命名规范来说,其实大家都有点乱命名,但对一些比较规范的项目,通常单词之间我们使用下划线多。
我们并不太使用横杠的方式来处理命名。
所以,很多时候,你可能需要使用 SNAKE_CASE 来标记你的命名规则。
https://www.isharkfly.com/t/jacks服务器托管网on-snake-case/15034
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
背景 SaaS软件工程师的成长需要循序渐进,和SaaS业务一样有耐心。SaaS工程师需要在“业务”、“技术”、“管理”三个维度做好知识储备、技能沉淀。本文基于“能力-知识-技能”模型,给出SaaS软件工程师成长路径、学习建议及要求。 A-K-S模…
