

本文以构建AIGC落地应用ChatBot和构建AI Agent为例,从代码级别详细分享AI框架LangChain、阿里云通义大模型和AnalyticDB提供引擎的开发经验和最佳实践,给大家快速搭建AIGC应用提供参考。
前言
9月13日,通义千问大模型已通过录制方式招募,并正式向公众开放。通义模型具备的能力包括:1.创作文字,如写故事、写公文、写邮件、写剧本、写诗歌等;2.编写代码;3.提供各类语言的翻译服务,如英语、日语、法语、西班牙语等;4.进行文本润色和文本摘要等工作;5.扮演角色进行对话;6.制作我们在可以登录通义千问官网体验的同时,也可以充分发挥想象力,通过调用通义千问API的方式来构建属于自己的AI应用了。
如果直接使用通义千问API从0到1来构建应用,技术成本还是相对比较高的。幸运的是,目前已经有非常优秀的框架LangChain来串联AIGC相关的各类组件,让我们轻松构建自己由于业务上对客户支持的需要,我在几个月前就已经在LangChain模块中添加了调用通义千问API的模块代码。在这个时间点,恰好可以直接拿来使用。
在过去的一段时间里,已经有很多同学分享了LangChain的框架和原理,本文则从实际开发角度出发,以构建应用流程中遇到的问题,以及我们实际遇到的客户案例出发,来详细讲解LangChain的代码,希望能给大家在基于通义API构建应用入门时提供一些启示和思路。本文主要包括几个部分:
1)LangChain的简单介绍。
2)LangChain的源码解读,以通义千问API调用为例。
3.)学习和构建一些基于不同链的小应用演示,比如基于通义和提供数据库的ChatBot;构建每日金融资讯收集和分析的AI代理。
4)如何提高大模型的问答准确率,比如如何更好地处理现有数据,如何利用思维链能力提升Agent的实际思考能力等。
浪链是什么
LangChain是一个基于语言模型开发应用程序的框架。其通过中央开发应用程序所需的各个模块和组件,简化和加速了程序的构建和开发。
LangChain模块
LLM模块提供统一的大语言模型调用接口,增强各种大语言模型调用方式和实现细节的不同带来的开发复杂度。比如OpenAI和统一模块。实现一个LLM模块需要实现LLM基类的调用和生成接口。
class LLM(BaseLLM):
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
"""Run the LLM on the given prompt and input."""
def _generate(
self,
prompts: List[str],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> LLMResult:
"""Run the LLM on the given prompt and input."""
Embedding模块提供统一的嵌入能力接口,与LLM一样,也提供不同的厂商实现,比如OpenAIEmbeddings,DashScopeEmbeddings。同样需要集成和实现Embeddings基类的两个方法embed_documents和embed_query。
class Embeddings(ABC):
"""Interface for embedding models."""
@abstractmethod
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Embed search docs."""
@abstractmethod
def embed_query(self, text: str) -> List[float]:
VectorStore模块支持存储模块,用于存储由Embedding模块生成的数据支持和生产支持,主要作为记忆和检索模块向LLM提供服务。比如AnalytiDB VectorStore模块。实现VectorStore模块主要需要实现几个读取和查询接口。
class VectorStore(ABC):
"""Interface for vector store."""
@abstractmethod
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
def search(self, query: str, search_type: str, **kwargs: Any) -> List[Document]:
链模块用于架构上面的这些模块,使得调用更加简单,让用户不需要关心繁琐的调用仓库,在LangChain中已经集成了很多链,对接的就是LLMChain,在其内部根据不同的场景定义和使用不同的PromptTemplate来达到目标。
代理模块和链类似,提供了丰富的代理模块版本,对于实现不同的代理,后面会详细介绍。
还有模块比如索引,检索器等都是上面这些模块的变种,以及提供一些可调用的工具类,比如工具等。这里就不再详细展开。我们会在后面的案例中讲解如何使用这些模块来构建自己的应用程序。
应用案例
构建聊天机器人
ChatBot是LLM应用的一个比较典型的场景,这个场景又可以解读为问答助手(知识库),智能客服,副驾驶等。比较典型的案例是LangChain-chatchat。构建ChatBot主要需要以下模块:
TextSplitter一篇文档的内容往往长达几十篇幅,由于LLM和Embedding token的限制,无法将其全部传给LLM,因此需要存储的文档按照一定的规则切分内聚的小块进行存储。
LLM模块用于总结问题和回答问题。
嵌入模块用于生产知识和问题的表示。
VectorStore模块用于存储和搜索匹配本地知识内容。
比较语音的调用流程图如下(比较经典语音,老图借用):
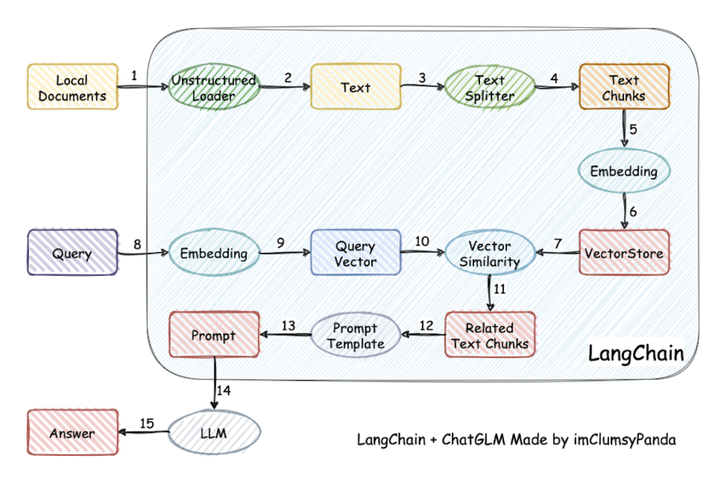
例子
基于通义API和ADB-PG提供数据库的ChatBot
首先我们从Google拉取一些问答数据,然后调用Dashscope上的Embedding模型进行支撑化,并写入AnalyticDB PostgreSQL。
import os
import json
import wget
from langchain.vectorstores.analyticdb import AnalyticDB
CONNECTION_STRING = AnalyticDB.connection_string_from_db_params(
driver=os.environ.get("PG_DRIVER", "psyco服务器托管网pg2cffi"),
host=os.environ.get("PG_HOST", "localhost"),
port=int(os.environ.get("PG_PORT", "5432")),
database=os.environ.get("PG_DATABASE", "postgres"),
user=os.environ.get("PG_USER", "postgres"),
password=os.environ.get("PG_PASSWORD", "postgres"),
)
# All the examples come from https://ai.google.com/research/NaturalQuestions
# This is a sample of the training set that we download and extract for some
# further processing.
wget.download("https://storage.googleapis.com/dataset-natural-questions/questions.json")
wget.download("https://storage.googleapis.com/dataset-natural-questions/answers.json")
# 导入数据
with open("questions.json", "r") as fp:
questions = json.load(fp)
with open("answers.json", "r") as fp:
answers = json.load(fp)
from langchain.vectorstores import AnalyticDB
from langchain.embeddings import DashScopeEmbeddings
from langchain import VectorDBQA, OpenAI
embeddings = DashScopeEmbeddings(
model="text-embedding-v1", dashscope_api_key="your-dashscope-api-key"
)
doc_store = AnalyticDB.from_texts(
texts=answers, embedding=embeddings, connection_string=CONNECTION_STRING,
pre_delete_collection=True,
)
然后创建LangChain内集成的tongyi模块。
from langchain.chains import RetrievalQA
from langchain.llms import Tongyi
os.environ["DASHSCOPE_API_KEY"] = "your-dashscope-api-key"
llm = Tongyi()
查询和搜索数据,然后回答问题。
from langchain.prompts import PromptTemplate
custom_prompt = """
Use the following pieces of context to answer the question at the end. Please provide
a short single-sentence summary answer only. If you don't know the answer or if it's
not present in given context, don't try to make up an answer, but suggest me a random
unrelated song title I could listen to.
Context: {context}
Question: {question}
Helpful Answer:
"""
custom_prompt_template = PromptTemplate(
template=custom_prompt, input_variables=["context", "question"]
custom_qa = VectorDBQA.from_chain_type(
llm=llm,
chain_type="stuff",
vectorstore=doc_store,
return_source_documents=False,
chain_type_kwargs={"prompt": custom_prompt_template},
)
random.seed(41)
for question in random.choices(questions, k服务器托管网=5):
print(">", question)
print(custom_qa.run(question), end="nn")
> what was uncle jesse's original last name on full house
Uncle Jesse's original last name on Full House was Cochran.
> when did the volcano erupt in indonesia 2018
No information about a volcano erupting in Indonesia in 2018 is present in the given context. Suggested song title: "Volcano" by U2.
> what does a dualist way of thinking mean
A dualist way of thinking means believing that humans possess a non-physical mind or soul which is distinct from their physical body.
> the first civil service commission in india was set up on the basis of recommendation of
The first Civil Service Commission in India was not set up on the basis of a recommendation.
> how old do you have to be to get a tattoo in utah
In Utah, you must be at least 18 years old to get a tattoo.
问题和挑战
在我们实际为用户提供构建ChatBot的过程中,我们仍然遇到了很多问题,比如文本切分过碎,导致语义丢失,文本包含图表,切分后导致段落无法被理解等。
- 文本切分器支持的匹配度直接影响识别率,而支持的识别率又和内容本身以及问题紧密联系在一起,存在一个很强大的嵌入模型,如果文本切分本身做的不好,也无法达到用户的预期效果。比如LangChain本身提供的CharacterTextSplitter,其会根据标点符号和换行符等来切分段落,在一些多级标题的场景下,小标题会被切分成单独的块,与正文分割开,导致被切分的标题和正文都无法很内聚地表达需要表达的内容。
- 优化切分长度,过长的chunk会导致在召回后达到token限制,过小的chunk又可能丢失想要的关键信息。我们尝试过很多切分策略,发现如果不做深度的优化,将文本直接按照200-500个token长度来切分反而效果比较好。
- 认知优化1.回溯上面,在某些场景中,我们能够准确地识别内容,但是这部分内容并不完整,因此我们可以在读取时为块按照文章级别构建id,在捕获时额外识别最相关块的相邻块,裁切。
- 认知优化2.构建标题树,在丰富的文本场景中,用户非常喜欢使用多级标题,有些文本内容在去掉标题之后就无法理解其到底在说什么,接下来我们可以通过构建内容标题树的方式来优化块。 chunk 按照下面的方式构建。
#大标题1-中标题1-小标题1#:内容1
#大标题1-中标题1-小标题1#:内容2
#大标题1-中标题1-小标题2#:内容1
#大标题2-中标题1-小标题1#:内容1
- 双路召回,纯醒醒有时会针对母语的不理解导致无法召回相关内容,接下来可以考虑使用醒醒和全文搜索进行双路醒醒,在醒后因为随后做精去重。搜索时,我们可以通过额外增加自定义词汇和虚词增强的方式来进一步优化召回效果。
- 问题优化,有时候用户的问题本身并不适合做护理匹配,接下来我们可以根据聊天历史做模型来总结独立问题,来提升反馈率,提高回答准确度。
虽然我们做了很多优化,但是由于用户的文档本身五花八门,现在依然无法找到一个完全通用的方案来应对所有的数据源。比如某样东西分器在markdown场景表现很好,但是对于pdf就效果回落得厉害。比如有的用户还要求能够在识别文本的同时识别图片、视频甚至ppt的切片。目前我们也只是通过元数据链接的方式识别相关内容,而不是把相关内容直接做处理。如果有同学有很好的方法,欢迎评论区交流。
构建AI代理
以LLM构建AI Agent是大语言模型的另一个典型的应用场景。一些开源的非常火热的项目,如AutoGPT、BabyAGI都是非常典型的例子。让我们明白LLM的潜力不仅仅局限于生成书写精彩的文本、故事、文章等;它可以被视为一个强大的自我决策的系统。用AI做决策存在一定的风险,但在一些简单的,只是处理繁琐工作的场景,让AI代替人工决策是可以取的。
Agent系统组成
在以LLM为核心的自主代理系统中,LLM是Agent的大脑,我们还需要一些其他的组件来补全它的四肢。AI Agent主要借助思维链和思维树的思想,提高Agent的思考和决策能力。
规划
规划的作用有两个:
- 进行子任务的设定和分解:实际生活中的任务往往很复杂,需要将大任务分层为更小、可管理的子目标,从而能够有效处理复杂任务。
- 进行自我反思和迭代:通过对过去的自我行为进行批评和反思,从错误中学习并为今后的步骤进行完善,从而提高最终结果的质量。
记忆
短期记忆:将所有上下文学习(参见提示工程)视为利用模型的短期记忆来学习。
长期记忆:这为代理提供了长时间内保留和检索(无限)信息的能力,通常通过利用外部存储和检索来快速实现。
工具
工具模块可以让Agent调用外部API以获取模型权限重中恢复的额外信息(通常在预训练后难以更改),包括实时信息、代码执行能力、访问逻辑信息源等。通常是通过设计API的让方式LLM调用执行。
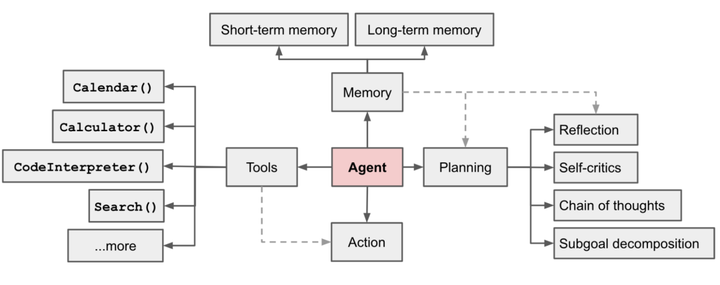
规划模块
一个复杂的任务通常包括许多步骤。代理需要知道这些步骤并提前规划。
任务拆解
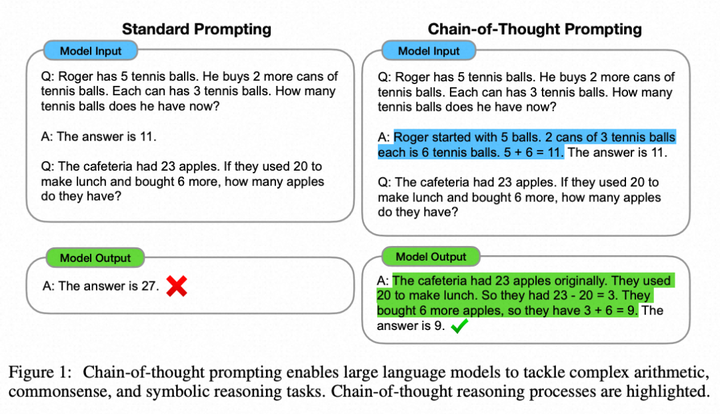
思维链(Chain of Thought)(CoT; Wei et al. 2022 )已经成为提高模型在复杂任务上性能的标准提示技术。模型被指示“阶段性思考”,以利用更多的测试时间计算来将困难任务分解成更小更简单的步骤。CoT将大任务转化为多个可管理的任务,并揭示了模型思考过程的解释。
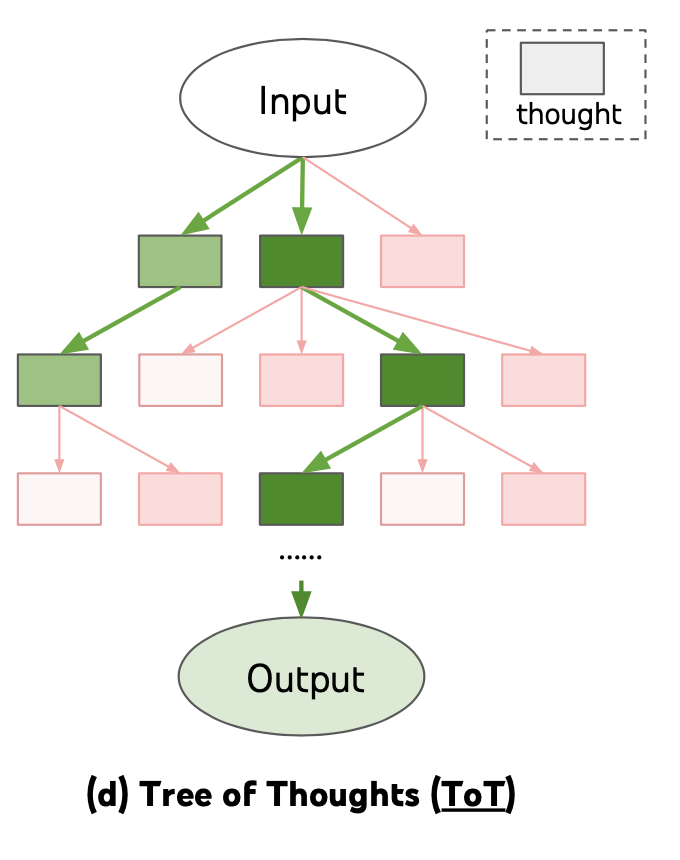
树(Tree of Thoughts)(Yao et al. 2023 )通过在每一步探索多种推理可能性来扩展了CoT。它首先将问题分解为多个思维步骤,并在每一步生成多种思考,创建一个树状结构。搜索过程可以是广度优先搜索(BFS)或深度优先搜索(DFS),每个状态都由分类器(通过提示)或大多数投票进行评估。
完成任务拆解可以通过以下方式:(1)LLM使用简单的提示,如完成“任务X需要a、b、c的步骤。n1。”,“实现任务X的子目标是什么?”,( 2)使用任务特定的指令;例如,“编写文案大纲。”,或者(3)通过交互式输入指定需要操作的步骤。
反思自我(Self-Reflection)是一个非常重要的思想,它允许Agent通过改进过去的行动决策和修正提高以前错误的方式来不断。在可以允许犯错和试错的现实任务中,它发挥着关键作用。比如写一段某些用途的脚本代码。
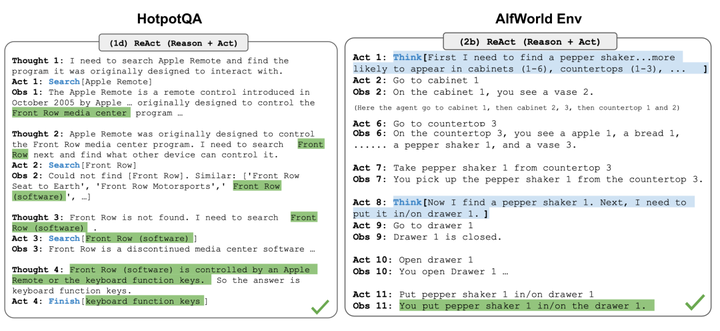
ReAct( Yao et al. 2023 )通过将行动空间扩展为任务特定的离散行动和语言空间的组合,将推理和行动整合到LLM中。上面使LLM能够与环境交互(例如使用搜索引擎API),而后者促使LLM生成自然语言中的推理趋势。
ReAct的提示模板包含明确的大致步骤,提供LLM思考,格式如下:
Thought: ...
Action: ...
Observation: ...
... (Repeated many times)
在对知识密集型任务和决策任务的两个实验中,ReAct都表现比仅仅包含行动(省略了“思考:…”步骤)更好的回答效果。
内存模块
记忆可以定义用于获取、存储、保留和以后检索信息的过程。对于人类大脑来说,有几种类型的记忆。
感觉记忆:这是记忆的初始阶段,它使我们能够在原始刺激结束后保留感觉信息(视觉、听觉等)的能力。感觉记忆通常只持续短暂的休息。子类别包括图像记忆(视觉记忆)、声音记忆记忆(听觉)和认知记忆(认知)。
短期记忆(Short-Term Memory):它存储我们当前认知的信息,需要执行复杂的认知任务,例如学习和推理。短期记忆的容量被认为大约有7个项目(Miller 1956),持续时间为20-30秒。
长期记忆(Long-Term Memory):长期记忆可以存储信息很长时间,范围从几天到目前的存储容量,本质上具有无限的存储容量。长期记忆有两种子类型:
显式/陈述性记忆:这是关于事实和事件的记忆,指的是那些有意识地回忆起来的记忆,包括情节记忆(事件和经历)和语义记忆(事实概念)。
隐式/程序性记忆:这种记忆是无意识的,涉及自动执行的技能和例行程序,如骑自行车、在键盘上打字等。

我们可以粗略地考虑以下映射关系:
记忆感觉为原始输入内容(包括文本、图像或其他模式),其可以在嵌入之后作为输入。
短期记忆就像上下文内容一样,因为聊天历史,它是短暂而有限的,因为受到Token长度的限制。
长期记忆就像Agent可以在查询时参考的外部支持存储,可以通过快速检索访问。
外部存储可以缓解有限的注意力跨度的限制。一个标准的做法是将信息的嵌入表示保存到一个支持存储数据库中,该数据库可以支持快速的最大内积搜索(Maximum Inner Product Search)。为了优化搜索速度,常见的选择是使用近似最近邻(ANN)算法,以返回近似的前k个最近邻,可以在轻微损失一些精度的情况下获得巨大的速度提升。对于类似性算法有兴趣的同学可以阅读这篇文章《ChatGPT都推荐的支持数据库,不仅仅是支持索引》。
工具模块
使用工具可以使LLM完成一些其本身无法直接完成的事情。
Modular Reasoning, Knowledge and Language( Karpas et al. 2022 )提出了一个MRKL系统,包含一组专家模块,通用的LLM作为路由器,将查询路由到最合适的专家模块。这些模块是其他模型(文生可以图) ,领域天气模型等)或功能模块(例如数学转换器、货币转换器、API)。现在最典型的方式就是使用ChatGPT的函数调用功能。通过对C hatGP T注册和描述接口的意义,就可以让ChatGP T帮助我们调用对应的接口,返回正确的答案。
典型案例-AUTOGPT
autogpt通过类似下面的提示可以成功完成一些复杂的任务,比如回顾开源项目的代码,给开源项目代码写注释。最近看到了Aone Copilot,其主要焦点在代码补全和代码问答两个场景。那么如果我们可以调用Aone Copilot的API,是否也可以在我们主动mr之后,让agent帮我们完成一些代码风格、语法校验的代码审查工作,和单元测试用例编写的工作。
You are {
{ai-name}}, {
{user-provided AI bot description}}.
Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.
GOALS:
1. {
{user-provided goal 1}}
2. {
{user-provided goal 2}}
3. ...
4. ...
5. ...
Constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed in double quotes e.g. "command name"
5. Use subprocesses for commands that will not terminate within a few minutes
Commands:
1. Google Search: "google", args: "input": ""
2. Browse Website: "browse_website", args: "url": "", "question": ""
3. Start GPT Agent: "start_agent", args: "name": "", "task": "", "prompt": ""
4. Message GPT Agent: "message_agent", args: "key": "", "message": ""
5. List GPT Agents: "list_agents", args:
6. Delete GPT Agent: "delete_agent", args: "key": ""
7. Clone Repository: "clone_repository", args: "repository_url": "", "clone_path": ""
8. Write to file: "write_to_file", args: "file": "", "text": ""
9. Read file: "read_file", args: "file": ""
10. Append to file: "append_to_file", args: "file": "", "text": ""
11. Delete file: "delete_file", args: "file": ""
12. Search Files: "search_files", args: "directory": ""
13. Analyze Code: "analyze_code", args: "code": ""
14. Get Improved Code: "improve_code", args: "suggestions": "", "code": ""
15. Write Tests: "write_tests", args: "code": "", "focus": ""
16. Execute Python File: "execute_python_file", args: "file": ""
17. Generate Image: "generate_image", args: "prompt": ""
18. Send Tweet: "send_tweet", args: "text": ""
19. Do Nothing: "do_nothing", args:
20. Task Complete (Shutdown): "task_complete", args: "reason": ""
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
You should only respond in JSON format as described below
Response Format:
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulletedn- list that conveysn- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
Ensure the response can be parsed by Python json.loads
LangChain Agent模块
LangChain已经内置了很多agent实现的框架模块,主要包含:
代理工具包
该模块目前是实验性的,其目的是为了模拟代替甚至超越C hatGP T插件的能力,通过提供一系列的工具集提供链式调用,来让用户完成自己的工作流程。比较典型的包括发送邮件功能,执行python代码,执行用户提供的sql,调用zapier api等。
toolkits主要通过注册机制向agent返回一系列可以调用的工具。其基类代码为BaseToolkit。
class BaseToolkit(BaseModel, ABC):
"""Base Toolkit representing a collection of related tools."""
@abstractmethod
def get_tools(self) -> List[BaseTool]:
"""Get the tools in the toolkit."""
我们可以通过继承BaseToolkit的方式来实现不同的工具包,每个工具包都会实现一系列的工具,一个工具则包含几个部分,必须包含的内容有name,description。通过这几个字段来告知LLM这个工具的作用和调用方法,这里就要求注册的工具最好能够通过名称明确表达其用途,同时也可以在描述中增加few-shot单独调用示例,使得LLM能够更好地理解工具。同时在LangChain内部已经集成了很多工具,我们可以直接调用这些工具来组成工具。
class BaseTool(BaseModel, Runnable[Union[str, Dict], Any]):
name: str
"""The unique name of the tool that clearly communicates its purpose."""
description: str
"""Used to tell the model how/when/why to use the tool.
You can provide few-shot examples as a part of the description.
"""
...
class Tool(BaseTool):
"""Tool that takes in function or coroutine directly."""
description: str = ""
func: Optional[Callable[..., str]]
"""The function to run when the tool is called."""
示例1 计算代理
接下来我们做一个简单的代理演示,这个代理主要做两件事情。 1.从网上检索收集问题的数据 2.利用收集到的需要的数据进行科学计算,回答用户的问题。在这个流程中,我们主要用到搜索和计算器两个工具。
from langchain.agents import initialize_agent, AgentType, Tool
from langchain.chains import LLMMathChain
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
from langchain.utilities import SerpAPIWrapper
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
search = SerpAPIWrapper()
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events. You should ask targeted questions"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
)
]
agent = initialize_agent(tools, llm, agent=AgentType.OPENAI_FUNCTIONS, verbose=True)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
> Entering new chain...
Invoking: `Search` with `{'query': 'Leo DiCaprio girlfriend'}`
Amidst his casual romance with Gigi, Leo allegedly entered a relationship with 19-year old model, Eden Polani, in February 2023.
Invoking: `Calculator` with `{'expression': '19^0.43'}`
> Entering new chain...
19^0.43```text
19**0.43
```
...numexpr.evaluate("19**0.43")...
Answer: 3.547023357958959
> Finished chain.
Answer: 3.547023357958959Leo DiCaprio's girlfriend is reportedly Eden Polani. Her current age raised to the power of 0.43 is approximately 3.55.
> Finished chain.
"Leo DiCaprio's girlfriend is reportedly Eden Polani. Her current age raised to the power of 0.43 is approximately 3.55."
可以看到,该代理人可以成功地完成寻求知识和科学计算得到的结果。
示例2 SQL代理
这个案例是结合大模型和数据库,通过查询表里的数据来回答用户问题,用的关键提示为
_postgres_prompt = """You are a PostgreSQL expert. Given an input question, first create a syntactically correct PostgreSQL query to run, then look at the results of the query and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per PostgreSQL. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use CURRENT_DATE function to get the current date, if the question involves "today".
Use the following format:
Question: Question here
SQLQuery: SQL Query to run
SQLResult: Result of the SQLQuery
Answer: Final answer here
"""
下面是实际的工作代码,目前在这个场景中,openai的推理能力最强,能够正确完成这个复杂的代理工作。
## export your openai key first export OPENAI_API_KEY=sk-xxxxx
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.agents import AgentExecutor
from langchain.llms.tongyi import Tongyi
from langchain.sql_database import SQLDatabase
import psycopg2cffi as psycopg2 # pip install psycopg-binary if on linux, just use psycopg2
from langchain.chat_models import ChatOpenAI
db = SQLDatabase.from_uri('postgresql+psycopg2cffi://admin:password123@localhost/admin')
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
toolkit = SQLDatabaseToolkit(db=db,llm=llm)
agent_executor = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True
)
agent_executor.run("using the teachers table, find the first_name and last name of teachers who earn less the mean salary?")
可以看到大模型经过多轮思考,正确回答了我们的问题。
> Entering new AgentExecutor chain...
Action: sql_db_list_tables
Action Input: ""
Observation: teachers
Thought:I can query the "teachers" table to find the first_name and last_name columns.
Action: sql_db_schema
Action Input: "teachers"
Observation:
CREATE TABLE teachers (
id INTEGER,
first_name VARCHAR(25),
last_name VARCHAR(50),
school VARCHAR(50),
hire_data DATE,
salary NUMERIC
)
/*
3 rows from teachers table:
id first_name last_name school hire_data salary
None Janet Smith F.D. Roosevelt HS 2011-10-30 36200
None Lee Reynolds F.D. Roosevelt HS 1993-05-22 65000
None Samuel Cole Myers Middle School 2005-08-01 43500
*/
Thought:I can now construct a query to find the first_name and last_name of teachers who earn less than the mean salary.
Action: sql_db_query
Action Input: "SELECT first_name, last_name FROM teachers WHERE salary ._completion_with_retry in 4.0 seconds as it raised RateLimitError: Rate limit reached for default-gpt-3.5-turbo in organization org-FDYSniIsv0FIQBi9p4P9Dinn on requests per min. Limit: 3 / min. Please try again in 20s. Contact us through our help center at help.openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method..
Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.._completion_with_retry in 4.0 seconds as it raised RateLimitError: Rate limit reached for default-gpt-3.5-turbo in organization org-FDYSniIsv0FIQBi9p4P9Dinn on requests per min. Limit: 3 / min. Please try again in 20s. Contact us through our help center at help.openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method..
Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.._completion_with_retry in 4.0 seconds as it raised RateLimitError: Rate limit reached for default-gpt-3.5-turbo in organization org-FDYSniIsv0FIQBi9p4P9Dinn on requests per min. Limit: 3 / min. Please try again in 20s. Contact us through our help center at help.openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method..
Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.._completion_with_retry in 8.0 seconds as it raised RateLimitError: Rate limit reached for default-gpt-3.5-turbo in organization org-FDYSniIsv0FIQBi9p4P9Dinn on requests per min. Limit: 3 / min. Please try again in 20s. Contact us through our help center at help.openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method..
The first_name and last_name of teachers who earn less than the mean salary are Janet Smith, Samuel Cole, Samantha Bush, Betty Diaz, and Kathleen Roush.
Final Answer: Janet Smith, Samuel Cole, Samantha Bush, Betty Diaz, Kathleen Roush
> Finished chain.
'Janet Smith, Samuel Cole, Samantha Bush, Betty Diaz, Kathleen Roush'
问题和挑战
和ChatBot不同,agent的构建对LLM的推理能力提出了更高的要求。ChatBot的答案可能是不正确的,但仍然可以通过人类的判别回馈来确定问答结果是否可以有效,对于无效的答案是否可以有效耐受地直接忽略或者重新回答。但是代理对模型的错误判断的耐受程度则较高。虽然我们可以通过自我反思机制降低代理的错误率,但其当前可以应用的情况依然较小。需要我们不断去探索和开拓新的场景,同时不断提高大模型的推理能力,从而能够搭建更加复杂的代理。
同时,代理目前能够在比较小的场景中胜任工作,比如我们的意思是明确的,同时也只给代理提供了比较小的工具包来执行任务(10个以内),并且每个工具的用差异明显,在这种情况下,LLM能够正确地选择工具执行任务,并得到期望的结果。当一个代理里注册了上百个甚至更多的工具时,LLM就可能无法正确地选择工具执行操作了。这里的一个解决方法是通过层级agent树的方式来解决,父agent负责路由分发任务给不同的子agent。每个子agent则简单包含并使用有限的工具包来执行任务,从而agent复杂场景提高任务完成率。
快来关注
云原生数据仓库AnalyticDB是一款海量处理数据仓库服务,可提供海量数据在线分析服务。在云原生数据仓库能力上全自研企业级存储引擎,支持流式处理数据写入、百亿数据级索引检索数据;支持结构化数据分析、索引检索和全文检索多路召回,支持对问卷千问等主题主流大模型。
作者:清都
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
