
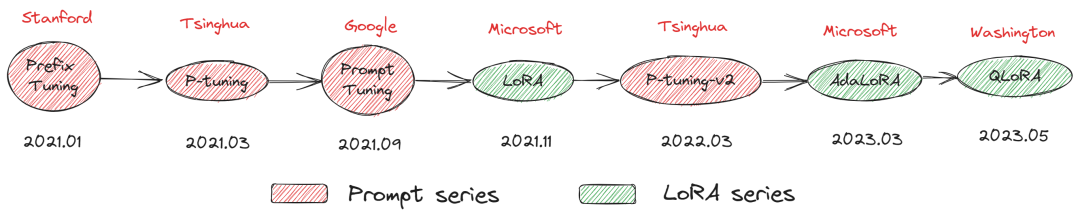
常见参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT)有哪些呢?主要是Prompt系列和LoRA系列。本文主要介绍P-Tuning v2微调方法。如下所示:
-
Prompt系列比如,Prefix Tuning(2021.01-Stanford)、Prompt Tuning(2021.09-Google)、P-Tuning(2021.03-Tsinghua)、P-Tuning v2(2022.03-Tsinghua); -
LoRA系列比如,LoRA(2021.11-Microsoft)、AdaLoRA(2023.03-Microsoft)、QLoRA(2023.05-Washington)。 -
还有不知道如何分类的比如,BitFit、Adapter Tuning及其变体、MAM Adapter、UniPELT等。
一.P-Tuning v2工作原理
1.Hard/Soft Prompt-Tuning如何设计
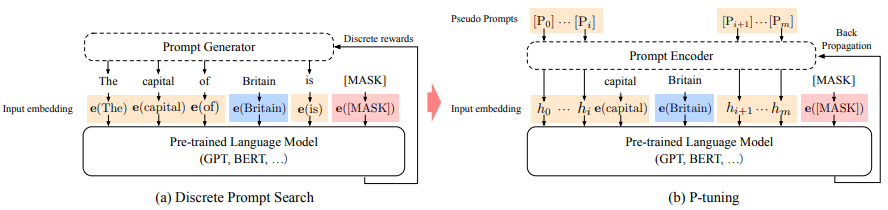
提示工程发展经过了从人工或半自动离散空间的hard prompt设计,到采用连续可微空间soft prompt设计的过程,这样的好处是可通过端到端优化学习不同任务对应的prompt参数。
2.P-Tuning工作原理和不足
主要是将continuous prompt应用于预训练模型的输入层,预训练模型后面的每一层都没有合并continuous prompt。
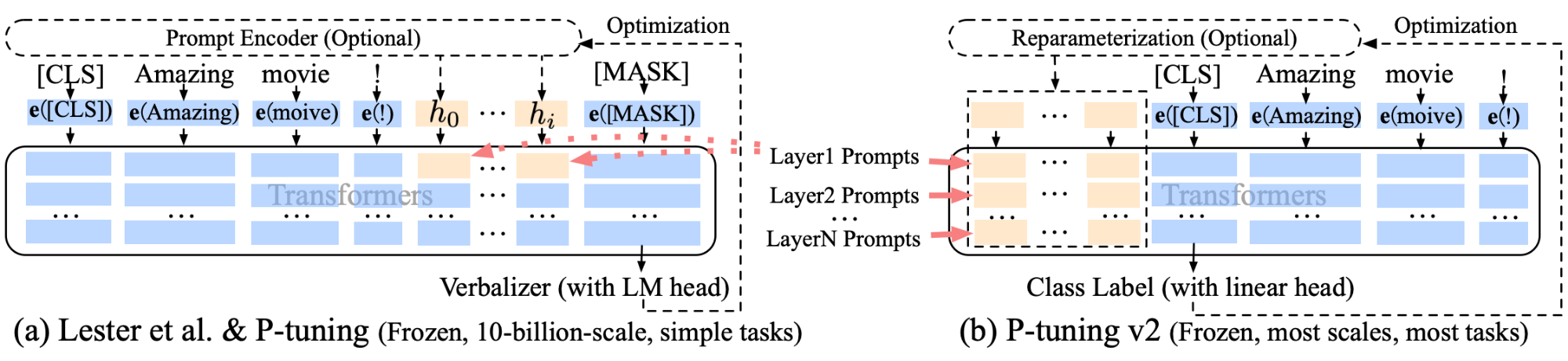
3.P-Tuning v2如何解决P-Tuning不足
P-Tuning v2把continuous prompt应用于预训练模型的每一层,而不仅仅是输入层。
二.P-Tuning v2实现过程
1.整体项目结构
源码参考文献[4],源码结构如下所示:

参数解释如下所示:
(1)–model_name_or_path L:/20230713_HuggingFaceModel/20231004_BERT/bert-base-chinese:BERT模型路径
(2)–task_name qa:任务名字
(3)–dataset_name squad:数据集名字
(4)–do_train:训练过程
(5)–do_eval:验证过程
(6)–max_seq_length 128:最大序列长度
(7)–per_device_train_batch_size 2:每个设备训练批次大小
(8)–learning_rate 5e-3:学习率
(9)–num_train_epochs 10:训练epoch数量
(10)–pre_seq_len 128:前缀序列长度
(11)–output_dir checkpoints/SQuAD-bert:检查点输出目录
(12)–overwrite_output_dir:覆盖输出目录
(13)–hidden_dropout_prob 0.1:隐藏dropout概率
(14)–seed 11:种子
(15)–save_strategy no:保存策略
(16)–evaluation_strategy epoch:评估策略
(17)–prefix:P-Tuning v2方法
执行代码如下所示:
python3run.py--model_name_or_pathL:/20230713_HuggingFaceModel/20231004_BERT/bert-base-chinese--task_nameqa--dataset_namesquad--do_train--do_eval--max_seq_length128--per_device_train_batch_size2--learning_rate5e-3--num_train_epochs10--pre_seq_len128--output_dircheckpoints/SQuAD-bert--overwrite_output_dir--hidden_dropout_prob0.服务器托管网1--seed11--save_strategyno--evaluation_strategyepoch--prefix
2.代码执行流程
(1)P-tuning-v2/run.py
-
根据task_name==”qa”选择tasks.qa.get_trainer -
根据get_trainer得到trainer,然后训练、评估和预测
(2)P-tuning-v2/tasks/qa/get_trainer.py
-
得到config、tokenizer、model、squad数据集、QuestionAnsweringTrainer对象trainer -
重点关注model是如何得到的
#fix_bert表示不更新bert参数,model数据类型为BertPrefixForQuestionAnswering
model=get_model(model_args,TaskType.QUESTION_ANSWERING,config,fix_bert=True)
-
重点关注QuestionAnsweringTrainer具体实现
trainer=QuestionAnsweringTrainer(#读取trainer
model=model,#模型
args=training_args,#训练参数
train_dataset=dataset.train_datasetiftraining_args.do_trainelseNone,#训练集
eval_dataset=dataset.eval_datasetiftraining_args.do_evalelseNone,#验证集
eval_examples=dataset.eval_examplesiftraining_args.do_evalelseNone,#验证集
tokenizer=tokenizer,#tokenizer
data_collator=dataset.data_collator,#用于将数据转换为batch
post_process_function=dataset.post_processing_function,#用于将预测结果转换为最终结果
compute_metrics=dataset.compute_metrics,#用于计算评价指标
)
(3)P-tuning-v2/model/utils.py
选择P-tuning-v2微调方法,返回BertPrefixForQuestionAnswering模型,如下所示:
defget_model(model_args,task_type:TaskType,config:AutoConfig,fix_bert:bool=False):
ifmodel_args.prefix:#训练方式1:P-TuningV2(prefix=True)
config.hidden_dropout_prob=model_args.hidden_dropout_prob#0.1
config.pre_seq_len=model_args.pre_seq_len#128
config.prefix_projection=model_args.prefix_projection#False
config.prefix_hidden_size=model_args.prefix_hidden_size#512
#task_type是TaskType.QUESTION_ANSWERING,config.model_type是bert,model_class是BertPrefixForQuestionAnswering
model_class=PREFIX_MODELS[config.model_type][task_type]
#model_args.model_name_or_path是bert-base-chinese,config是BertConfig,revision是main
model=model_class.from_pretrained(model_args.model_name_or_path,config=config,revision=model_args.model_revision,)

(4)P-tuning-v2/model/question_answering.py(重点)
主要是BertPrefixForQuestionAnswering(BertPreTrainedModel)模型结构,包括构造函数、前向传播和获取前缀信息。
(5)P-tuning-v2/model/prefix_encoder.py(重点)
在BertPrefixForQuestionAnswering(BertPreTrainedModel)构造函数中涉及到前缀编码器PrefixEncoder(config)。
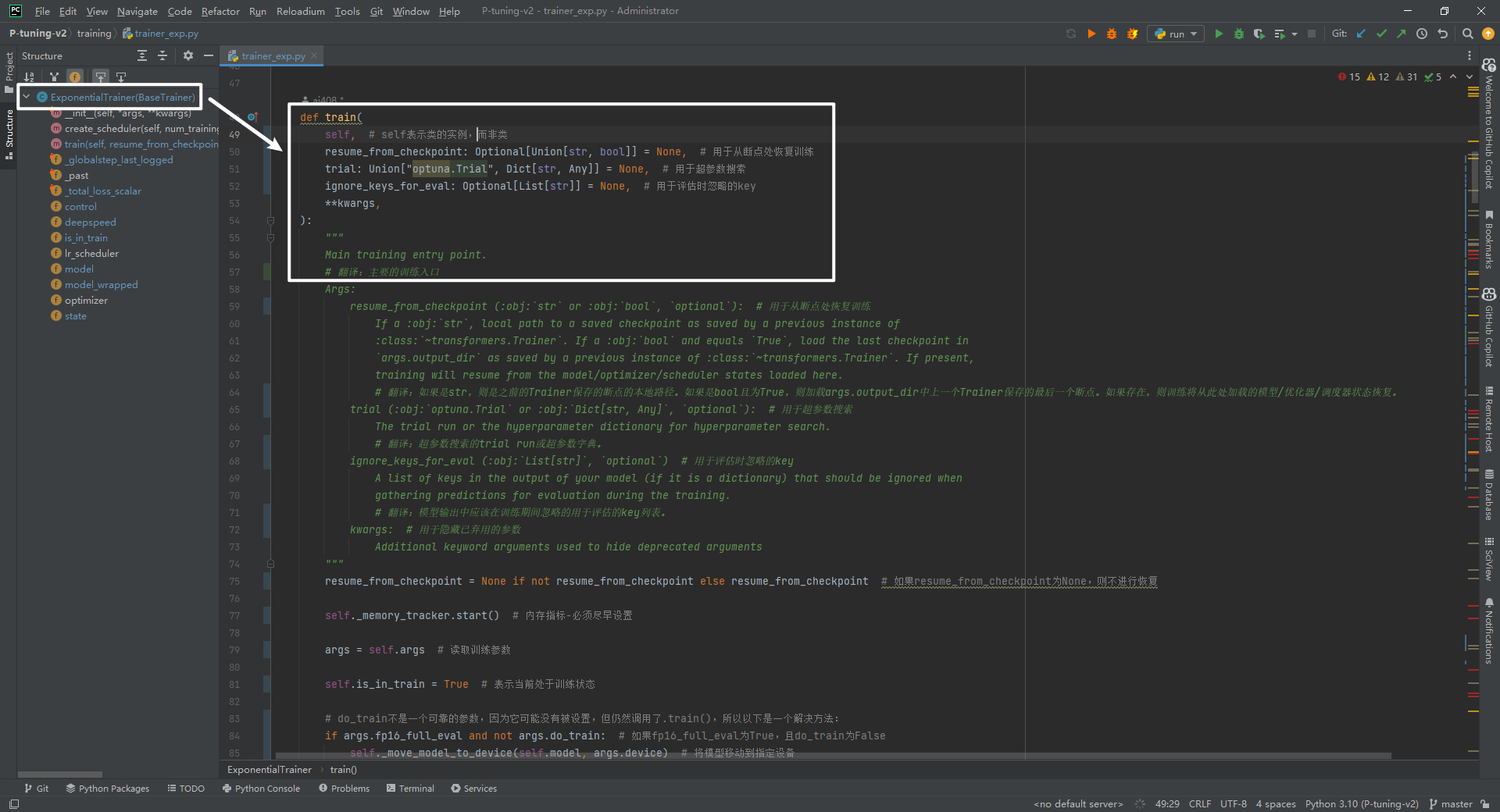
(6)P-tuning-v2/training/trainer_qa.py
继承关系为QuestionAnsweringTrainer(ExponentialTrainer)->ExponentialTrainer(BaseTrainer)->BaseTrainer(Trainer)->Trainer,最核心训练方法如下所示:
3.P-tuning-v2/model/prefix_encoder.py实现
该类作用主要是根据前缀prefix信息对其进行编码,假如不考虑batch-size,那么编码后的shape为(prefix-length, 2*layers*hidden)。假如prefix-length=128,layers=12,hidden=768,那么编码后的shape为(128,2*12*768)。
classPrefixEncoder(torch.nn.Module):
def__init__(self,config):
super().__init__()
self.prefix_projection=config.prefix_projection#是否使用MLP对prefix进行投影
ifself.prefix_projection:#使用两层MLP对prefix进行投影
self.embedding=torch.nn.Embedding(config.pre_seq_len,config.hidden_size)
self.trans=torch.nn.Sequential(
torch.nn.Linear(config.hidden_size,config.prefix_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(config.prefix_hidden_size,config.num_hidden_layers*2*config.hidden_size)
)
else:#直接使用Embedding进行编码
self.embedding=torch.nn.Embedding(config.pre_seq_len,config.num_hidden_layers*2*config.hidden_size)
defforward(self,prefix:torch.Tensor):
ifself.prefix_projection:#使用MLP对prefix进行投影
prefix_tokens=self.embedding(prefix)
past_key_values=self.trans(prefix_tokens)
else:#不使用MLP对prefix进行投影
past_key_values=self.embedding(prefix)
returnpast_key_values
这里面可能会有疑问,为啥还要乘以2呢?因为past_key_values前半部分要和key_layer拼接,后半部分要和value_layer拼接,如下所示:
key_layer=torch.cat([past_key_value[0],key_layer],dim=2)
value_layer=torch.cat([past_key_value[1],value_layer],dim=2)
说明:代码路径为transformers/models/bert/modeling_bert.py->class BertSelfAttention(nn.Module)的forward()函数中。
4.P-tuning-v2/model/question_answering.py
简单理解,BertPrefixForQuestionAnswering就是在BERT上添加了PrefixEncoder,get_prompt功能主要是生成past_key_values,即前缀信息的编码表示,用于与主要文本序列一起输入BERT模型,以帮助模型更好地理解问题和提供答案。因为选择的SQuAD属于抽取式QA数据集,即根据question从context中找到answer的开始和结束位置即可。
classBertPrefixForQuestionAnswering(BertPreTrainedModel):
def__init__(self,config):
self.bert=BertModel(config,add_pooling_layer=False)#bert模型
self.qa_outputs=torch.nn.Linear(config.hidden_size,config.num_labels)#线性层
self.prefix_encoder=PrefixEncoder(config)#前缀编码器
defget_prompt(self,batch_size):#根据前缀token生成前缀的编码,即key和value值
past_key_values=self.prefix_encoder(prefix_tokens)
past_key_values=past_key_values.view(
bsz,#batch_size
seqlen,#pre_seq_len
self.n_layer*2,#n_layer表示BERT模型的层数
self.n_head,#n_head表示注意力头的数量
self.n_embd#n_embd表示每个头的维度
)
returnpast_key_values
defforward(self,...,return_dict=None):
past_key_values=self.get_prompt(batch_size=batch_size)#获取前缀信息
attention_mask=torch.cat((prefix_attention_mask,attention_mask),dim=1)
outputs=self.bert(
......
past_key_values=past_key_values,
)
returnQuestionAnsweringModelOutput(#返回模型输出,包括loss,开始位置的logits,结束位置的logits,hiddenstates和attentions
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
重点是outputs = self.bert(past_key_values=past_key_values),将past_key_values传入BERT模型中,起作用的主要是transformers/models/bert/modeling_bert.py->class BertSelfAttention(nn.Module)的forward()函数中。接下来看下past_key_values数据结构,如下所示:

5.BertSelfAttention实现
BERT网络结构参考附件1,past_key_values主要和BertSelfAttention部分中的key和value进行拼接,如下所示:
(self):BertSelfAttention(
(query):Linear(in_features=768,out_features=768,bias=True)
(key):Linear(in_features=768,out_features=768,bias=True)
(value):Linear(in_features=768,out_features=768,bias=True)
(dropout):Dropout(p=0.1,inplace=False)
)
具体past_key_values和key、value拼接实现参考代码,如下所示:
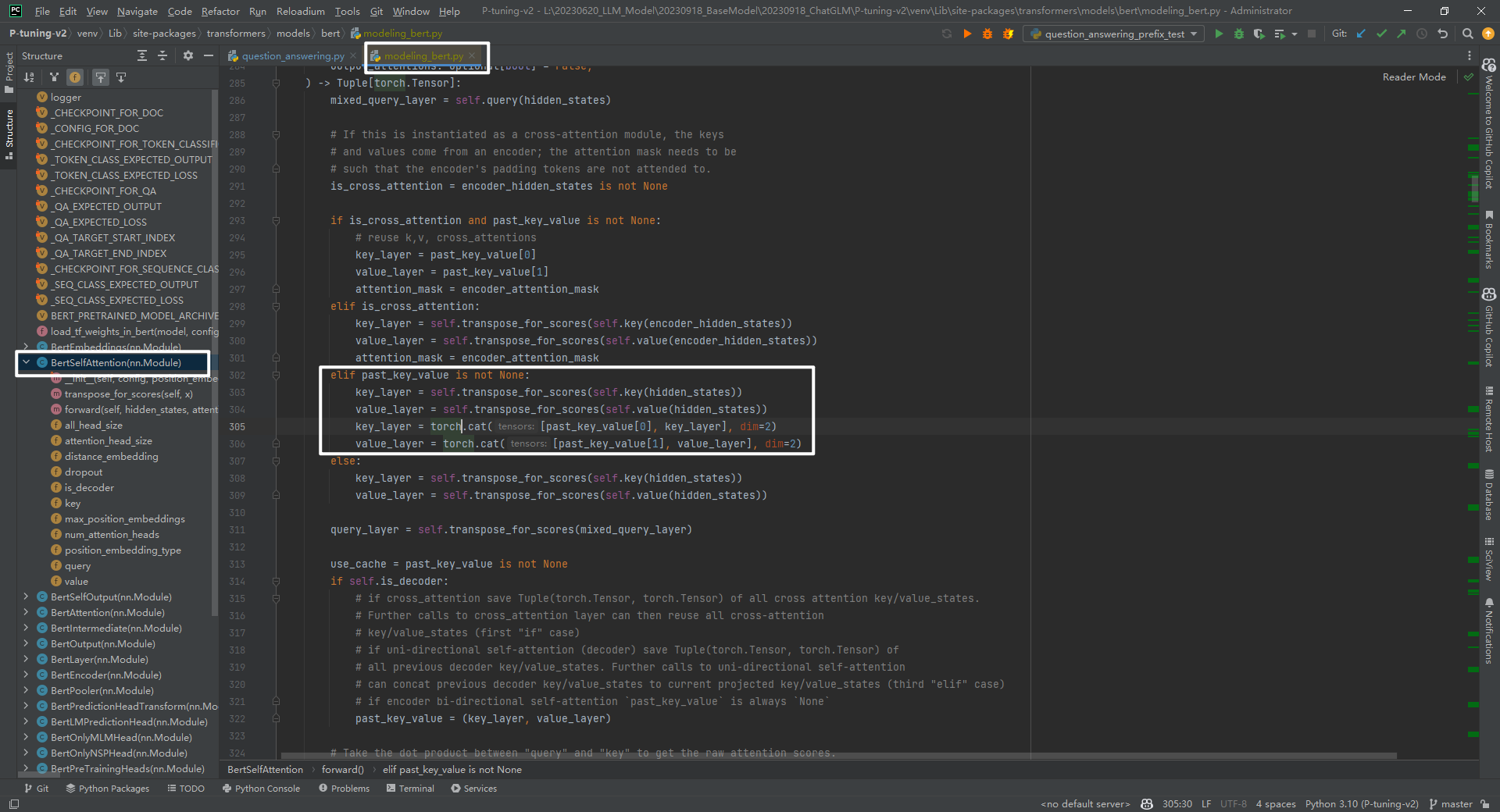
经过BertSelfAttention部分后,输出outputs的shape和原始输入的shape是一样的,即都不包含前缀信息。
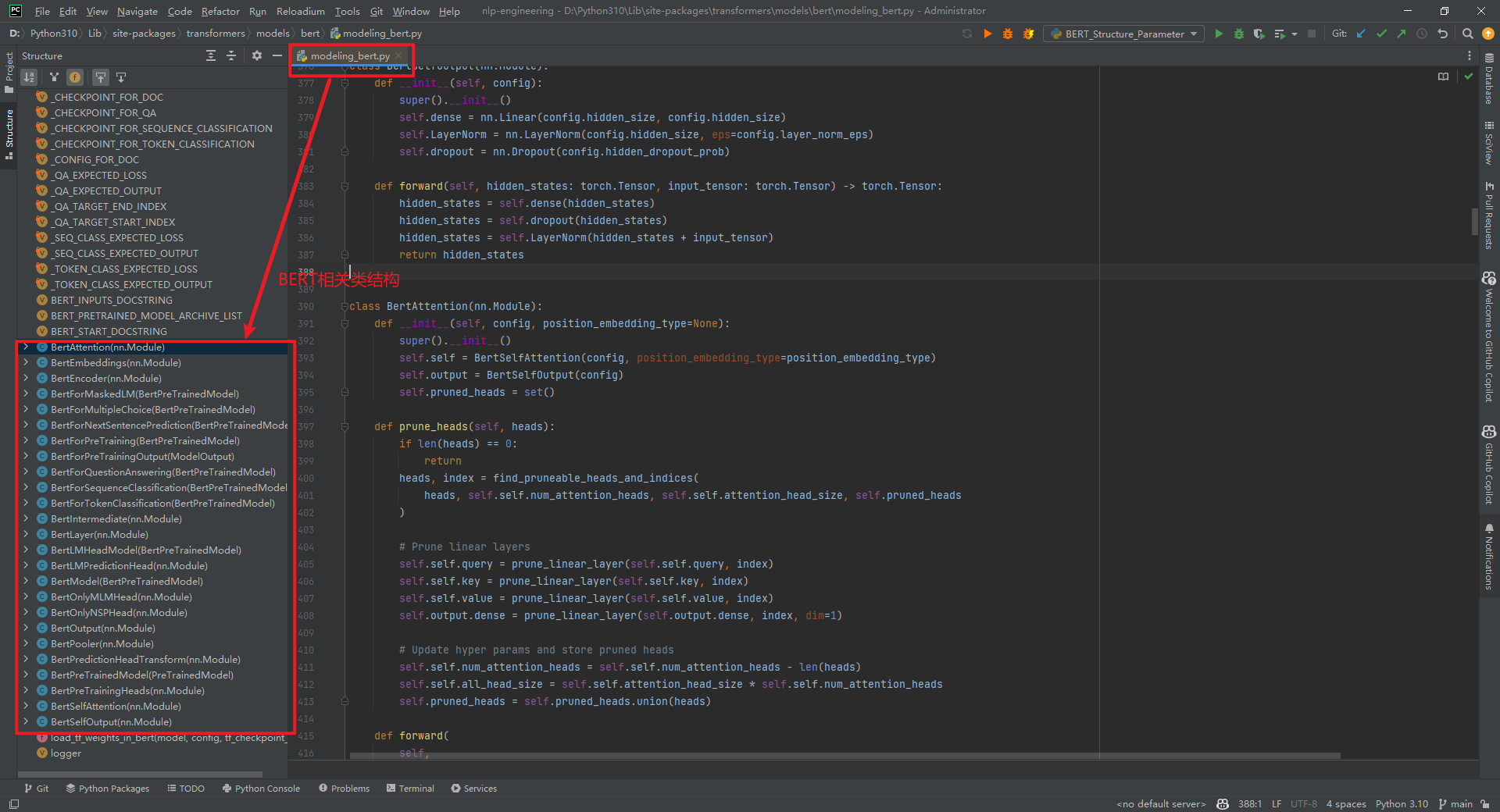
附件1:BERT网络结构
打印出来BERT模型结构,如下所示:
BertModel(
(embeddings):BertEmbeddings(
(word_embeddings):Embedding(21128,768,padding_idx=0)
(position_embeddings):Embedding(512,768)
(token_type_embeddings):Embedding(2,768)
(LayerNorm):LayerNorm((768,),eps=1e-12,elementwise_affine=True)#embeddings层做了LayerNorm
(dropout):Dropout(p=0.1,inplace=False)#embeddings层做了Dropout
)
(encoder):BertEncoder(
(layer):ModuleList(
(0-11):12xBertLayer(#BertLayer包括BertAttention、BertIntermediate和BertOutput
(attention):BertAttention(#BertAttention包括BertSelfAttention和BertSelfOutput
(self):BertSelfAttention(
(query):Linear(in_features=768,out_features=768,bias=True)
(key):Linear(in_features=768,out_features=768,bias=True)
(value):Linear(in_features=768,out_features=768,bias=True)
(dropout):Dropout(p=0.1,inplace=False)
)
(output):BertSelfOutput(
(dense):Linear(in_features=768,out_features=768,bias=True)
(LayerNorm):LayerNorm((768,),eps=1e-12,elementwise_affine=True)
(dropout):Dropout(p=0.1,inplace=False)
)
)
(intermediate):BertIntermediate(
(dense):Linear(in_features=768,out_features=3072,bias=True)
(intermediate_act_fn):GELUActivation()
)
(output):BertOutput(
(dense):Linear(in_features=3072,out_features=768,bias=True)
(LayerNorm):LayerNorm((768,),eps=1e-12,elementwise_affine=True)
(dropout):Dropout(p=0.1,inplace=False)
)
)
)
)
(pooler):BertPooler(
(dense):Linear(in_features=768,out_features=768,bias=True)
(activation):Tanh()
)
)
BERT模型相关类结构在文件D:Python310Libsite-packagestransformersmodelsbertmodeling_bert.py中,如下所示:
附件2:SQuAD数据集
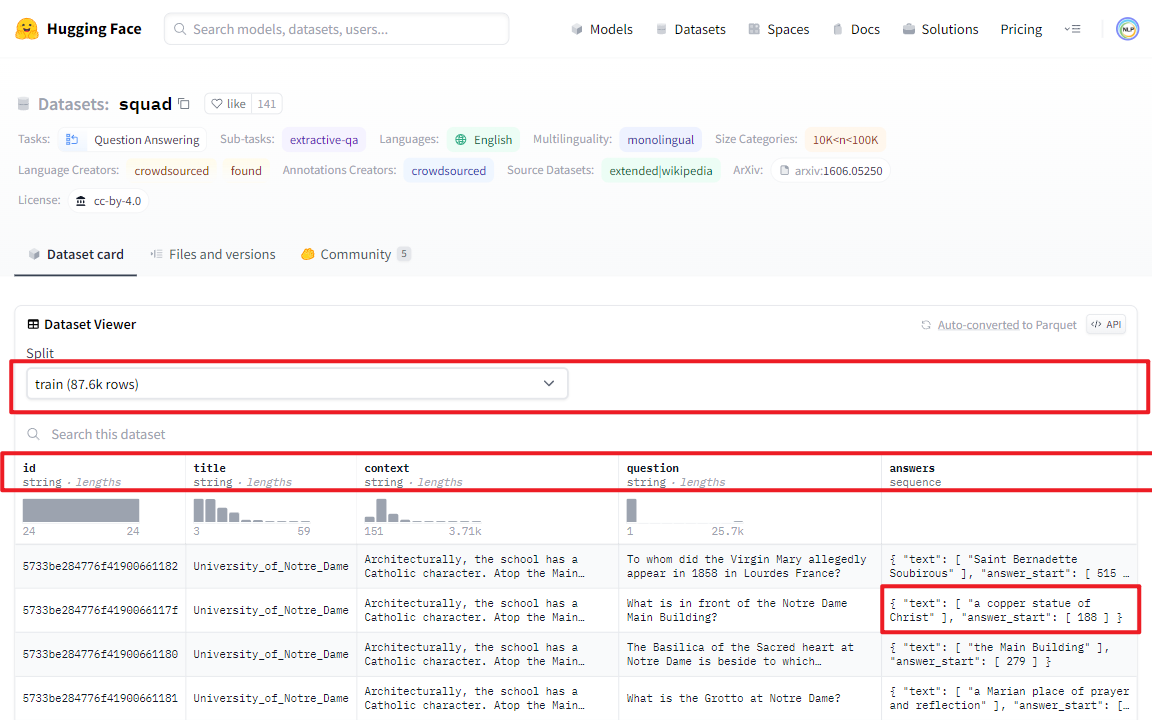
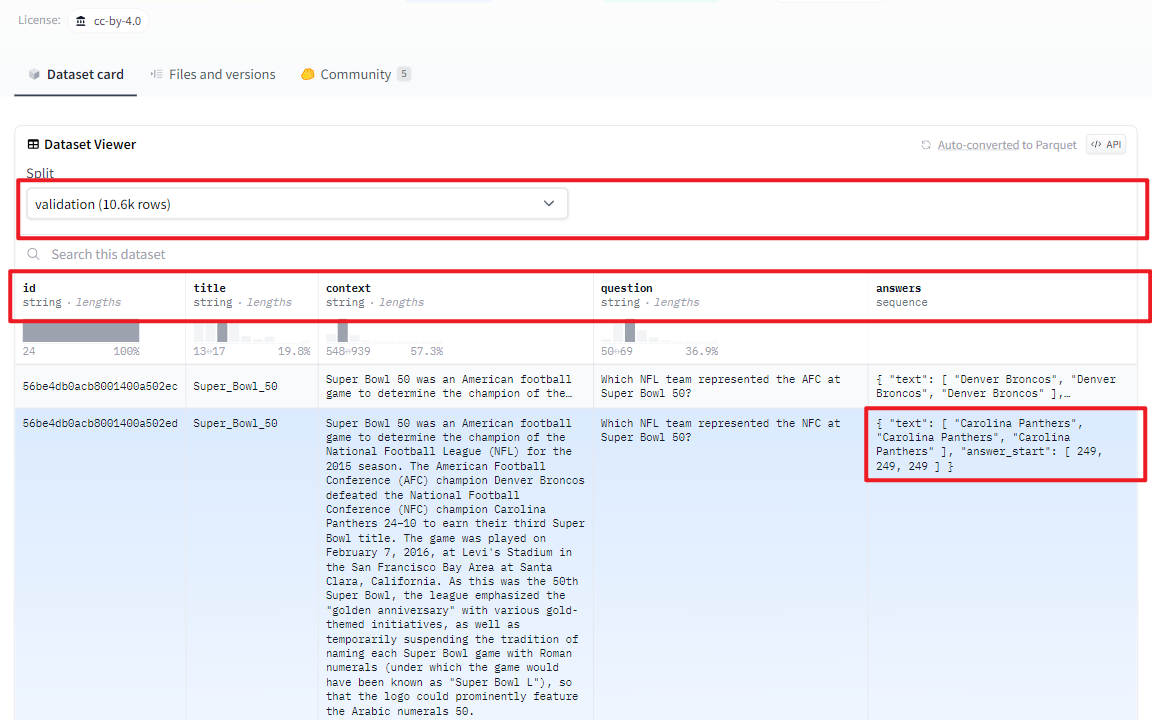
SQuAD是斯坦福大学推出的机器阅读理解问答数据集,其中每个问题的答案来自于对应阅读段落的一段文本,即(问题,原文,答案)。一共有107,785问题,以及配套的536篇文章。除了SQuAD 1.1之外,还推出了难度更大的新版本SQuAD 2.0(《Know What You Don’t Know: Unanswerable Questions for SQuAD》_ACL2018)。
(1)训练集数据
(2)验证集数据
(3)加载SQuAD数据集
"""
执行脚本:python3dataset_test.py--model_name_or_pathL:/20230713_HuggingFaceModel/20231004_BERT/bert-base-chinese--task_nameqa--dataset_namesquad--do_train--do_eval--max_seq_length128--per_device_train_batch_size2--learning_rate5e-3--num_train_epochs10--pre_seq_len128--output_dircheckpoints/SQuAD-bert--overwrite_output_dir--hidden_dropout_prob0.1--seed11--save_strategyno--evaluation_strategyepoch--p服务器托管网refix
"""
fromtransformersimportAutoTokenizer,HfArgumentParser,TrainingArguments
fromargumentsimportget_args,ModelArguments,DataTrainingArguments,QuestionAnwseringArguments
fromtasks.qa.datasetimportSQuAD
if__name__=='__main__':
args=get_args()#从命令行获取参数
model_args,data_args,training_args,qa_args=args#model_args是模型相关参数,data_args是数据相关的参数,training_args是训练相关的参数
tokenizer=AutoTokenizer.from_pretrained(#读取tokenizer
model_args.model_name_or_path,#模型名称
revision=model_args.model_revision,#模型版本
use_fast=True,#是否使用fasttokenizer
)
dataset=SQuAD(tokenizer,data_args,training_args,qa_args)
print(dataset)
打个断点看下dataset数据结构如下所示:
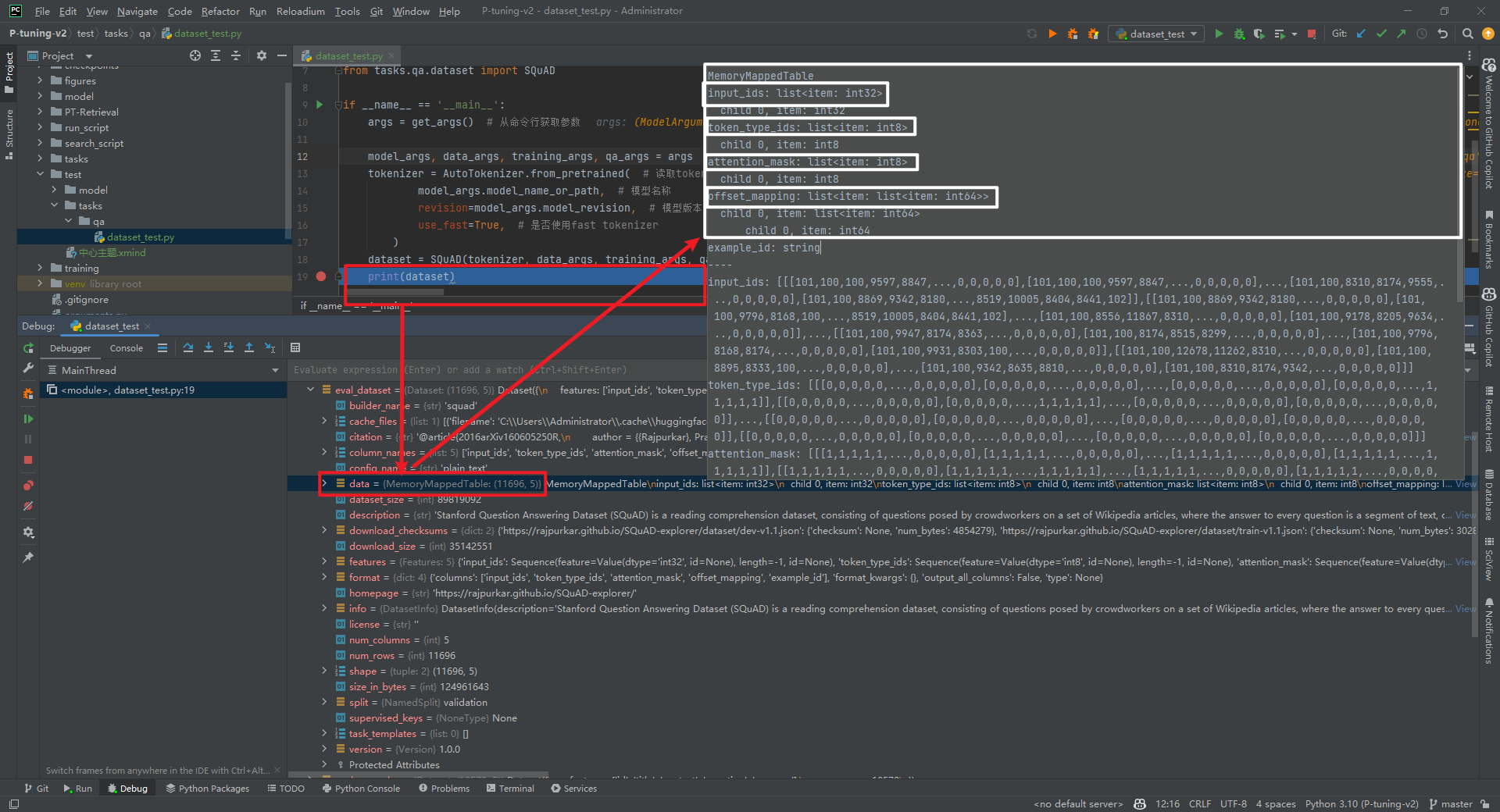
-
input_ids:经过tokenizer分词后的subword对应的下标列表 -
attention_mask:在self-attention过程中,这一块mask用于标记subword所处句子和padding的区别,将padding部分填充为0 -
token_type_ids:标记subword当前所处句子(第一句/第二句/ padding) -
position_ids:标记当前词所在句子的位置下标 -
head_mask:用于将某些层的某些注意力计算无效化 -
inputs_embeds:如果提供了,那就不需要input_ids,跨过embedding lookup过程直接作为Embedding进入Encoder计算 -
encoder_hidden_states:这一部分在BertModel配置为decoder时起作用,将执行cross-attention而不是self-attention -
encoder_attention_mask:同上,在cross-attention中用于标记encoder端输入的padding -
past_key_values:在P-Tuning V2中会用到,主要是把前缀编码和预训练模型每层的key、value进行拼接。 -
use_cache:将保存上一个参数并传回,加速decoding -
output_attentions:是否返回中间每层的attention输出 -
output_hidden_states:是否返回中间每层的输出 -
return_dict:是否按键值对的形式返回输出,默认为真。
觉得P-Tuning v2里面还有很多知识点没有讲解清楚,只能后续逐个讲解。仅仅一个P-Tuning v2仓库代码涉及的知识点非常之多,首要就是把Transformer和BERT标准网络结构非常熟悉,还有对各种任务及其数据集要熟悉,对BERT变体网络结构要熟悉,对于PyTorch和Transformer库的深度学习模型训练、验证和测试流程要熟悉,对于Prompt系列微调方法要熟悉。总之,对于各种魔改Transformer和BERT要了如指掌。
参考文献:
[1]P-Tuning论文地址:https://arxiv.org/pdf/2103.10385.pdf
[2]P-Tuning代码地址:https://github.com/THUDM/P-tuning
[3]P-Tuning v2论文地址:https://arxiv.org/pdf/2110.07602.pdf
[4]P-Tuning v2代码地址:https://github.com/THUDM/P-tuning-v2
[5]BertLayer及Self-Attention详解:https://zhuanlan.zhihu.com/p/552062991
[6]https://rajpurkar.github.io/SQuAD-explorer/
[7]https://huggingface.co/datasets/squad
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
知识点总结 以将其右侧的信息插入到流中, endl:重起一行。在输出流中插入endl将导致光标移动到下一行开头,它确保程序继续运行前刷新输出(将其立即显示在屏幕上) 空格、制表符、回车统称为空白, volatile 可以保证对特殊地址的稳定访问 抽象和类。类是…
