

写在前面
我们平时部署web服务,当服务压力大撑不住的时候,我们会加机器(加钱);一般没有上容器编排是手动加的,临时加的机器,临时部署的服务还要改Nginx的配置,最后回收机器的时候,也是手动回收,手动修改Nginx的,挺麻烦的其实;
而K8s是支持这整个流程的自动化的,也就是HPA;
HPA介绍
HPA:全称Horizontal Pod Autoscaler ,对应中文叫Pod的自动水平伸缩;
Pod的水平伸缩是水平方向增加/减少Pod的数量;
Pod的垂直伸缩则是垂直方向上控制Pod的硬件,比如增加/缩减CPU、内存等资源;
k8s的HPA一般会根据一个具体的指标来做,比如常见CPU、内存的负载;也可以根据web服务的吞吐量、单位时间内的传输字节数等;另外还可以根据自定义的指标,比如RabbitMQ的队列数量、Webhook等;
我这里先讲讲怎么根据CPU、内存的负载来做HPA;
HPA实操
环境
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.5"
Server Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.5"
$ kubectl get node
NAME STATUS ROLES AGE VERSION
docker-desktop Ready control-plane,master 177d v1.22.5
检查获取指标是否正常
是否安装了metrics-server
HPA是需要获取具体的指标做伸缩的, metrics-server是提供指标的
$ kubectl get pod -n kube-system|grep metrics-server
metrics-server-5d78c4b4f5-x5c46 1/1 Running 2 (3d12h ago) 10d
是否正常获取指标
$ kubectl top node
docker-desktop 133m 0% 2671Mi 16%
如果没有的,需先安装metrics-server
安装metrics-server
下载yaml
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
修改yaml
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls #加上这个(不推荐生产这样用)
#image: k8s.gcr.io/metrics-server/metrics-server:v0.6.1 #这个镜像需要梯子
image: registry.cn-hangzhou.aliyuncs.com/chenby/metrics-server:v0.6.1 #换成网友阿里云的镜像
imagePullPolicy: IfNotPresent
提交yaml
kubectl apply -f components.yaml -n kube-system
再验证
kubectl get pod -n kube-system|grep metrics-server
kubectl top node
部署一个测试的Pod(Webapi)
创建一个hpa-api.yaml的文件内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-api
spec:
selector:
matchLabels:
app: hpa-api
replicas: 1
template:
metadata:
labels:
app: hpa-api
spec:
containers:
- name: hpa-api
image: gebiwangshushu/hei-ocelot-api:1.0 #这是我写其他文章上传的镜像,代码:https://github.com/gebiWangshushu/Hei.Ocelot.ApiGateway/blob/master/Hei.Api/Controllers/WeatherForecastController.cs
ports:
- containerPort: 80
resources:
requests:
cpu: 1000m
memory: 100Mi
# limits:
# cpu: 100m
# memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:
name: hpa-api
labels:
app: hpa-api
spec:
ports:
- port: 80
nodePort: 30999
type: NodePort
selector:
app: hpa-api
kubectl apply -f hpa-api.yaml
这里创建了一个测试的webapi,所用镜像是gebiwangshushu/hei-ocelot-api:1.0,源码在这;这个Deployment的副本数是1,资源requests为cpu: 1000m memory: 100Mi;并且创建了一个nodePort:30999 类型的Service;
访问看看:
172.16.6.90 是我自己k8s集群的地址;测试的webapi部署好了,我们来给他创建一个HPA(HorizontalPodAutoscaler);
创建HPA–HorizontalPodAutoscaler
查看当前HPA支持版本:
$ kubectl api-versions|grep autoscaling
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
autoscaling/v1: 只支持基于CPU的自动伸缩
autoscaling/v2beta1: 支持Resource Metrics(资源指标,如pod的CPU)和Custom Metrics(自定义指标)的缩放。
autoscaling/v2beta2:支持Resource Metrics(资源指标,如pod的CPU)和Custom Metrics(自定义指标)和ExternalMetrics(额外指标)的缩放。
创建一个HPA.yaml的文件,内容如下:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-api
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment #针对Deployment做伸缩
name: hpa-api
minReplicas: 1 #最小副本数
maxReplicas: 10 #最大副本数
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization #Utilization 使用率做指标
averageUtilization: 50 #CPU平均使用率超requests要求的cpu的50%时,开始做扩容
#type: averageValue
#averageValue: 30 #使用平均值averageValue(平均值) 做指标
-
type: Utilization #Utilization 表示用使用率作为指标,此外还有Value 或 AverageValue
-
averageUtilization: 50 表示CPU平均使用率超requests要求的cpu的50%时,开始做扩容
-
apiVersion: autoscaling/v2beta2 autoscaling的版本,不同版本的字段和支持的指标不一样;
当然,这里的apiVersion: autoscaling/v2beta2 ,支持还支持很多参数,例如:
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60 #CPU平均负载超requests60%时,开始做扩容
# - type: Resource
# resource:
# name: cpu
# target:
# type: AverageValue
# averageValue: 500m
# - type: Pods #Pods类型的指标
# pods:
# metric:
# name: packets-per-second
# target:
# type: AverageValue
# averageValue: 1k
# - type: Object
# object:
# metric:
# name: requests-per-second
# describedObject:
# apiVersion: networking.k8s.io/v1
# kind: Ingress
# name: main-route
# target:
# type: Value
# value: 10k
# behavior: #控制伸缩行为速率的
# scaleDown:
# policies: #支持多个策略
# - type: Pods
# value: 4
# periodSeconds: 60 #60秒内#最多缩容4个pod
# - type: Percent
# value: 300
# periodSeconds: 60 #60秒内#最多缩容300%
# selectPolicy: Min
# stabilizationWindowSeconds: 300
# scaleUp:
# policies:
# - type: Pods
# value: 5
# periodSeconds: 60 #60秒内#最多缩容5个pod
# # - type: Percent
# # value: 100 #最多扩容100%
# # periodSeconds: 60 #60秒内
# selectPolicy: Max
# stabilizationWindowSeconds: 0
metrics中的type字段有四种类型的值:Object、Pods、Resource、External。
- Resource:指的是当前伸缩对象下的pod的cpu和memory指标,只支持Utilization和AverageValue类型的目标值。
- Object:指的是指定k8s内部对象的指标,数据需要第三方adapter提供,只支持Value和AverageValue类型的目标值。
- Pods:指的是伸缩对象(statefulSet、replicaController、replicaSet)底下的Pods的指标,数据需要第三方的adapter提供,并且只允许AverageValue类型的目标值。
- External:指的是k8s外部的指标(比如prometheus),数据同样需要第三方的adapter提供,只支持Value和AverageValue类型的目标值。
另外还有自定义指标等,需要1.23及以上版本才支持了;
创建HPA资源
kubectl apply -f HPA.yaml
查看HPA
$ kubectl get hpa
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
aspnetcore hpa-api Deployment/hpa-api 0%/50% 1 10 1 8d
验证
hpa开启watch监控模式
$ kubectl get hpa --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-api Deployment/hpa-api 0%/50% 1 10 1 8d
...
#阻塞监听状态
用ab压测工具压一下
ab -n 200000 -c 10 http://172.16.6.90:30999/user
没安装的自己搜索安装下,这里的 -n:请求个数,-c : 请求并发数
查看资源使用情况
$ kubectl top po
NAME CPU(cores) MEMORY(bytes)
hpa-api-88ddc5c49-2vgjd 1m 301Mi
hpa-api-88ddc5c49-4h5pz 1m 300Mi
hpa-api-88ddc5c49-8c8d2 1m 340Mi
hpa-api-88ddc5c49-8hmnm 1m 300Mi
hpa-api-88ddc5c49-cgxm9 1m 23Mi
hpa-api-88ddc5c49-tdrc6 1m 23Mi
扩容情况
kubectl get hpa --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-api Deployment/hpa-api 0%/50% 1 10 1 8d
hpa-api Deployment/hpa-api 262%/50% 1 10 1 8d
hpa-api Deployment/hpa-api 33%/50% 1 10 4 8d
hpa-api Deployment/hpa-api 0%/50% 1 10 6 8d #这里请求结束了
伸容过程
$ kubectl describe hpa hpa-api
Name: hpa-api
...
Reference: Deployment/hpa-api
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 262% (2628m) / 50% #这里资源直接远超1000m的50%,达到了262% (2628m)
Deployment pods: 1 current / 4 desired
..
Deployment pods: 1 current / 4 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 4
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True ScaleUpLimit the desired replica count is increasing faster than the maximum scale rateEvents:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 39s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target #扩容到4个
Normal SuccessfulRescale 3m11s horizontal-pod-autoscaler New size: 6; reason: All metrics below target #扩容到6个
一旦 CPU 利用率降至 0,HPA 会自动将副本数缩减为 1;
扩容详情
HPA 控制器基于 Master 的 kube-controller-manager 服务启动参数 –horizontal-pod-autoscaler-sync-period 定义的探测周期(默认值为 15s) , 周期性地监测目标 Pod 的资源性能指标, 并与 HPA 资源对象中的扩缩容条件进行对比, 在满足条件时对 Pod 副本数量进行调整。
在每个时间段内,控制器管理器都会根据每个 HorizontalPodAutoscaler 定义中指定的指标查询资源利用率。 控制器管理器找到由 scaleTargetRef 定义的目标资源,然后根据目标资源的 .spec.selector 标签选择 Pod, 并从资源指标 API(针对每个 Pod 的资源指标)或自定义指标获取指标 API(适用于所有其他指标)。
-
对于按 Pod 统计的资源指标(如 CPU),控制器从资源指标 API 中获取每一个 HorizontalPodAutoscaler 指定的 Pod 的度量值,如果设置了目标使用率, 控制器获取每个 Pod 中的容器资源使用 情况, 并计算资源使用率。如果设置了 target 值,将直接使用原始数据(不再计算百分比)。 接下来,控制器根据平均的资源使用率或原始值计算出扩缩的比例,进而计算出目标副本数。
需要注意的是,如果 Pod 某些容器不支持资源采集,那么控制器将不会使用该 Pod 的 CPU 使用率。
-
如果 Pod 使用自定义指示,控制器机制与资源指标类似,区别在于自定义指标只使用 原始值,而不是使用率。
-
如果 Pod 使用对象指标和外部指标(每个指标描述一个对象信息)。 这个指标将直接根据目标设定值相比较,并生成一个上面提到的扩缩比例。 在
autoscaling/v2beta2版本 API 中,这个指标也可以根据 Pod 数量平分后再计算。
HorizontalPodAutoscaler 的常见用途是将其配置为从(metrics.k8s.io、custom.metrics.k8s.io 或 external.metrics.k8s.io)获取指标。 metrics.k8s.io API 就是我们前面安装Metrics Server 的插件;
扩容算法
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]
例如,如果当前指标值为
200m,而期望值为100m,则副本数将加倍, 因为200.0 / 100.0 == 2.0如果当前值为50m,则副本数将减半, 因为50.0 / 100.0 == 0.5。如果比率足够接近 1.0(在全局可配置的容差范围内,默认为 0.1), 则控制平面会跳过扩缩操作。
套入上面的实例:
期望副本数 = ceil[ 1 * (262% / 50%)] == 6
类似本实例的示意图:
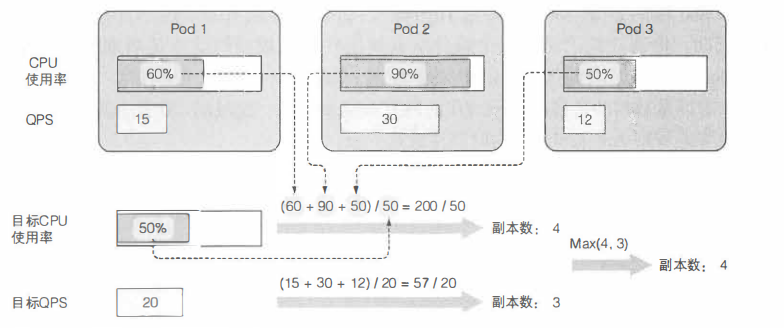
可以看到这里的指标,是针对所有pod的;
总结
k8s的东西太多,只学了点皮毛,有个基本的概念就赶紧记下来;k8s集群版本、HPA的版本的不同又有很多限制与字段的区别,需要后面更多的实践与学习;
[参考]
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/#algorithm-details
https://blog.51cto.com/smbands/4903843
https://kubernetes.io/zh-cn/docs/reference/kubernetes-api/workload-resources/horizontal-pod-autoscaler-v2beta2/
https://www.cnblogs.com/fanggege/p/12299923.html
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
