
正则表达式(RegExp)
正则表达式不是JS独有的内容,大部分语言都支持正则表达式
JS中正则表达式使用得不是那么多,我们可以尽量避免使用正则表达式
在JS中,正则表达式就是RegExp对象,RegExp 对象用于将文本与一个模式匹配
正则表达式(regular expressions, 规则表达式)
- 正则表达式用来定义字符串匹配的规则
- 通过这个规则计算机可以检查一个字符串是否符合规则,或者将字符串中符合规则的内容提取出来
- 正则表达式也是JS中的一个对象,所以要使用正则表达式,需要先创建正则表达式的对象
创建正则表达式
// 通过构造函数创建正则表达式,RegExp() 可以接收两个参数(字符串) 1.正则表达式 2.匹配模式
let reg = new RegExp("a", "i")//以不区分大小写的方式匹配含"a"的字符串
//或
// 使用字面量创建正则表达式,`/正则表达式/匹配模式`
let reg = /a/i
注意:以构造函数创建正则表达式,构造函数里面的字符串转换成正则表达式字面量的过程也有一个转义的过程
let reg = new RegExp("w")//相当于reg = /w/
let reg = new RegExp("w")//相当于reg = /w/
用RegExp对象的实例方法test()检测字符串是否匹配正则表达式
let reg = new RegExp("a")
let str = "a"
let result = reg.test(str) // true
result = reg.test("b") // false
result = reg.test("abc") // true
result = reg.test("bcabc") // true
方法
-
正则表达式.test(字符串):判断字符串是否匹配正则表达式,返回布尔值 -
正则表达式.exec(字符串): 提取字符串里匹配正则表达式的部分,返回一个数组array,array[0]为匹配的字符串部分,array[1]为正则表达式的第1个分组,array[2]为正则表达式的第2个分组,以此类推
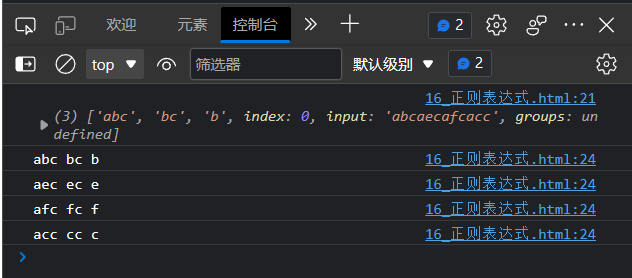
例:提取出str中符合axc格式的内容,即字符串开头时a,末尾是c,中间为任意字母
// 提取出str中符合axc格式的内容
let str = "abcaecafcacc"
// g表示全局匹配
//"[a-z]c"是分组1,[a-z]是分组2
let re = /a(([a-z])c)/ig // JS没有规定表示匹配模式的字母的书写顺序
let result = re.exec(str) //每执行一次返回一个数组
console.log(result)
// 最后匹配结束时会返回null给result,循环结束
while(result){
console.log(result[0], result[1], result[2])
result = re.exec(str)
}
语法
匹配模式
i: 不区分字母大小写
g: 全局模式匹配,如果不写这个用exec()方法提取匹配的字符串,默认服务器托管网是只提取匹配的第一个
正则表达式中的特殊字符
1.在正则表达式中大部分字符都可以直接写
2.| 在正则表达式中表示或,它是整体的或
3.[] 表示或(字符集)
[a-z] 任意的小写字母
[A-Z] 任意的大写字母
[a-zA-Z] 任意的字母
[0-9]任意数字
4.[^] 表示除了
[^x] 除了x其他字符都可以
5. . 表示除了换行外的任意字符
6. 在正则表达式中使用作为转义字符
7. 其他的字符集
w 任意的单词字符(就是单词中会出现的字符) [A-Za-z0-9_]
W 除了单词字符 [^A-Za-z0-9_]
d 任意数字 [0-9]
D 除了数字 [^0-9]
s 空格
S 除了空格
b 单词边界
B 除了单词边界
8. 开头和结尾
^ 表示字符串的开头
$ 表示字符串的结尾
/^字符串$/表示完全匹配该字符串
9. 量词
{m} m个
{m,} 至少m个
{m,n} m-n个
+ 一个及以上,相当于{1,}
* 0个及以上, 即任意数量的a
? 0-1个,即有或没有,相当于{0,1}
let re = /abc|bcd/ // "|"是整体的或, 表示abc或bcd
re = /[ab]/ // 表示a或b
re = /[A-Za-z][A-Z]/ //只是第1处忽略大小写
re = /[a-z]/i // 匹配模式i表示忽略大小写,这样写就是整个正则表达式忽略大小写
re = /[^a-z]/ // 匹配除小写字母以外内容的字符串
console.log(re.test(aH))// ture, 因为"aH"包含除小写字母以外的字符
re = /./
console.log(re.test("n服务器托管网")) // false
console.log(re.test("r")) //false
re = /./ //匹配含"."的字符串
re = /^a/ // 开始位置是a
console.log(re.test("a")) //true
console.log(re.test("ab")) //true
console.log(re.test("ba")) //false
re = /a$/ // 结束位置是a
console.log(re.test("a")) //true
console.log(re.test("ab")) //false
console.log(re.test("ba")) //true
re = /^a$/ // 只匹配字母a,完全匹配,要求字符串必须和正则表达式完全一致
console.log(re.test("aa")) //false
console.log(re.test("a")) //true
re = /^abc$/
console.log(re.test("abcabc")) //false
console.log(re.test("abc")) //true
let re = /ab{3}/ // 相当于/abbb/
re = /(ab){3}/ // 相当于/ababab/, 如果需要整体重复,就要在这个整体上加括号`()`
re = /^a{3}$/ // 相当于/^aaa$/
re = /^(ab){3}$/ // 相当于/^ababab$/
re = /^[a-z]{3}$/ //完全匹配3个字母
re = /^[a-z]{1,}$/ // 完全匹配1个及以上的字母
re = /^[a-z]{1,3}$/ // 完全匹配1-3个字母
re = /^ba+$/
re.test("b") //false
re.test("ba") //true
re.test("baa") //true
re = /^ba*$/
re.test("b") //true
re.test("ba") //true
re.test("baa") //true
re = /^ba?$/
re.test("b") //true
re.test("ba") //true
re.test("baa") //false
练习
- 从字符串中找出手机号码,并且手机号中间4位用*代替
let str="dajsdh13715678903jasdlakdkjg13457890657djashdjka13811678908sdadadasd";
//首先确定号码的格式为:1 3到9之间 任意数字 x 9,然后用正则表达式表达出来
let reg = /(1[3-9]d)d{4}(d{4})/g; // 注意别忘了写匹配模式"g"(全局匹配),不写的话会陷入死循环
let r=reg.exec(str);
while(r){
console.log(r[1]+"****"+r[2])
r=reg.exec(str)
}
- 判断字符串是否是手机号
这种情况只需完全匹配
let re = /^1[3-9]d{9}$/
console.log(re.test("13456789042"))
与正则表达式关系密切的字符串方法
split()
split()可以根据正则表达式来对一个字符串进行拆分
没有正则表达式作为split()的参数前,只能根据固定的字符(串)分割字符串
let str = "a@b@c@d"
let result = str.split("@") // ['a','b','c','d']
有了正则表达式后,可以根据符合一定规律的字符(串)分割字符串
str = "孙悟空abc猪八戒adc沙和尚"
result = str.split(/a[bd]c/) // ["孙悟空","猪八戒","沙和尚"]
search()
search()的作用类似于indexOf(), 区别在于search()支持正则表达式作为参数,它可以去搜索符合正则表达式的内容第一次在字符串中出现的位置。返回值是第一次出现的索引,没有搜索到则返回-1
str ="dajsdh13715678903jasdlakdkjg13457890657djashdjka13811678908sdadadasd"
result = str.search(/1[3-9]d{9}/)
console.log(result) // 6
replace() replaceAll()
replace()和replaceAll()都是根据正则表达式替换字符串中的指定内容
str ="dajsdh13715678903jasdlakdkjg13457890657djashdjka13811678908sdadadasd"
// 如果是全局匹配replace()与replaceAll()的功能就基本一致了,replace()此时会替换所有匹配的字符
result = str.replace(/1[3-9]d{9}/g, "哈哈哈")
result = str.replaceAll(/1[3-9]d{9}/g, "哈哈哈") // 注意replaceAll()仍要求字符串使用全局匹配模式g
以回调函数的形式替换匹配的字符串,这样就可以实现用各自相应的字符替换不同的字符
// 定义转义 HTML 字符的函数
function htmlEscape(htmlStr){
// 别忘了将htmlStr.replace()的返回值返回给htmlEscape()
return htmlStr.replace(/|&/g,(match)=>{
switch(match){
case '':
return '>'
case '&':
return '&'
}
})
}
console.log(htmlEscape("这是h1标签123
"))

match() matchAll()
match()
– 根据正则表达式去匹配字符串中符合要求的内容
– 与RegExp对象的方法exec()相似, exec()由RegExp实例调用,match()由String实例调用
– match()返回一个数组(与exec()返回的数组不一样),match()返回的数组元素是所有匹配的字符串
– 所以match()的功能相较于exec()的功能更简单,它不能看到正则表达式的匹配分组
matchAll()
– 作用同match(), 该方法仍要求正则表达式为全局匹配g
– 它返回的是一个迭代器(迭代器需要遍历才能看到其中的内容, 遍历出的内容能看到正则表达式的匹配分组)
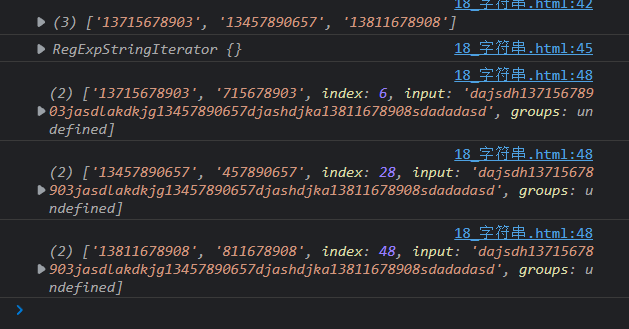
result = str.match(/1[3-9]d{9}/g)
console.log(result);
//注意不要忘了g
result = str.matchAll(/1[3-9](d{9})/g)
console.log(result);
// 迭代器需要遍历才能看到其中的内容
for(let item of result){
console.log(item)
}
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 复制内容后自动跳转到淘宝客户端请在Safari中打开
基本原型代码如下: @extends(‘layout.master’) @section(‘header’) 请在Safari中打开 @stop @section(‘content’) 点击G图标复制内容 跳转到淘宝 var clipboard = new C…
