
1.概述
随着大数据技术的不断发展,处理海量数据的需求变得愈发迫切。MapReduce作为一种分布式计算模型,为处理大规模数据提供了有效的解决方案。在这篇博客中,我们将探讨如何使用MapReduce框架读取快照表(Snapshot Table)的数据。快照表是一种记录某一时刻系统状态的表格,通过MapReduce读取,可以有效地进行数据分析和处理。
2.内容
HBase的快照表提供了一种机制,允许用户在不中断正在进行的写操作的情况下,对表的状态进行快照,并在之后的时间点恢复到这个快照状态。快照表在以下方面发挥着关键的作用:
- 备份和还原: 允许用户创建表的快照,以应对数据误删除或损坏的情况。通过还原到先前的快照状态,可以方便地进行数据修复。
- 版本控制: 提供了一种历史版本的管理机制,使得用户可以在需要时回溯到先前的表状态。这对于数据历史记录和分析非常有用。
- 测试和开发: 在开发和测试环境中,快照表使得可以在不影响生产环境的情况下创建和还原测试数据。
2.1 创建快照表
HBase快照表的实现是建立在HBase的架构之上的,主要涉及以下几个关键步骤:
1.创建快照
用户可以通过HBase Shell或HBase API创建表的快照。创建快照时,HBase会记录当前表的状态,并生成一个标识符。
hbase> snapshot 'mytable', 'snapshot1'
2.还原快照
用户可以使用已创建的快照标识符来还原表的状态。在还原的过程中,HBase会回滚表的状态到快照的时间点。
hbase> disable 'mytable' hbase> restore_snapshot 'snapshot1' hbase> enable 'mytable'
3.查看和删除快照
用户可以查看系统中存在的快照列表,并在不需要的时候删除快照。
hbase> list_snapshots hbase> delete_snapshot 'snapshot1'
4.快照的存储
HBase会将快照存储在HDFS上,确保持久性和可靠性。这意味着快照不会受到HBase的单点故障的影响。
5.分布式一致性
HBase快照的实现考虑到了分布式环境下的一致性和原子性。在创建和还原快照的过程中,HBase确保所有Region Server都能够参与操作,以保证数据的一致性。
3.HBase Scan
HBase的Scan和Get操作在数据获取方式上存在显著的区别,前者是串行获取数据,而后者则采用并行方式。这种不同的处理方式可能让人感到有些出乎意料,让我们深入了解这其中的原因。
Scan操作在HBase中有四种模式:scan、snapScan、scanMR和snapshotscanMR。前两者采用串行方式,而后两者则运用MapReduce机制,其中SnapshotScanMR性能最为出众。
首先,我们需要理解什么是快照(snapshot)。快照是HBase数据表元数据的一个静态快照,注意,这里并不包括数据本身。在HBase中,数据的存储由HDFS管理,和关系型数据库类似,但不同之处在于一旦数据写入,就不再修改。更新和删除等操作并不是直接修改HFile,而是填充墓碑文件。因此,快照具有很高的价值,例如,可以快速创建一个HBase表的副本,仅拷贝表结构,重用原始表的HDFS数据。
上述提到的快照在Scan操作中也有一定的应用场景,尤其是在SnapshotScan和SnapshotScanMR模式中。需要注意的是,在MapReduce中,Scan模式不再是最开始提到的串行查询,而是采用并行查询机制,底层是通过MapReduce实现的,因此性能更高,尤其是在多个Regi服务器托管网on的查询场景下。
HBase Scan查询实现步骤如下:
- 业务通过HBase Client进行调用,首先检查缓存是否存在数据,如果有则直接返回数据。
- 如果缓存中没有数据,将向RegionServer发送请求,继续获取下一批记录。
- 服务器端接收到next请求后,通过查询BlockCache、HFile、Memstore的流程逐行返回数据。

这种API每次返回少量条(比如200条)的调用模式旨在减轻网络资源和HBase客户端端内存的压力。因此,从实现上来看,scanAPI更适合处理少量数据的场景。
对于处理海量数据的查询,我们需要考虑使用上文提到的MapReduce(MR)框架。MR框架分为两种主要类型:TableScanMR(对应的处理类:TableMapReduceUtil.initTableMapperJob)和SnapshotScanMR(对应处理类:TableMapReduceUtil.initSnapshotMapperJob)。下面的两张图展示了它们在架构上的差异:
- TableScanMR: 该类型适用于对HBase表进行大规模的扫描和查询。通过TableMapReduceUtil.initTableMapperJob初始化Mapper任务,可以在整个表上并行处理数据。
- SnapshotScanMR: 与TableScanMR不同,SnapshotScanMR主要用于对HBase快照表的处理。通过TableMapReduceUtil.initSnapshotMapperJob初始化Mapper任务,能够在HBase快照上并行执行查询操作。
这两种MR框架的选择取决于具体的业务需求和数据规模。在处理海量数据时,MR框架的分布式计算和并行处理能力能够充分发挥,提高处理效率。
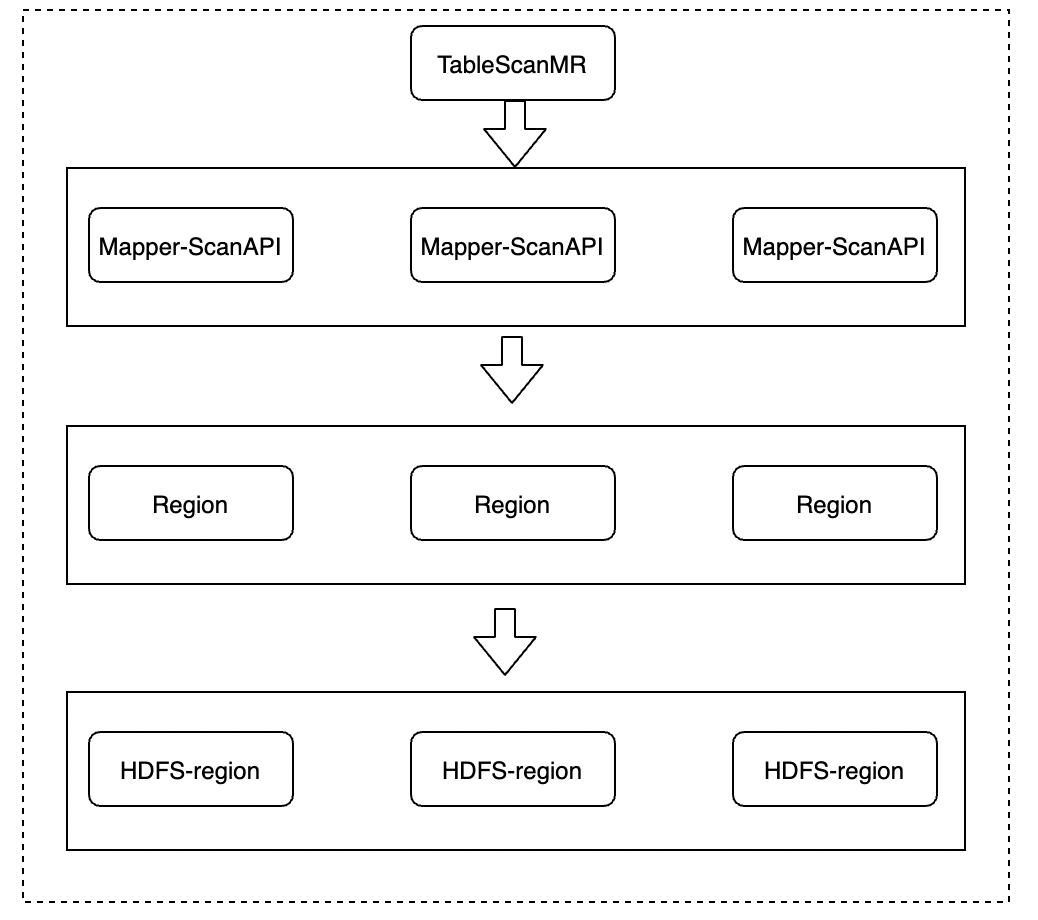
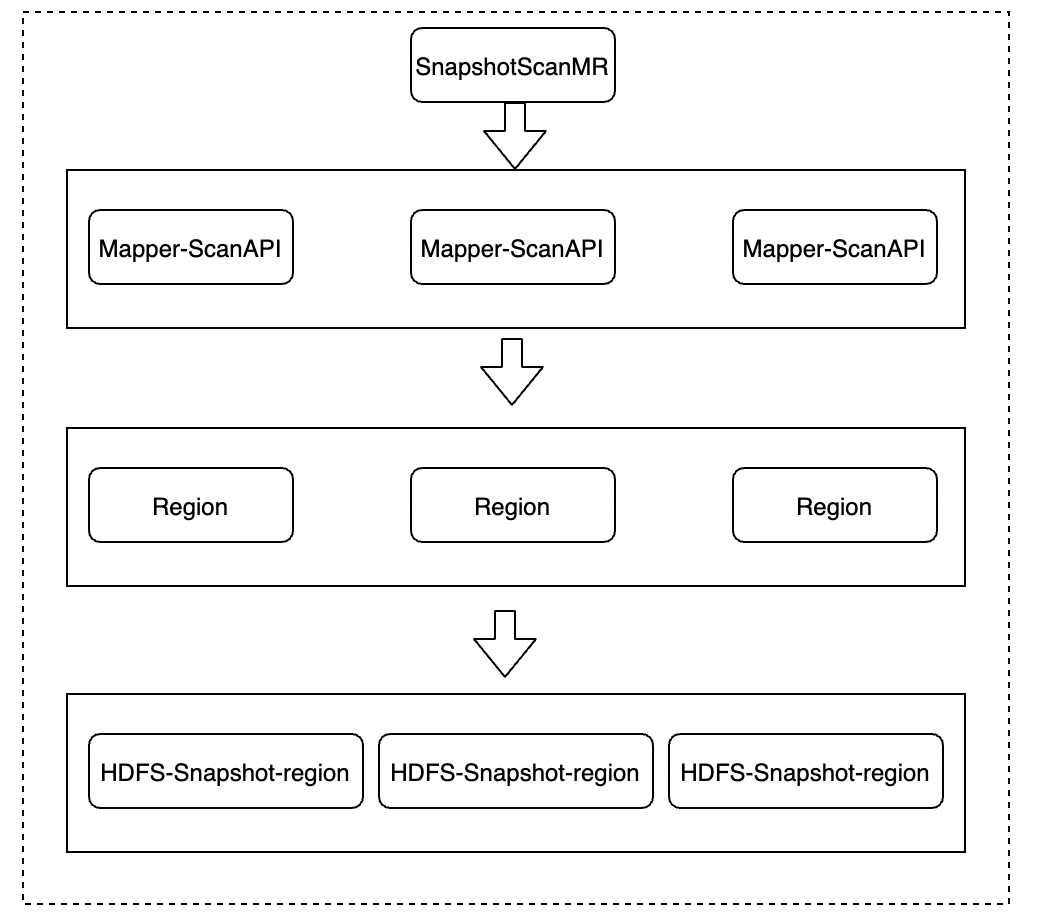
可以观察到,两种模式都采用了在客户端通过多线程方式进行并行处理的方法。然而,SnapshotScanMR与TableScanMR相比,不再直接与Region Server进行交互,而是直接在客户端和HDFS之间进行交互。这样的设计有一些优势,例如减轻了Region Server的负担。但值得注意的是,在使用SnapshotScanMR之前,需要在客户端和Region Server之间进行一次交互,以获取snapshot的信息,即HBase的元数据信息,包括表结构和HDFS存储信息。这使得可以跳过Region Server,直接与HDFS地址进行交互。
然而,snapshot也有一些缺点。首先,实时性较差,可能最近的一些数据修改并未在snapshot中体现。这可能导致读取到一些脏数据,即已被删除或更新的数据仍然存在,只是在墓碑记录中。当然,如果经过合并(merge)后,这些脏数据会被清理。其次,由于snapshot是一种静态的快照,可能无法读取到一些最新的数据。
总体而言,SnapshotScanMR的设计优势在于减轻了Region Server的负担,但需要在性能和实时性之间做出权衡。在选择使用SnapshotScanMR时,必须充分了解数据的更新和删除情况,以确保得到准确的查询结果。
3.代码实现
在MapReduce中扫描HBase快照表的代码实现主要涉及Mapper的编写,以及MapReduce作业的配置。以下是一个简单的示例,演示了如何使用MapReduce扫描HBase快照表:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HConstants; import org.apache.hadoop.hbase.KeyValue; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableSnapshotInputFormat; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; public class HBaseSnapshotScan服务器托管网MR extends Configured implements Tool { public static class HBaseSnapshotMapper extends Mapper { @Override protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { // 处理每一行的数据,这里简单地将每行数据输出到MapReduce的输出 StringBuilder output = new StringBuilder(); for (Cell cell : value.rawCells()) { output.append(Bytes.toString(CellUtil.cloneValue(cell))).append(","); } context.write(NullWritable.get(), new Text(output.toString())); } } @Override public int run(String[] args) throws Exception { Configuration conf = getConf(); // HBase配置 Configuration hbaseConf = HBaseConfiguration.create(conf); hbaseConf.set(TableInputFormat.SCAN, TableMapReduceUtil.convertScanToString(new Scan())); // MapReduce作业配置 Job job = Job.getInstance(conf, "HBaseSnapshotScanMR"); job.setJarByClass(getClass()); // 设置HBase快照输入格式 TableMapReduceUtil.initTableSnapshotInput(job, args[0], new Path(args[1]), HConstants.HBASE_DIR); // Mapper和Reducer配置 job.setMapperClass(HBaseSnapshotMapper.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); // 提交作业 return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run(new HBaseSnapshotScanMR(), args); System.exit(exitCode); } }
在这个例子中:
- HBaseSnapshotMapper 类是 Mapper 的具体实现,负责处理每一行的数据,这里简单地将每行数据输出为文本。
- HBaseSnapshotScanMR 类实现了 Tool 接口,用于配置和运行 MapReduce 作业。
- 在 run 方法中,配置了 HBase 快照的输入格式,设置了 Mapper 类、输出键值类型等信息。
- main 方法调用 ToolRunner.run 运行 MapReduce 作业。
运行这个作业时,需要提供两个参数:HBase 表的名称和快照的名称。例如:
hadoop jar HBaseSnapshotScanMR.jar HBaseSnapshotScanMR tableName snapshotName outputDir
4.总结
1.注意事项
- 确保HBase中的快照表存在,且其中包含所需的数据。
- 对Mapper和Reducer进行适当的配置,以满足具体的业务需求。
- 在处理大规模数据时,调整Hadoop和MapReduce的配置参数以提高性能。
2.适用场景
- 扫描HBase快照表适用于需要处理历史数据、数据版本控制以及数据备份与还原的场景。
- 使用MapReduce进行处理可以充分发挥Hadoop分布式计算的优势,实现并行化和分布式处理。
总体而言,MapReduce扫描HBase快照表是一种强大的数据处理方法,能够有效处理大规模数据集,提供了分布式计算的优势,同时充分利用了HBase的快照功能来处理历史数据。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
译者注:在微服务架构设计,构建API和服务间通信技术选型时,对 REST 和 gRPC 的理解和应用还存在知识盲区,近期看到国外的这篇文章:A detailed comparison of REST and gRPC,将二者进行了详细对比。周末有时间翻译过来,…
