

1、概念
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica)分布式消息系统(kafka2.8.0版本之后接触了对zk的依赖,使用自己的kRaft做集群管理,新增内部主体@metadata存储元数据信息),它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
类似产品还有 JBoss、MQ(ActiveMQ、RabbitMQ-erlang、RocketMQ-支持事务型消息)
2、kafka的特性
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒。(RecordAccumulate)
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
3、为什么要使用kafka
① 异步处理
② 服务解耦
③ 流量控制
4、kafka原理解析
消息是kafka的基本单位,消息是一串字节构成的。主要是key、value,key根据一定的策略,将消息体路由到不同的partition分区中。
kafka消息全部持久化到磁盘,其使用日志文件的方式来保存。Partition 以文件的形式存储在文件系统中
命名规则:-

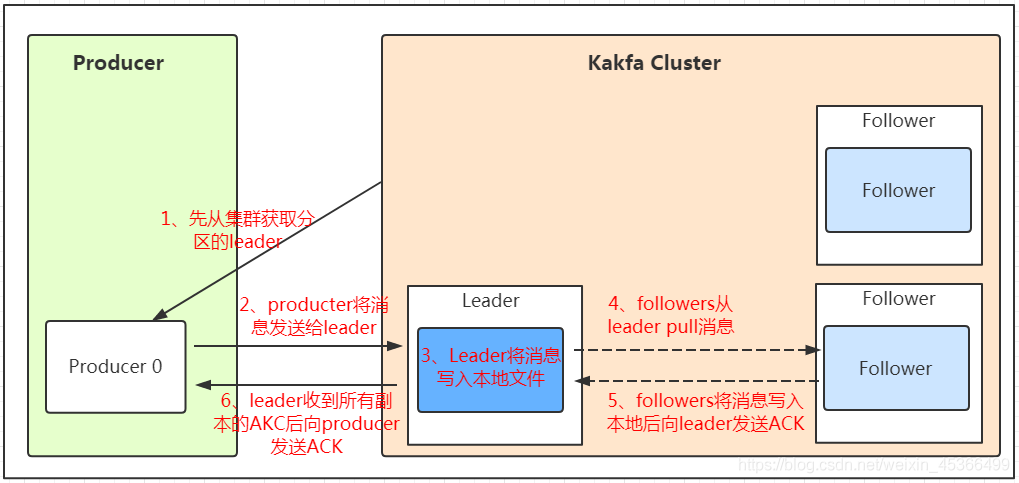
Producer:消息⽣产者,向 Kafka Broker 发消息的客户端。
Consumer:消息消费者,从 Kafka Broker 取消息的客户端。Kafka支持持久化,生产者退出后,未消费的消息仍可被消费。
Consumer Group:消费者组(CG),消费者组内每个消费者负责消费不同分区的数据,提⾼消费能⼒。⼀个分区只能由组内⼀个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的⼀个订阅者。
Broker:⼀台 Kafka 机器就是⼀个 Broker。⼀个集群(kafka cluster)由多个 Broker 组成。⼀个 Broker 可以容纳多个 Topic。
Controller:由zookeeper选举其中一个Broker产生。它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。Broker都在ZooKeeper的Controller节点上注册一个Watcher,当controller发生故障的时候,注册在其上的Watcher会被触发,竞选成为新的controller
Topic:可以理解为⼀个队列,Topic 将消息分类,⽣产者和消费者⾯向的是同⼀个 Topic。
Partition:为了实现扩展性,提⾼并发能⼒,⼀个⾮常⼤的 Topic 可以分布到多个 Broker上,⼀个 Topic 可以分为多个 Partition,同⼀个topic在不同的分区的数据是不重复的,每个 Partition 是⼀个有序的队列,其表现形式就是⼀个⼀个的⽂件夹。不同Partition可以部署在同一台机器上,但不建议这么做。
Replication:每⼀个分区都有多个副本,副本的作⽤是做备胎。当主分区(Leader)故障的时候会选择⼀个备胎(Follower)上位,成为Leader。在kafka中默认副本的最⼤数量是10个,且副本的数量不能⼤于Broker的数量,follower和leader绝对是在不同的机器,同⼀机器对同⼀个分区也只可能存放⼀个副本(包括⾃⼰)。
Message:每⼀条发送的消息主体。
Leader:每个分区多个副本的“主”副本,⽣产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。
Follower:每个分区多个副本的“从”副本,使用发布订阅模式主动拉取Leader的数据(与redis不同),实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发⽣故障时,某个 Follower 还会成为新的 Leader。
Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
ZooKeeper:Kafka 集群能够正常⼯作,需要依赖于 ZooKeeper,ZooKeeper 帮助 Kafka存储和管理集群信息。
High Level API 和Low Level API :高水平API,kafka本身定义的行为,屏蔽细节管理,使用方便;低水平API细节需要自己处理,较为灵活但是复杂。
kafka的高吞吐量
1,数据批量发送
kafka消息从producer发送出去时并不是一条一条发送的,而是先发送到一个消息批次(RecordAccumulate)中,然后由sender线程异步的将消息批次中的消息发到broker。这也是kafka吞吐量高的主要原因之一

消息发送 —> 放入队列 —> 申请内存 —> 消费消息

之所以用到CopyOnWriteMap (采用写时复制),读不需要加锁,适用于读多写少的情况。而kafka只有当某个topic+partition下的第一条消息进行写入时才会写入数据,大部分情况都是读,符合读多写少的情况。
kafka的高可用

每个partition分区至少有一个副本,各个副本同步leader副本,一主多从的模式。
- AR:分区中的所有 Replica 统称为 AR
- ISR:所有与 Leader 副本保持一定程度同步的Replica(包括 Leader 副本在内)组成 ISR
- OSR:与 Leader 副本同步滞后过多的 Replica 组成了 OSR
有效的分区副本是一个ISR集合,ISR集合保存服务器托管网的是有效的副本集合,如果发现某一个副本同步非常慢,则可以自动剔除。leader副本和fllower副本同步的时候会有延迟,但是只要未超过阈值都是可以接受的
ISR集合的存在只要是解决分区leader和follwer 同步复制和异步复制带来的问题
持同步不是指与Leader数据保持完全一致,只需在replica.lag.time.max.ms时间内与Leader保持有效连接
Follower周期性地向Leader发送FetchRequest请求,发送时间间隔配置在replica.fetch.wait.max.ms中,默认值为500ms
极端情况下,如果ISR集合内的所有节点都down了,有两种情况:
1,等待ISR集合中的某一个节点恢复并担任leader
2,选择所有节点(包含ISR之外的) 第一个恢复的担当leader
那么目前kafka的策略是第二点,这样会有一个问题就是ISR集合之外的节点可能数据不全,会和有效ISR集合内节点的数据有出入,造成数据不准确,但是保持了可用性
ACK机制
① 0:生产者无需等待服务端的任何确认,消息被添加到生产者套接字服务器托管网缓冲区后就视为已发送,因此acks=0不能保证服务端已收到消息
② 1:只要 Partition Leader 接收到消息而且写入本地磁盘了,就认为成功了,不管它其他的 Follower 有没有同步过去这条消息了
③ all:Leader将等待ISR中的所有副本确认后再做出应答,因此只要ISR中任何一个副本还存活着,这条应答过的消息就不会丢失
2,磁盘的顺序读写
3,数据压缩传输
4,topic划分多个partition分区,提高并发能力
kafka高性能
普通文件读取:
磁盘文件 –①-> 内核缓冲区 –②-> 用户缓存区 –③-> 内核socket缓存区 –④-> 网卡接口 —> 消费者
零拷贝技术
磁盘文件 –①-> 内核缓冲区 –②(transferTo)-> 网卡接口 —> 消费者
划重点: 零拷贝并不是不需要拷贝,而是减少拷贝的次数。
DMA
DMA技术使得 数据文件在各个层之间的传输,则可以直接绕过CPU。
linux系统中,零拷贝依赖于底层的sendfile() 方法实现,java中,FileChannel.transfeTo方法的底层实现了sendfile方法。


kafka消费方式
推拉结合:生产者push,消费组pull
① enable.auto.commit 是否自动提交自己的offset值;默认值时true
② auto.commit.interval.ms 自动提交时长间隔;默认值时5000 ms
③ consumer.commitSync(); offset提交命令;
at most onece:最多消费一次,存在数据丢失的情况
at least once:最少消费一次,保证数据不丢,存在重复消费 (kafka默认消费方式)
exactly once:精确一次,无论何种情况下,消息只会消费一次 (依赖于外部存储系统协调)
最多一次、最少一次的主要区别:是消费消息再记录offset还是先记录offset再消费消息。
5、kafka消息丢失问题
场景:
消费端从leader副本poll了一批消息消费之后,leader副本挂机了,之后从ISR选举出的副本中的消息可能是比leader少了的。如果此时consumer处理完这批数据提交offset,消费端会丢失这部分新产生而在kafka中实实在在保存着的数据。
解决方式:
HW(high Watermark)高水位
它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息。
分区 ISR 集合中的每个副本都会维护自身的 LEO(Log End Offset):俗称日志末端位移,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
附
1.kafka的消费组如果需要增加组员,最多增加到和partition数量一致,否则超过的组员只会占用资源而没有作用
2.Raft协议是啥? 比较流行的分布式协议算法(leader选举、日志复制)
3.分区设置:一天一亿消息大致分为8个分区资源可满足。
参考: https://www.jianshu.com/p/6cbe28a44543
作者:京东零售张继
来源:京东云开发者社区 转载请注明来源
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
