

目前,微调定制化LLM会耗费工程师的大量时间和精力,而选择合适的微调方法以及掌握相关技巧可以做到事半功倍。
此前,在《微调语言大模型选LoRA还是全参数?基于LLaMA 2深度分析》中,文中对比了全参数微调和LoRA各自的优势和劣势。而在《LoRA和QLoRA微调语言大模型:数百次实验后的见解》中,本文作者讨论了使用LoRA和QLoRA对LLM进行微调的实用见解。在本文中,作者进一步分享了使用LoRA微调LLM的实用技巧,并回答了LoRA相关的十个常见问题。
本文作者是机器学习和人工智能研究员Sebastian Raschka。Sebastian已在人工智能领域深耕十多年,在这一领域拥有丰富的经验。
(以下内容由OneFlow编译发布,转载请联系授权。原文:https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms)
作者 |Sebastian Raschka
OneFlow编译
翻译|杨婷、宛子琳
LoRA(低秩自适应)是目前用于高效训练定制语言大模型(LLM)的最广泛和最有效的技术之一。对于那些对开源LLM感兴趣的人来说,这是一项值得熟悉的关键技术。
上个月,我分享了基于开源Lit-GPT代码库进行的几个LoRA实验的文章,该代码库由我和Lightning AI的同事共同维护。这篇AI前沿文章旨在讨论我从实验中获得的主要经验教训。如果你想要微调定制LLM,希望本文能对你有所帮助,为你节省时间。
简而言之,本文我将主要讨论以下几点:
-
尽管在LLM(或通常在GPU上训练模型时)的训练中存在固有的随机性,但从多次运行的结果来看,最终仍表现出惊人的稳定性。
2. 如果你受限于GPU内存,QLoRA可能是值得考虑的选择。它可以节省33%的内存,但运行时间将增加39%。
3. 微调LLM时,优化器的选择并不是我们关注的重点。虽然单独使用随机梯度下降(SGD)效果不佳,但无论是选择AdamW、带调度器的SGD或者带调度器的AdamW,它们对模型的最终结果影响都不大。
4. Adam为每个模型参数引入了两个新参数,所以人们通常认为它是一种内存密集型优化器,但这并没有显著影响LLM的内存峰值需求,因为大部分内存用于大规模矩阵乘法运算上,而不是保留额外的参数。
5. 对静态数据集来说,进行多次迭代(也就是进行多轮训练)并不一定有益。相反,这可能会由于过拟合,导致结果恶化。
6. 如果你正在使用LoRA,应将其应用于所有层(而不是仅仅应用于Key和Value矩阵),以最大化模型性能。
7. 调整LoRA的秩(rank)并选择合适的alpha值至关重要。将alpha值设定为rank值的两倍是一个明智的选择。
8. 我们可以在14GB RAM的单个GPU上,在几小时内有效微调70亿参数的模型。使用静态数据集优化一个LLM,让其完美胜任所有基准任务难以实现。要解决这个问题,需要使用多样化的数据源,或许LoRA并不是理想的工具。
此外,我将回答有关LoRA的十个常见问题。
1
LoRA简介
语言大模型规模庞大,由于GPU内存限制,在训练期间更新模型的所有权重十分昂贵。
例如,假设我们有一个LLM,其中权重矩阵W表示7B参数。(实际上,模型参数分布在许多层的不同矩阵中,但为简单起见,这里指的是单个权重矩阵 )在反向传播过程中,我们学习一个W矩阵,其中包含了我们希望更新原始权重以最小化训练过程中损失函数的信息。
权重更新如下:
更新后的W = W + W
如果权重矩阵W包含7B个参数,则权重更新矩阵W也包含7B个参数,计算矩阵W需要大量的计算和内存资源。
Hu等人提出的LoRA方法将权重变化W分解为一个低秩表示(https://arxiv.org/abs/2106.09685)。因此,LoRA方法能够在训练过程中直接学习权重变化W的分解表示,而不需要显式计算W,从而节约了计算资源,如下图所示。
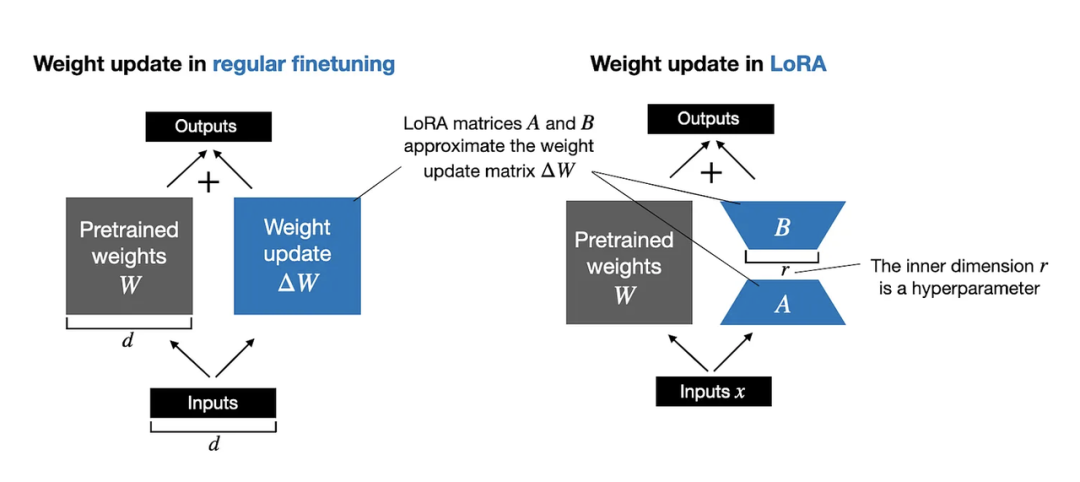
如上图所示,W的分解意味着我们用了两个较小的LoRA矩阵A和B来表示大型矩阵W。如果A的行数与W相同,B的列数与W相同,那么我们可以将分解表示为W = AB。(这里的AB表示矩阵A和B的矩阵相乘的结果。)
这样做能够节省多少内存呢?这取决于分解的秩r,这是一个超参数。举例来说,如果W有10000行和20000列,那么它将存储200000000个参数。如果我们选择r=8的A和B,那么A有10000行和8列,B有8行和20000列,这样总共就有100008 + 820000 = 240000个参数,比200000000少了830倍左右。
当然,A和B无法捕获W可能捕获的所有信息,这是设计使然。使用LoRA时,我们假设W在模型中是一个具有完整秩的大矩阵,以捕获预训练数据集中的所有知识。然而,当我们微调LLM时,并不需要更新所有权重,并且只需用比W更小的权重数量捕捉适应性的核心信息。因此,我们可以通过AB进行低秩更新。
2
LoRA一致性
通过对LoRA进行多次实验,我发现,尽管在语言模型训练中或者在GPU上训练模型时存在固有随机性,但基准结果却在不同运行中表现出了惊人的一致性。这为进一步的比较研究提供了良好基础。

(请注意,结果是在默认设置下使用较小的r=8获得的。实验的详细信息见我的另一篇文章。)
3
QLoRA 计算内存权衡
Dettmers等人提出的QLoRA是量化LoRA的缩写,这种技术可进一步减少微调期间的内存使用。在反向传播期间,QLoRA将预训练权重量化为4位精度,并使用分页优化器处理内存峰值。
事实上,我发现使用LoRA可以节省33%的GPU内存。然而,由于在QLoRA中对预训练模型权重进行额外的量化和去量化处理,导致训练运行时间增加了39%。
默认LoRA为16位浮点精度:
-
训练时间: 1.85 小时
-
内存占用: 21.33 GB
QLoRA为4位普通浮点数:
-
训练时间: 2.79 小时
-
内存占用: 14.18 GB
此外,我发现QLoRA几乎没有影响模型的建模性能,因此可以作为常规LoRA训练的替代方案,以应对常见的GPU内存瓶颈。

4
学习率调度器
学习率调度器会在整个训练过程中降低学习率,以优化收敛并避免损失函数极小值的超调(overshooting)。
余弦退火(Cosine annealing)是一种学习率调度器,它根据余弦曲线调整学习率。它从一个较高的学习率开始平滑地递减,以一种类似余弦函数的方式逼近零点。一个常用的变体是半周期变体,在训练过程中只完成半个余弦周期,如下图所示。

作为实验的一部分,我向LoRA微调脚本中添加了余弦退火调度器,并观察到它显著提高了随机梯度下降(SGD)的性能。然而,对于Adam和AdamW优化器,它的影响较小,几乎没有什么区别。

接下来,我将讨论SGD相对Adam的潜在优势。
5
Adam vs SGD
Adam和AdamW优化器在处理大模型时非常占内存,尽管如此,它们在深度学习中仍然非常受欢迎,因为Adam优化器为每个模型参数维护两个移动平均值:梯度的一阶矩(均值)和梯度的二阶矩(非中心化的方差)。换句话说,Adam优化器在内存中为每个单一模型参数存储了两个额外的值。如果我们处理一个7B参数的模型,那就需要在训练过程中追踪额外的140亿个参数。
SGD优化器在训练过程中不需要追踪任何额外参数,那么在训练语言大模型时,将Adam替换为SGD对峰值内存需求有何优势?
在我的实验中,使用AdamW和LoRA默认参数(r=8)训练一个包含7B个参数的Llama 2模型需要14.18 GB的GPU内存。而如果使用SGD进行训练,相同的模型则只需要14.15GB的GPU内存。换句话说,节省的内存(0.03 GB)非常有限。
为什么节省的内存如此之少?因为使用LoRA时,我们只有少量可训练的参数。举例来说,如果r=8,那么在7B参数的Llama 2模型中,我们只有4194304个可训练的LoRA参数,而总参数量为6738415616个。服务器托管网
如果只单纯看数字,4194304个可训练参数听起来还是很多,但通过计算会发现,我们只有4194304 2 16位 = 134.22兆位 = 16.78兆字节。(我们观察到0.03 Gb = 30 Mb的差异,因为存储和复制优化器状态会产生额外开销。)这里的2代表Adam存储的额外参数数量,而16位是指模型权重的默认精度。

然而,如果我们将LoRA的r增加到256,这是我在后续实验中做过的,那么Adam和SGD优化器之间的差异就会变得更加显著:
-
AdamW的内存占用为17.86 GB
-
SGD的内存占用为14.46 GB
值得一提的是,当LoRA的r较小时,将Adam优化器替换为SGD可能并不值得。然而,当我们增大r时,这样做可能是值得的。
6
多轮训练
在传统深度学习中,我们经常对训练集进行多次迭代,对训练集的一次迭代称为一个epoch。例如,我们通常会对卷积神经网络进行数百个epoch训练。那么,对指令微调进行多轮训练是否有用呢?
当我将包含5万个示例的Alpaca指令微调数据集的迭代次数增加两倍(相当于增加了2个epoch)时,注意到模型性能有所下降。

结论是,对指令微调进行多轮训练作用不大,可能会导致结果恶化。我在1000个示例的LIMA数据集上也观察到了同样的情况。这种性能下降可能是由过拟合导致的,这需要进一步的研究。
7
在更多层中应用LoRA
上表所示的实验显示,LoRA仅在选择的权重矩阵上启用,即在每个Transformer层中的Key和Value权重矩阵。此外,我们还可以将LoRA应用于Query权重矩阵、投影层、多头注意力模块之间的其他线性层以及线性输出层。

如果在所有额外层上启用LoRA,对于7B Llama 2模型,可训练参数的数量将增加5倍,从4194304个增至20277248个。这也意味着更大的内存需求(从14.18GB增加到16.62GB),但可以显著提高建模性能。

然而,实验存在一个限制是我仅探索了两种设置:(1) 仅在Query和Value权重矩阵启用LoRA和 (2) 在所有层启用LoRA。在未来的实验中,可能还有其他值得探索的组合。例如,了解在投影层启用LoRA是否真正有益,这可能会很有趣。
8
平衡LoRA超参数:R和Alpha
正如原始的LoRA论文所述,LoRA在前向传播过程中引入了一个额外的扩展系数(scaling coefficient),用于将LoRA权重应用于预训练权重。这种扩展涉及到之前讨论的秩参数r,以及另一个名为(alpha)的超参数,其应用如下:
scaling = alpha / rweight += (lora_B @ lora_A) * scaling
根据上述代码公式,alpha值越大,LoRA权重的影响就越大。
在之前的实验中,使用了r=8和alpha=16,导致了2倍的扩展。在LLM中应用LoRA时,将alpha值设置为r的两倍是一个常见的经验法则,但我好奇这是否仍然适用于更大的r值。换句话说,“alpha = 2rank” 似乎确实是一个合适的选择。然而,在这个特定的模型和数据集组合中,当r=256和alpha=128(0.5倍扩展)时,性能甚至更好。

(我在r分别为32、64、128和512的情况下进行了实验,但为了清晰起见省略了结果,因为r=256时性能最佳。)
通常情况下,将alpha设置为r的两倍会产生最佳结果,但尝试不同的比例也未尝不可。
9
在单个GPU上训练7B参数模型
这里的主要收获之一是,LoRA让我们能够在单个GPU上微调7B参数的LLM。在这种特殊情况下,使用最佳设置(r=256、alpha=512)的QLoRA,在A100上,使用AdamW进行50000个训练示例(Alpaca数据集)的训练,占用了17.86 GB的内存,大约需要3小时。
本文剩余部分将回答其他可能有疑问的地方。
10
常见问题答疑
Q1:数据集的重要性?
数据集至关重要。在实验中,我使用了包含5万个训练样本的Alpaca数据集进行实验,因为这个数据集非常受欢迎。由于文章篇幅限制,在不同数据集上进行实验超出了本次的讨论范围。
不过,值得注意的是,Alpaca是通过查询ChatGPT的旧版本生成的一个合成数据集。在当前标准下,Alpaca可能并不是最佳数据集。
数据质量可能非常重要。例如,在六月份,我讨论了LIMA数据集(AI前沿#9:LLM调优与数据集视角),这是一个仅包含1000个示例的精选数据集。
根据论文《LIMA: Less Is More for Alignment》,使用LIMA微调的65B Llama模型在性能上明显优于在Alpaca上微调的65B Llama模型。

在LIMA上使用最佳配置(r=256,alpha=512)时,我获得了与50倍更大的Alpaca数据集相当、甚至更好的性能。

Q2:LoRA是否适用于领域自适应?
很遗憾,我难以回答上述问题。通常来说,模型会从预训练数据集中吸收知识,而指令微调通常更多地是帮助或引导LLM遵循指令。
然而,值得注意的是,如果内存是一个问题,LoRA也可以用于在特定领域数据集上进一步对已预训练的LLM进行预训练。
需要注意的是,我的实验还包括了两个算术基准测试(它们包含在我其他技术性更强的文章中),在这些基准测试中,经过LoRA微调的模型的性能明显低于预训练基础模型。我的假设是,模型遗忘了算术运算,因为Alpaca数据集中没有相应的示例。关于模型究竟是完全丧失了这些知识,还是因为模型不能再处理这些指令,这需要进一步的研究。然而,一个值得注意的教训是,在微调LLM时,数据集中最好包含你关注的每个任务的示例。
Q3:如何选择最佳秩?
很遗憾,对于选择一个好的r,我并没有好的启发式方法,这是一个需要针对每个LLM和每个数据集进行探索的超参数。我怀疑过大的r可能会导致过拟合。另一方面,较小的r可能无法涵盖数据集中的多样化任务。换句话说,我认为数据集中任务越多样,r就应该越大。例如,如果我只需要一个执行基本的两位数运算的模型,那么很小的r可能就已经足够了。不过,这只是一种假设,还需要进一步研究。
Q4:是否需要在所有层启用LoRA?
我只探索了两种设置:(1)仅启用Query和Value权重矩阵的LoRA,以及(2)启用所有层的LoRA。在未来的实验中,可能值得探索其他组合。例如,了解激活投影层的LoRA是否真的有益,这将是一个有意思的研究方向。

例如,如果我们考虑各种设置(lora_query,lora_key,lora_value,lora_projection,lora_mlp和lora_head),那么就有 2^6 = 64 种组合需要探索。这样的探索将是未来研究的一个有趣课题。
Q5:如何避免过拟合?
通常情况下,较大的r可能会导致更严重的过拟合,因为它决定了可训练参数的数量。如果模型存在过拟合问题,减小r值或增加数据集大小是首选的探索方向。此外,你还可以尝试增加AdamW或SGD优化器中的权重衰减率(weight decay rate),也可以考虑增加LoRA层的dropout值。
我在实验中没有探索的LoRA dropout参数(我使用了固定的0.05的dropout率),这将是未来研究中一个有趣的课题。
Q6:其他优化器?
未来还有一些其他有趣的LLM优化器值得探索。Sophia就是其中之一,它是一种用于语言模型预训练的可扩展随机二阶优化器。
Sophia是一种宣称尤其适用于LLM的二阶优化算法,而Adam和AdamW通常在这一领域占主导地位。根据论文,与Adam相比,Sophia的速度快2倍,并且使用Sophia训练的模型可以实现更好的建模性能。简而言之,Sophia通过梯度曲率(gradient curvature)而非像Adam一样的梯度方差(gradient variance)来对梯度进行归一化。
Q7:其他影响内存占用的因素?
除了精度和量化设置、模型大小、批量大小以及可训练的LoRA参数数量之外,数据集也会影响内存占用。
请注意,Llama 2的block大小为4048。例如,如果一个LLM的block大小为4048个词元,它可以一次处理多达4048个词元的序列。然而,较短的训练序列可以通过屏蔽未来词元来大幅节省内存。
举例来说,Alpaca数据集相对较小,最大长度为1304个词元。
当我尝试其他长度长达2048个词元的数据集时,注意到内存占用从17.86 GB增加到26.96 GB。
Q8:LoRA与完全微调和RLHF相比如何?
我并没有进行任何RLHF实验,但我考虑过进行全微调(full finetuning)。全微调至少需要2个GPU,每个GPU的完成时间为3.5小时,内存占用为36.66GB。然而,由于过拟合或次优超参数,基准结果并不理想。

Q9:是否可以合并LoRA权重?
是的,可以合并多组LoRA权重。在训练过程中,我们将LoRA权重与预训练权重分开存储,并在每次前向传播中将它们相加。
然而,如果你在实际应用中有多组LoRA权重,例如为每个应用用户准备一组权重,将这些权重单独存储以节省磁盘空间是有意义的。然而,在训练后,我们可以合并预训练权重和LoRA权重,创建一个单一的模型。这样就不需要在每次前向传播中应用LoRA权重:
weight+=(lora_B@lora_A)*scaling
相反,我们可以应用如上所示的权重更新,并保存合并(相加)后的权重。
同样,我们可以不断添加多组LoRA权重集:
weight += (lora_B_set1 @ lora_A_set1) * scaling_set1weight += (lora_B_set2 @ lora_A_set2) * scaling_set2weight += (lora_B_set3 @ lora_A_set3) * scaling_set3...
我还没有进行实验来评估这种方法的性能,但从技术上讲,通过Lit-GPT提供的merge_lora.py脚本已经可以实现这一点。
Q10:如何看待逐层最优秩自适应?
为了简单起见,我们通常对深度神经网络使用相同的学习率,而学习率是我们需要优化的超参数。为了更进一步,我们也可以为每一层选择不同的学习率(在PyTorch中,这并不太复杂)。然而,实际操作中很少这样做,因为这会增加额外的计算开销,而在训练深度神经网络时通常已经有很多参数需要调整。
类似于为不同层选择不同学习率,我们也可以为不同层选择不同的LoRA秩。我没有找到与此相关的实验,但有一份详细介绍这种方法的文档,称为逐层最优秩自适应(也缩写为LORA)。从理论上讲,这听起来是个不错的主意。然而,在优化超参数时,这也将增加大量的选择。
其他人都在看
-
LoRA和QLoRA微调语言大模型
-
可复现的语言大模型推理性能指标
-
ChatGPT规模化服务的经验与教训
-
机器学习硬件十年:性能变迁与趋势
-
微调语言大模型选LoRA还是全参数?
-
语言大模型的分布式训练与高效微调指南
-
开源语言大模型演进史:向LLaMA2看齐
试用OneFlow: github.com/Oneflow-Inc/oneflow/

本文分享自微信公众号 – OneFlow(OneFlowTechnology)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
Wireshark 是一款功能强大的网络协议分析工具,可以帮助您查看和分析不同运营商的网络协议。以下是一般的使用方法: 安装 Wireshark:首先,在您的计算机上安装 Wireshark。您可以从官方网站(https://www.wireshark.org…
