
目录
Map和Set是用来专门查找的数据结构,查找效率非常高
Map是k服务器托管网ey-value模型(对应了两个东西)
Set是纯key模型(只对应i一个东西)
Map的使用
Map的方法
Map的put()方法
Map的get()方法
Map的getOrdefault()方法
Map的keySet()方法
Map的entrySet()方法
Entry是Map的内部接口类编辑Entry的方法,v>,v>
Map的values()方法,返回类型是Collection
Map的containsKey()方法
Map的containsValue()方法
Set的使用
Set的方法,
1.有100W个(10个)数据,并且数据有重复的,将所有重复的数据进行去重复
2.有100W个(10个)数据,并且数据有重复的,找到第一个重复的数据
3.统计10W个(几个)数据当中,每个数据出现的次数
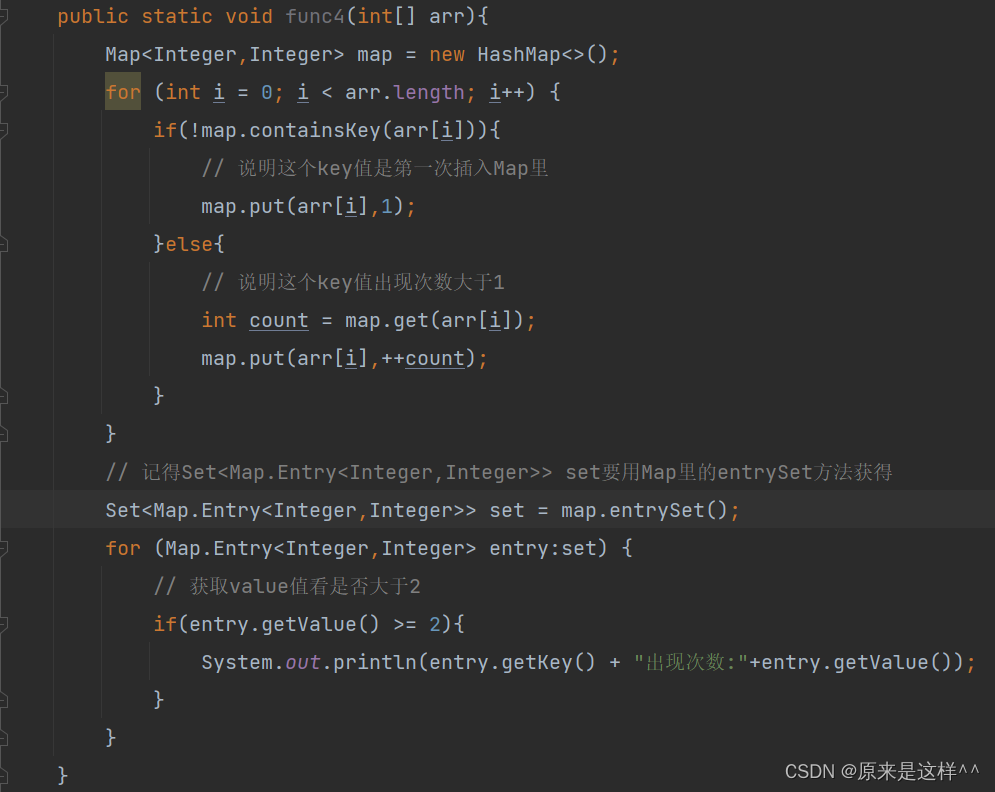
4.统计100W个(10个)数据重复数据>=2出现的次数?
Map和Set是用来专门查找的数据结构,查找效率非常高
我们以前也有用来查找的方法比如:
1.直接遍历查找,效率非常慢
2.二分查找,前提还得让数据有序
假如我们将全国人民的身份证信息存储在一个地方然后需要查找某个人的信息就非常麻烦,用直接遍历查找效率非常慢,用二分查找还得把12亿的数据排序一遍,并且它们还非常不适合删除操作
这时候我们就可以用Map或Set两数据结构
Map是key-value模型(对应了两个东西)
key-value模型的意思是 一个关键字对应一个值,
例如:hello在一片文章里出现了几次,hello就是key(关键字),helllo出现的次数就是value(对应的值,这里的值不一定是整数),这里对应了两个东西分别是hello,和hello出现次数
Set是纯key模型(只对应i一个东西)
key模型意思是只有关键字
例如:hello是否出现在某篇文章里
Map的使用
Map是一个接口类,不能实例化,只能实例化实现Map接口的类入TreeMap或HashMap
TreeMap底层是一棵搜索树(红黑树),HashMap底层是一个哈西表
Map的方法

Map的put()方法
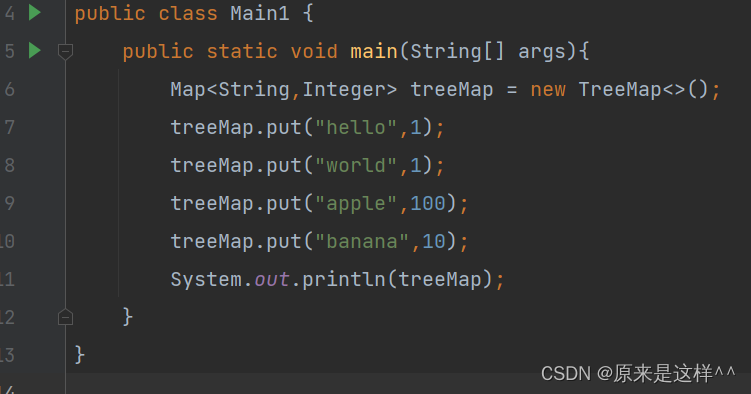

Map实现的是TreeMap,由于底层是一棵搜索树(红黑树)它们会这样放
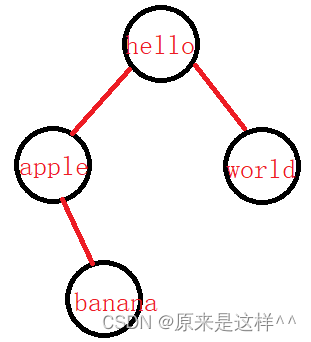

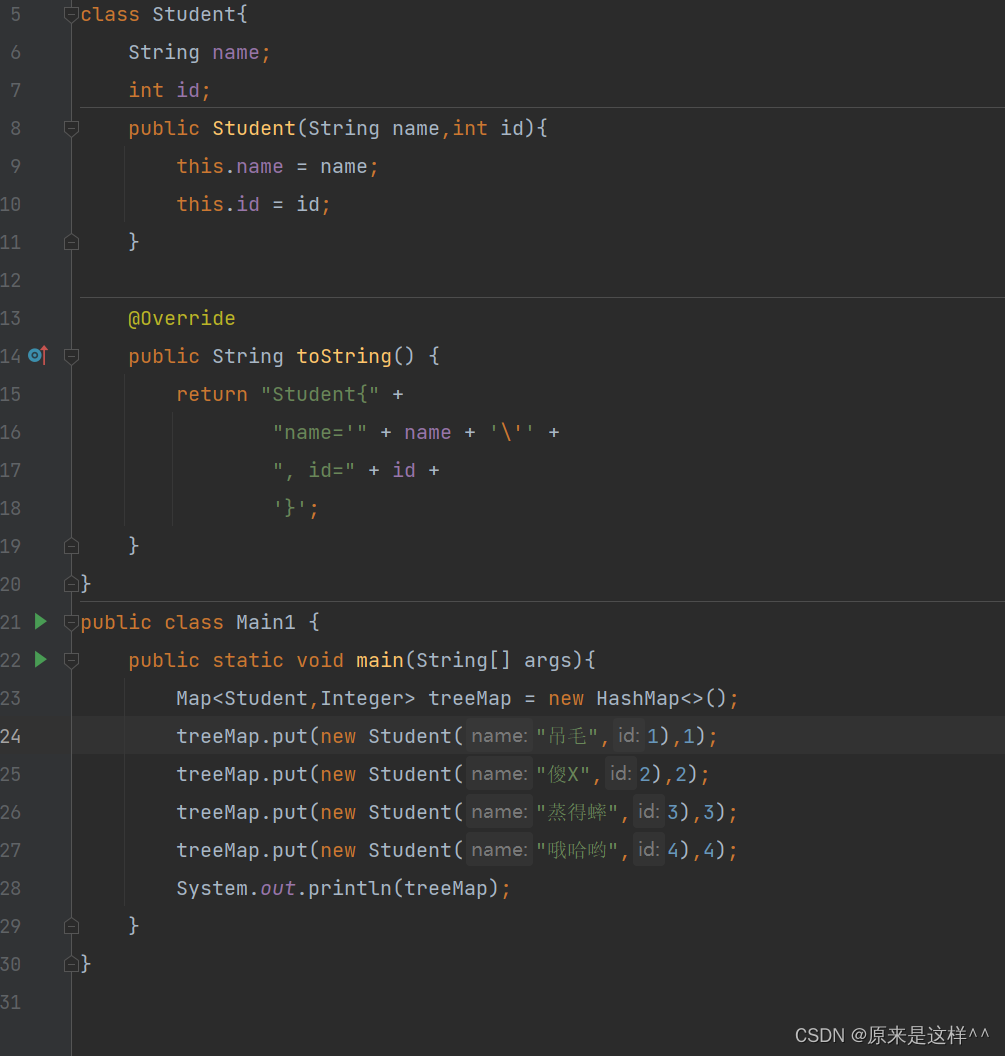

可以发现实现了TreeMap类的由于底层是一颗搜索树(红黑树)它重写了toString方法的同时还对key进行了排序,但要求key能够进行比较(可以实现Comparable接口)
实现了HashMap类由于底层是哈希表,它不要求key一定能够进行比较也并没有根据key排序的同时也没有重写toString()方法
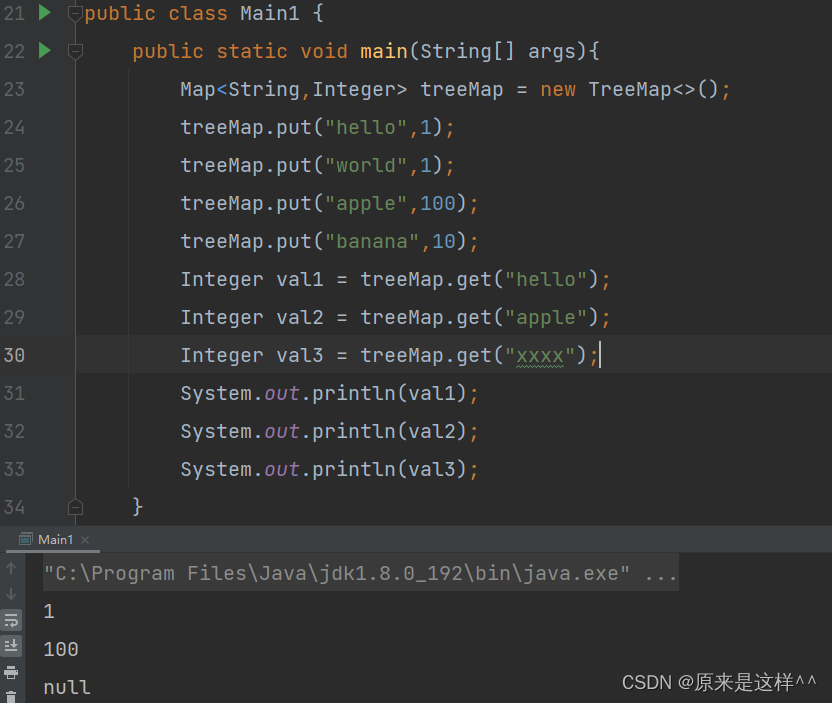
Map的get()方法
根据key名字获取到对应value,没有对应key就返回null
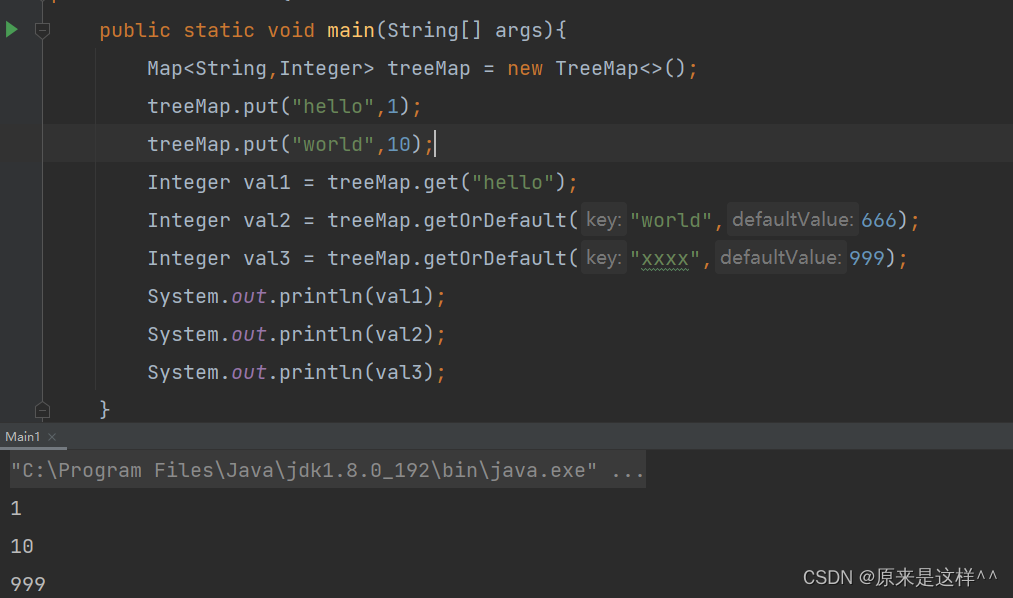
Map的getOrdefault()方法
如果key有返回对应的value值,如果没有就返回默认值
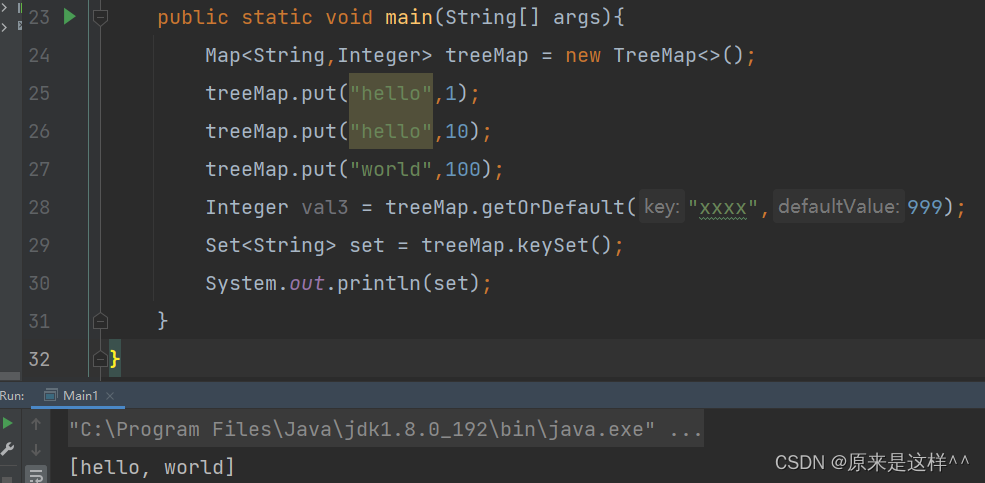
Map的keySet()方法
获取到Map里所有的key值放到Set里,并且还去重,返回类型是S服务器托管网et
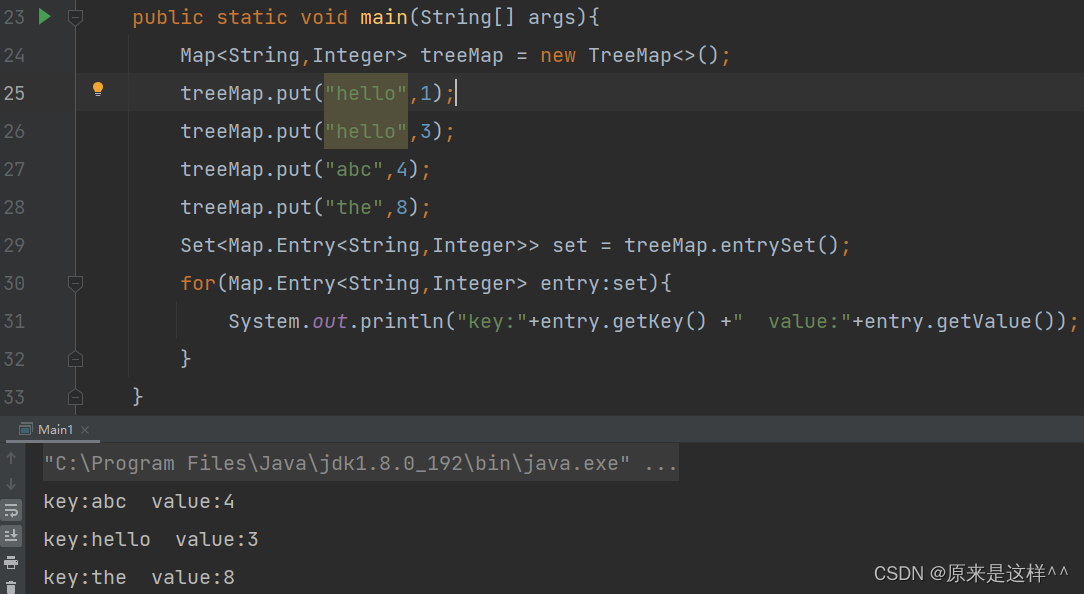
Map的entrySet()方法
返回类型是Set
Set
对应着Map里每条key-value数据,相当于
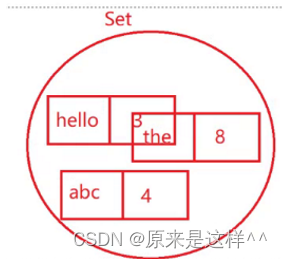
Map.Entry对应众多key-value数据里的一条

Entry是Map的内部接口类
Entry的方法

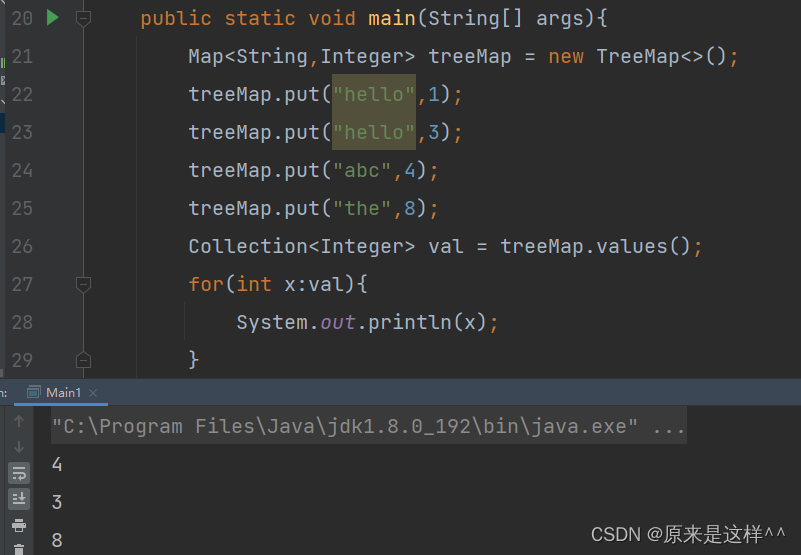
Map的values()方法,返回类型是Collection
返回Map所有的value值,可以有重复
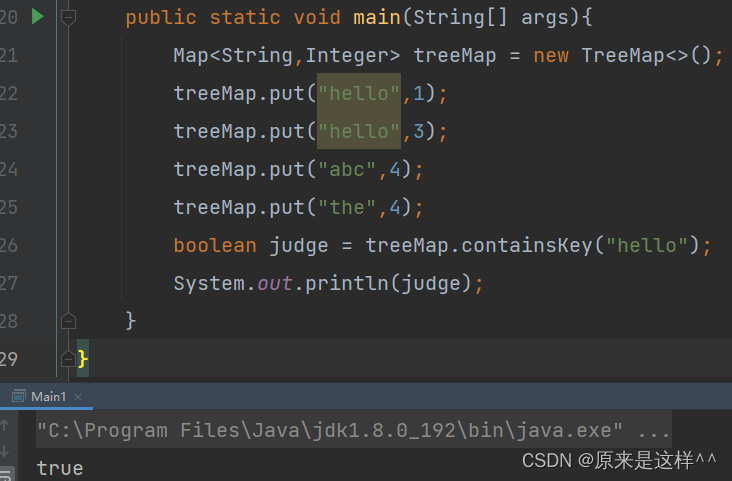
Map的containsKey()方法
判断Map里是否有对应的key值
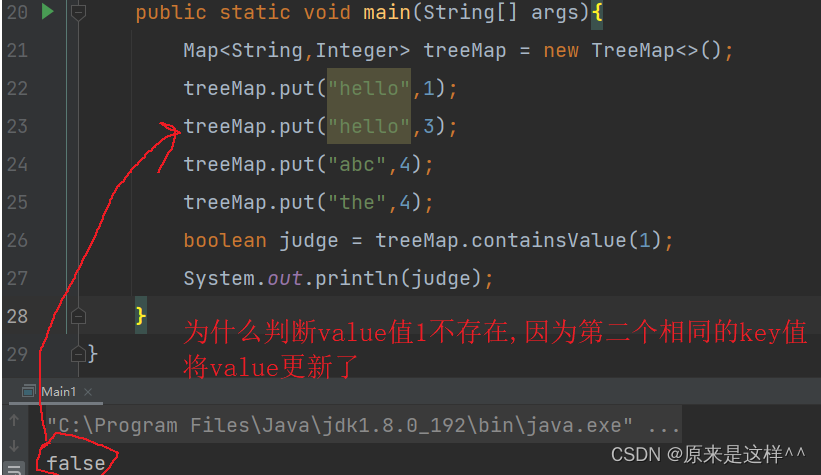
Map的containsValue()方法
判断Map里是否有对应的Value值
Set的使用
Set只存储Key并且不能重复
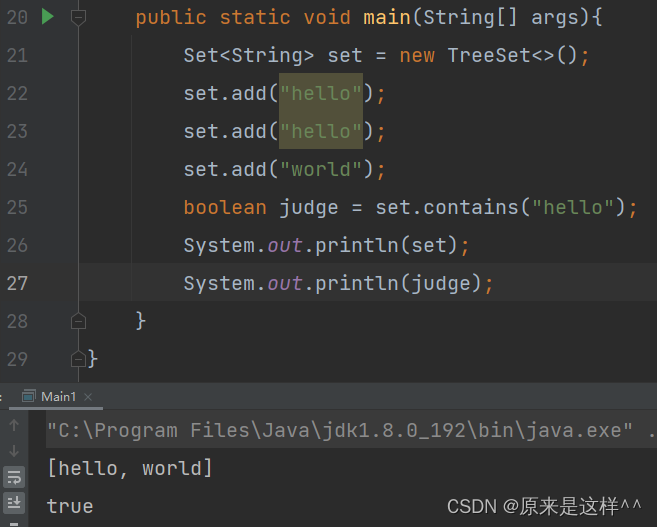
为什么Set存储的数据不能重复?
Set的底层是Map,它利用了Map中key不能重复的原则

Set的方法,
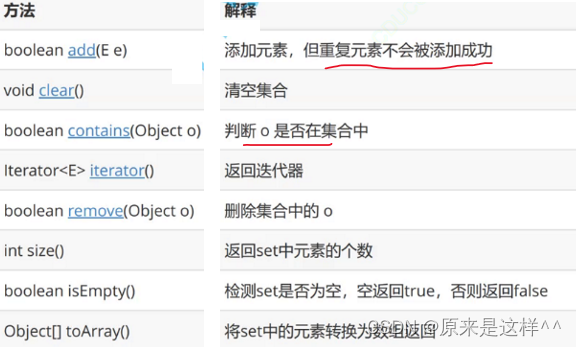
具体方法的使用我们就不展开了,写几道题吧
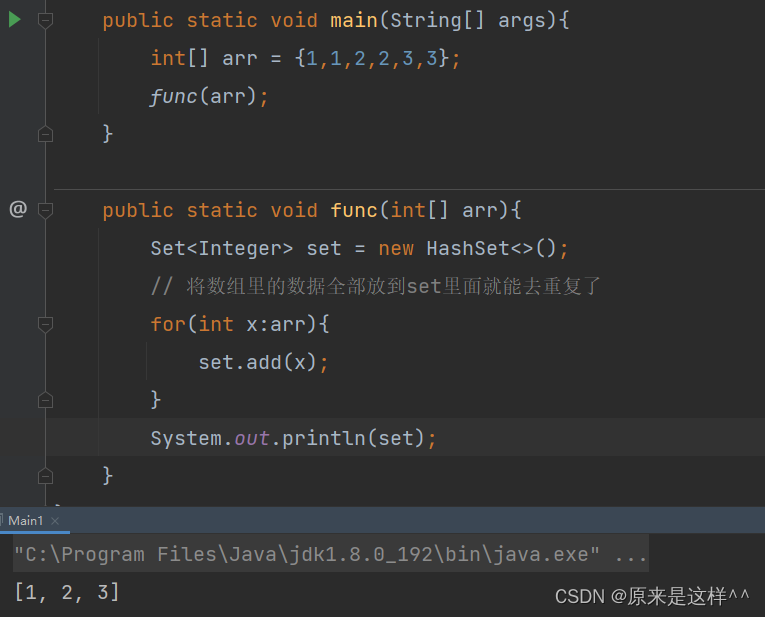
1.有100W个(10个)数据,并且数据有重复的,将所有重复的数据进行去重复
Set是个纯key模型且能够去重复用这个数据结构刚好
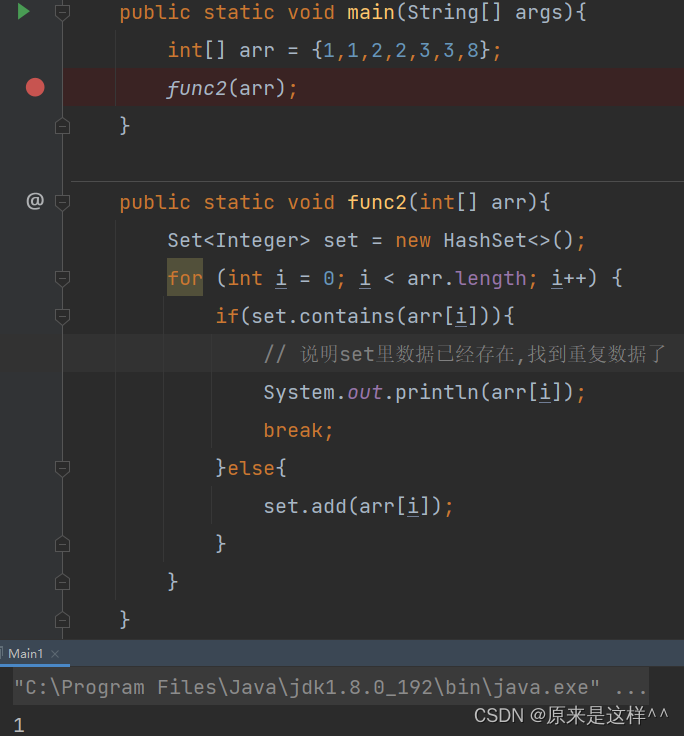
2.有100W个(10个)数据,并且数据有重复的,找到第一个重复的数据
3.统计10W个(几个)数据当中,每个数据出现的次数
这里出现了 每个数据 和 次数 两个不同的元素,用key-value模型,
例如hello在文章里出现了几次

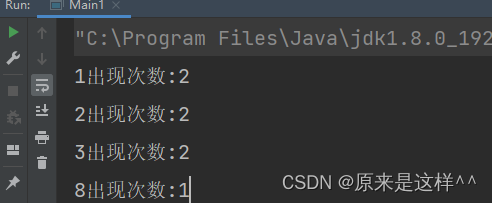
4.统计100W个(10个)数据重复数据>=2出现的次数?
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
