
以kubeadm方式部署的k8s,当出现问题,排查解决的难度会非常大,如果是实验环境,直接进行集群重置即可,如果是生产环境,如果集群已经崩掉了,而且短时间时间内无法定位原因的情况的下,建议先备份好ETCD的数据,然后对生产k8s集群进行重置,以期业务能快速恢复。
1.执行重置
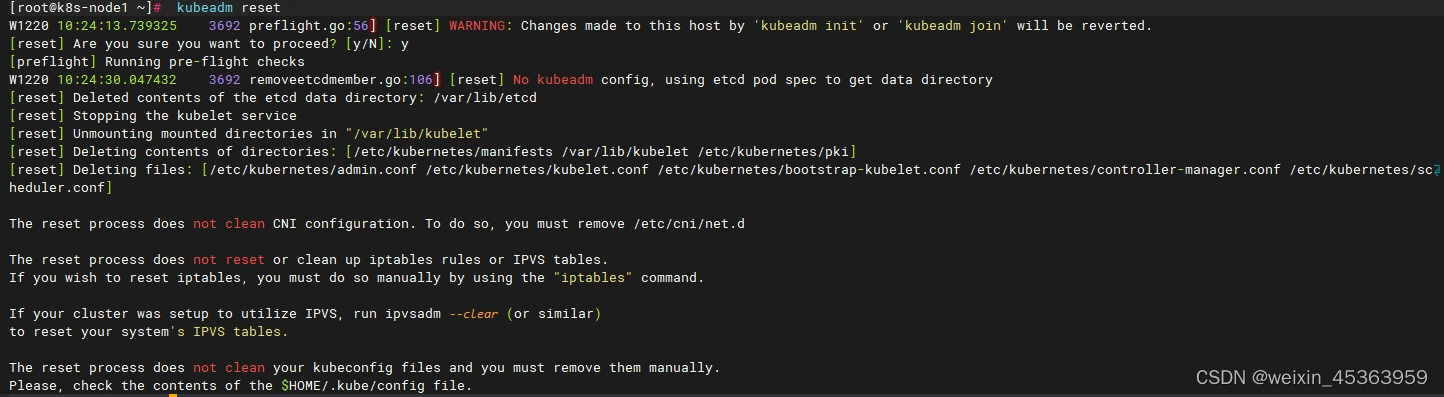
在每台节点机器上执行 kubeadm reset
kubeadm reset
2.删除$HOME/.kube
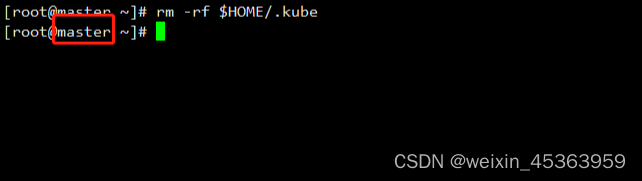
在master节点上执行 rm -rf $HOME/.kube命令
rm -rf $HOME/.kube
3.集群初始化
只需要在master节点上执行即可
kubeadm init --kubernetes-version=1.28.0 --apiserver-advertise-address=192.168.1.200 --pod-network-cidr=10.244.0.0/16 --image-repository registry.aliyuncs.com/google_containers
4.创建必要文件
mkdir -p $HOME/.kube
sudo cp -i /etc服务器托管网/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
5.把Node节点加入集群
kubeadm join 192.168.1.200:6443 --token cexxct.pvvfy19t7w59w85j
--discovery-token-ca-cert-hash服务器托管网 sha256:3013aff45d18317bf5e533c6b727d3cfe2ab3bedf5b14ff668d8d878d45d9f2c
在每台node节点上分别执行,记得把token 和 discovery-token-ca-cert-hash 换成自己的,如果是生产集群,把备份的edct数据拷贝到重置后etcd对应的文件夹中。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
代码: // 第一种搜索顺序 #include using namespace std; con服务器托管网st int N = 20; int n; char g[N][N]; bool col[N], dg[N], udg[N]; void dfs(int…
