
1.概述
最近,在研究LangChain时,发现一些比较有意思的点,今天笔者将给大家分享关于LangChain的一些内容。
2.内容
2.1 什么是LangChain?
LangChain是一项旨在赋能开发人员利用语言模型构建端到端应用程序的强大框架。它的设计理念在于简化和加速利用大型语言模型(LLM)和对话模型构建应用程序的过程。这个框架提供了一套全面的工具、组件和接口,旨在简化基于大型语言模型和对话模型的应用程序开发过程。
LangChain本质上可被视为类似于开源GPT的插件。它不仅提供了丰富的大型语言模型工具,还支持在开源模型的基础上快速增强模型的功能。通过LangChain,开发人员可以更轻松地管理与语言模型的交互,无缝地连接多个组件,并集成额外的资源,如API和数据库等,以加强应用的能力和灵活性。
LangChai服务器托管网n的优势在于为开发人员提供了一个便捷的框架,使其能够更高效地构建应用程序,利用最先进的语言模型和对话系统,同时能够灵活地定制和整合其他必要的资源,为应用程序的开发和部署提供了更大的灵活性和便利性。
2.2 LangChain框架组成?

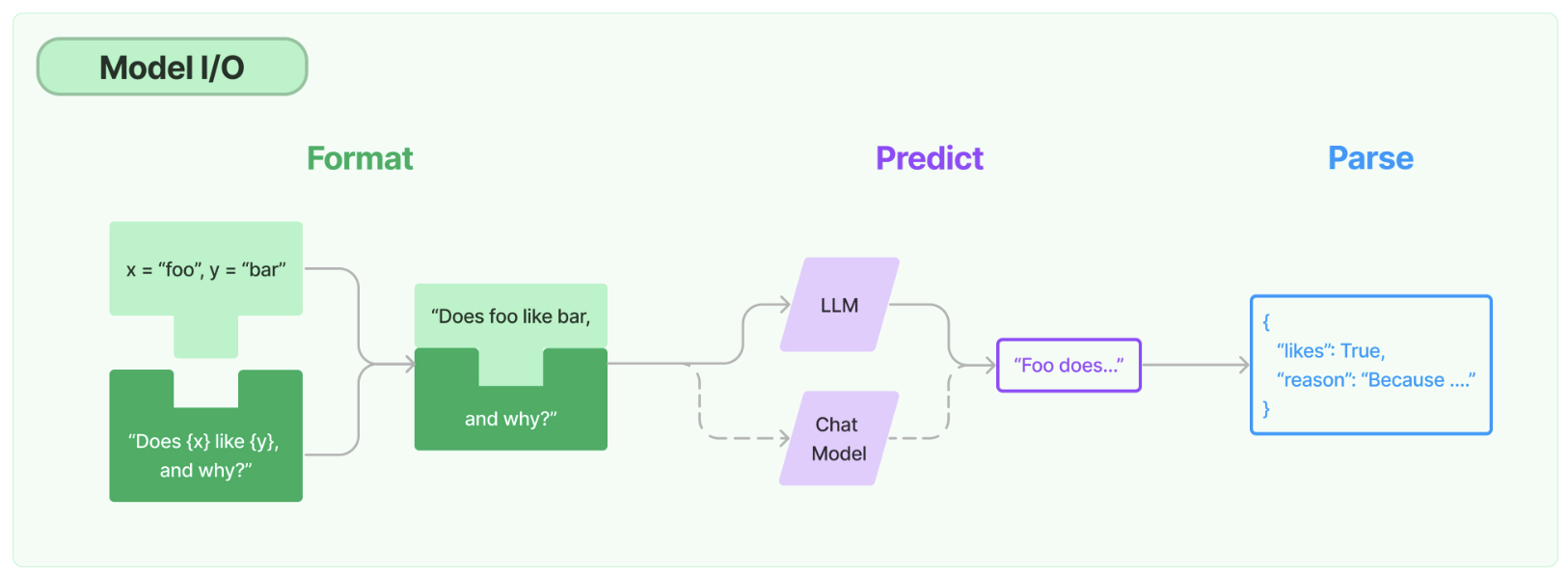
1.Model
任何语言模型应用的核心要素是…… 模型。LangChain为您提供了与任何语言模型进行接口的基本构件。
- 提示:模板化、动态选择和管理模型输入
- 语言模型:通过通用接口调用语言模型
- 输出解析器:从模型输出中提取信息
此外,LangChain还提供了额外的关键功能,如:
- 模型适配器:通过适配器将不同类型的语言模型无缝整合到应用程序中。
- 模型优化器:优化和调整模型以提高性能和效率。
- 自定义组件:允许开发人员根据特定需求创建和整合自定义组件,以扩展和改进模型的功能。
2.Retrieval
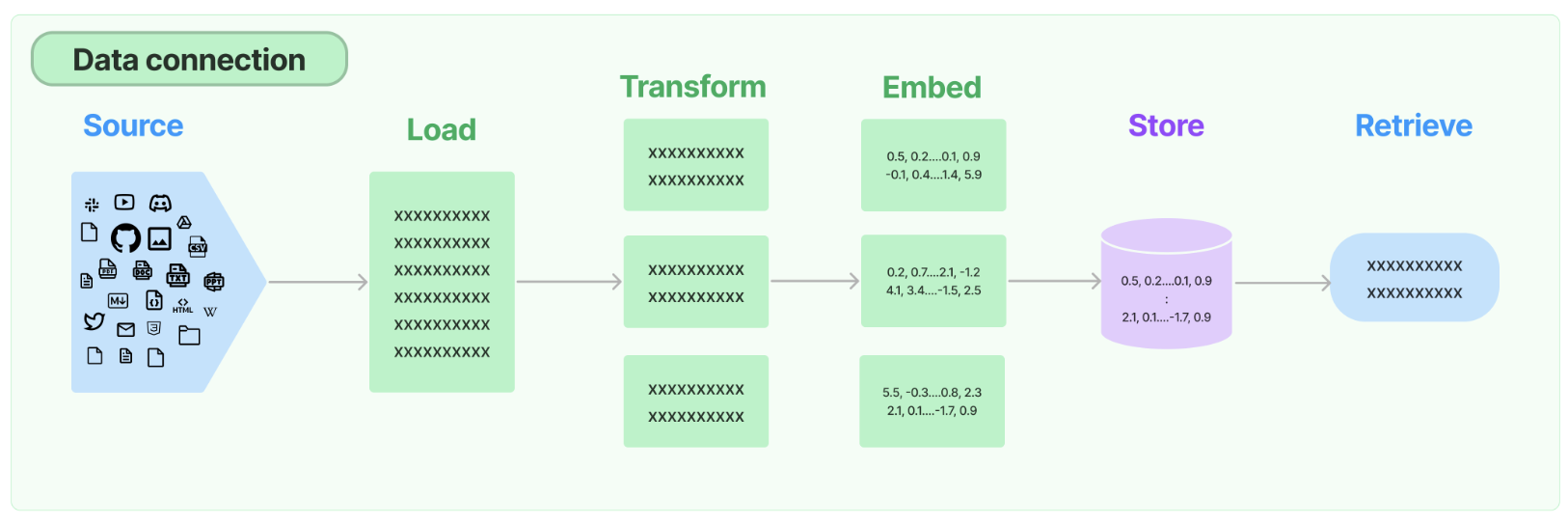
许多大型语言模型(LLM)应用需要用户特定的数据,这些数据并不属于模型的训练集。实现这一点的主要方法是通过检索增强生成(RAG)。在这个过程中,会检索外部数据,然后在生成步骤中传递给LLM。
LangChain为RAG应用提供了从简单到复杂的所有构建模块。文档的此部分涵盖与检索步骤相关的所有内容,例如数据的获取。尽管听起来简单,但实际上可能相当复杂。这包括几个关键模块。
文档加载器
从许多不同来源加载文档。LangChain提供超过100种不同的文档加载器,并与其他主要提供者(如AirByte和Unstructured)进行集成。我们提供与各种位置(私人S3存储桶、公共网站)的各种文档类型(HTML、PDF、代码)的加载集成。
文档转换器
检索的关键部分是仅获取文档的相关部分。这涉及几个转换步骤,以最服务器托管网佳准备文档进行检索。其中一个主要步骤是将大型文档分割(或分块)为较小的块。LangChain提供了几种不同的算法来执行此操作,同时针对特定文档类型(代码、Markdown等)进行了优化逻辑。
文本嵌入模型
检索的另一个关键部分是为文档创建嵌入。嵌入捕获文本的语义含义,使您能够快速高效地查找其他类似的文本。LangChain与超过25种不同的嵌入提供者和方法进行集成,涵盖了从开源到专有API的各种选择,使您可以选择最适合您需求的方式。LangChain提供了标准接口,使您能够轻松切换模型。
向量存储
随着嵌入技术的兴起,出现了对数据库的需求,以支持这些嵌入的有效存储和搜索。LangChain与超过50种不同的向量存储进行集成,涵盖了从开源本地存储到云托管专有存储的各种选择,使您可以选择最适合您需求的方式。LangChain提供标准接口,使您能够轻松切换向量存储。
检索器
一旦数据存储在数据库中,您仍需要检索它。LangChain支持许多不同的检索算法,这是我们增加最多价值的领域之一。我们支持易于入门的基本方法,即简单的语义搜索。然而,我们还在此基础上添加了一系列算法以提高性能。这些包括:
- 父文档检索器:这允许您为每个父文档创建多个嵌入,使您能够查找较小的块,但返回更大的上下文。
- 自查询检索器:用户的问题通常包含对不仅仅是语义的某些逻辑的引用,而是可以最好表示为元数据过滤器的逻辑。自查询允许您从查询中提取出语义部分以及查询中存在的其他元数据过滤器。
- 组合检索器:有时您可能希望从多个不同来源或使用多种不同算法检索文档。组合检索器可以轻松实现此操作。
3.Chains
单独使用LLM适用于简单的应用程序,但更复杂的应用程序需要将LLM链接起来,要么彼此链接,要么与其他组件链接。
LangChain提供了两个高级框架来“链接”组件。传统方法是使用Chain接口。更新的方法是使用LangChain表达语言(LCEL)。在构建新应用程序时,我们建议使用LCEL进行链式组合。但是,我们继续支持许多有用的内置Chain,因此我们在这里对两个框架进行了文档化。正如我们将在下面提到的,Chain本身也可以用于LCEL,因此两者并不是互斥的。
新内容补充:
此外,LangChain还提供了其他关于链式组合的重要内容:
- 模块兼容性:LangChain旨在确保不同模块之间的兼容性,使得可以无缝地将不同类型的LLMs和其他组件相互链接,以构建更加复杂和高效的应用程序。
- 动态调整:框架允许动态调整不同模块和LLMs之间的连接方式,从而使得应用程序的功能和性能得到灵活的调整和优化。
- 可扩展性:LangChain提供了灵活的扩展机制,允许开发人员根据具体需求定制新的链接策略和模块组合,以适应不同场景下的需求。
LCEL最显著的部分是它提供了直观且易读的组合语法。但更重要的是,它还提供了一流的支持。为一个简单且常见的例子,我们可以看到如何将提示(prompt)、模型和输出解析器结合起来:
from langchain.chat_models import ChatAnthropic from langchain.prompts import ChatPromptTemplate from langchain.schema import StrOutputParser model = ChatAnthropic() prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}"), ]) runnable = prompt | model | StrOutputParser()
Chain 是“链式”应用程序的传统接口。我们通常很泛化地定义 Chain 为对组件的一系列调用,其中可能包括其他链。基本接口很简单:
class Chain(BaseModel, ABC): """Base interface that all chains should implement.""" memory: BaseMemory callbacks: Callbacks def __call__( self, inputs: Any, return_only_outputs: bool = False, callbacks: Callbacks = None, ) -> Dict[str, Any]: ...
4.Memory
在与模型交互时,用于存储上下文状态。模型本身不具备上下文记忆,因此在与模型交互时,需要传递聊天内容的上下文。
大多数大型语言模型应用具有会话式界面。对话的一个基本组成部分是能够引用先前在对话中提到的信息。至少,会话系统应能直接访问一定范围内的先前消息。更复杂的系统需要具有一个持续更新的世界模型,使其能够保持关于实体及其关系的信息。
我们称存储关于先前互动的信息的能力为“记忆”。LangChain为向系统添加记忆提供了许多实用工具。这些实用工具可以单独使用,也可以无缝地整合到链中。
一个记忆系统需要支持两种基本操作:读取和写入。要记住,每个链定义了一些核心执行逻辑,期望得到某些输入。其中一些输入直接来自用户,但有些输入可能来自记忆。在给定运行中,一个链将两次与其记忆系统交互。
在接收到初始用户输入之后,但在执行核心逻辑之前,链将从其记忆系统中读取并增补用户输入。
在执行核心逻辑后,但在返回答案之前,链将把当前运行的输入和输出写入记忆,以便在将来的运行中引用。
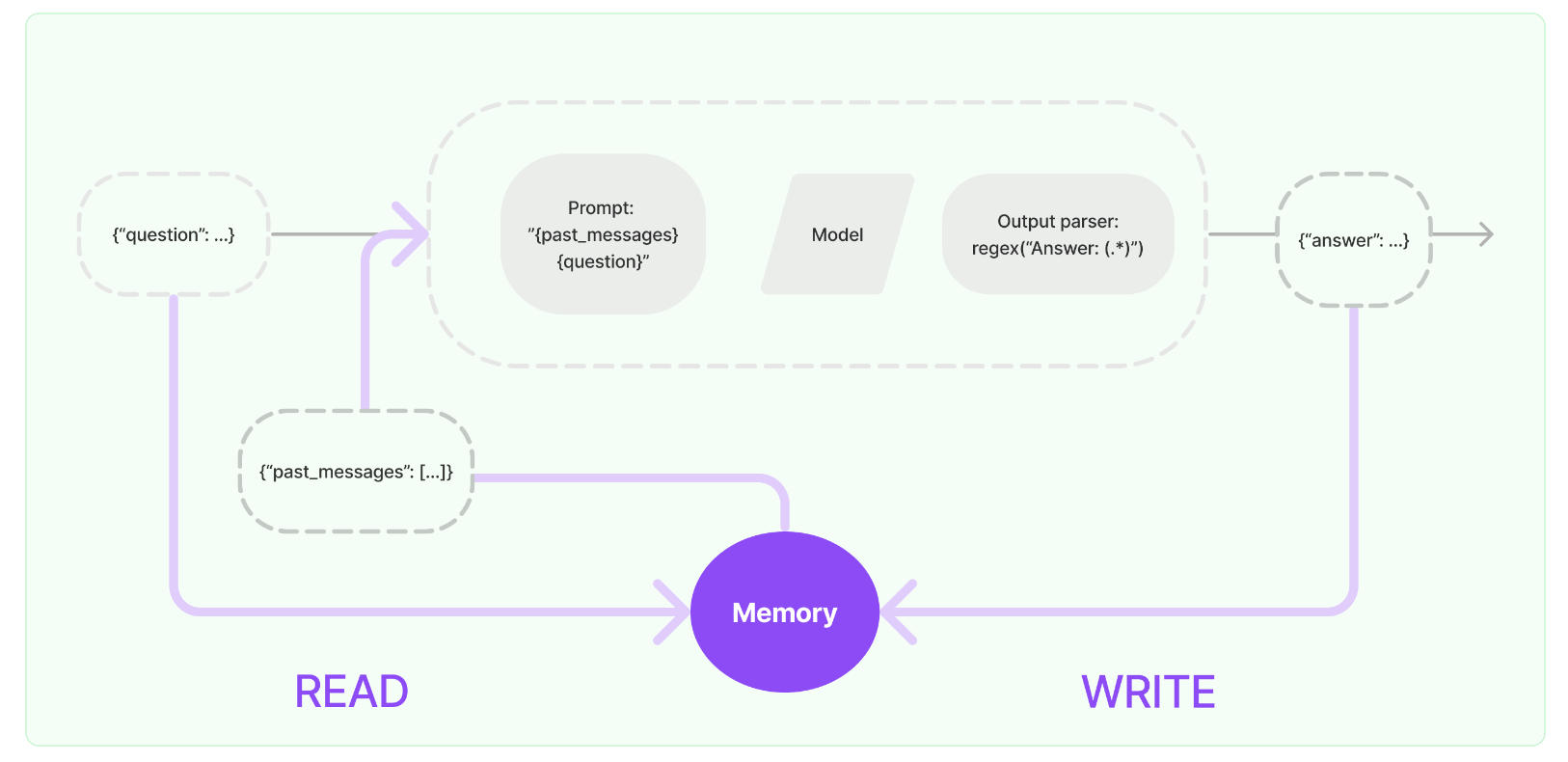
让我们看一看如何在链中使用 ConversationBufferMemory。ConversationBufferMemory 是一种极其简单的内存形式,它只是在缓冲区中保留了一系列聊天消息,并将其传递到提示模板中。
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory() memory.chat_memory.add_user_message("hi!") memory.chat_memory.add_ai_message("what's up?")
在链中使用记忆时,有一些关键概念需要理解。请注意,这里我们介绍了适用于大多数记忆类型的一般概念。每种单独的记忆类型可能都有其自己的参数和概念,需要理解。
通常情况下,链接收或返回多个输入/输出键。在这些情况下,我们如何知道要保存到聊天消息历史记录的键是哪些?这通常可以通过记忆类型的 input_key 和 output_key 参数来控制。这些参数默认为 None – 如果只有一个输入/输出键,那么会自动使用该键。但是,如果有多个输入/输出键,则必须明确指定要使用哪一个的名称。最后,让我们来看看如何在链中使用这个功能。我们将使用一个 LLMChain,并展示如何同时使用 LLM 和 ChatModel。
使用一个LLM:
from langchain.llms import OpenAI from langchain.prompts import PromptTemplate from langchain.chains import LLMChain from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0) # Notice that "chat_history" is present in the prompt template template = """You are a nice chatbot having a conversation with a human. Previous conversation: {chat_history} New human question: {question} Response:""" prompt = PromptTemplate.from_template(template) # Notice that we need to align the `memory_key` memory = ConversationBufferMemory(memory_key="chat_history") conversation = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory )
使用一个ChatModel:
from langchain.chat_models import ChatOpenAI from langchain.prompts import ( ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, HumanMessagePromptTemplate, ) from langchain.chains import LLMChain from langchain.memory import ConversationBufferMemory llm = ChatOpenAI() prompt = ChatPromptTemplate( messages=[ SystemMessagePromptTemplate.from_template( "You are a nice chatbot having a conversation with a human." ), # The `variable_name` here is what must align with memory MessagesPlaceholder(variable_name="chat_history"), HumanMessagePromptTemplate.from_template("{question}") ] ) # Notice that we `return_messages=True` to fit into the MessagesPlaceholder # Notice that `"chat_history"` aligns with the MessagesPlaceholder name. memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) conversation = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory )
5.Agents
Agents的核心理念是利用LLM选择要采取的一系列行动。在链式结构中,行动序列是硬编码的(在代码中)。而在Agents中,语言模型被用作推理引擎,决定要采取哪些行动以及顺序。
一些重要的术语(和模式)需要了解:
- AgentAction:这是一个数据类,代表Agents应该执行的操作。它具有一个tool属性(应该调用的工具的名称)和一个tool_input属性(该工具的输入)。
- AgentFinish:这是一个数据类,表示Agent已经完成并应该返回给用户。它有一个return_values参数,这是要返回的字典。通常它只有一个键 – output – 是一个字符串,因此通常只返回这个键。
- intermediate_steps:这些表示传递的先前Agent操作和对应的输出。这些很重要,以便在将来的迭代中传递,以便Agent知道它已经完成了哪些工作。它的类型被定义为List[Tuple[AgentAction, Any]]。请注意,observation目前以Any类型留下以保持最大的灵活性。在实践中,这通常是一个字符串。
6.Callbacks
LangChain提供了回调系统,允许您连接到LLM应用程序的各个阶段。这对于日志记录、监控、流处理和其他任务非常有用。
您可以通过使用API中始终可用的callbacks参数来订阅这些事件。该参数是处理程序对象的列表,这些处理程序对象应该详细实现下面描述的一个或多个方法。
CallbackHandlers 是实现 CallbackHandler 接口的对象,该接口为可以订阅的每个事件都有一个方法。当事件触发时,CallbackManager 将在每个处理程序上调用适当的方法。
class BaseCallbackHandler: """Base callback handler that can be used to handle callbacks from langchain.""" def on_llm_start( self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any ) -> Any: """Run when LLM starts running.""" def on_chat_model_start( self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any ) -> Any: """Run when Chat Model starts running.""" def on_llm_new_token(self, token: str, **kwargs: Any) -> Any: """Run on new LLM token. Only available when streaming is enabled.""" def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any: """Run when LLM ends running.""" def on_llm_error( self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any ) -> Any: """Run when LLM errors.""" def on_chain_start( self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any ) -> Any: """Run when chain starts running.""" def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> Any: """Run when chain ends running.""" def on_chain_error( self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any ) -> Any: """Run when chain errors.""" def on_tool_start( self, serialized: Dict[str, Any], input_str: str, **kwargs: Any ) -> Any: """Run when tool starts running.""" def on_tool_end(self, output: str, **kwargs: Any) -> Any: """Run when tool ends running.""" def on_tool_error( self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any ) -> Any: """Run when tool errors.""" def on_text(self, text: str, **kwargs: Any) -> Any: """Run on arbitrary text.""" def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any: """Run on agent action.""" def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> Any: """Run on agent end."""
LangChain提供了一些内置处理程序,供开发者快速开始使用。这些处理程序位于 langchain/callbacks 模块中。最基本的处理程序是 StdOutCallbackHandler,它简单地将所有事件记录到标准输出(stdout)。
注意:当对象的 verbose 标志设置为 true 时,即使未显式传入,StdOutCallbackHandler 也会被调用。
from langchain.callbacks import StdOutCallbackHandler from langchain.chains import LLMChain from langchain.llms import OpenAI from langchain.prompts import PromptTemplate handler = StdOutCallbackHandler() llm = OpenAI() prompt = PromptTemplate.from_template("1 + {number} = ") # Constructor callback: First, let's explicitly set the StdOutCallbackHandler when initializing our chain chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler]) chain.run(number=2) # Use verbose flag: Then, let's use the `verbose` flag to achieve the same result chain = LLMChain(llm=llm, prompt=prompt, verbose=True) chain.run(number=2) # Request callbacks: Finally, let's use the request `callbacks` to achieve the same result chain = LLMChain(llm=llm, prompt=prompt) chain.run(number=2, callbacks=[handler])
结果如下:
> Entering new LLMChain chain... Prompt after formatting: 1 + 2 = > Finished chain. > Entering new LLMChain chain... Prompt after formatting: 1 + 2 = > Finished chain. > Entering new LLMChain chain... Prompt after formatting: 1 + 2 = > Finished chain. 'nn3'
3.快速使用
3.1 环境设置
使用LangChain通常需要与一个或多个模型提供商、数据存储、API等进行集成。在本示例中,我们将使用OpenAI的模型API。
首先,我们需要安装他们的Python包:
pip install langchain pip install openai
在初始化OpenAI LLM类时直接通过名为 openai_api_key 的参数传递密钥:
from langchain.llms import OpenAI llm = OpenAI(openai_api_key="...")
3.2 LLM
在LangChain中有两种类型的语言模型,分别被称为:
- LLMs:这是一个以字符串作为输入并返回字符串的语言模型。
- ChatModels:这是一个以消息列表作为输入并返回消息的语言模型。
LLMs的输入/输出简单易懂 – 字符串。但ChatModels呢?那里的输入是一个ChatMessages列表,输出是一个单独的ChatMessage。ChatMessage有两个必需的组成部分:
- content:这是消息的内容。
- role:这是产生ChatMessage的实体的角色。
LangChain提供了几个对象来轻松区分不同的角色:
- HumanMessage:来自人类/用户的ChatMessage。
- AIMessage:来自AI/助手的ChatMessage。
- SystemMessage:来自系统的ChatMessage。
- FunctionMessage:来自函数调用的ChatMessage。
如果这些角色都不合适,还有一个ChatMessage类,可以手动指定角色。
LangChain提供了标准接口,但了解这种差异有助于构建特定语言模型的提示。LangChain提供的标准接口有两种方法:
- predict:接受一个字符串,返回一个字符串。
- predict_messages:接受一个消息列表,返回一个消息。
from langchain.llms import OpenAI from langchain.chat_models import ChatOpenAI llm = OpenAI() chat_model = ChatOpenAI() llm.predict("hi!") >>> "Hi" chat_model.predict("hi!") >>> "Hi"
OpenAI 和 ChatOpenAI 对象基本上只是配置对象。开发者可以使用诸如 temperature 等参数来初始化它们,并在各处传递它们。
接下来,让我们使用 predict 方法来处理一个字符串输入。
text = "What would be a good company name for a company that makes colorful socks?" llm.predict(text) # >> Feetful of Fun chat_model.predict(text) # >> Socks O'Color
最后,让我们使用 predict_messages 方法来处理一个消息列表。
from langchain.schema import HumanMessage text = "What would be a good company name for a company that makes colorful socks?" messages = [HumanMessage(content=text)] llm.predict_messages(messages) # >> Feetful of Fun chat_model.predict_messages(messages) # >> Socks O'Color
3.3Prompt 模版
PromptTemplates也可以用于生成消息列表。在这种情况下,提示不仅包含有关内容的信息,还包含每条消息的信息(其角色、在列表中的位置等)。在这里,最常见的情况是ChatPromptTemplate是ChatMessageTemplate列表。每个ChatMessageTemplate包含了如何格式化ChatMessage的指令 – 其角色以及内容。
from langchain.prompts.chat import ChatPromptTemplate template = "You are a helpful assistant that translates {input_language} to {output_language}." human_template = "{text}" chat_prompt = ChatPromptTemplate.from_messages([ ("system", template), ("human", human_template), ]) chat_prompt.format_messages(input_language="English", output_language="French", text="I love programming.")
3.3Output parsers
OutputParsers 将LLM的原始输出转换为可在下游使用的格式。其中主要的OutputParsers类型包括:
- 将LLM的文本转换为结构化信息(例如 JSON)
- 将 ChatMessage 转换为纯字符串
- 将调用返回的除消息外的额外信息(例如 OpenAI 函数调用)转换为字符串。
from langchain.schema import BaseOutputParser class CommaSeparatedListOutputParser(BaseOutputParser): """Parse the output of an LLM call to a comma-separated list.""" def parse(self, text: str): """Parse the output of an LLM call.""" return text.strip().split(", ") CommaSeparatedListOutputParser().parse("hi, bye") # >> ['hi', 'bye']
3.4PromptTemplate + LLM + OutputParser
我们现在可以将所有这些组合成一个链条。该链条将接收输入变量,将其传递到提示模板以创建提示,将提示传递给语言模型,然后通过(可选的)输出解析器传递输出。这是打包模块化逻辑的便捷方式。
from langchain.chat_models import ChatOpenAI from langchain.prompts.chat import ChatPromptTemplate from langchain.schema import BaseOutputParser class CommaSeparatedListOutputParser(BaseOutputParser): """Parse the output of an LLM call to a comma-separated list.""" def parse(self, text: str): """Parse the output of an LLM call.""" return text.strip().split(", ") template = """You are a helpful assistant who generates comma separated lists. A user will pass in a category, and you should generate 5 objects in that category in a comma separated list. ONLY return a comma separated list, and nothing more.""" human_template = "{text}" chat_prompt = ChatPromptTemplate.from_messages([ ("system", template), ("human", human_template), ]) chain = chat_prompt | ChatOpenAI() | CommaSeparatedListOutputParser() chain.invoke({"text": "colors"}) # >> ['red', 'blue', 'green', 'yellow', 'orange']
请注意,我们使用 | 符号将这些组件连接在一起。这种 | 符号称为 LangChain 表达语言。
4.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
博客地址:https://www.cnblogs.com/zylyehuo/ 基于[移动机器人运动规划及运动仿真],详见之前的博客 移动机器人运动规划及运动仿真 – zylyehuo – 博客园 参考链接 Autolabor-ROS机器人入门课程《ROS理论与…
