
介绍
Java SpringBoot自动化网页爬虫,以图形化方式定义爬虫流程,不写代码即可完成爬虫。
平台以流程图的方式定义爬虫,是一个高度灵活可配置的爬虫平台
功能根据需要可定制化开发。
特性
- 支持Xpath/JsonPath/css选择器/正则提取/混搭提取
- 支持JSON/XML/二进制格式、支持代理
- 支持多数据源/SQL select/selectInt/selectOne/insert/update/delete
- 支持爬取JS动态渲染(或ajax)的页面
- 支持自动保存至数据库/文件
- 常用字符串、日期、文件、加解密等函数
- 支持插件扩展(自定义执行器,自定义方法)
- 任务监控,任务日志
- 支持HTTP接口
- 支持Cookie自动管理
- 支持自定义函数、sql脚本
项目截图
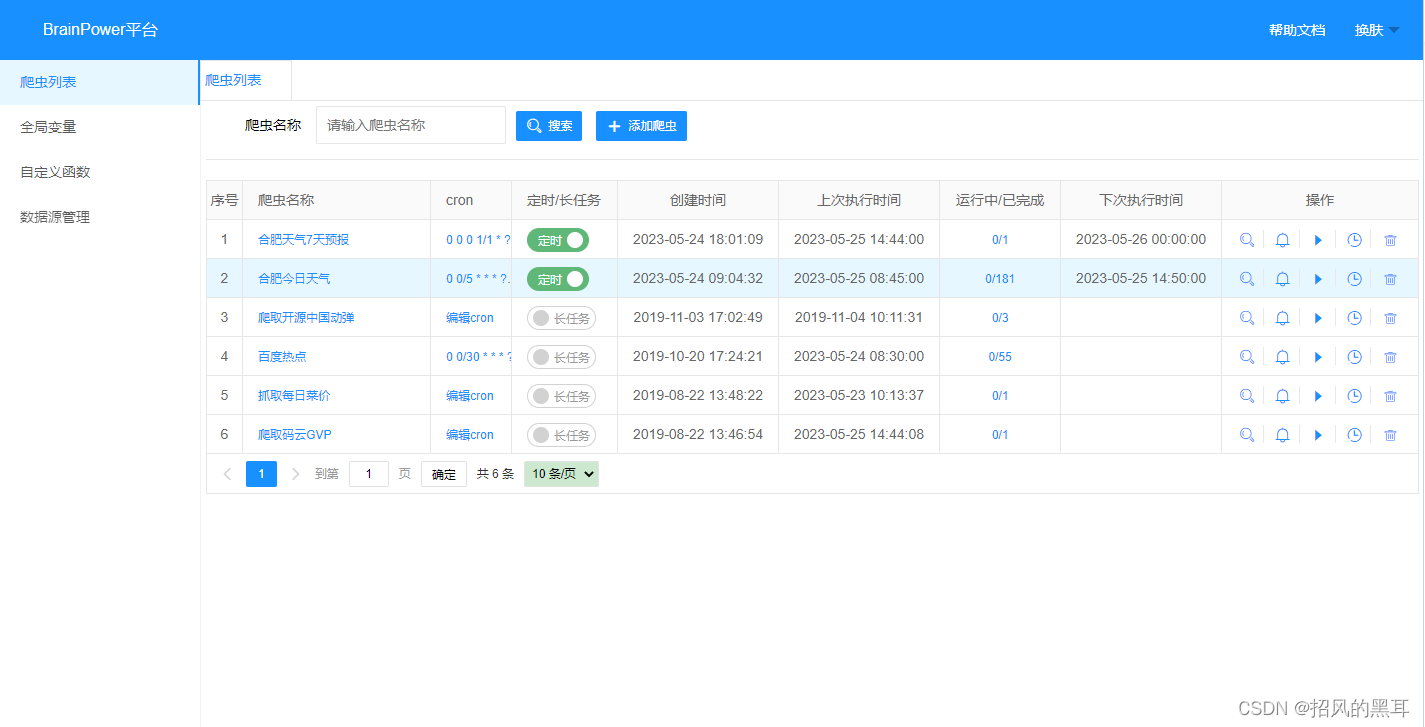
爬虫列表,可以定义为定时/手动提取方式
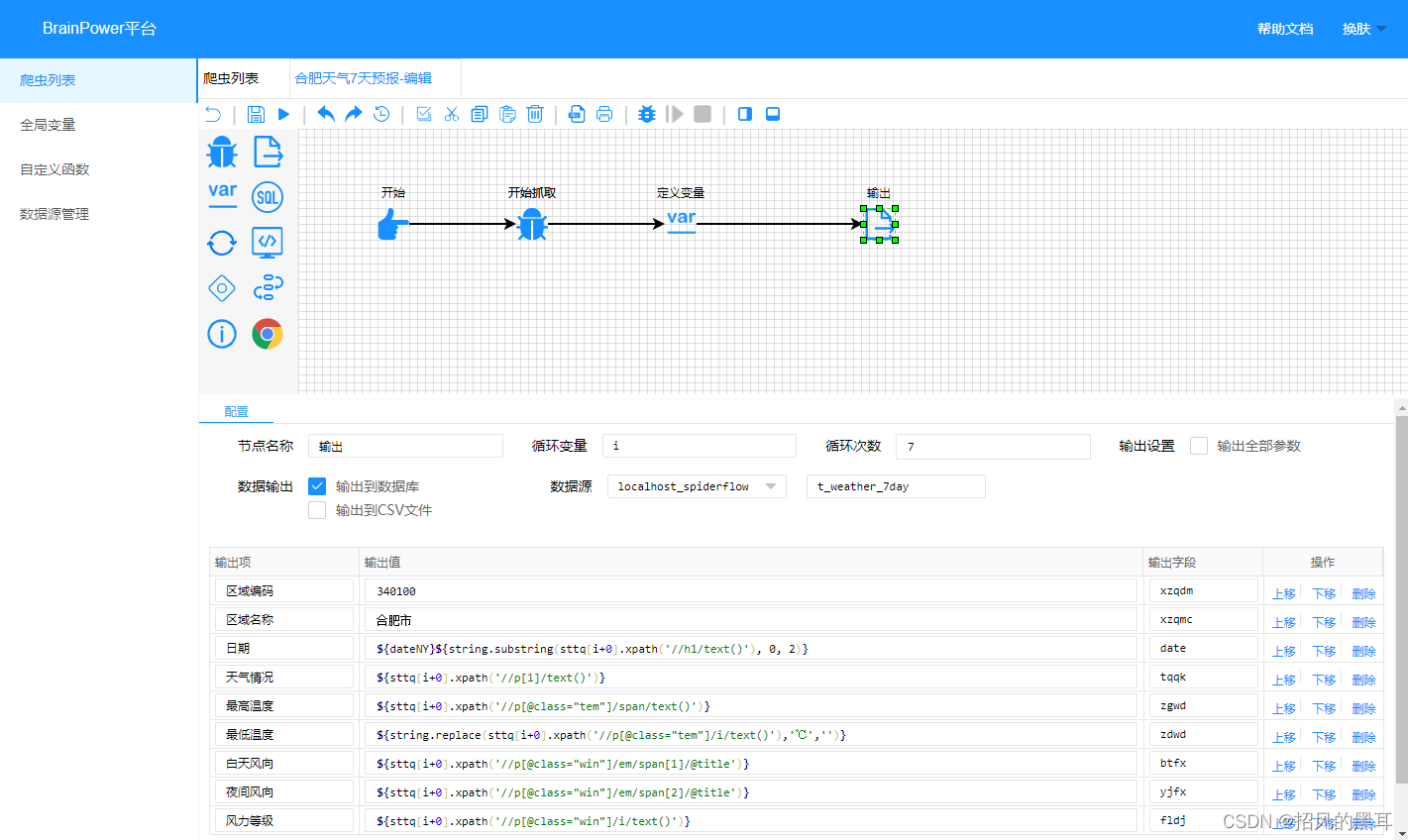
以获取中国气象台网页天气数据为例,添加流程,定义变量、输出项、提取表达式:
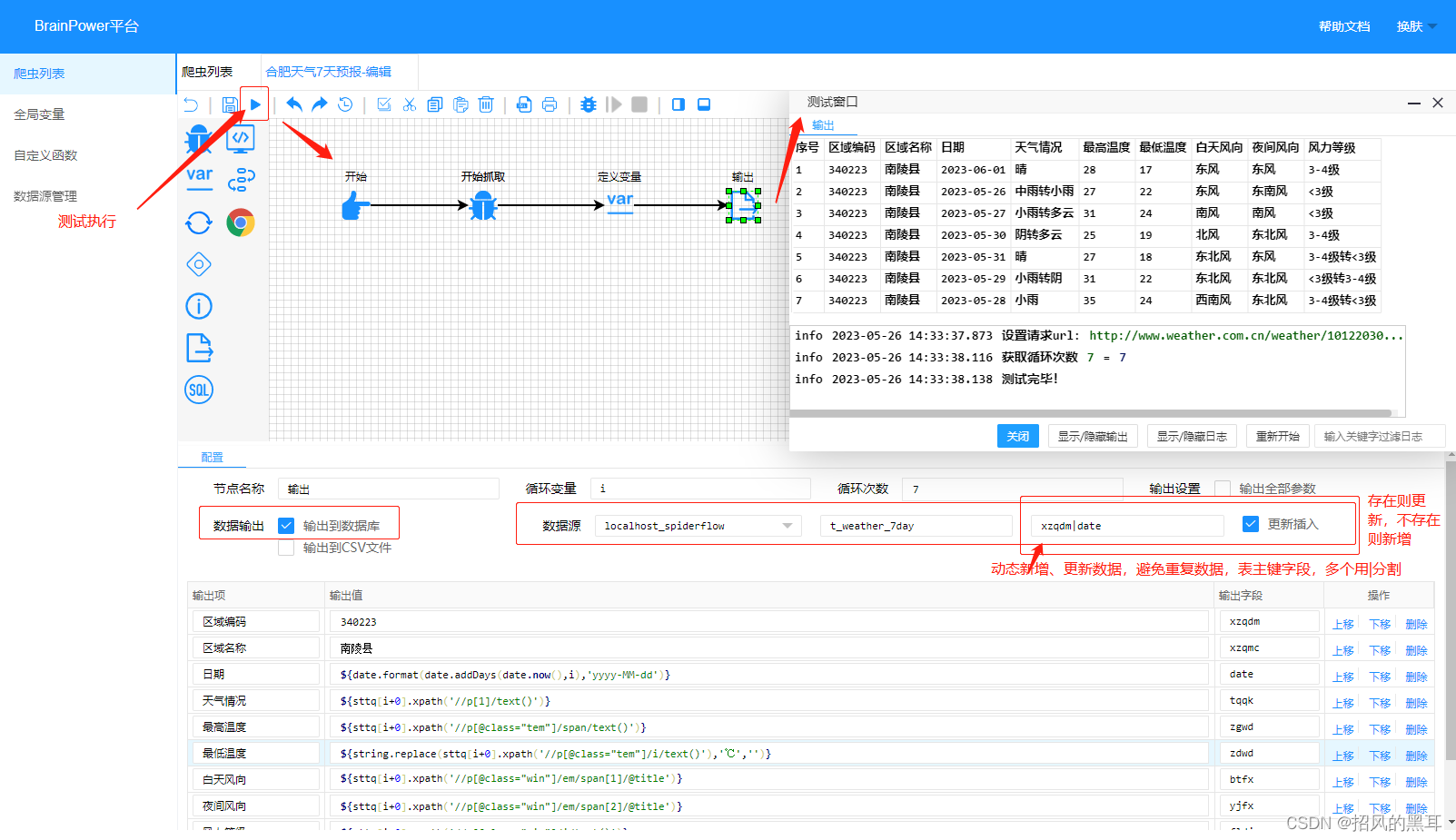
爬取流程定义完成后,点击开始测试,网页数据爬取成功。
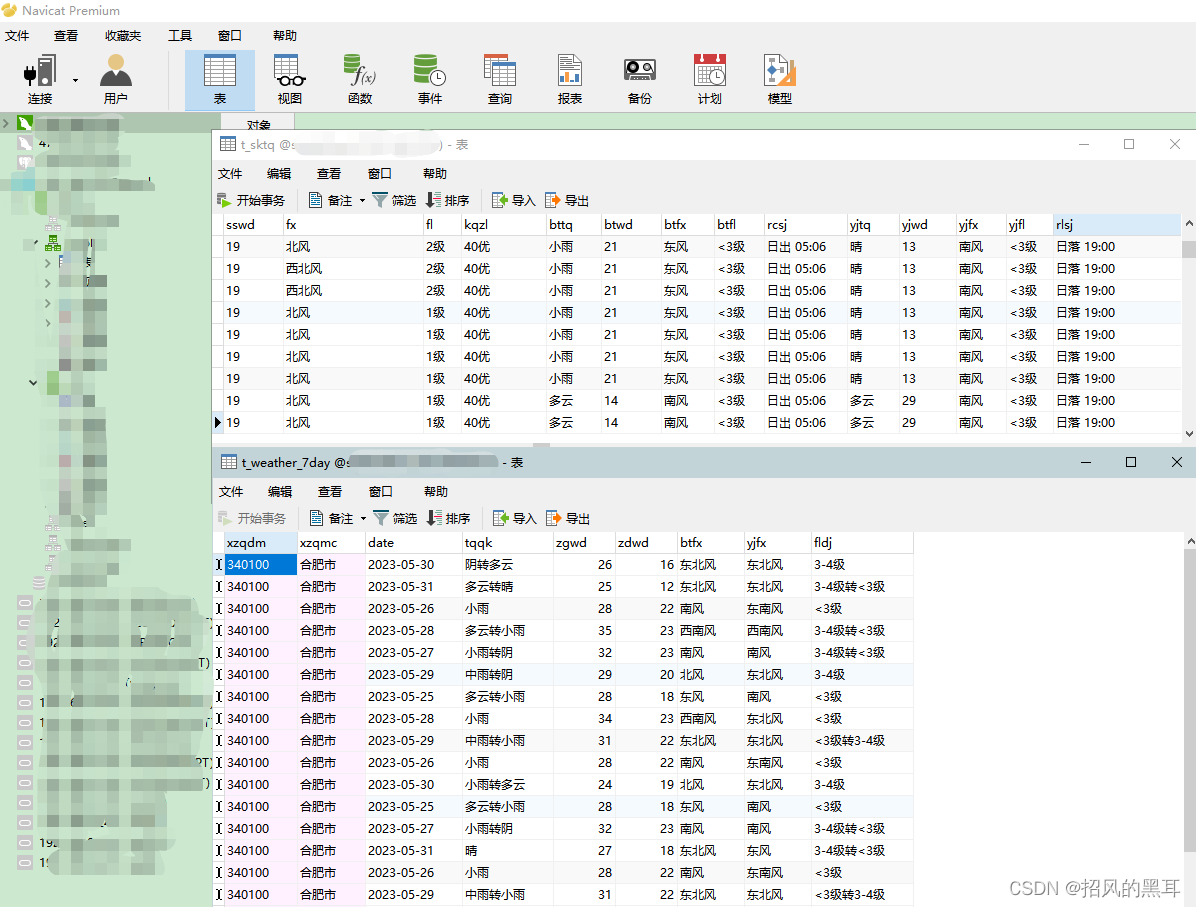
提取到的数据可以选择保存到数据库,只需建立数据连接、表结构,对应好输出字段与表字段无需任何开发。
同时支持动态网页数据爬取,平台引入selenium插件,模拟浏览器运行获取浏览器页面的特定内容。
如果我的文章对你有帮助,还请点个赞再走,如有问题欢迎评论区一起交流。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
