
首先,我要向大家道个歉。原本我计划今天向大家展示如何将图片和视频等形式转换为向量并存储在向量数据库中,但是当我查看文档时才发现,腾讯的向量数据库尚未完全开发完成。因此,今天我将用文本形式来演示相似图片搜索。如果您对腾讯的产品动态不太了解,可以查看官方网址:https://cloud.tencent.com/document/product/1709/95477
在开始讲解之前,我想给大家介绍一个很有用的第三方包,它就是gradio。如果你想与他人共享你的机器学习模型、API或数据科学工作流的最佳方式之一,可以创建一个交互式应用,让用户或同事可以在浏览器中试用你的演示。而gradio正是可以帮助你在Python中构建这样的演示,并且只需要几行代码即可完成!
作为一个后端开发者,我了解如果要我开发前端代码来进行演示,可能需要花费很长时间,甚至可能需要以月为单位计算。所幸,我发现了gradio这个工具的好处,它可以帮助我解决这个问题。使用gradio,我只需要专注于实现我的方法,而不需要关心如何实现界面部分,这对于像我这样不擅长前端开发的人来说非常合适。gradio为我提供了一个简单而有效的解决方案。
源码仓库地址:https://github.com/StudiousXiaoYu/tx-image-search
Gradio
关于gradio的环境配置和官方文档,我就不再赘述了,有兴趣的同学可以去官方文档地址https://www.gradio.app/guides/quickstart 查看。对于后端开发者来说,上手使用gradio非常容易。
接下来,我们将搭建一个最简单的图片展示应用。由于我要实现的功能是图片展示,所以我将直接上代码。
数据准备
首先,我们需要准备数据。我已经从官方获取了训练数据,并将图片的信息和路径保存到了我的向量数据库中。幸运的是,这些数据已经被整理成了一个CSV文件。现在,我想要将这些数据插入到数据库中。这是一个很好的机会来练习一下我们的Python语法,比如读取文件、引用第三方包以及使用循环。让我们来看一下具体的实现方法。
我的csv文件是这样的:
id,path,label
0,./train/brain_coral/n01917289_1783.JPEG,brain_coral
1,./train/brain_coral/n01917289_4317.JPEG,brain_coral
2,./train/brain_coral/n01917289_765.JPEG,brain_coral
3,./train/brain_coral/n01917289_1079.JPEG,brain_coral
4,./train/brain_coral/n01917289_2484.JPEG,brain_coral
5,./train/brain_coral/n01917289_1082.JPEG,brain_coral
6,./train/brain_coral/n01917289_1538.JPEG,brain_coral
在这个文件中,第一行是列名,从第二行开始,我可以开始解析数据了。
之前已经完成了数据库的创建,所以我就不再演示了。现在,我们将直接开始设计集合,并将数据插入到我们的集合中。
import gradio as gr
import numpy as np
import tcvectordb
from tcvectordb.model.collection import Embedding
from tcvectordb.model.document import Document, Filter, SearchParams
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency,EmbeddingModel
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams
client = tcvectordb.VectorDBClient(url='http://*****',
username='root', key='1tWQ*****',
read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
db = client.database('db-xiaoyu')
上面提到的这些流程是基本的,我就不再详细解释了。我们可以直接开始连接,但是在此之前,我们需要先创建一个专门用于图片搜索的集合。之前我们创建的是用于文本搜索的集合,现在我们需要创建一个新的集合来区分。以下是相应的代码:
# -- index config
index = Index(
FilterIndex(name='id', field_type=FieldType.String, index_type=IndexType.PRIMARY_KEY),
服务器托管网 VectorIndex(name='vector', dimension=768, index_type=IndexType.HNSW,
metric服务器托管网_type=MetricType.COSINE, params=HNSWParams(m=16, efconstruction=200))
)
# Embedding config
ebd = Embedding(vector_field='vector', field='image_info', model=EmbeddingModel.BGE_BASE_ZH)
# create a collection
coll = db.create_collection(
name='image-xiaoyu',
shard=1,
replicas=0,
description='this is a collection of test embedding',
embedding=ebd,
index=index
)
由于目前向量数据库尚未完全支持图像文件转换为向量的功能,因此我们决定将其改为存储图像描述信息,并将图像路径直接存储为普通字段。由于我们对路径没有过滤要求,因此将其作为普通字段进行存储。所有信息已经成功存储在CSV文件中,因此我们只需直接读取该文件内容并将其存入向量数据库中即可。以下是相关代码示例:
data = np.genfromtxt('./reverse_image_search/reverse_image_search.csv', delimiter=',', skip_header=1, usecols=[0, 1, 2], dtype=None)
doc_list = []
for row in data:
id_row = str(row[0])
image_url = row[1].decode()
image_info = row[2].decode()
doc_list.append(Document(id=id_row,image_url=image_url,image_info=image_info))
res = coll.upsert(
documents=doc_list,
build_index=True
)
在这段代码中,我使用了 import numpy as np 语句来导入 numpy 库。为什么我使用它呢?因为我在搜索中发现它可以处理 CSV 文件。毕竟,在Python编程中总是喜欢使用现成的工具。最后,我将 Document 封装成一个列表,并将其全部插入到集合中。
构建Gradio交互界面
数据准备工作已经完成,接下来我们需要考虑如何建立一个交互界面。我知道Python有很多优秀的库,其中有一个可以一键构建交互界面的库,这真的很厉害。与Java的自定义界面相比,它们是完全不同的东西,因为他俩没得比。为了实现交互界面的功能,我们需要在一个新的py文件中编写以下代码:
import gradio as gr
import tcvectordb
from tcvectordb.model.document import SearchParams
from tcvectordb.model.enum import ReadConsistency
client = tcvectordb.VectorDBClient(url='http://lb-m*****',
username='root', key='1tWQ*****',
read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
db = client.database('db-xiaoyu')
coll = db.collection('image-xiaoyu')
def similar_image_text(text):
doc_lists = coll.searchByText(
embeddingItems=[text],
params=SearchParams(ef=200),
limit=3,
retrieve_vector=False,
output_fields=['image_url', 'image_info']
)
img_list = []
for i,docs in enumerate(doc_lists.get("documents")):
for my_doc in docs:
print(type(my_doc["image_url"]))
img_list.append(str(my_doc["image_url"]))
return img_list
def similar_image(x):
pass
with gr.Blocks() as demo:
gr.Markdown("使用此演示通过文本/图像文件来找到相似图片。")
with gr.Tab("文本搜索"):
with gr.Row():
text_input = gr.Textbox()
image_text_output = gr.Gallery(label="最终的结果图片").style(height='auto', columns=3)
text_button = gr.Button("开始搜索")
with gr.Tab("图像搜索"):
with gr.Row():
image_input = gr.Image()
image_output = gr.Gallery(label="最终的结果图片").style(height='auto', columns=3)
image_button = gr.Button("开始搜索")
with gr.Accordion("努力的小雨探索AI世界!"):
gr.Markdown("先将图片或者路径存储到向量数据库中。然后通过文本/图像文件来找到相似图片。")
text_button.click(similar_image_text, inputs=text_input, outputs=image_text_output)
image_button.click(similar_image, inputs=image_input, outputs=image_output)
demo.launch()
我创建了一个带有两个标签页的界面。由于本次项目不需要使用图像相似搜索功能,所以等到该功能推出后,我会再次进行图像方面的相似搜索演示。目前,我们只能通过图片描述来查找并显示图片。这部分没有太多值得讲的,我只是对 Gardio 官方示例进行了一些修改。如果你还不清楚的话,我建议你查看官方示例和介绍。现在,让我们来看一下我的运行界面吧。
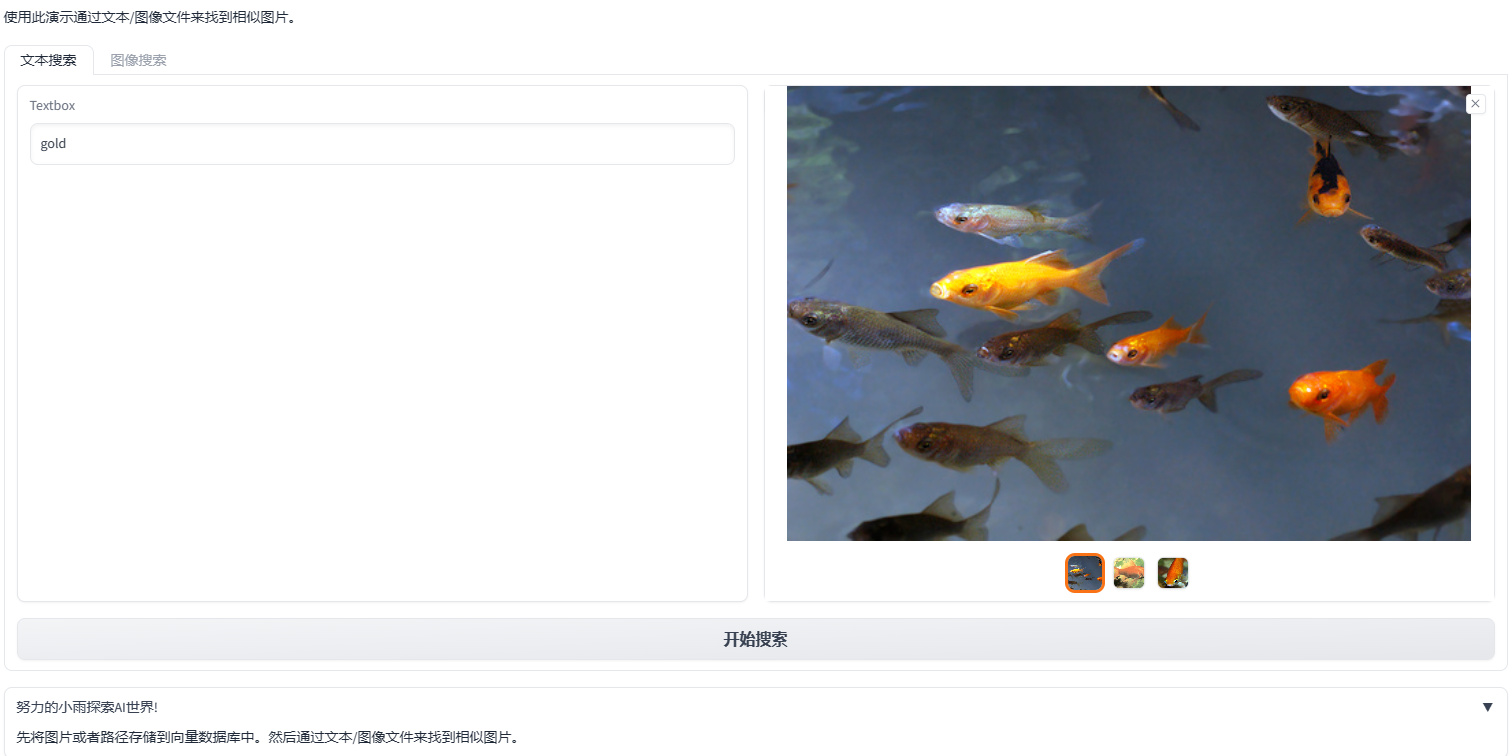
当我输入”gold”后,根据我所存储的图片描述是”gold fish”,所以可以找到对应的匹配项。当我看到三种金鱼的图片时,就说明我们的运行是正常的。我已经为图片相似搜索留出来了,以便及时更新。
总结
今天我们写代码时,基本上已经熟练掌握了Python的语法。剩下的就是学习如何使用第三方包,以及在编写过程中遇到不熟悉的包时,可以通过百度搜索来获取答案。虽然并没有太大难度,但是对于使用gradio来说,可能需要花费一些时间上手。有时会遇到一些错误,不像Java那样能够一眼识别出问题所在,需要上网搜索来解决。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 阿里云argusagent的监控客户端的安装脚本,值得借鉴
阿里云argusagent的监控客户端的安装脚本 agent_install_necs-1.7.sh #!/bin/bash echo “installing” export LANG=en_US.UTF-8 export LANGUAGE=en_US: #有…
