
ChatGPT 的爆火证明了大型语言模型(LLM)在生成知识和推理方面的能力。不过,ChatGPT 是使用公共数据集进行预训练的模型,因此可能无法提供与用户业务相关的特定答案或结果。
那么,如何使用私有数据最大化发挥 LLM 的能力?LlamaIndex 可以解决这一问题。LlamaIndex 是一个简单、灵活、集中的接口,可用于连接外部数据和 LLMs。
近期,Zilliz 与 LlamaIndex 梦幻联动,举办了一次干货满满的网络研讨会。会上,LlamaIndex 的联合创始人兼首席执行官 Jerry Liu 向大家介绍了如何使用 LlamaIndex 通过私有数据提升 LLM 能力。
LlamaIndex:使用私有数据增强 LLM 的神器
“如何使用私有数据增强 LLM”是困扰许多 LLM 开发者的一大难题。在网络研讨会中,Jerry 提出了两种方法:微调和上下文学习。
所谓“微调”是指使用私有数据重新训练网络,但这个方案成本高昂,缺乏透明度,且这种方法可能只在某些情况下才有效。另一种方法是上下文学习。“上下文学习”是指将预训练模型、外部知识和检索模型相结合。这样开发者就能在输入 prompt 的过程中添加上下文。不过,结合检索和内容生成,检索上下文、管理海量源数据方面都会让整个过程显得困难重重,LlamaIndex 系列工具正好可以解决这些问题。
开源工具 LlamaIndex 能够为 LLM 应用提供中央数据管理和查询接口。LlamaIndex 系列工具主要包含三个组件:
- 数据连接器——用于接收各种来源的数据。
- 数据索引——用于为不同应用场景调整数据结构。
- 查询接口——用于输入 prompt 和接收经过知识扩展后生成的结果。
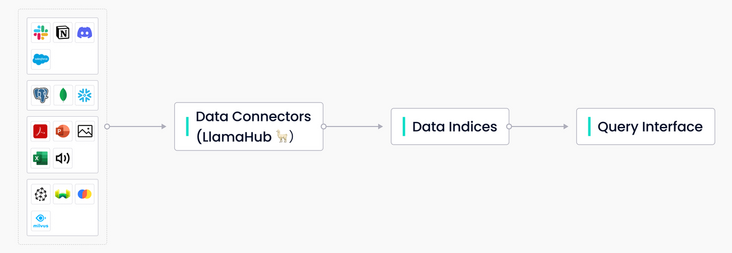
|LlamaIndex 的三个主要组件
LlamaIndex 也是开发 LLM 应用的重要工具。它像一个黑匣子,接收详细的查询描述,返回相应回答和丰富的参考资料。LlamaIndex 还可以管理语言模型和私有数据之间的应用集成,从而提供准确的结果。

|整个应用流程中的LlamaIndex
LlamaIndex VS 向量检索
LlamaIndex 向量索引的工作原理
LlamaIndex 支持各种索引,包括列表索引、向量索引、树索引和关键字索引。Jerry 在网络研讨会中以向量索引为例,展示了 LlamaIndex 索引的工作原理。向量索引是一种常见的检索和数据整合模式,它能将向量存储库与语言模型进行配对。LlamaIndex 向量索引先接收一组源文档数据,将文档切分成文本片段,并将这些片段存入内置的向量存储库里,每个片段都有相应的向量与之对应。当用户进行查询时,查询问题先转化为向量,然后在向量存储系统中检索 top-k 最相似的向量数据。后续,这些检索出来的相似向量数据将在相应合成模块中用于生成结果。
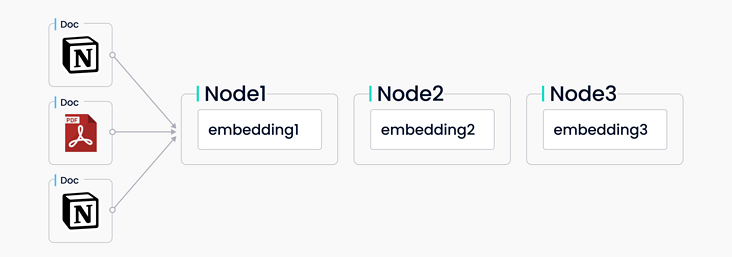
|LlamaIndex 接收数据
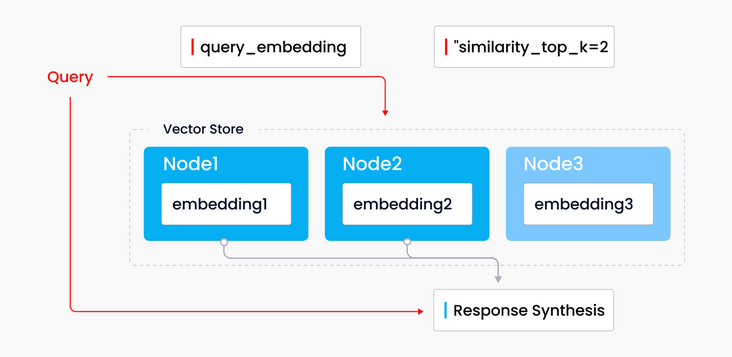
|通过向量存储系统查询
对于在 LLM 应用中引入相似性检索有刚需的用户而言,向量存储系统的索引是最好的选择。这种索引类型非常适合语义相似性检索,因为它可以比较不同文本。例如,向量存储索引适合搭建问答机器人,回答各种关于特定开源项目的问题(参考 OSSChat)。
集成 Milvus 和 LlamaIndex
LlamaIndex 集成十分多样且轻量。在本次网络研讨会中,Jerry 强调了 Milvus 和 LlamaIndex 的集成(参考:https://milvus.io/docs/integrate_with_llama.md)。
开源向量数据库 Milvus 可以处理数百万、数十亿甚至数万亿规模的向量数据集。在这个集成中,Milvus 承担了后端向量库的角色,用来存储文本片段和向量。集成 Milvus 和 LlamaIndex 也十分简单——仅需输入几个参数,在向量存储环节中加入 Milvus,通过查询引擎便可获得问题答案。
当然,作为提供全托管云原生 Milvus 服务的 Zilliz Cloud 同样支持集成 LlamaIndex
LlamaIndex 应用案例
在网络研讨会中,Jerry 还分享了许多 LlamaIndex 的典型应用场景,包括:
- 语义搜索
- 总结归纳
- 文本转化为 SQL 结构化数据
- 合成异构数据
- 比较/对比查询
- 多步骤查询
更多用例详情,可以点击观看视频讲解。
精彩问答集锦
- 如何看待 OpenAI 的插件?如何使用 OpenAI 插件与 LlamaIndex 协同合作?
Jerry Liu: 这是个好问题。一方面,我们其实就是 OpenAI 的插件之一,可以被任何外部代理调用,无论是 ChatGPT 还是 LangChain,任何外部代理都可以调用我们。客户端代理将一个输入请求发送给我们,我们以最佳的方式执行。比如,在 ChatGPT 的 chatgpt-retrieval-plugin 仓库里就可以找到我们的插件。另一方面,从客户端的角度而言,我们支持与任何软件服务集成,只要这个服务是[ [chatgpt-retrieval-plugin] ](https://github.com/openai/chatgpt-retrieval-plugin/blob/main/datastore/providers/llama_datastore.py)插件。
- 您提到了性能和延迟方面的 tradeoff。在这一方面,你们遇到过哪些瓶颈或挑战?
Jerry Liu: 如果上下文更丰富、文本块更大,延迟也会更高。有人认为文本块越大,生成的结果越准确,也有人持怀疑态度。总之,文本块大小是否影响性能结果还存在争议。
GPT-4 在处理提供更多上下文的问题时就比 GPT-3 的表现要好。但总的来说,我认为文本块大小和性能结果还是正相关的。另一个权衡是任何高级 LLM 系统都需要用链式方法进行调用,这样一来执行所需时间也会变长。
- 如果使用外部模型来执行查询,传输私有数据是否安全?
Jerry Liu: 这取决于使用的 API 服务。例如,OpenAI 不会使用 API 数据来训练或者优化其模型。但一些企业仍然会担心 OpenAI 向第三方发送敏感数据。因此,我们最近新增了 PII 模块来应对这一问题。还有一种解决方法就是使用本地模型。
- 以下两种方法的优缺点分别是什么?方法一:在 LlamaIndex 上加载数据和建索引之前,利用如 Milvus 之类的向量数据库进行相似性检索和图索引优化。方法二:使用 LlamaIndex 原生的 vector store 集成?
Jerry Liu: 两种方法都可以。我们正在计划整合这两种方法。敬请期待。
如果使用 Milvus 加载数据,用户可以在现有数据上使用 LlamaIndex。如果使用 LlamaIndex 中由 Milvus 提供的向量索引,我们会根据现有数据,重新定义数据结构。前者的好处是用户可以直接使用现有数据,后者的好处是可以定义元数据。
- 我需要在本地分析大约 6,000 个 PDF 和 PowerPoint 文件。如果不使用 OpenAI 和 LlamaIndex 的 llama65b 模型,我如何才能获取最佳分析结果?
Jerry Liu: 如果你可以接受 Llama 的许可证,那我还是建议尝试使用 Llama。
点击查看 GitHub 上的开源模型。
🌟【特别提醒】为了让用户更丝滑地使用 Zilliz Cloud,我们也将于今年 6 月底登陆阿里云,与其他几朵云的合作也已提上日程,敬请期待!
- 如果在使用 Milvus 或Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群
- 欢迎关注微信公众号“Zilliz”,了解最新资讯。

本文由mdnice多平台发布
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
近日,财政部会计司发布了《关于公布电子凭证会计数据标准(试行版)的通知》,为做好电子凭证会计数据标准深化试点工作,研究制定了9类电子凭证的会计数据标准。在通知的《电子凭证会计数据标准——全面数字化的电子发票(试行版)》指南中,明确了数电票报销入账归档的具体…
