
1. 背景
应项目需求,本qiang~这两周全身心投入了进去。
项目是关于一个博物馆知识图谱,上层做KBQA应用。实现要求是将传统KBQA中的部分模块,如NLU、指代消解、实体对齐等任务,完全由LLM实现,本qiang~针对该任务还是灰常感兴趣的,遂开展了项目研发工作。
注意,此篇是纯纯的干货篇,除了源码没有提供外,整体核心组件均展示了出来。也是这两周工作的整体总结,欢迎大家查阅以及加关注(不强求哈~)
2. 整体框架
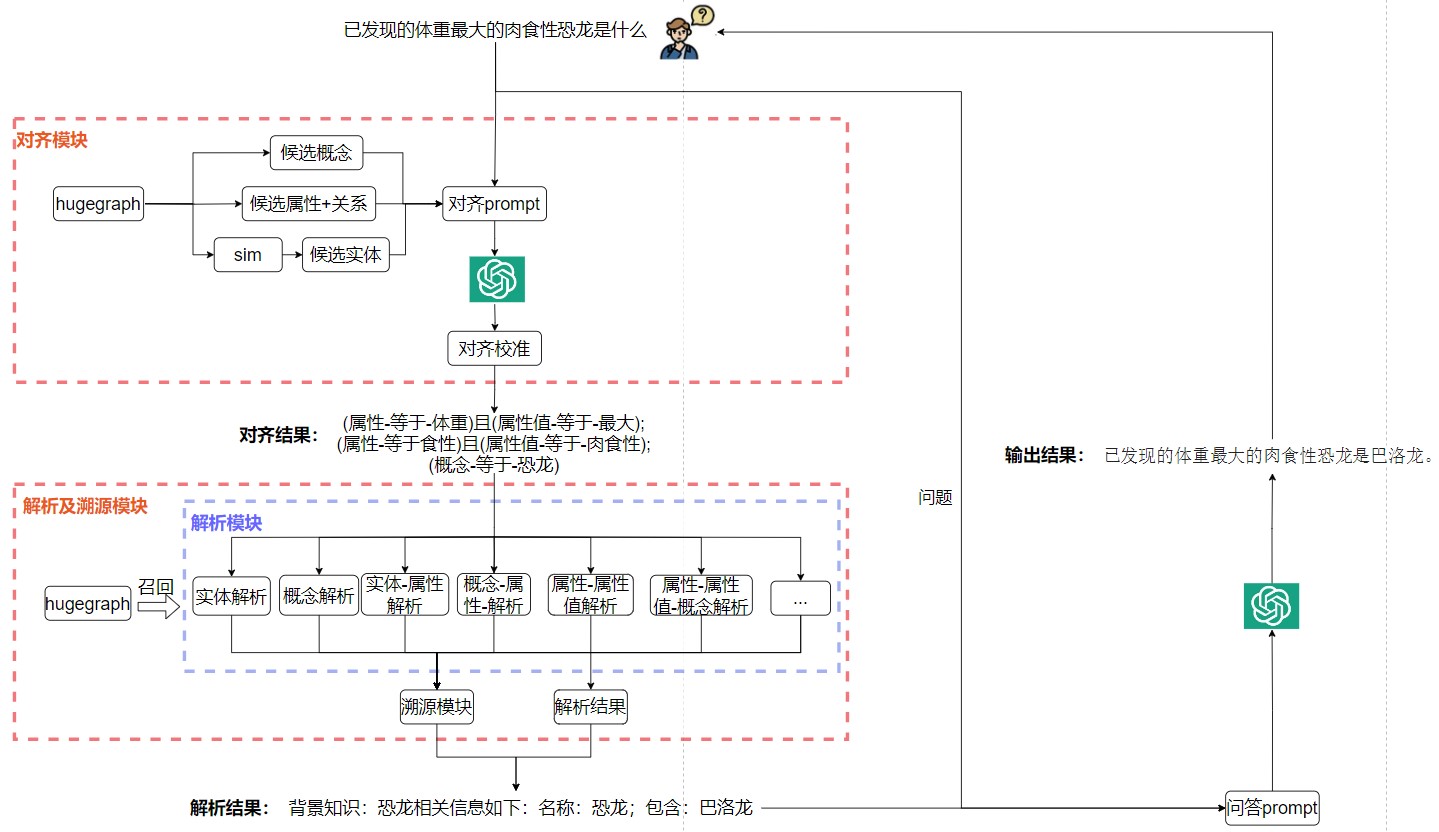
整体思想还是遵循RAG策略,从图谱召回候选背景知识,让LLM进行润色回答。
具体的流程如下:
(1) 用户提问:已发现的体重最大的肉食性恐龙是什么
(2) 对齐模块。
对齐模块的主要作用是针对问题与知识图谱中的实体、概念、关系、属性进行对齐。
其中候选概念、候选属性、候选关系在图谱中的数量是少量有限的,而实体的数量可多可少,因此候选概念、候选属性、候选关系可以在查询hugegraph后,直接拼到对齐prompt中(对齐的prompt预留了占位符),而实体则需要进行预筛选,筛选的方式是通过问题query与实体名进行语义相似度比较,通过语义相似度引擎实现,比如simbert, bge, gte等开源模型,预筛选后的少量实体可以拼接到对齐prompt。
对齐的prompt增加要求和few-shot示例,可以解决常见对齐问题,比如实体、概念、属性、关系存在缺字、多字、相似字等情况。
(3) 对齐模块经过LLM进行服务器托管对齐,输出对齐结果。
本示例的对齐结果为:(属性-等于-体重)且(属性值-等于-最大); (属性-等于-食性)且(属性值-等于-肉食性);(概念-等于-恐龙)。
(4) 对齐校准模块。
对齐校准模块主要针对LLM对齐结果进行二次校对,解决的问题如下:
1) 一些LLM将概念与实体混淆的情况;
2) 与图谱中的实体、概念、属性、关系进行对齐匹配;
3) 实体名和概念名重复时,二者均进行召回等
(5) 解析及溯源模块
解析模块:
针对校准后的对齐结果,执行解析模块,解析模块会基于对齐结果进行判断,该执行如下哪种解析,候选的解析列表有:纯实体解析、纯概念解析、实体-属性解析、概念-属性解析、属性-属性值解析、属性-属性值-概念解析等。
(Ps: 候选解析列表是分析了大量数据之后,抽象出来的解析列表,常见的问答基本就涵盖在这些列表中)
每个解析模块会有不同的解析逻辑,例如:
1) 纯实体解析:会将查询hugegraph得到的实体作为背景知识提供给LLM,如介绍下霸王龙
2) 纯概念解析:会查询概念下有哪些实体,且仅列出实体名称作为背景知识提供给LLM,如恐龙都有哪些?
3) 实体-属性解析:会查询实体对应的属性或关系,并作为背景知识,如霸王龙有多重多高?
4) 概念-属性解析:会查询概念下实体的属性信息作为背景知识,如恐龙目下动物的体重分别是多少?
5) 属性-属性值解析:会查询属性对应属性值的信息,并作为背景知识,如肉食性的动物有?
溯源模块:主要功能就是从图谱中查询的结果,需要返回图谱对应的实体id、概念id、属性等
6) 问答模块
通过将解析后的背景知识以及用户的问题,经过问答prompt,然后调用LLM进行润色回答。
PS:
对齐prompt调用大模型是非流式输出,因为对齐结果不需要实时同步给用户;
问答prompt调用大模型是流式输出,因为问答结果需要实时同步给用户
3. 优缺点
(1) 优点
1) 整体架构简单,仅需要2个prompt,与LLM仅交互2次
2) 解析模块基于多数据集进行抽象,可覆盖多数查询场景
3) 针对未覆盖的场景,解析模块可支持快速扩展适配
4) 迁移新图谱时,业务只需要更改prompt即可,对业务相对友好
(2) 缺点
1) 首字响应时间主要耗时在对齐prompt与LLM的交互中,因为需要对齐完整输出结果
2) 概念、属性、实体对齐集中在1个prompt中,所以prompt的长度较长
4. 多轮问答实现
实现的思路如下:
1) 缓存历史问题以及缓存历史对齐的实体或概念,如可以缓存最近10轮的用户问题以及对齐结果
2) 针对指代消解、语义对齐prompt调优,且多轮问答的prompt也集成在对齐prompt中(因此,对齐prompt任务十分繁重)
具体示例如下(从对齐prompt截取了部分,第一次输入参考为空):
|
历史输入信息: “` 输入:盐都龙喜欢吃什么 参考: 输入:喜欢生活在什么地方 参考:盐都龙 输入:三角龙是植食还是肉食 参考:盐都龙 输入:有什么本事 参考:三角龙 输入:普尔塔龙多重 参考:三角龙 “` 现在请回答: 输入: 吃什么 参考: 普尔塔龙 输出: |
具体的效果可以查阅下面章节中的效果示例。
5. 效果
图谱三元组总量3000+,测试样例共计385条,其中单轮问答340条,多轮问答45条。
(1) 单轮问答效果,准确率93%+
|
一阶问答 |
华阳龙的头骨化石是在哪里发现的 |
华阳龙的头骨化石是在中国四川省发现的。 |
|
判断问答 |
恐爪龙有4米长吗 |
恐爪龙的身长是3.5米左右,没有4米。 |
|
对比问答 |
三角龙和姜氏巴克龙谁更重 |
三角龙更重。 |
|
条件问答 |
化石在四川发现的恐龙有哪些 |
最大体型的长羽毛恐龙是二连巨盗龙。 |
|
组合问答 |
单爪龙身长体重多少? |
单爪龙的身长是1~1.2米,体重约3.5千克。 |
(2) 多轮问答效果,准确率93%+
1) 示例1:缺字情况
问:普尔塔多重
答:普尔塔龙的体重是75吨。
问:吃什么
答:普尔塔龙是植食性的
2) 示例2:错字情况
问:河堤列龙生活在什么地方
答:河堤猎龙生活在英国的怀特岛和奇尔顿岭。
问:它是什么时候的恐龙
答:河堤猎龙是早白垩世,巴雷姆期的恐龙。
3) 示例3:较困难的指代消解
问:三角龙是植食还是肉食
答:三角龙是植食性的。
问:有啥本事
答:三角龙的能力是快速奔跑。
问:和肿头龙比,谁更长一些?
答:三角龙的身长为8米,而肿头龙的身长为4~6米。因此,三角龙更长一些。
问:那它的体重是多少?
答:三角龙的体重是6.1~12吨。
6. 答疑解惑
(1) 候选实体、候选概念、候选属性如何动态加载至prompt?
解:prompt预留占位符,代码解析时进行格式化
(2) 概念、属性数量有限,可以全部写在prompt,但如果实体有1W个呢?
解:基于sim进行候选实体召回策略
(3) 如何实现流式输出?
解:基于tornado的websocket框架,结合异步框架asyncio以及python的yield、next等方法实现
(4) 非流式调用LLM出现网络不稳定导致超时,如何解决?
解:增加重试机制
(5) 对齐结果如何进一步保障?
解:增加对齐校准模块
(6) 如何减少频繁调用hugegraph
解:预先加载图谱至内存,然后使用python的lru_cache缓存机制
(7) 如何提高属性、概念、实体对齐的准确率,比如多字、缺字、相近字等?
解:对齐prompt增加要求以及few-shot
(8) 如何解决实体文字完全不一致,但指的同一个实体的情况,比如霸王龙和雷克斯暴龙?
解:通过图谱的别名维护,且当前别名与正式名地位相同
(9) 溯源是如何实现的?
解:在每个解析分支中,基于解析结果增加对应图谱的信息
(10) 如何实现最大、最小之类的查询,如体重最大的植食性恐龙是哪个?
解:对齐结果:(属性-等于-体重)且(属性值-等于-最大)且(概念-等于-恐龙)
解析逻辑:筛选恐龙概念下实体 -> 食性为植食性的实体 -> 其中体重最大的
(11) 如何实现关系的推理,比如鱼石螈演进关系的演进关系是?
解:原始图谱关系:鱼石螈 -> 演进关系 ->蜥螈 -> 演进关系 -> 异齿龙
对齐结果:(实体-等于-鱼石螈)且(属性-等于-演进关系);(属性-等于-演进关系)
答案:鱼石螈的演进关系是蜥螈,而蜥螈的演进关系是异齿龙。
(12) 为什么说解析模块便于快速扩展?
解:实体、概念、属性查询接口均封装为独立方法。
(13) 对比类、判断类的问题回答如何更加口语化?
解:问答prompt调优
(14) 如何快速定位问题?
解:增加debug机制,即接口调用时,debug机制会将每个阶段的处理结果均记录下来,并返回。
(15) 目前支持多少轮问答?
解:理论上支持N多轮,且N支持配置
(16) 如何提高指代消解的准确率?
解:对齐prompt增加历史的参考实体或概念
7. 遗留的问题
(1) 基于属性值查实体未实现,分析部分badcase,属于此类情况
(2) 服务器托管路径查询未实现,因为当前图谱关系数量极少
8. 总结
一句话足矣~
本文主要是KBQA方案基于LLM实现,主要模块包括对齐、解析、润色、多轮问答等内容,而且基于业务测试集效果相对较好。
纯纯的干货篇!!
原创声明,禁止转载!

服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: WPF Blend for visual studio使用
Blend for visual studio介绍 VS自带的Blend for visual studio是专门用来做WPF、Metro等的界面设计的可视化工具,其功能和PS类似。其目的让做界面和后台的程序分开,能快速绘制形状和路径、修改对象样式、动态显示对…
