
Kubeadm安装高可用k8s 1.23.x
本篇文章参考杜宽的《云原生Kubernetes全栈架构师》,视频、资料文档等,大家可以多多支持!
1. 高可用架构
1.1 架构图

Kubernetes是属于主从设备模型(Master-Slave架构),即有Master节点负责核心的调度、管理和运维,Slave节点则执行用户的程序。在Kubernetes中,主节点一般被称为Master Node 或者 Head Node,而从节点则被称为Worker Node 或者 Node。
Tips:Master节点通常包括API Server、Scheduler、Controller Manager等组件,Node节点通常包括Kubelet、Kube-Proxy等组件!
看到蓝色框内的Control Plane,这个是整个集群的控制平面,相当于是master进程的加强版。k8s中的Control Plane一般都会运行在Master节点上面。在默认情况下,Master节点并不会运行应用工作负载,所有的应用工作负载都交由Node节点负责。
控制平面中的Master节点主要运行控制平面的各种组件,它们主要的作用就是维持整个k8s集群的正常工作、存储集群的相关信息,同时为集群提供故障转移、负载均衡、任务调度和高可用等功能。对于Master节点一般有多个用于保证高可用,而控制平面中的各个组件均以容器的Pod形式运行在Master节点中,大部分的组件需要在每个Master节点上都运行,少数如DNS服务等组件则只需要保证足够数量的高可用即可。
1.1.1 ectd
ETCD:它是兼具一致性和高可用性的键值key-value数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库,负责保存Kubernetes Cluster的配置信息和各种资源的状态信息,当数据发生变化时,etcd 会快速地通知Kubernetes相关组件。
Kubernetes 集群的 etcd 数据库通常需要有个备份计划。此外还有一种k8s集群部署的高可用方案是将etcd数据库从容器中抽离出来,单独作为一个高可用数据库部署,从而为k8s提供稳定可靠的高可用数据库存储。
Tips:生成环境如果机器配置够高,安装etcd与master安装在一起也OK,也可以单独分离。
1.1.2 kube-apiserver
k8s集群的控制平面的核心是API服务器,而API服务器主要就是由kube-apiserver组件实现的,它被设计为可水平扩展,即通过部署不同数量的实例来进行缩放从而适应不同的流量。API服务器作为整个k8s控制平面的前端,负责提供 HTTP API,以供用户、集群中的不同部分组件和集群外部组件相互通信。(可以通过kubeadm或者kubectl这类的CLI工具来操控API从而控制整个k8s集群,也可以通过其他的Web UI来进行操控)
Tips:工具在背后也是调用 API,包括Web操作。
1.1.3 kube-scheduler
主节点上的组件,该组件监视那些新创建的未指定运行节点的 Pod,并选择节点让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
1.1.4 kube-controller-manager
K8S所有Worker Node的监控器。Controller Manager作为集群内部的管理控制中心,运行在Master节点上,是一个永不休止的循环。它实质上是群内的Node、Pod、服务(Server)、端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的监视与守护进程的合集,每个资源的Controller通过API Server提供的接口实时监控每个资源对象的当前状态,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
其中控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应。
- 副本控制器(Replication Controller): 负责为系统中的每个副本控制器对象维护正确数量的 Pod。
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)。
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌。
1.1.5 kubelet
K8S中Master节点在每个Worker Node节点上运行的主要“节点代理”,也可以说是Master 的“眼线”。它会定期向Master Node汇报自己Node上运行服务的状态,并接受来自Master Node的指示采取调整措施。负责控制由 K8S 创建的容器的启动停止,保证节点工作正常。
1.1.6 kube-proxy
kube-proxy是集群中每个节点上运行的网络代理,负责Node在K8S的网络通讯、以及对外网络流量的负载均衡。 kube-proxy通过维护主机上的网络规则并执行连接转发,实现了Kubernetes服务抽象。
service在逻辑上代表了后端的多个Pod,外界通过service访问Pod。service接收到的请求就是通过kube-proxy转发到Pod上的,kube-proxy服务负责将访问service的TCP/UDP数据流转发到后端的容器。如果有多个副本,kube-proxy会实现负载均衡。
由于性能问题,目前大部分企业用K8S进行实际生产时,都不会直接使用Kube-proxy作为服务代理,而是通过Ingress Controller来集成HAProxy, Nginx来代替Kube-proxy。
1.2 高可用分析
所有从集群(或所运行的 Pods)发出的 API 调用都终止于 API server,而API Server直接与ETCD数据库通讯。若仅部署单一的API server ,当API server所在的 VM 关机或者 API 服务器崩溃将导致不能停止、更新或者启动新的 Pod、服务或副本控制器;而ETCD存储若发生丢失,API 服务器将不能启动。
所以如下几个方面需要做到:
- **集群状态维持:**K8S集群状态信息存储在ETCD集群中,该集群非常可靠,且可以分布在多个节点上。需要注意的是,在ETCD群集中至少应该有3个节点,且为了防止2网络分裂,节点的数量必须为奇数。
- **API服务器冗余灾备:**K8S的API server服务器是无状态的,从ETCD集群中能获取所有必要的数据。这意味着K8S集群中可以轻松地运行多个API服务器,而无需要进行协调,因此我们可以把负载均衡器(LB)放在这些服务器之前,使其对用户、Worker Node均透明。
- **Master选举:**一些主组件(Scheduler和Controller Manager)不能同时具有多个实例,可以想象多个Scheduler同时进行节点调度会导致多大的混乱。由于Controller Manager等组件通常扮演着一个守护进程的角色,当它自己失败时,K8S将没有更多的手段重新启动它自己,因此必须准备已经启动的组件随时准备取代它。高度可扩展的Kubernetes集群可以让这些组件在领导者选举模式下运行。这意味着虽然多个实例在运行,但是每次只有一个实例是活动的,如果它失败,则另一个实例被选为领导者并代替它。
- **K8S高可用:**只要K8S集群关键结点均高可用,则部署在K8S集群中的Pod、Service的高可用性就可以由K8S自行保证。
负载均衡节点设计
负载均衡节点承担着Worker Node集群和Master集群通讯的职责,同时Load Balance没有部署在K8S集群中,不受Controller Manager的监控,倘若Load Balance发生故障,将导致Node与Master的通讯全部中断,因此需要对负载均衡做高可用配置。Load Balance同样不能同时有多个实例在服务,因此使用Keepalived对部署了Load Balance的服务器进行监控,当发生失败时将虚拟IP(VIP)飘移至备份节点,确保集群继续可用。
2. 前期规划及准备
2.1 高可用Kubernetes集群规划
主机规划
|
主机名 |
IP地址 |
说明 |
|
k8s-master01 ~ 03 |
10.0.0.104 ~ 106 |
master节点 * 3 |
|
k8s-master-lb |
10.0.0.236 |
keepalived虚拟IP(不占用机器) |
|
k8s-node01 ~ 02 |
10.0.0.107 ~ 108 |
worker节点 * 2 |
网络规划及版本说明
|
配置信息 |
备注 |
|
系统版本 |
CentOS 7.9 |
|
Docker版本 (containerd) |
20.10.x |
|
Pod网段 |
172.16.0.0/16 |
|
Service网段 |
192.168.0.0/16 |
Tips:宿主机网段、K8s Service网段、Pod网段不能重复!
本方案负载均衡(VIP)在Master上,没有单独做负载均衡双机热备。
|
IP |
角色 |
Hostname |
说明 |
|
10.0.0.104 |
Master |
k8s-master01 |
keepalived、haproxy、kube-apiserver、kube-scheduler、kube-controller-manager |
|
10.0.0.105 |
Master |
k8s-master02 |
keepalived、haproxy、kube-apiserver、kube-scheduler、kube-controller-manager |
|
10.0.0.106 |
Master |
k8s-master03 |
keepalived、haproxy、kube-apiserver、kube-scheduler、kube-controller-manager |
|
10.0.0.107 |
Node |
k8s-node01 |
kubelet、kube-proxy |
|
10.0.0.108 |
Node |
k8s-node02 |
kubelet、kube-proxy |
|
10.0.0.236 |
Virtual IP(VIP) |
k8s-master-lb |
各主机hosts解析需要对应加上这一条10.0.0.36 k8s-master-lb |
2.2 基本环境配置
centos通过单独安装,非克隆。安装完后进行基本环境的配置,配置一下几个方面:
- 设置主机名
- 关闭NetworkManager、firewalld、dnsmasq、selinux
- 设置eth0
- 优化ssh
- 设置时区为Asia/Shanghai
- 备份并新增清华yum源、epel源、docker-ce源、k8s源
- 更新yum源软件包缓存
- 修改history格式及记录数
- 添加hosts解析
- 关闭swap分区
- 安装ntpdate服务,并同步时间
- 配置limits.conf
- 安装必备工具
- 升级系统并重启
在/root目录下创建k8s_system_init.sh,复制以下内容。然后sh /root/k8s_system_init.sh进行基本环境的配置。
此步骤Master及Node节点都需进行!
#!/bin/bash
if [ $# -eq 2 ];then
echo "设置主机名为:$1"
echo "eth0设置IP地址为:10.0.0.$2"
else
echo "使用方法:sh $0 主机名 主机位"
exit 2
fi
echo "--------------------------------------"
echo "1.正在设置主机名:$1"
hostnamectl set-hostname $1
echo "2.正在关闭NetworkManager、firewalld、dnsmasq、selinux"
systemctl disable firewalld &> /dev/null
systemctl disable NetworkManager &> /dev/null
systemctl disable dnsmasq &> /dev/null
systemctl stop firewalld
systemctl stop NetworkManager
systemctl stop dnsmasq
sed -i "s#SELINUX=enforcing#SELINUX=disabled#g" /etc/selinux/config
setenforce 0
echo "3.正在设置eth0:10.0.0.$2"
cat > /etc/sysconfig/network-scripts/ifcfg-eth0 /etc/yum.repos.d/Centos-Base.repo /etc/yum.repos.d/epel.repo /etc/yum.repos.d/kubernetes.repo /dev/null
sed -i 's+https://download.docker.com+https://mirrors.tuna.tsinghua.edu.cn/docker-ce+' /etc/yum.repos.d/docker-ce.repo
echo "7.更新yum源软件包缓存"
yum makecache
echo "8.修改history格式及记录数"
sed -i "s#HISTSIZE=1000##g" /etc/profile
cat >> /etc/profile /dev/null| awk '{print $NF}'|sed -e 's/[()]//g'`
export HISTFILE=~/.commandline_warrior
export HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S `whoami`@${USER_IP}: "
export HISTSIZE=200000
export HISTFILESIZE=1000000
export PROMPT_COMMAND="history -a"
EOF
source /etc/profile
echo "9.添加hosts解析"
cat >> /etc/hosts /dev/null
sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab
echo "11.安装ntpdate服务,并同步时间"
yum install ntpdate -y &> /dev/null
systemctl enabled ntpdate &> /dev/null
systemctl start ntpdate
echo "*/10 * * * * root /usr/sbin/ntpdate ntp1.aliyun.com >/dev/null 2>&1" > /etc/cron.d/ntp_sync
echo "12.配置limits.conf"
ulimit -SHn 65535
cat >> /etc/security/limits.conf /dev/null
echo "14.升级系统并重启"
yum update -y --exclude=kernel* && reboot2.3 内核及ipvs模块配置
此步骤是升级内核、配置ipvs模块,开启一些k8s集群中必须的内核参数。配置一下几个方面:
- 下载安装包到/server/soft
- 安装kernel
- 更改内核启动顺序
- 安装ipvsadm
- 配置ipvs模块
- 开启k8s集群必须的内核参数
- 配置完内核,重启服务器
在/root目录下创建kernel_update.sh,复制以下内容。然后sh /root/kernel_update.sh进行基本环境的配置。
此步骤Master及Node节点都需进行!
#!/bin/bash
echo "1.下载安装包到/server/soft"
mkdir -p /server/soft ; cd /server/soft
wget http://193.49.22.109/elrepo/kernel/el7/x86_64/RPMS/kernel-ml-devel-4.19.12-1.el7.elrepo.x86_64.rpm
wget http://193.49.22.109/elrepo/kernel/el7/x86_64/RPMS/kernel-ml-4.19.12-1.el7.elrepo.x86_64.rpm
echo "2.正在安装kernel"
yum localinstall -y kernel-ml*
echo "3.更改内核启动顺序"
grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg
grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)"
echo "4.输出现在内核版本信息"
grubby --default-kernel
echo "5.安装ipvsadm"
yum install ipvsadm ipset sysstat conntrack libseccomp -y &> /dev/null
echo "6.配置ipvs模块"
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
cat >> /etc/modules-load.d/ipvs.conf /dev/null
echo "7.开启k8s集群必须的内核参数"
cat /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
fs.may_detach_mounts = 1
net.ipv4.conf.all.route_localnet = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_timestamps = 0
net.core.somaxconn = 16384
EOF
sysctl --system
echo "8.配置完内核,重启服务器!"
reboot2.4 检查ipvs加载、内核版本验证
lsmod | grep –color=auto -e ip_vs -e nf_conntrack

uname -a

2.5 高可用组件安装
2.5.1 HAproxy配置
所有Master节点安装Keepalived、HAproxy
yum install keepalived haproxy -y所有Master节点配置HAProxy,所有Master节点的HAProxy配置相同。
# cat /etc/haproxy/haproxy.cfg
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
frontend k8s-master
bind 0.0.0.0:16443
bind 127.0.0.1:16443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server k8s-master01 10.0.0.104:6443 check
server k8s-master02 10.0.0.105:6443 check
server k8s-master03 10.0.0.106:6443 check2.5.2 Keepalived配置
所有Master节点配置Keepalived,以下三个Master节点配置注意ip和网卡。
Master01配置
[root@k8s-master01 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
mcast_src_ip 10.0.0.104
virtual_router_id 51
priority 101
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
10.0.0.236
}
track_script {
chk_apiserver
}
}Master02配置
[root@k8s-master02 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
mcast_src_ip 10.0.0.105
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
10.0.0.236
}
track_script {
chk_apiserver
}
}Master03配置
[root@k8s-master03 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
mcast_src_ip 10.0.0.106
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
10.0.0.236
}
track_script {
chk_apiserver
}
}所有Master节点配置Keepalived健康检查文件
#cat /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $(seq 1 3)
do
check_code=$(pgrep haproxy)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 1
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi赋予执行权限
chmod +x /etc/keepalived/check_apiserv服务器托管网er.sh所有Master节点启动haproxy和keepalived,并设置开机自启动。
systemctl daemon-reload
systemctl enable --now haproxy
systemctl enable --now keepalived2.5.3 测试VIP及HAproxy端口
所有节点测试VIP
#ping 10.0.0.236 -c 2
PING 10.0.0.236 (10.0.0.236) 56(84) bytes of data.
64 bytes from 10.0.0.236: icmp_seq=1 ttl=64 time=0.067 ms
64 bytes from 10.0.0.236: icmp_seq=2 ttl=64 time=0.061 ms随便一台telnet VIP 16443端口,显示^]就说明端口开放的。
[root@k8s-master01 ~]# telnet 10.0.0.236 16443
Trying 10.0.0.236...
Connected to 10.0.0.236.
Escape character is '^]'.
Connection closed by foreign host.2.5.4 故障解决
- 所有节点查看防火墙状态必须为disable和inactive:systemctl status firewalld
- 所有节点查看selinux状态,必须为disable:getenforce
- 如果ping不通且telnet没有出现 ] ,VIP没起来,不可在继续往下执行,需要排查keepalived的问题,比如防火墙和selinux,haproxy和keepalived的状态,监听端口等。
master节点查看haproxy和keepalived状态:systemctl status keepalived haproxy
master节点查看监听端口:netstat -lntp
3. k8s集群安装
3.1 安装Docker作为Runtime
如果选择Docker作为Runtime,安装步骤较Containerd较为简单,只需要安装并启动即可。
所有节点安装docker-ce 20.10:
yum install docker-ce-20.10.* docker-ce-cli-20.10.* -y由于新版Kubelet建议使用systemd,所以把Docker的CgroupDriver也改成systemd:
mkdir /etc/docker
cat > /etc/docker/daemon.json 所有节点设置开机自启动Docker
systemctl daemon-reload && systemctl enable --now docker3.2 安装Kubene服务器托管网tes组件
在Master01节点查看最新的Kubernetes版本是多少,列出 kubeadm软件包的可用版本,并显示重复的版本,最后再进行一个最新版本优先顺序显示。
yum list kubeadm.x86_64 --showduplicates | sort -r安装1.23最新版本kubeadm、kubelet和kubectl**(所有节点均需安装)**
yum install kubeadm-1.23* kubelet-1.23* kubectl-1.23* -y- kubeadm:用来初始化集群的指令。
- kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
- kubectl:用来与集群通信的命令行工具。
设置Kubelet开机自启动**(由于还未初始化,没有kubelet的配置文件,此时kubelet无法启动,无需管理)**
systemctl daemon-reload
systemctl enable --now kubelet3.3 集群初始化
以下操作在master01,vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: 7t2weq.bjbawausm0jaxury
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.0.0.104
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
certSANs:
- 10.0.0.236
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 10.0.0.236:16443
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.23.17 # 更改此处的版本号和kubeadm version一致
networking:
dnsDomain: cluster.local
podSubnet: 172.16.0.0/16
serviceSubnet: 192.168.0.0/16
scheduler: {}更新kubeadm文件
kubeadm config migrate --old-config kubeadm-config.yaml --new-config new.yaml将new.yaml文件复制到其他master节点
scp /root/new.yaml root@10.0.0.105:/root
scp /root/new.yaml root@10.0.0.106:/root之后所有Master节点提前下载镜像,可以节省初始化时间**(其他节点不需要更改任何配置,包括IP地址也不需要更改)**
kubeadm config images pull --config /root/new.yaml三台Master拉取镜像结束如下:
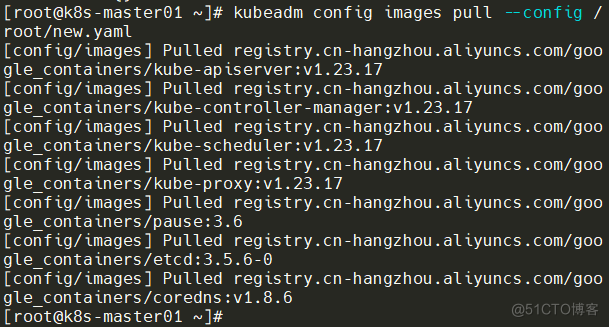
Master01节点初始化,初始化以后会在**/etc/kubernetes目录下生成对应的证书和配置文件,之后其他Master节点加入Master01**即可。
kubeadm init --config /root/new.yaml --upload-certs初始化成功以后,会产生Token值,用于其他节点加入时使用,因此要记录下初始化成功生成的token值(令牌值),有效期24小时,后续需要操作可以重新生成Token
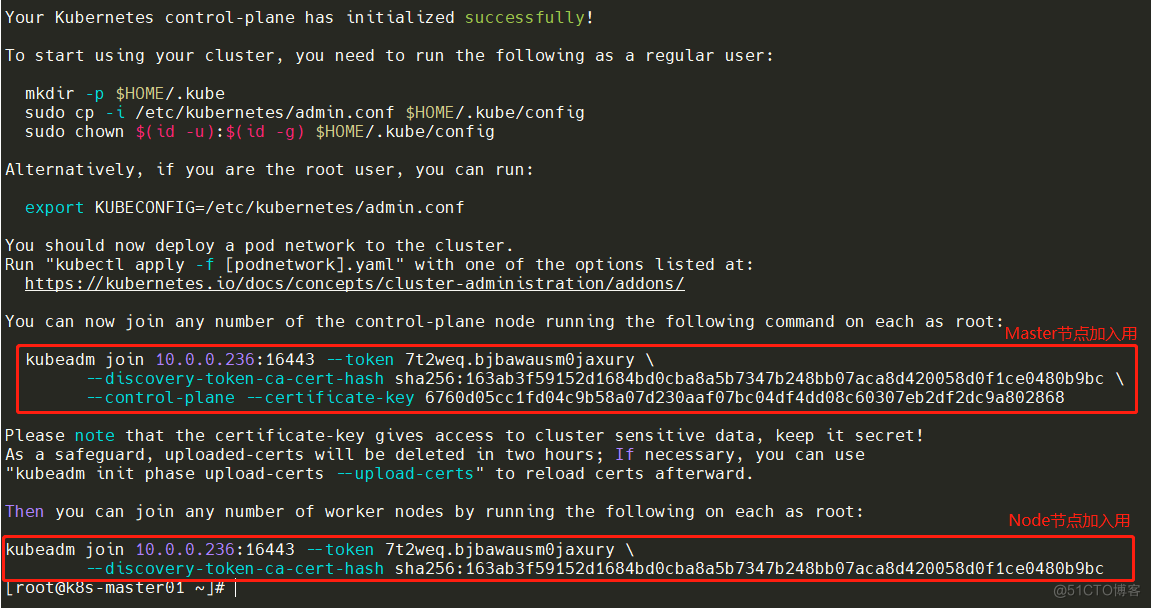
此时通过kubectl操作,会出现失败,因为还没有将集群的”钥匙”交给root用户。/etc/kubernetes/admin.conf 文件是 Kubernetes(K8s)集群中的管理员配置文件,它包含了用于管理集群的身份验证和访问信息。所以下面进行配置环境变量,用于访问Kubernetes集群:
cat > /root/.bashrc
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
source /root/.bashrc此时root用户可以使用 Kubernetes 的命令行工具(例如 kubectl)或其他库来与集群进行交互,执行管理操作,例如创建、更新和删除资源,监视集群状态等。
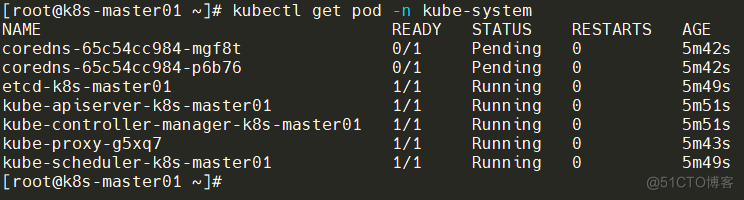
Master01节点查看节点状态:(显示NotReady不影响)

采用kubeadm初始化安装方式,所有的系统组件均以容器的方式运行并且在kube-system命名空间内,此时可以查看Pod状态**(Pending不用管,后续装好Node节点再回来看)**:
3.4 添加Master实现高可用
其他Master加入集群,master02和master03分别执行刚从上面获得的kubeadm join的命令参数。


如果Master01、02节点要操作集群就添加环境变量
cat > /root/.bashrc
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
source /root/.bashrc查看当前node,三个master节点已在集群中。

3.5 模拟Token过期重新生成并加入Node节点
如果集群在运行过一段时间后需要新增Node或者Master节点,此时之前生成的Token会失效,需要重新生成Token。
Token过期后生成新的token:
kubeadm token create --print-join-commandMaster需要生成–certificate-key:
kubeadm init phase upload-certs --upload-certs生成新的Token用于集群添加新Node节点

复制到Node节点执行
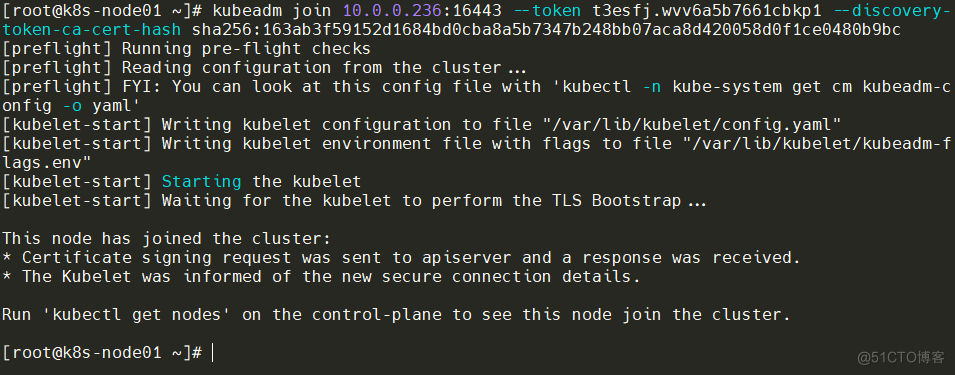
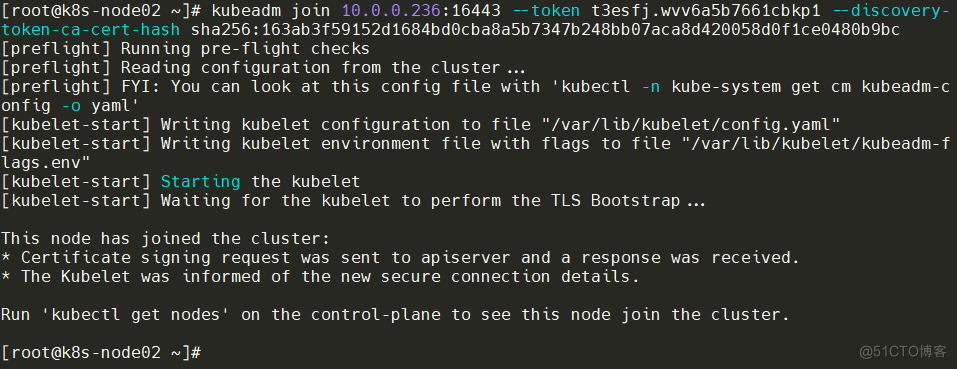
查看当前node,两个Node节点已添加在集群中。
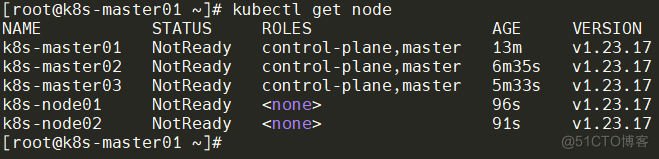
如果是新增Mster节点则拼接Token
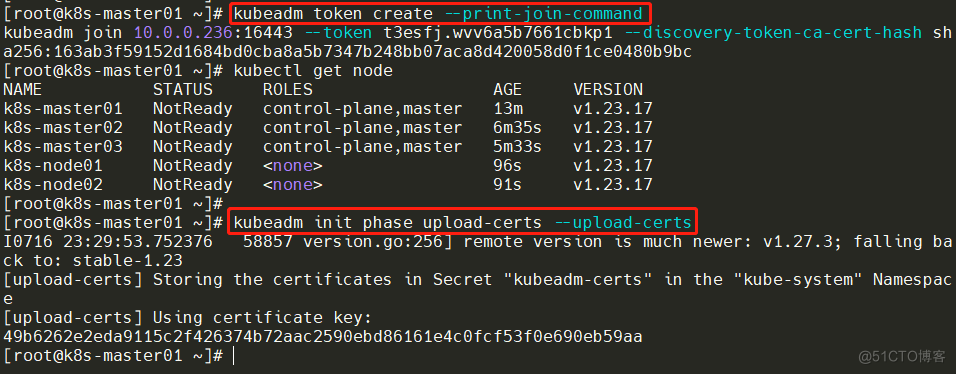
[root@k8s-master01 ~]# kubeadm token create --print-join-command
kubeadm join 10.0.0.236:16443 --token t3esfj.wvv6a5b7661cbkp1 --discovery-token-ca-cert-hash sha256:163ab3f59152d1684bd0cba8a5b7347b248bb07aca8d420058d0f1ce0480b9bc
[root@k8s-master01 ~]# kubeadm init phase upload-certs --upload-certs
I0716 23:29:53.752376 58857 version.go:256] remote version is much newer: v1.27.3; falling back to: stable-1.23
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
49b6262e2eda9115c2f426374b72aac2590ebd86161e4c0fcf53f0e690eb59aa
#拼接如下:
kubeadm join 10.0.0.236:16443 --token t3esfj.wvv6a5b7661cbkp1 --discovery-token-ca-cert-hash sha256:163ab3f59152d1684bd0cba8a5b7347b248bb07aca8d420058d0f1ce0480b9bc --control-plane --certificate-key 49b6262e2eda9115c2f426374b72aac2590ebd86161e4c0fcf53f0e690eb59aa3.6 安装Calico网络插件
git拉取下来k8s-ha-install的仓库
cd /root/ ; git clone https://gitee.com/dukuan/k8s-ha-install.git以下步骤只在master01执行(.x不需要更改)
cd /root/k8s-ha-install && git checkout manual-installation-v1.23.x && cd calico/vim calico.yml 配置文件修改Pod网段,并保存。(大约在配置文件的4365行)

如果不手动在配置文件修改,也可以使用以下命令直接替换。
POD_SUBNET=`cat /etc/kubernetes/manifests/kube-controller-manager.yaml | grep cluster-cidr= | awk -F= '{print $NF}'`
sed -i "s#POD_CIDR#${POD_SUBNET}#g" calico.yaml然后进行安装calico
kubectl apply -f calico.yamlcalico.yaml 是 Calico 的配置清单文件,其中包含了部署 Calico 所需的各种 Kubernetes 资源和配置选项。这个文件定义了 Calico 控制器、网络策略、路由配置等参数。
通过执行 kubectl apply -f calico.yaml 命令,Kubernetes 集群会根据 calico.yaml 文件中的定义创建或更新相关的资源。apply 命令会检查已存在的资源并更新其配置,或者创建新资源。这样,Calico 的组件和配置将被应用到集群中,以实现 Calico 网络和网络策略。
查看集群中 kube-system命名空间下的所有 Pod 的状态信息,已经Running状态。
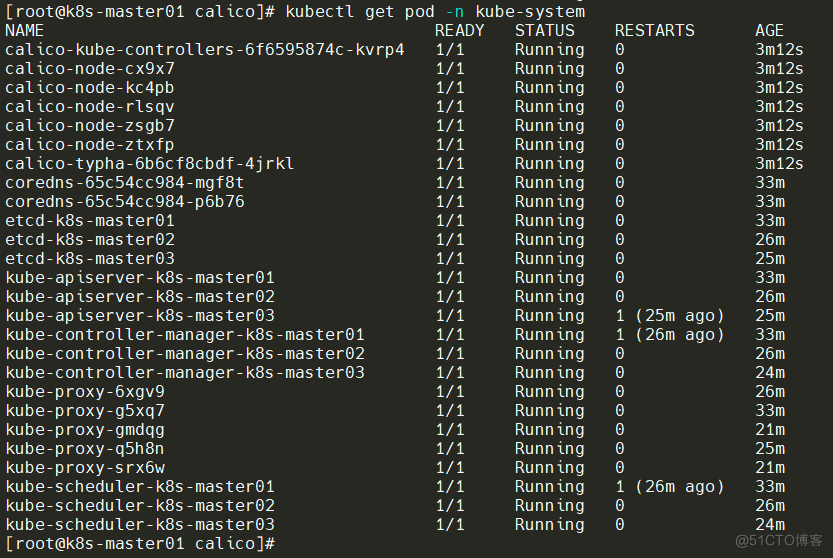
获取 Kubernetes 集群中所有的节点(Node)的状态信息,已经全部Ready状态。

3.7 Metrics部署
在新版(1.8版本开始)的Kubernetes中系统资源的采集均使用Metrics-server,可以通过Metrics采集节点和Pod的内存、磁盘、CPU和网络的使用率。
将Master01节点的front-proxy-ca.crt复制到所有Node节点
scp /etc/kubernetes/pki/front-proxy-ca.crt 10.0.0.107:/etc/kubernetes/pki/front-proxy-ca.crt
scp /etc/kubernetes/pki/front-proxy-ca.crt 10.0.0.108:/etc/kubernetes/pki/front-proxy-ca.crt以下操作均在master01节点执行
cd /root/k8s-ha-install/kubeadm-metrics-server
kubectl create -f comp.yaml查看这个Pod是否起来了,kubectl get po -n kube-system -l k8s-app=metrics-server,OK,已经Running。

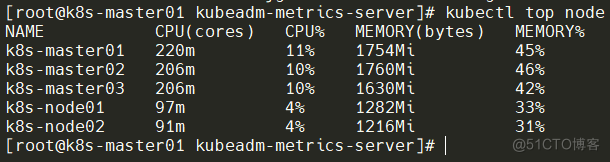
此时可以查看集群中所有节点的资源使用情况,命令:kubectl top node
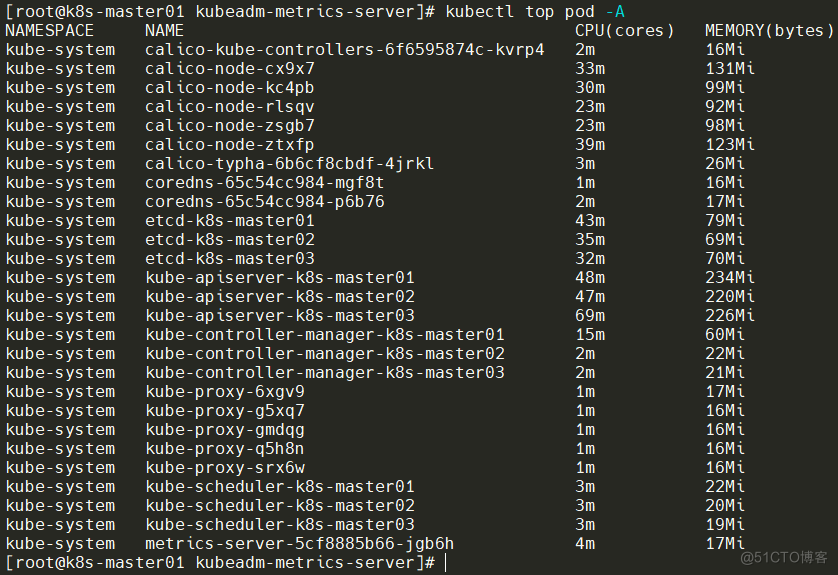
查看所有命名空间底下的Pod资源使用情况,命令:kubectl top pod -A
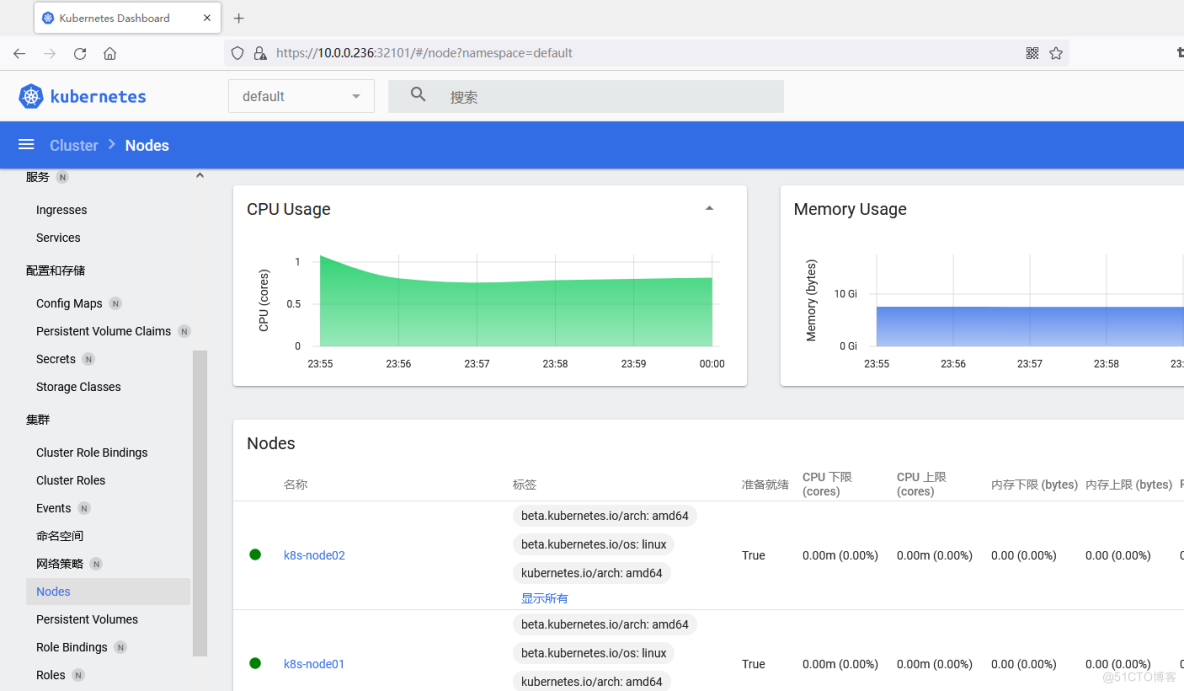
3.8 Dashboard部署
Dashboard用于展示集群中的各类资源,同时也可以通过Dashboard实时查看Pod的日志和在容器中执行一些命令等。
在Master01下执行
cd /root/k8s-ha-install/dashboard/
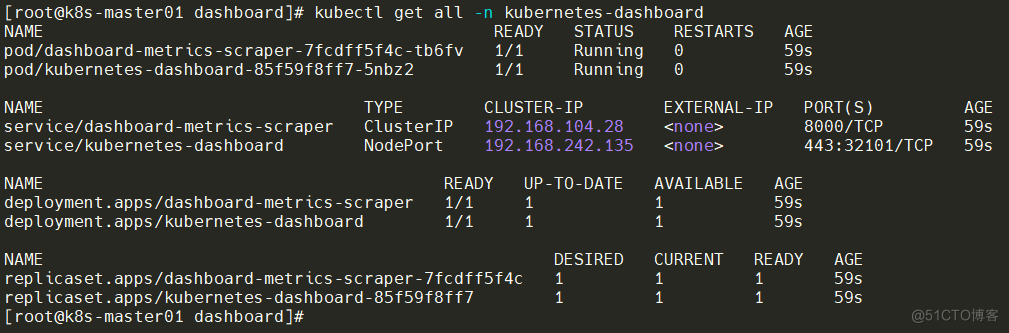
kubectl create -f .kubectl get all -n kubernetes-dashboard 用于获取在 kubernetes-dashboard 命名空间中的所有资源的详细信息。
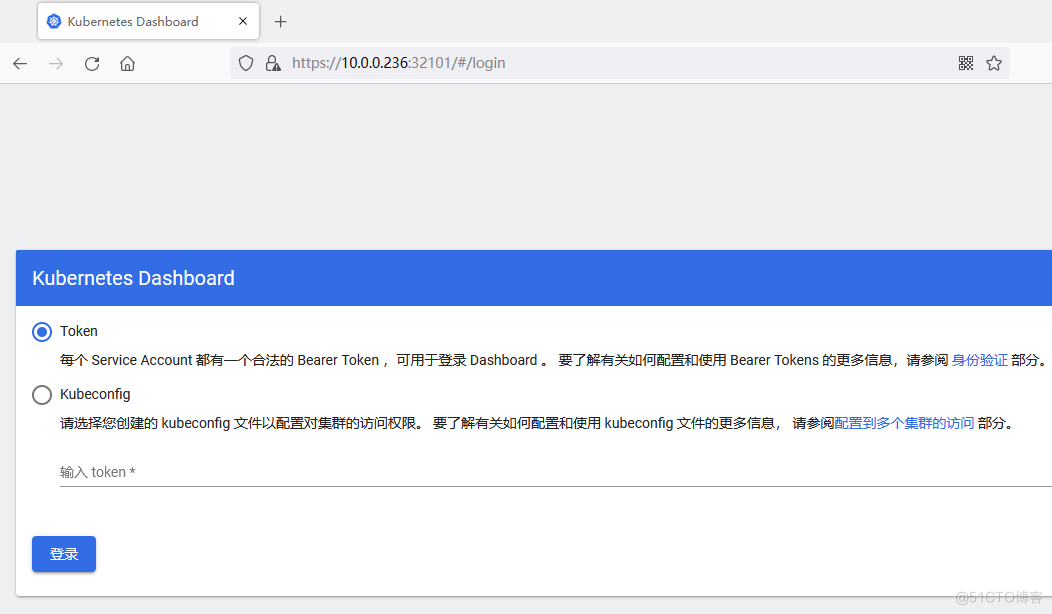
查看端口号kubectl get svc kubernetes-dashboard -n kubernetes-dashboard

根据自己的实例端口号,通过任意安装了kube-proxy的宿主机的IP+端口即可访问到dashboard,或者直接VIP+端口也可访问到dashboard。
创建登录Token
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')将token值输入到令牌后,单击登录即可访问Dashboard。
3.9 必须的配置更改
将kube-proxy改为ipvs模式,因为在初始化集群的时候注释了ipvs配置,所以需要自行修改一下:
#在master01节点执行
kubectl edit cm kube-proxy -n kube-system
#找到mode那一行修改成ipvs
mode: ipvs更新kube-proxy的Pod
kubectl patch daemonset kube-proxy -p "{"spec":{"template":{"metadata":{"annotations":{"date":"`date +'%s'`"}}}}}" -n kube-system验证Kube-Proxy模式
[root@k8s-master01 ~]# curl 127.0.0.1:10249/proxyMode
ipvs4. 集群可用性验证
节点均需正常
kubectl get node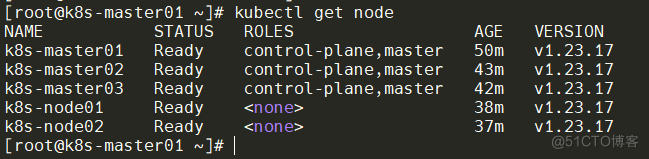
Pod均需正常
kubectl get pod -A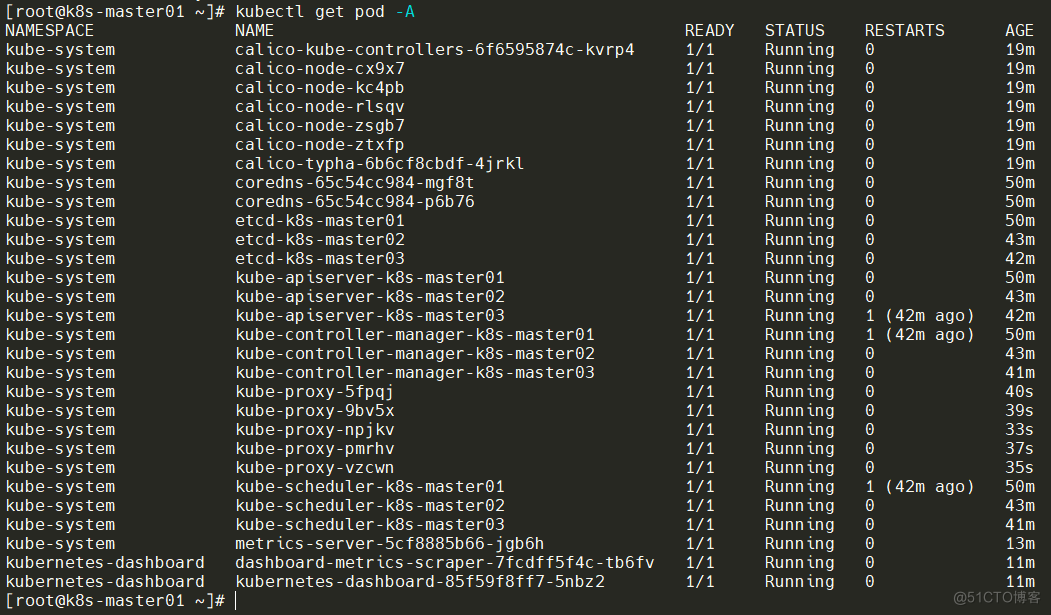
检查集群网段无任何冲突
kubectl get svc
kubectl get pod -A -owide能够正常创建资源
kubectl create deploy cluster-test --image=registry.cn-beijing.aliyuncs.com/dotbalo/debug-tools -- sleep 3600
Pod 必须能够解析 Service(同 namespace 和跨 namespace)
#取上面的NAME进入pod
kubectl exec -it cluster-test-8b47d69f5-dbvvf -- bash
#解析两个域名,能够对应到.1和.10即可
nslookup kubernetes
nslookup kube-dns.kube-system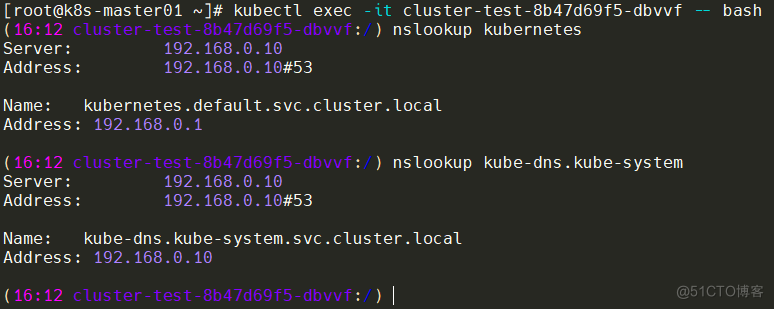
每个节点都必须要能访问 Kubernetes 的 kubernetes svc 443 和 kube-dns 的 service 53
curl https://192.168.0.1:443
curl 192.168.0.10:53每个节点均需出现以下返回信息说明已通
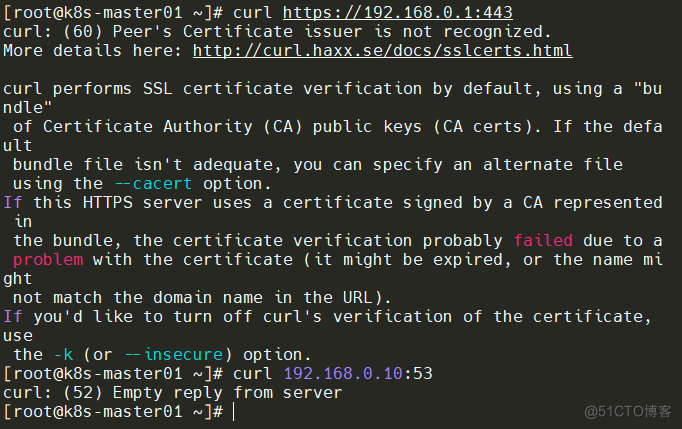
Pod 和 Pod 之间要能够正常通讯(同 namespace 和跨 namespace)
#刚刚创建的一个测试Pod,看看IP也放在哪个节点上
[root@k8s-master01 ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cluster-test-8b47d69f5-dbvvf 1/1 Running 0 6m34s 172.16.58.194 k8s-node02
#找出不在node02上的Pod IP,然后两个Pod之间不在同一机器上进ping
kubectl get pod -n kube-system -owide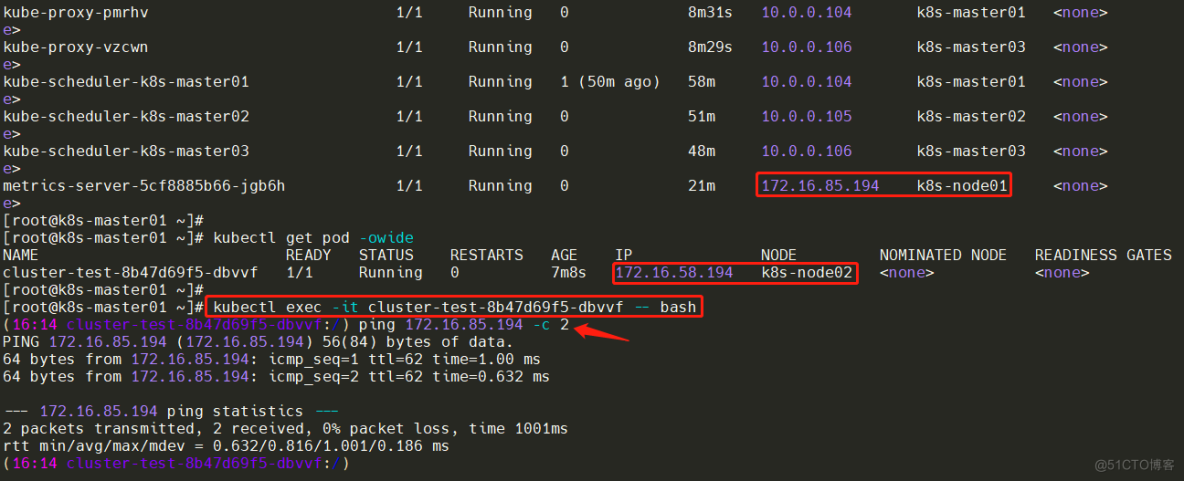
Pod 和 Pod 之间要能够正常通讯(同机器和跨机器)
#找刚从创建的测试Pod IP,全主机进行ping测试,都ping通即可。
[root@k8s-master01 ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cluster-test-8b47d69f5-dbvvf 1/1 Running 0 9m23s 172.16.58.194 k8s-node02 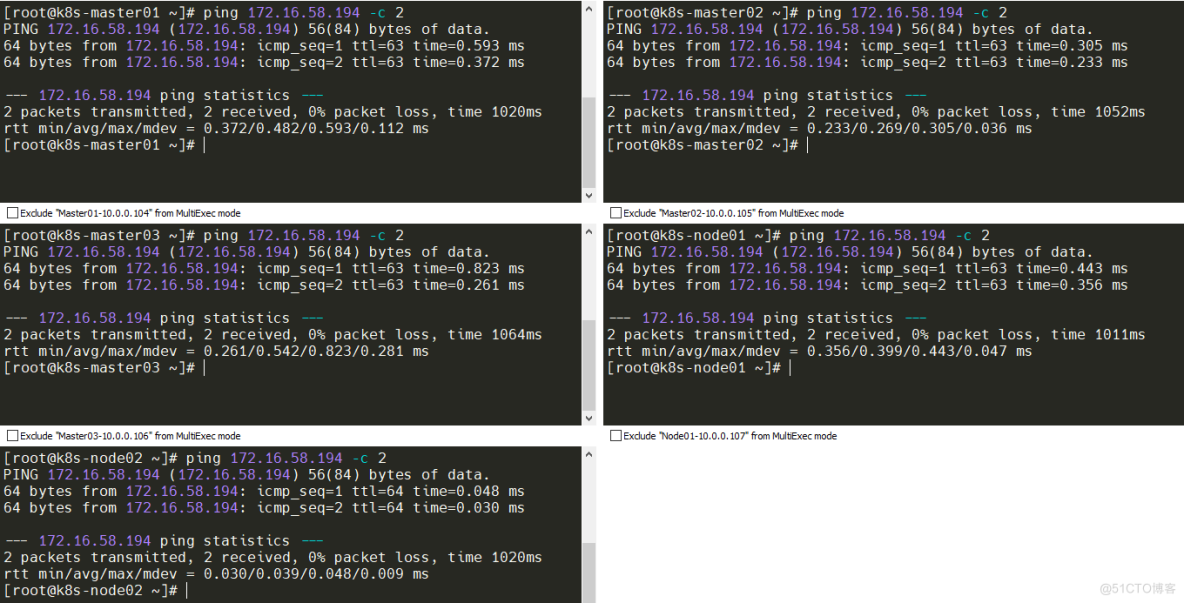
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
