
学生: 老师,我想请问为什么在月球上物体也会有坠落呢,和在地球上一样诶?
老师: 因为他们都遵循相同的规律, 我们根据规律就可以预测行为。但你观察到没有在月球上的坠落速度会慢一点。
到底什么是内存模型?
这里我们来回忆一下《JMM 学习笔记(一) 跨平台的JMM》讲述的东西,在这篇文章里面有两条线, 第一条是硬件性能提升带来的问题,在单核时代,提升CPU的方向是优化架构性能和提升主频速度,但是遗憾的是主频并不能无限制的提升,主频提高过一个拐点之后,功耗会爆炸提升。但我们还需要更强、更快的CPU,多核是一剂良药,引入了多核以后,如何提升CPU运算性能的问题得到了解决,我们就可以通过多核来不断的提升CPU的性能了,某种程度上来说,我们也可以理解为提供给软件的计算资源在不断的增加,那摆在开发者面前的一个问题是如何更好的使用这些计算资源,如何提升计算资源的使用率。我们将结合操作系统的发展历史来回答这个问题。让我们从纸带计算机开始讲起,如下图所示

一边读一边执行想来是那时的内存比较小,但是随着技术的发展,内存在慢慢的变大,高级语言开始出现,我们来观察一下一台计算机同时只能执行一个程序会遇到哪些问题, 我们先来看下下面一个很简单C语言小程序:
#include
#include
#include
// argv 用于接收以命令行方式启动传递的参数
int main(int argc , char* argv[])
{
int to ,sum = 0;
// 字符串转int
to = atoi(argv[1]);
// 打印传入的外部参数
printf("sum: %dn",to);
// 获取output.txt的指针
FILE* fp = fopen("output.txt", "w");
// 获取当前时间
clock_t start_time = clock();
for(int i = 0 ; i 然后我们以命令行方式启动这个程序:
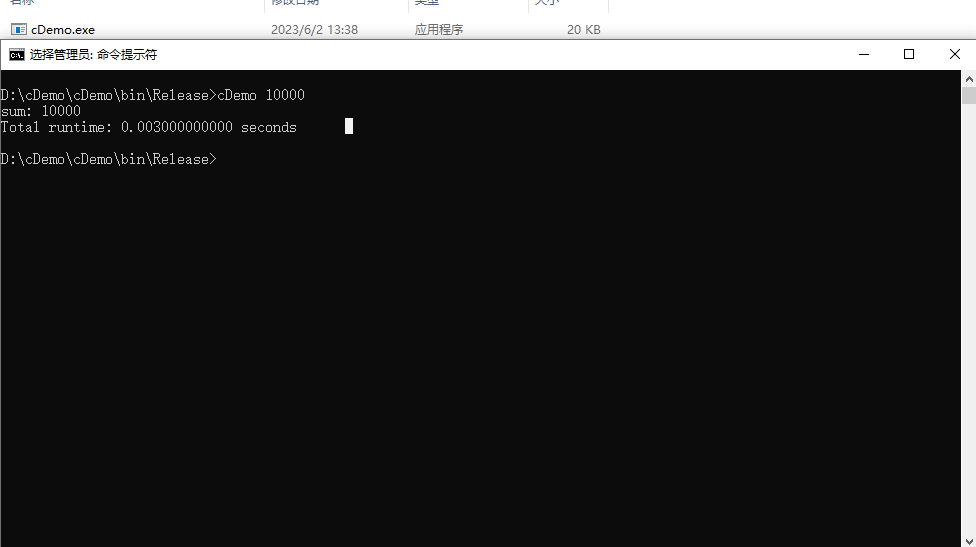
然后我们将语句二注释,将语句一解除注释,看下执行效果:
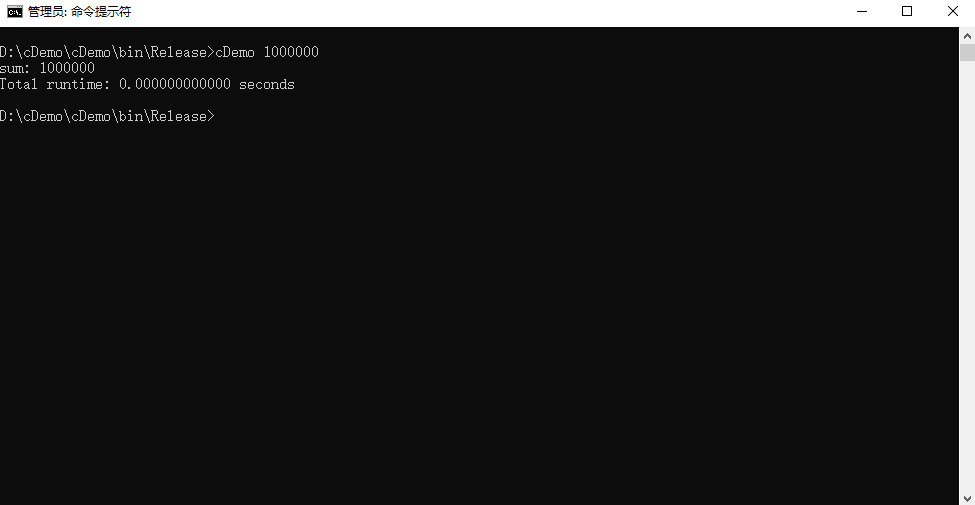
我们可以看到循环次数上升,只是将I/O语句注释,速度得到了飞快的提升,就几乎不需要花费时间一样,我执行了十几次,我将循环的次数提升到了1000w,但是速度仍然很快。我们来计算下语句二不注释的情况下,平均每次循环执行的时间是0.003/10^4^, 那我们将语句二注释换成语句一,那么花费的时间,由于分子是0,那么可以认为不需要花费时间? 可能有朋友觉得还是不够直观我们就姑且取时间为10^-8^ , 然后我们的循环次数是10^8^, 那么花费的时间就是1 / 10^16^, 我们可以看到相差的数量级。0.003/10^4^是有I/O指令花费的时间。两者的比例近似在1:3 × 10^9^, 可以看到有I/O指令会非常慢, 换句话说一条I/O指令所花费的时间够计算指令执行3×10^9^次, 假设我们有如下一个程序:
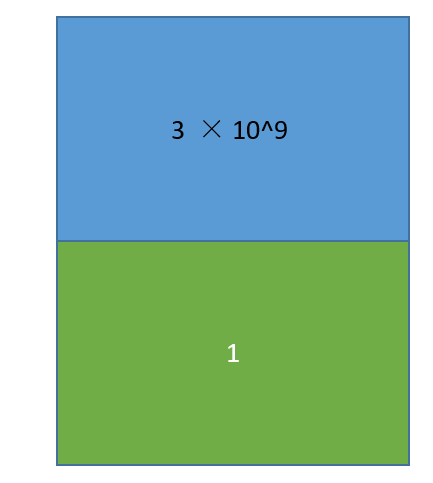
蓝色区域的代表有3×10^9^条计算指令,绿色部分代表有一条I/O指令,处理器在执行完计算指令之后,就发出I/O指令,等磁盘上写入或从磁盘上读取,在这段时间内CPU处于空闲状态,利用率也就是百分之之五十,但实际的程序中我们碰到的问题可能是三十条计算指令,一条I/O指令,二十条计算指令,一条I/O指令,换句话说,如果计算机只能执行一个程序,那么CPU的使用率接近于零,换言之软件并没有享受到计算能力的提升,那我们该如何提升呢,答案就是并发,交替的执行程序,在等待I/O指令的时候,CPU切换到了其他程序上进行执行。就像我们去烧热水一样,我们将水灌进热水壶之后,打开开关,我们就会去做别的事情。那交替的执行会带来什么问题,我们先在有两个程序,都加载进了计算机开始执行:
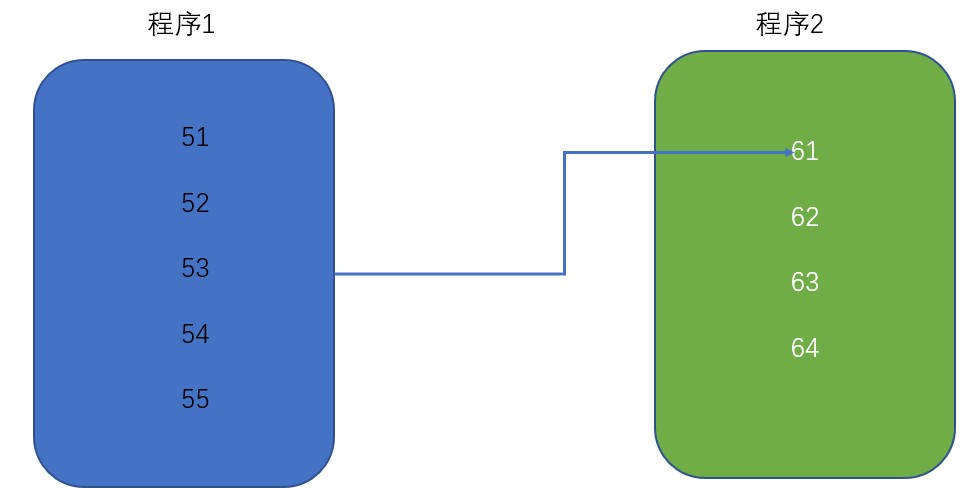
程序1执行到第53条指令,需要将CPU切换到程序2开始执行,程序2也有I/O指令,我们同样也不让CPU闲着,将CPU切回到程序1执行,那么这个时候CPU需要知道切换到程序2执行之前,这个程序执行到了哪里和指定到那个位置的数据(也就是程序执行到53条指令的时候,寄存器里面存储的数据),也就是我们需要一块内存来记录运行中程序的相关数据,我们看到再引入并发提高CPU的利用率的时候,刻化运行中的程序就需要再引入一些新的概念,这是相对于静态的程序不一样的地方,这也就是进程。引入进程之后,CPU的使用率得到了提高,但遇到了新的问题 ,比如一个音乐播放软件,先从音频文件中读取数据,然后对数据进行解压缩,然后执行播放,我们这里用伪代码表示就是:
main{
while(true){
read(); // I/O 加载数据
decomress(); // CPU 解压
play(); // 播放
}
}我们的思路是读一些放一些,但是I/O很慢,这就会导致我们听到的歌曲,唱一句等一些时间再唱一句,我们也可以想到将这三个功能拆成三个进程,先让读数据的进程先跑一段时间,再执行解压和播放进程,但是多进程之间共享资源可是个问题,除此之外,进程也需要消耗,我们能否提出一种实体,每一个实体共享地址空间,这些实体也交付给CPU并发的执行,这也就是线程,创建线程的代价要远小于进程切换代价,所需要的空间也远小于进程,但在软件领域就是这样我们引入一个机制去解决旧的问题,就会带来新的问题:
In multiprocessor systems, processors generally have one or more layers of memory cache, which improves performance both by speeding access to data (because the data is closer to the processor) and reducing traffic on the shared memory bus (because many memory operations can be satisfied by local caches.).
在多处理器系统内,处理器通常有一级或多级内存,用来加速读写数据改善性能,因为缓存里CPU更近,又可以减少内存总线上的数据传输(因为一些内存操作可以由本地缓存来满足)
Memory caches can improve performance tremendously, but they present a host of new challenges. What, for example, happens when two processors examine the same memory location at the same time? Under what conditions will they see the same value?
缓存可以极大的提升性能,但是也带来了一系列新挑战,比如当两个处理同时检查同一内存位置会发生什么? 在什么条件下它们会看到相同的值。《JSR 133 (Java Memory Model) FAQ》
我们可以将这个同一内存位置理解为多核CPU操纵共享变量,为了解决这个问题,就需要制定协议,这也就是缓存一致性协议,这类的协议有MESI、MSI、MOSI等,使用较为广泛的就是MESI协议,MESI解决了缓存一致性问题,但其实也存在一个性能弱点, 处理器执行写内存操作时,必须等待其他所有处理器将其告诉缓存中相应副本数据删除并接收到这些处理器回复的消息之后,才能将数据写入告诉缓存。为了规避和减少这种等待造成的写操作延迟,硬件设计者引入了写缓冲器和无效化队列。第二条是Java做为一个跨平台的语言, 该如何处理不同平台之间的差异。那这里的平台是什么意思? 我们在学习Docker的时候也看到过平台这个词,我们来回忆一下Docker是如何介绍自己的:
Docker is a platform for developers and sysadmins to build, run, and share applications with containers.
Dokcer 是一个开发者和系统管理员构建、运行、共享容器应用的平台。
那Java跨的平台呢? 在Oracle 出的教程《The Java™ Tutorials》是如是说的:
A platform is the hardware or software environment in which a program runs.
平台是程序运行的软件或硬件环境。
We’ve already mentioned some of the most popular platforms like Microsoft Windows, Linux, Solaris OS, and Mac OS. Most platforms can be described as a combination of the operating system and underlying hardware.
我们已经提及了一些广泛使用的平台,像Windows、Linux、Solaris OS、MacOS。大多数平台可以被描述为操作系统和底层硬件的组合。
The Java platform differs from most other platforms in that it’s a software-only platform that runs on top of other hardware-based platforms.
Java平台和其他大多数平台的不同之处在于,它是一个纯软件平台,在其他基于硬件的平台之上运行。
当我开始学习Java,Java向我承诺:
Your applications are portable across multiple platforms. Write your applications once, and you never need to port them–they will run without modification on multiple operating systems and hardware architectures.
你的应用很容易可以跨平台,编写一次,不需要移植,无需修改,就能运行在多个不同的操作系统和硬件架构上。
当Java喊出那句“一次编写,到处运行”的口号时,Java面临的是一个差异化的世界,不同指令集架构的CPU,不同的操作系统,不同的处理器架构有着不同的内存模型,我们这里再来复习一下:
从处理器的角度来说,读内存操作的实质是从指定的RAM地址加载数据,因此这种内存操作也被称为Load,写内存操作的实质是将数据存储到指定地址表示的RAM存储单元中,因此内存操作通常被称为Store。所以,内存重排序实际上只有以下四种可能:
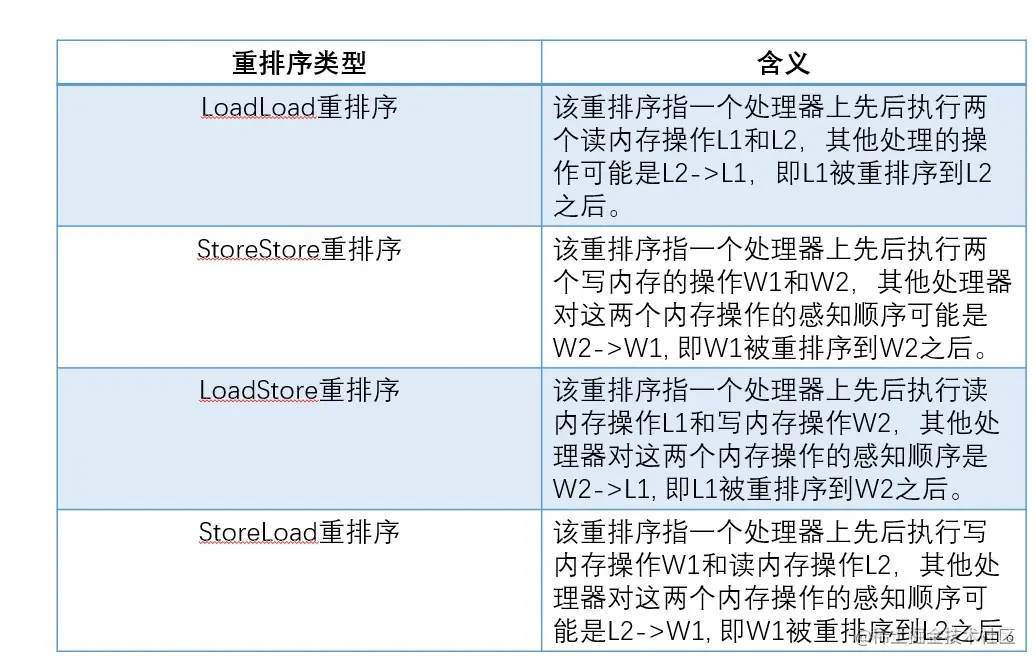
X86系列的处理器只存在最后一种问题,所以X86系列的处理器被称为具有强内存模型的处理器,其他平台的处理器则四种重排序都有可能出现,但是我们也不能完全禁止内存重排序,除非我们能够接受性能降低。这也就是并发问题的来源之一,有序性,有序性指的是在什么情况下一个处理器运行的一个线程所执行的内存访问操作在另外一个处理器上运行的其他线程看来是乱序的。所谓乱序,是指内存访问操作的顺序看起来像是发生了变化。我们再回忆一下JSR 133中的话:
Memory caches can improve performance tremendously, but they present a host of new challenges. What, for example, happens when two processors examine the same memory location at the same time? Under what conditions will they see the same value?
缓存可以极大的提升性能,但是也带来了一系列新挑战,比如当两个处理同时检查同一内存位置会发生什么? 在什么条件下它们会看到相同的值。
这说的也就是可见性问题,现代计算机的执行单位是线程,上面的话换一句话说也就是一个线程对共享变量的更新在什么情况下对另一个线程可见。可见性是有序性的基础,有序性描述的是一个处理器上运行的线程对共享变量做所的更新,在其他处理上运行的其他线程是以什么样的顺序观察到这些更新。在有序性的基础上我们又希望如果我们需要,访问某个共享变量的操作从其执行线程以外的任何线程来看,该操作要么已经执行结束,要么尚未发生,即其他线程不会“看到” 该操作的中间效果,这也就是原子性。做最终要回答的问题还是,一个线程对共享变量的更新在什么情况下会另一个线程可见。
Java的想法是在各个不同的处理器内存模型之间建立一个属于Java的内存模型:
The Java Memory Model was an ambitious undertaking; it was the first time that a programming language specification attempted to incorporate a memory model which could provide consistent semantics for concurrency across a variety of architectures.
Java 内存模型是一项雄心勃勃的工作,这是第一次有高级语言试图引入一个内存模型为各种架构的并发性提供一致的语义。
Unfortunately, defining a memory model which is both consistent and intuitive proved far more difficult than expected. JSR 133 defines a new memory model for the Java language which fixes the flaws of the earlier memory model. In order to do this, the semantics of final and volatile needed to change.
不幸的是,定义一个一致又直观的内存模型比预想的要困难的多,JSR 133 为Java语言定义了一个新的内存模型,修复了早期内存模型的缺陷。为了做到这一点,final和volatile的语义需要改变。
《JSR 133》
Java内存模型的总体目标是:
the goal of JSR 133 was to create a set of formal semantics that provides an intuitive framework for how volatile, synchronized, and final work.
JSR 133的目标是创建一套形式化语义,为volatile、synchronized和final关键字的工作方式提供直观的框架。
更详细一点的目标是:
- Preserving existing safety guarantees, like type-safety, and strengthening others. For example, variable values may not be created “out of thin air”: each value for a variable observed by some thread must be a value that can reasonably be placed there by some thread.
保留现有的安全保障,如类型安全,并加强其他。例如变量的值不能“凭空产生”: 某个线程观察到的每个变量值都必须是某个线程可以合理设置的值。
- The semantics of correctly synchronized programs should be as simple and intuitive as possible.
正确的同步语义应当是尽可能的简单而又直观的。
- The semantics of incompletely or incorrectly synchronized programs should be defined so that potential security hazards are minimized.
对不完全或不正确的同步程序的愿意进行定义,以便将潜在的安全隐患降到最低。
- Programmers should be able to reason confidently about how multithreaded programs interact with memory.
程序员应该能够自信地推理出多线程与内存的互动方式
- It should be possible to design correct, high performance JVM implementations across a wide range of popular hardware architectures.
应该可以在广泛流行的架构上设计出正确、高性能的JVM实现。
- A new guarantee of initialization safety should be provided. If an object is properly constructed (which means that references to it do not escape during construction), then all threads which see a reference to that object will also see the values for its final fields that were set in the constructor, without the need for synchronization.
应该提供一个新的初始化安全保证,如果一个对象是被正确创建(这意味着对它的引用在构造过程中没有被逃逸),那么所有看到该对象的引用的线程也将看到在构造函数中设置字段的最终值,而不需要同步。
- There should be minimal impact on existing code.
最小化对已有代码的影响
简单总结一下就是: 修复旧模型的bug的同时保证高性能,设计一套直观的框架让程序员可以直观的推导出来多线程与内存的交互方式。
内存模型定义了什么?
The Java Memory Model describes what behaviors are legal in multithreaded code, and how threads may interact through memory.
内存模型描述了多线程代码中的哪些行为是合法的,线程如何内存进行交互。
Java includes several language constructs, including volatile, final, and synchronized, which are intended to help the programmer describe a program’s concurrency requirements to the compiler.
Java 语言中提供了多个特性、机制,包括volatile、final和synchronized,帮助程序员向编译器描述并发需求。
The Java Memory Model defines the behavior of volatile and synchronized, and, more importantly, ensures that a correctly synchronized Java program runs correctly on all processor architectures.
Java内存模型定义了volatile 和synchronized的行为,更重要的是,确保在所有处理器架构上的程序能够被正确同步。
到这里我们可以看出Java内存模型为我们做的一切,当我们编写Java程序的时候,Java Memory Model屏蔽掉了各种硬件和操作系统的内存访问差异,Java内存模型给出了一组规则或规范, 定义了程序中各个变量(包括示例字段,静态字段和构成数组对象的元素)的访问方式,规范了Java虚拟机与计算机内存是如何协同工作的,JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些文献也称为栈空间),用于存储线程私有的数据,而Java内存模型中规定所有变量都必须存储在内存,主内存是共享内存区域,所有线程可以访问,但线程对遍历的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝的自己的工作内存空间,然后对遍历进行操作,操作完成后再将变量写会主内存,不能直接操作主内存中的变量,工作内存中存储着主内存中的变量副本拷贝。工作内存是每个线程的私有数据区域,因此不同的线程无法访问对方的工作内存,线程间的通信(传值) 必读通过主内存来完成。
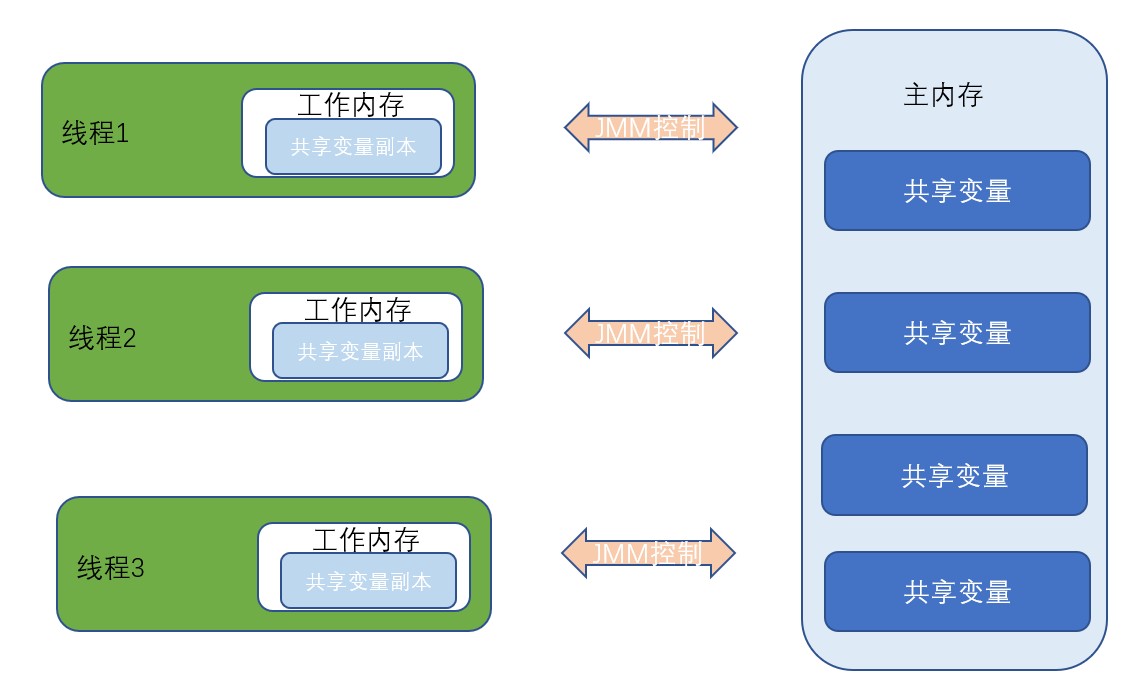
我们需要注意的是JMM只是一组规范,对于真正的计算机硬件来说,计算机内存只有寄存器、缓存内存、主内存的概念。
不管是工作内存的数据还是主内存的数据,对于真正的计算机硬件来说,可能存储在计算机的主内存中,也有可能存储到CPU缓存或者寄存器中 来自参考文献5
我开始的理解是存在某个数据存在寄存器,不在内存,不在CPU缓存 。 存在某个数据在CPU缓存,不在寄存器,不在内存。这可能与我们的一般理解有所违背,一般的理解是数据分配在主内存存储,CPU需要操作某个变量的时候,该变量会从主内存加载到缓存,然后再到寄存器。但是这句话让我想到了C语言,C语言里面有一个关键字register,可以请求编译器将数据分配到寄存器存储,所以我推测,编译器是否也会将变量直接分配到CPU缓存中进行存储,但是没有找到相关的资料,我们还是将其理解为数据从主内存加载,然后加载到CPU缓存,然后加载到寄存器中。 当然一些贴近机器的语言,也提供了将变量直接分配进寄存器的选项。
工作内存同步到主内存之间的实现细节,JMM定义了以下八种操作:
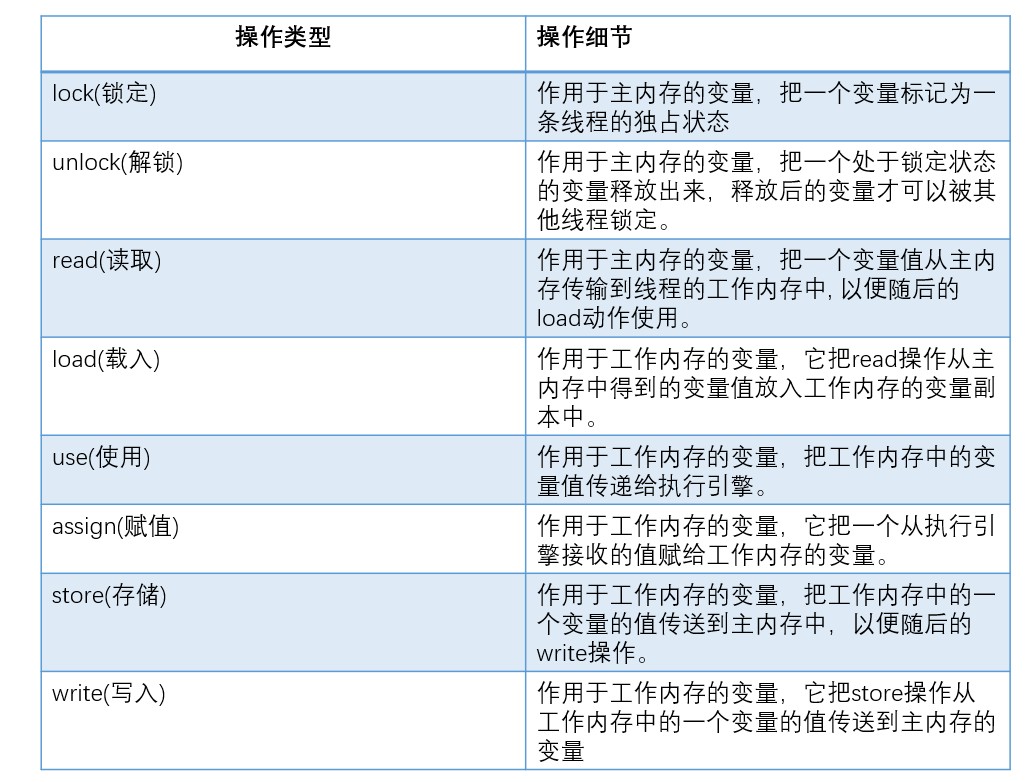
如果要把一个变量从主内存中复制到工作内存中,就需要按顺序地执行read和load操作,如果把变量从工作内存中同步到主内存中,就需要按顺序地执行store和write操作。但Java内存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行。

- 同步规则分析
(1)不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存中。
(2)一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或者assign)的变量。即就是对一个变量实施use和store操作之前,必须先自行assign和load操作。
(3)一个变量在同一时刻只允许一条线程对其进行lock操作,但lock操作可以被同一线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。lock和unlock必须成对出现。
(4)如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量之前需要重新执行load或assign操作初始化变量的值。
(5)如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量。
(6)对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)。
对于可见性和有序性问题,Java 内存模型则使用happens-before这个术语来解答。
happens-before
The new memory model semantics create a partial ordering on memory operations (read field, write field, lock, unlock) and other thread operations (start and join), where some actions are said to happen before other operations.
新的内存模型在内存操作(读字段、写字段、锁定、解锁)和其他线程操作(启动和加入)上创建了一个部分有序性,其中一些操作被认为先于其他操作之前发生(也就是happens-before)。
When one action happens before another, the first is guaranteed to be ordered before and visible to the second. The rules of this ordering are as follows:
当一个操作在另一个操作之前先行发生时(可以理解为一个操作happens-before), 第一个操作保证在第二个操作之前被排序和可见。
这里我们重点理解一下这个partial ordering 局部有序,存在一些操作是要排在一些操作之前,这也就是happens-before。那哪些操作存在这样的关系呢, 我们先简单的看一个规则,程序次序规则(Program Order rule):
- Each action in a thread happens before every action in that thread that comes later in the program’s order.
在一个线程内,按照控制流顺序,书写在前面的操作先行发生于书写在后面的操作。
这是符合我们的直觉的,我们再读一下上面的话:
When one action happens before another, the first is guaranteed to be ordered before and visible to the second.
当一个操作先行发生于另一个操作,第一个操作保证在第二个操作之前被排序和可见。
我们可以将这句话理解为,一个线程内指令的执行顺序和程序的书写顺序是一致的嘛? 当然不可以,我的理解是相对有序,好像是按顺序执行的:
public static void main(String[] args){
Student student = new Student(); // 语句一
System.out.println(student); // 语句二
}语句一happens-before语句二,我们知道一个对象的产生,要经历三步:
① 首先为Student 对象分配内存
② 调用 Student 的构造函数来初始化成员变量
③ 将student变量 指向分配的内存
JVM在执行的时候,发现2和3没有依赖关系,执行顺序就可能是①③②,也可能是①②③,那么无论是哪种执行顺序,根据程序次序规则,语句二拿到的对象就好像是①②③执行一样,规则并没有强制要求执行顺序,这会损害性能。再举一个例子, 在这个例子中我们用可见性来描述有序性,换句话说从可见性描述有序性也就是再说,最后看到的结果,一个处理器最后看到另一个处理器对共享变量的操作产生的结果,好像是顺序操作产生的, 顺序操作理解起来更为简单,即使编译器和处理器进行了内存重排, 假设处理器0、处理器1上两个线程按照下表所示的交错顺序执行,X、Y、Z和ready为共享变量,r1,r2,r3为局部变量。

进一步假设,Process 1读取到变量ready的值时,S1、S2、S3、S4的操作结果均已经提交完毕,并且L2、L3不会与L1进行重排序,那么此时S1、S2、S3和S4的操作结果对L1及其以后的L2和L3都是可见的。因此,从L1、L2和L3的角度来看此时S1、S2和S3就好像是被Process 0上的线程依照程序顺序执行一样,即S1、S2、S3和S4对于L1、L2和L3是有序的。尽管Process 0 可能会对S1、S2、S3和S4时可能进行指令重排,但是只要Process 1 开始执行L1时,S1、S2、S3和S4的操作结果已经提交完毕,即这些操作的结果同时对L1可见,那么S1、S2、S3和S4在L1、L2看来就是有序的。
接着我们来理解第二条规则,管程锁定规则 (Monitor Lock Rule): 一个unlock操作先行发生于后面对同一个锁的lock操作。 读到这里可能会有疑问,怎么先unlock,再lock,不应该是先lock再unlock嘛,就没锁门,你拿个钥匙开个什么劲。之所以有这个疑问,是因为把“先行发生”理解为一种主动的规则要求,而先行发生事实上是程序运行时的客观结果,正确的解读方式是这样的,对于“同一把锁”, 如果在程序运行过程中“一个unlock”操作先行发生于对同一把锁的lock操作, 那么该unlock操作所产生的影响(修改共享变量的值、发送了消息、调用了方法),对于该lock操作是可见的。我们结合代码来理解这个规则:
// 这个例子来自参考文档 [4]
public class WithoutMonitorLockRule {
private static boolean stop = false;
public static void main(String[] args) {
Thread updater = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
stop = true;
System.out.println("updater set stop true");
}
}, "updater");
Thread getter = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
if (stop) {
System.out.println("getter stopped");
break;
}
}
}
}, "getter");
getter.start();
updater.start();
}
}程序输出结果是updater set stop true,说明getter线程对共享变量的修改对getter不可见。我们在使用锁,来来试试看, 如下所示:
// 这个例子来自参考文档 [4]
public class MonitorLockRuleSynchronized {
private static boolean stop = false;
private static final Object lockObject = new Object();
public static void main(String[] args) {
Thread updater = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (lockObject) {
stop = true;
System.out.println("updater set stop true.");
}
}
}, "updater");
Thread getter = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
synchronized (lockObject) {
if (stop) {
System.out.println("getter stopped.");
break;
}
}
}
}
}, "getter");
updater.start();
getter.start();
}
}程序输出结果为:updater set stop true. getter stopped.。 这印证了管程锁定规则,,对于“同一把锁”, 如果在程序运行过程中“一个unlock”操作先行发生于对同一把锁的lock操作, 那么该unlock操作所产生的影响(修改共享变量的值、发送了消息、调用了方法),对于该lock操作是可见的。剩余的规则如下:
- volatile变量规则:对于同一个volatile变量,如果对于这个变量的写操作先行发生于这个变量的读操作,那么对于这个变量的写操作所产的影响对于这个变量的读操作是可见的。
- 线程启动规则:对于同一个Thread对象,该Thread对象的start()方法先行发生于此线程的每一个动作,也就是说对线程start()方法调用所产生的影响对于该线程的每一个动作都是可见的。
- 线程终止规则:对于一个线程,线程中发生的所有操作先行发生于对此线程的终止检测,也就是说线程中的所有操作所产生的影响对于调用线程Thread.join()方法或者Thread.isAlive()方法都是可见的。
- 线程中断规则:对于同一个线程,对线程interrupt()方法的调用先行发生于该线程检测到中断事件的发生,也就是说线程interrupt()方法调用所产生的影响对于该线程检测到中断事件是可见的。
- 对象终结规则:对于同一个对象,它的构造方法执行结束先行发生于它的finalize()方法的开始,也就是说一个对象的构造方法结束所产生的影响,对于它的finalize()方法开始执行是可见的。
- 传递性:如果操作A先行发生于操作B,操作B先行发生于操作C,则操作A先行发生于操作C,也就说操作A所产生的所有影响对于操作C是可见的。
这里讲一下volatile,这是Java内置的关键字,三年前我们就在《今天我们来聊聊单例模式和枚举》遇见了,在单例模式那里,我们使用volatile来禁止指令重排序,这里我们又理解了它的一个作用,可以用于修饰共享变量,在以前我不理解,volatile的作用,当一个变量被volatile修饰,B线程读取了这个共享变量,加载到自己的工作内存 , 刚加载完,然后时间片耗尽,A线程更新了共享变量,B线程还怎么读到A线程更新的值,这里就要探究volatile的实现了,本篇不做探索,简单的说就是,当volatile变量被修改时,其他CPU的缓存行会失效,CPU会不断对总线进行内存嗅探,如果滥用volatile可能会引起总线风暴(我在想该如何验证这个说法),除此之外,大量的CAS操作也会引发这个问题。我们不用锁,使用volatile修饰stop,也能输出updater set stop true. getter stopped。
public class VolatileRule {
private volatile static boolean stop = false;
public static void main(String[] args) {
Thread updater = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
stop = true;
System.out.println("updater set stop true");
}
}, "updater");
Thread getter = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
if (stop) {
System.out.println("getter stopped");
break;
}
}
}
}, "getter");
getter.start();
updater.start();
}
}volatile变量还有一个说是特点,其实也不是的特性。如下代码并未将stop变量用volatile修饰,而是用volatile修饰了volatileObject变量,如下所示:
public class VolatileRule1 {
private static boolean stop = false;
private static volatile Object volatileObject = new Object();
public static void main(String[] args) {
Thread updater = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
stop = true;
volatileObject = new Object();
System.out.println("updater set stop true.");
}
}, "updater");
Thread getter = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
Object volatileObject = VolatileRule1.volatileObject;
if (stop) {
System.out.println("getter stopped.");
break;
}
}
}
}, "getter");
updater.start();
getter.start();
}
}也能得到:updater set stop true. getter stopped.。 这个结果。 这看起来颇为神奇,我们结合传递性和程序顺序规则进行分析,在updater线程内,根据程序顺序规则,stop = true先于 volatileObject = new Object(), 而在getter线程内,对volatileObject的读取先于读取stop变量,所以stop = true 先行发生于if(stop) , 所以stop = true 对于if(stop) 就是可见的。
看到这里可能有同学就会问了,这不就是传递性和程序顺序规则嘛,怎么能算上volatile 的特点呢? 这里我们再来读一下volatile规则:
对于同一个volatile变量,如果对于这个变量的写操作先行发生于这个变量的读操作,那么对于这个变量的写操作所产的影响对于这个变量的读操作是可见的。
如果volatileObject上没有volatile,这个传递性就传不过来,我们再捋一下,在updater线程内,根据程序顺序规则,对stop变量的更新先行发生于对volatileObject的更新,而在getter线程内对volatileObject的读取先于对stop的读取, 那么在根据volatile规则,对volatile变量的写操作先行发生于这个变量的读操作:
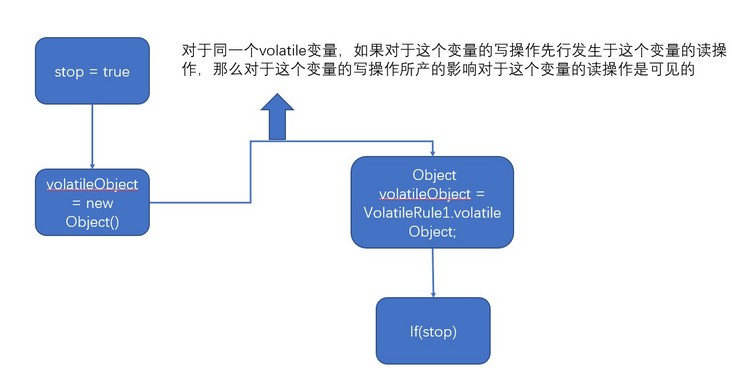
如果valueObject没被volatile修饰,就传不过来。利用此特性的一个典型例子在jdk的FutureTask,下面的代码来自FutureTask:
private volatile int state;
// non-volatile, protected by state reads/writes
没有被volatile修饰,被state变量读写保护
private Object outcome;其他语言有内存模型嘛?
Most other programming languages, such as C and C++, were not designed with direct support for multithreading.
像其他语言,比如C和C++,在设计时不被直接支持多线程。
The protections that these languages offer against the kinds of reorderings that take place in compilers and architectures are heavily dependent on the guarantees provided by the threading libraries used (such as pthreads), the compiler used, and the platform on which the code is run.
这些语言对发生在编译器和架构中的重排的保护很大程度取决于所使用得线程库(如pthread)、所使用的编译器以及代码运行的平台所提供保证。 《JSR 133 (Java Memory Model) FAQ》
总结一下其他语言没有承诺跨平台,语言原生就没有支持多线程,所以也不需要建立一个自己的内存模型来屏蔽系统和架构差异。
总结一下
总结Java memory model 是什么? 我们回忆一下《JMM 学习笔记(一) 跨平台的JMM》中我们已经谈到了什么是模型?
模型是指对于某个实际问题或客观事物、规律进行抽象后的一种形式化表达方式。
而计算机在发展过程中,引入多核整体提升CPU性能,引入进程增大CPU的利用率,引入线程更好的共享变量,而引入线程操作共享变量再碰上多核心,就会碰到下面三个问题:
- 可见性: 一个线程对共享变量的更新在什么情况下对另一个线程可见。可见性是有序性的基础
- 有序性: 描述的是一个处理器上运行的线程对共享变量做所的更新,在其他处理上运行的其他线程是以什么样的顺序观察到这些更新。
- 原子性: 访问某个共享变量的操作从其执行线程以外的任何线程来看,该操作要么已经执行结束,要么尚未发生,即其他线程不会“看到” 该操作的中间效果
Java面对的是形形色色的硬件,有的CPU是强内存模型,有的CPU是弱内存模型,而Java身上的特点就是跨平台,该怎么做到跨平台,Java的选择是建立自己的内存模型,在强和弱之间,选择了自己的模型,给出一组规则回答可见性这个并发的最根本问题,根据这些规则我们可以推测出在各个平台上的行为,以这种方式做到跨平台。就像是开篇写的,在月球上物体会下落,在地球上物体也会下落,但是下落的速度不同,这是物理规律的均匀性。而JMM的规则在各个平台上也具备这种均匀性。
写在最后
JDK 9开始对JMM进行调整,但不要担心,没有做破坏性更新,依旧兼容从前,我原本想在这一篇一口气把这些都介绍,但是发现文章篇幅已经很大了,我总是雄心勃勃想在一篇文章将一切都将清楚,但是想做的东西太多,有的时候我可能潜意识里面也畏惧这么多内容,有的时候甚至畏惧开始写这方面的内容。于是我将JDK 9之上,JMM做的调整移动到下一篇。以前我不懂JMM提供的happens-before规则,但也不影响我使用并发编程,原因在于JMM的happens-before规则也是贴合直觉的。操作系统的课程在B站看了两个《【哈工大】操作系统 李治军(全32讲)》、《清华 操作系统原理》,李治军老师讲进程的时候,是从提升CPU的利用率来说的,《清华 操作系统原理》是从系统要运行两个相同的程序来说的,感觉引出进程这个概念来说,李治军老师讲的更好。 在写这篇文章的时候,也一直在回溯自己关于对操作系统的理解,讲多线程、多进程,不仅仅从语言本身来说,总体站在操作系统的角度来说,很多问题不能仅仅从语言本身来说,思路容易狭窄。
参考资料
[1] 清华 操作系统原理 https://www.bilibili.com/video/BV1uW411f72n?p=8&vd_source=aae…
[2] SR 133 (Java Memory Model) http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html
[3]【哈工大】操作系统 李治军(全32讲) https://www.bilibili.com/video/BV19r4y1b7Aw?p=8&vd_source=aae…
[4] Happens-Before原则深入解读 https://juejin.cn/post/7124504859247804424
[5] Java 并发编程之 JMM & volatile 详解 https://juejin.cn/post/6916331359258542087#heading-7
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
