
我们为什么需要学习Kotlin协程呢?
我们已经有了成熟的JVM库,比如RxJava或Reactor。此外,Java本身就支持多线程,很多人也服务器托管网选择使用普通的回调函数。很明显,我们已经有了很多选项来执行异步操作。 Kotlin协程提供了更多的功能。它们是一个概念的实现,该概念最早在1963年被描述,但等待了多年才获得适合实际产业应用的实现。Kotlin协程将半个世纪前的强大能力与适用于实际用例的库相连接。此外,Kotlin协程是多平台的,这意味着它们可以在所有Kotlin平台上使用(如JVM、JS、iOS以及通用模块)。最后,它们不会大幅改变代码结构。我们几乎可以毫不费力地使用大多数Kotlin协程的功能(这对RxJava或回调函数是不适用的),这使它们非常适合初学者使用。 让我们来实际操作一下。我们将探讨协程和其他众所周知的方法是如何解决不同的常见用例的。我将展示两个典型的用例:Android和后端业务逻辑实现。让我们从第一个开始.
在Android(和其他前端平台)上的协程
我们大部分的工作可能是这样的逻辑:
- 从某个数据源(也可能是多个)获取数据
- 处理数据
- 将数据处理结果显示在ui上. 现在假设我们有一些信息要加载, 并显示在ui上. 大体的逻辑差不多是这样的:
fun onCreate() {
val news = getNewsFromApi() val sortedNews = news
.sortedByDescending { it.publishedAt }
view.showNews(sortedNews)
}很遗憾,这并不是那么容易实现的。在 Android 中,每个应用程序只有一个可以修改视图的线程。这个线程非常重要,不应该被阻塞。这就是为什么上面的函数不能以这种方式实现的原因。如果它在主线程上启动,getNewsFromApi 将阻塞它,我们的应用程序将崩溃。如果我们在另一个线程上启动它,当我们调用 showNews 时,我们的应用程序将崩溃,因为它需要在主线程上运行。
线程切换
我们可以通过切换线程来解决这些问题,首先切换到一个可以被阻塞的线程,然后再切换回主线程
fun onCreate() {
thread {
val news = getNewsFromApi() val sortedNews = news
.sortedByDescending { it.publishedAt }
runOnUiThread {
view.showNews(sortedNews)
}
}
}这种线程切换方法在一些应用程序中仍然可以发现,但是因为以下几个原因而被认为是有问题的:
- 这里没有机制来取消这些线程,因此我们经常面临内存泄漏的问题。
- 制造过多的线程会导致成本高昂
- 频繁切换线程很容易让人困惑且难以管理, 复杂性提高, 可维护性下降
- 代码将变得更加冗长复杂
为了更好地理解这些问题,想象一下以下情况:您打开并快速关闭了一个视图。在打开过程中,您可能已经启动了多个线程来获取和处理数据。如果不取消它们,它们仍将继续执行任务并尝试修改一个不再存在的视图。这意味着您的设备将进行不必要的工作,在后台可能会出现异常,以及可能会产生其他意外结果。
考虑到所有这些问题,让我们寻找更好的解决方案。
Callbacks
回调函数是另一种可能用于解决我们问题的模式。其思想是使我们的函数非阻塞,但是我们向它们传递一个函数,该函数应在回调函数启动的流程完成后执行。如果我们使用这种模式,我们的函数可能看起来是这样的:
fun onCreate() {
getNewsFromApi { news ->
val sortedNews = news.sortedByDescending { it.publishedAt }
view.showNews(sortedNews)
}
}请注意,这个实现不支持取消。我们可能会制作可取消的回调函数,但这并不容易。不仅每个回调函数需要特别实现以支持取消,而且要取消它们,我们需要单独收集所有对象。
fun onCreate() {
startedCallbacks += getNewsFromApi { news ->
val sortedNews = news.sortedByDescending { it.publishedAt }
view.showNews(sortedNews)
}
}回调架构可以解决这个简单问题,但它也有很多缺点。为了探索这些缺点,让我们讨论一个更复杂的情况,在这个情况中,我们需要从三个远端节点获取数据:
fun showNews() {
getConfigFromApi { config ->
getNewsFromApi(config) { news ->
getUserFromApi { user ->
view.showNews(user, news)
}
}
}
}This code is far from perfect for several reasons:
- 获取新闻和用户数据可能可以并行处理,但我们当前的回调函数架构不支持这样做(使用回调函数实现这一点将会很困难)
- 如前所述,支持取消任务将需要很多额外的工作
- 越来越多的缩进使得这段代码难以阅读(使用多个回调函数的代码通常被认为难以阅读)。这种情况被称为“回调地狱”,在一些较旧的Node.JS项目中特别容易出现:
当我们使用回调函数时,很难控制事件发生的顺序。以下显示进度指示器的方法将无法正常工作:
fun onCreate() {
showProgressBar()
showNews()
hideProgressBar() // Wrong
}进度条将在开始显示新闻进程后立即隐藏,因此实际上是在显示后立即隐藏。要使其工作,我们需要将showNews也改为回调函数。
fun onCreate() {
showProgressBar()
showNews {
hideProgressBar()
}
}这就是为什么回调函数架构对于非平凡情况来说远非完美。让我们来看另一种方法:RxJava和其他响应式流。
RxJava和其他响应式流
在Java(包括Android和后端)中流行的另一种方法是使用响应式流(或反应式扩展):RxJava或其后继者Reactor。使用这种方法,所有操作都发生在可以启动、处理和观察的数据流中。这些流支持线程切换和并发处理,因此它们经常用于并行处理应用程序。 以下是我们如何使用RxJava解决问题的示例:
fun onCreate() {
disposables += getNewsFromApi()
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.map { news ->
news.sortedByDescending { it.publishedAt }
}
.subscribe { sortedNews ->
view.showNews(sortedNews)
}
}上面示例中的disposable用于取消该流(例如,如果用户退出了屏幕)
这绝对比使用回调函数更好:没有内存泄漏,支持取消操作,线程使用合理。唯一的问题是它比较复杂。如果您将其与开头的“理想”代码进行比较(下面也显示了它们的代码),您会发现它们几乎没有共同之处。
fun onCreate() {
val news = getNewsFromApi()
val sortedNews = news.sortedByDescending { it.publishedAt }
view.showNews(sortedNews)
}所有这些函数,例如subscribeOn、observeOn、map或subscribe,都需要学习。取消操作需要显式指定。函数需要返回Observable或Single类中包装的对象。在实践中,当我们引入RxJava时,我们需要重新组织我们的代码。
fun getNewsFromApi(): Single>想想第二个问题,我们需要在显示数据之前调用三个远端数据源。这可以使用RxJava得到很好的解决,但它甚至更加复杂。
fun showNews() {
disposables += Observable.zip(
getConfigFromApi().flatMap { getNewsFromApi(it) },
getUserFromApi(),
Function2 { news: List, config: Config ->
Pair(news, config)
})
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe { (news, config) ->
view.showNews(news, config)
}
}这段代码确实是并发的,并且没有内存泄漏,但我们需要引入RxJava函数,例如zip和flatMap,将一个值打包成Pair,然后解构它。这是一个正确的实现,但非常复杂。因此,最后让我们看看协程为我们提供了什么。
使用kotlin协程
Kotlin协程引入的核心功能是能够在某个点上暂停协程并在未来恢复它的能力。由于这个功能,我们可以在主线程上运行代码,并在请求API数据时暂停它。当协程被暂停时,线程不会被阻塞,而是可以自由使用,因此它可以用于更改视图或处理其他协程。一旦数据准备好了,协程就会等待主线程(这是一个罕见的情况,但可能会有一组协程在等待它);一旦获得了线程,它就可以从停止的地方继续执行。
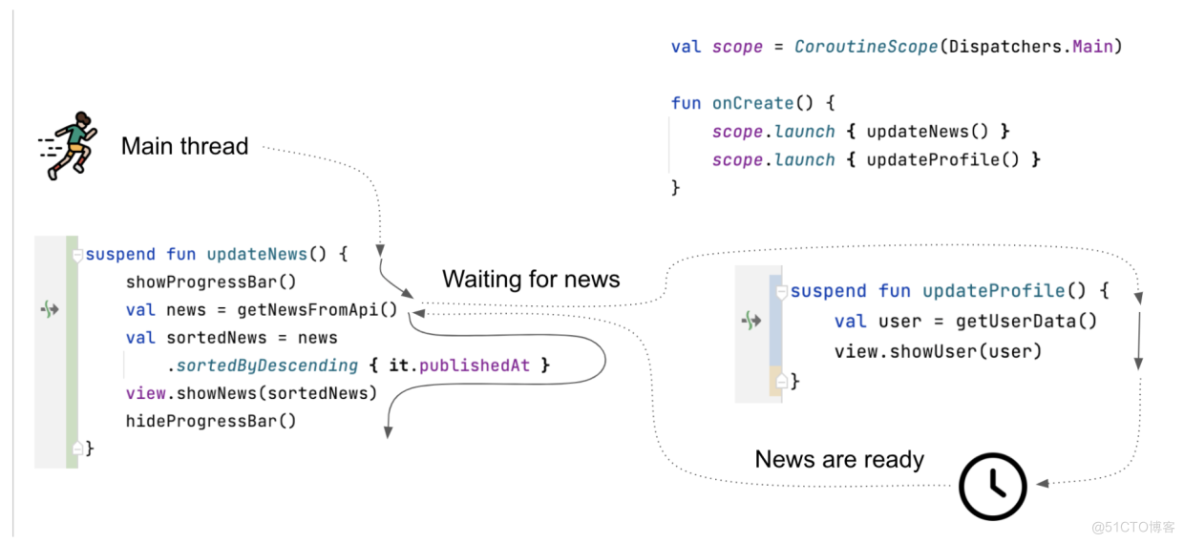
这张图片展示了updateNews和updateProfile函数在独立的协程中在主线程上运行。它们可以交替执行,因为它们挂起它们的协程而不是阻塞线程。当updateNews函数等待网络响应时,主线程被updateProfile使用。在这里,假设getUserData没有暂停,因为用户数据已经被缓存,因此它可以一直运行到完成。这不足以为网络响应提供足够的时间,因此此主线程空闲(它可以被其他函数使用)。一旦数据出现,我们会获取主线程并将其用于updateNews函数,从getNewsFromApi()之后的位置开始。 (你可以把这个动作想象成handler机制中post了一个消息给主线程handler, 并执行, 而执行的代码逻辑就是updateNews()中getNewsFromApi()之后的代码, 其实底层也是这么实现的)
根据定义,协程是可以被暂停和恢复的组件。像JavaScript、Rust或Python等语言中可以找到的async/await和generators等概念也使用了协程,但它们的能力非常有限。
因此,我们可以通过以下方式使用Kotlin协程来解决我们的第一个问题:
fun onCreate() {
viewModelScope.launch {
val news = getNewsFromApi()
val sortedNews = news.sortedByDescending { it.publishedAt }
view.showNews(sortedNews)
}
}如此的自然, 就像没有修改过一样
在上面的代码中,我使用了viewModelScope,它目前在Android上很常见。我们也可以使用自定义作用域。稍后我们将讨论两个选项。
这段代码几乎与我们一开始想要的完全相同!在此解决方案中,代码在主线程上运行,但从不阻塞它。由于挂起机制,我们在需要等待数据时挂起(而不是阻塞)协程。当协程被挂起时,主线程可以做其他事情,比如绘制美丽的进度条动画。一旦数据准备好了,我们的协程再次占用主线程,并从先前停止的地方开始执行。 那么另一个涉及三个调用的问题呢?类似地解决:
fun showNews() {
viewModelScope.launch {
val config = getConfigFromApi()
val news = getNewsFromApi(config服务器托管网)
val user = getUserFromApi() view.showNews(user, news)
}
}这个解决方案看起来不错,但它的工作方式并不是最优的。这些调用将按顺序进行(一个接一个),因此如果每个调用需要1秒钟,整个函数将需要3秒钟,如果我们能让前两个请求并行执行, 就能在2秒钟完成,它提供了像async这样的函数,可以用于立即启动另一个协程并等待其结果稍后到达(使用await函数)。
fun showNews() {
viewModelScope.launch {
val config = async { getConfigFromApi() }
val news = async { getNewsFromApi(config.await()) }
val user = async { getUserFromApi() }
view.showNews(user.await(), news.await())
}
}这段代码仍然简单易读。它使用了在其他语言中广泛使用的async/await模式,包括JavaScript或C#。它还是高效的,不会引起内存泄漏。代码既简单又实现良好。 使用Kotlin协程,我们可以轻松实现不同的用例并使用其他Kotlin特性。例如,它们不会阻止我们使用for循环或集合处理函数。下面,您可以看到如何并行下载下一页或一个接一个地下载它们的示例代码:
// all pages will be loaded simultaneously
fun showAllNews() {
viewModelScope.launch {
val allNews = (0 until getNumberOfPages())
.map { page -> async { getNewsFromApi(page) } }
.flatMap { it.await() }
view.showAllNews(allNews)
}
}
// next pages are loaded one after another
fun showPagesFromFirst() {
viewModelScope.launch {
for (page in 0 until getNumberOfPages()) {
val news = getNewsFromApi(page)
view.showNextPage(news)
}
}
}协程在后端的应用
在我看来,使用协程在后端的最大优势就是简单性。与RxJava不同,使用协程几乎不会改变我们代码的外观。在大多数情况下,从线程迁移到协程只需要添加suspend修饰符。当我们这样做时,我们可以轻松地引入并发,测试并发行为,取消协程,并使用本书中将要探讨的所有其他强大功能。
除了所有这些功能外,使用协程还有一个重要的原因:线程成本高昂。它们需要被创建、维护,并需要分配内存。如果您的应用程序被数百万用户使用,并且每当您等待从数据库或另一个服务的响应时都会阻塞,这将增加显著的内存和处理器使用成本(用于创建、维护和同步这些线程)。
在kotlin中, 协程的本质还是线程, 只是增加了线程池的概念, 因此降低了创建成本.
这个问题可以通过以下代码段来可视化,这个代码段模拟了一个有100,000个用户请求数据的后端服务。第一个代码段启动100,000个线程,让它们睡眠一秒钟(模拟等待来自数据库或其他服务的响应)。如果您在计算机上运行它,您将看到它需要一段时间才能打印所有这些点,或者会因OutOfMemoryError异常而崩溃。这是运行这么多线程的成本。第二个代码段使用协程而不是线程,并将它们暂停而不是使它们睡眠。如果您运行它,程序将等待一秒钟,然后打印所有点。启动所有这些协程的成本是如此之低,以至于几乎不可感知。
// 线程版本
fun main() {
repeat(100_000) {
thread {
Thread.sleep(1000L)
print(".")
}
}
}
// 协程版本
fun main() = runBlocking {
repeat(100_000) {
launch {
delay(1000L)
print(".")
}
}
}结论
我希望现在您已经有了更多了解Kotlin协程的兴趣。它们不仅是一个库,而且使用现代工具可以使并发编程尽可能简单。如果我们已经确定了这一点,那么让我们开始学习吧。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
