
全文链接:http://tecdat.cn/?p=2655
最近我们被客户要求撰写关于偏最小二乘回归的研究报告,包括一些图形和统计输出。
此示例显示如何在matlab中应用偏最小二乘回归(PLSR)和主成分回归(PCR),并讨论这两种方法的有效性 ( 点击文末“阅读原文”获取完整代码数据******** ) 。
当存在大量预测变量时,PLSR和PCR都是对因变量建模的方法,并且这些预测变量高度相关或甚至共线性。两种方法都将新的预测变量(称为成分)构建为原始预测变量的线性组合,但它们以不同的方式构造这些成分。PCR创建成分来解释预测变量中观察到的变异性,而根本不考虑因变量。另一方面,PLSR确实将因变量考虑在内,因此通常会导致模型能够使用更少的成分来适应因变量。
加载数据
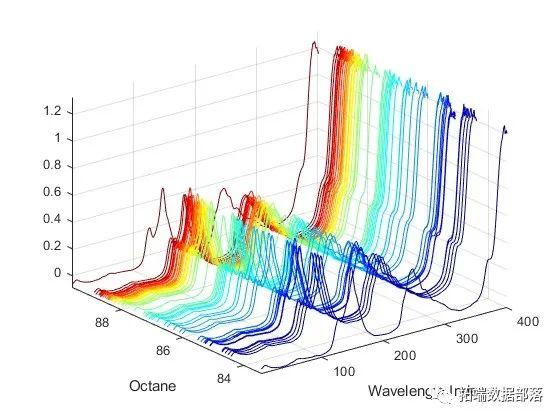
加载包括401个波长的60个汽油样品的光谱强度及其辛烷值的数据集。
set(gcf,'DefaultAxesColorOrder',jet(60));xlabel('Wavelt Inde'); ylabel('Oct'); axis('tiht');grid on
点击标题查阅往期内容

[](http://mp.weixin.qq.com/s?__biz=MzU4NTA1MDk4MA==&mid=2247519328&idx=5&sn=28741e8f7bb6590672b2fb9bae649bb5&chksm=fd92b26bcae53b7d5eddf40bf99e90191c033a32ff59aed3b31b5d0c3919a6e5e775ad706df1&scene=21#wechat_redirect)Matlab中的偏最小二乘法(PLS)回归模型,离群点检测和变量选择

左右滑动查看更多

01
02
03
04
使用两个拟合数据
使PLSR模型拟合10个PLS成分和一个因变量。
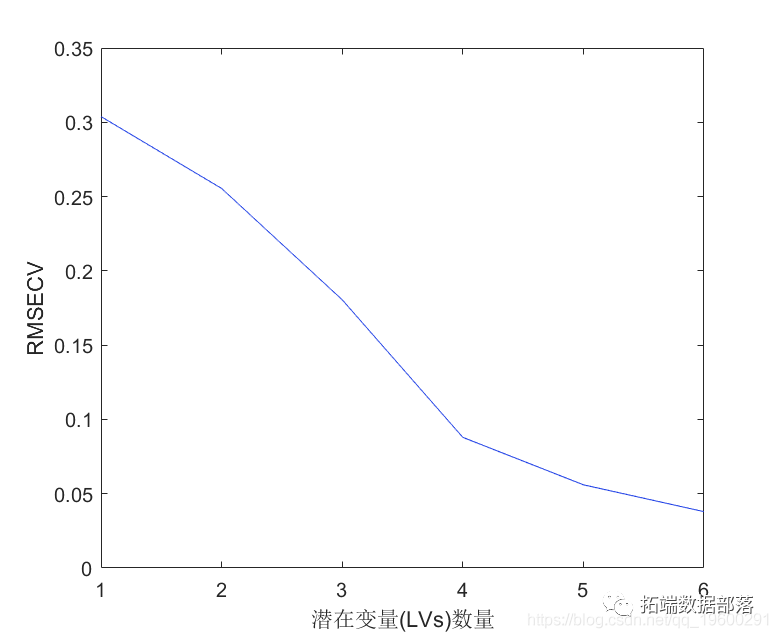
为了充分拟合数据,可能需要十个成分,但可以使用此拟合的诊断来选择具有更少成分的更简单模型。例如,选择成分数量的一种快速方法是将因变量中解释的方差百分比绘制为成分数量的函数。
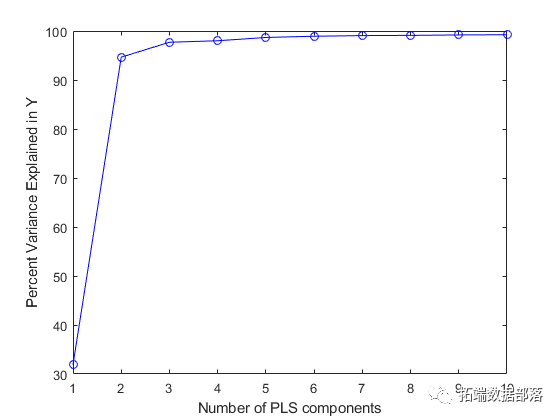
在实践中,在选择成分数量时可能需要更加谨慎。例如,交叉验证是一种广泛使用的方法,稍后将在本示例中进行说明。目前,上图显示具有两个成分的PLSR解释了观察到的大部分方差y。计算双组分模型的拟合因变量。
接下来,拟合具有两个主要成分的PCR模型。第一步是X使用该pca函数执行主成分分析,并保留两个主成分。然后,PCR只是这两个成分的因变量的线性回归。当变量具有非常不同的可变性时,通常首先通过其标准偏差来规范每个变量。
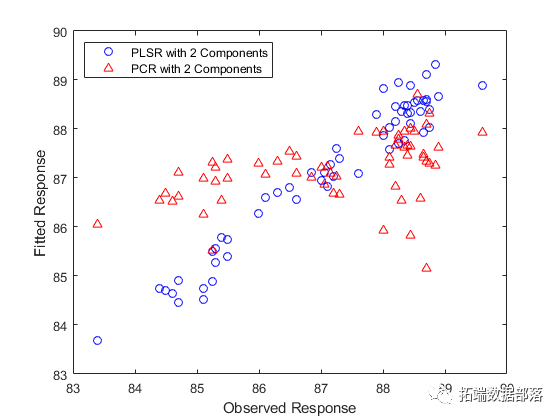
从某种意义上说,上图中的比较并不合理 – 通过观察双组分PLSR模型预测因变量的程度来选择成分数(两个),并且没有说明为什么PCR模型应该限制相同数量的成分。然而,使用相同数量的成分,PLSR做得更好。实际上,观察上图中拟合值的水平分布,使用两个分量的PCR几乎不比使用常数模型好。回归的r方值证实了这一点。
比较两种模型的预测能力的另一种方法是在两种情况下将因变量绘制成两个预测变量。
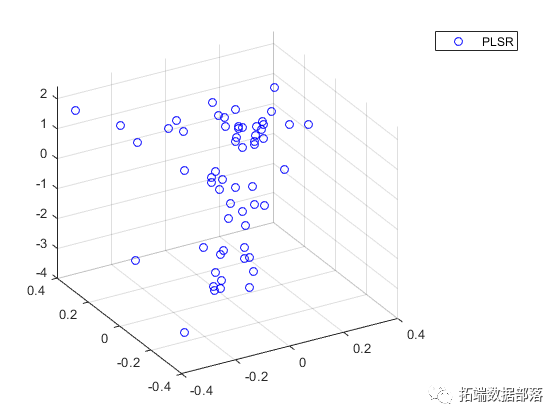
如果不能以交互方式旋转图形,有点难以看到,但上面的PLSR图显示了紧密分散在平面上的点。另一方面,下面的PCR图显示点几乎没有线性关系。
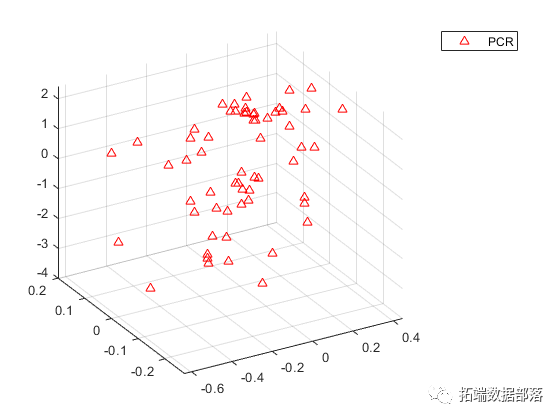
请注意,尽管两个PLS成分是观察到的更好的预测因子,但下图显示它们解释的方差比例比PCR中使用的前两个主成分少。
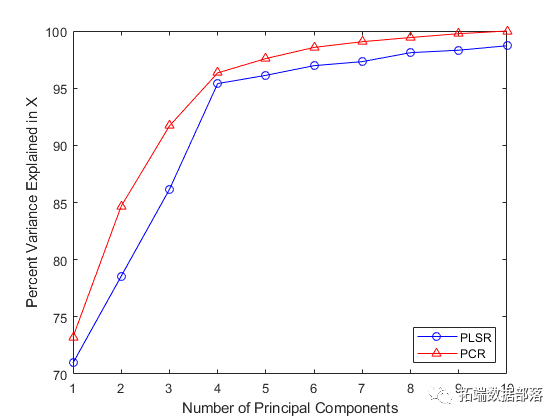
PCR曲线一致性较高的事实表明,为什么使用两种成分的PCR相对于PLSR在拟合时表现很差。PCR构建成分以便最好地解释X,因此,前两个成分忽略了数据拟合中观察到的重要信息y。
拟合更多成分
随着在PCR中添加更多成分,它必然会更好地拟合原始数据y,这仅仅是因为在某些时候,大多数重要的预测信息X将存在于主要成分中。例如,使用10个成分时,两种方法的残差远小于两个成分的残差。
交叉验证
在预测未来变量的观察结果时,选择成分数量以减少预期误差通常很有用。简单地使用大量成分将很好地拟合当前观察到的数据,但这是一种导致过度拟合的策略。过于拟合当前数据会导致模型不能很好地推广到其他数据,并对预期误差给出过度乐观的估计。
交叉验证是一种更加统计上合理的方法,用于选择PLSR或PCR中的成分数量。它通过不重复使用相同的数据来拟合模型和估计预测误差来避免过度拟合数据。因此,预测误差的估计不会乐观地向下偏差。
pls可以选择通过交叉验证来估计均方预测误差(MSEP),在这种情况下使用10倍CV。
plsreg(X,y,10,'CV',10);
对于PCR,crossval结合用于计算PCR的平方误差之和,可以再次使用10倍交叉验证来估计MSEP。
sum(crossval(@ pcrsse,X,y,'KFold',10),1)/ n;
PLSR的MSEP曲线表明两个或三个成分好。另一方面,PCR需要四个成分才能获得相同的预测精度。
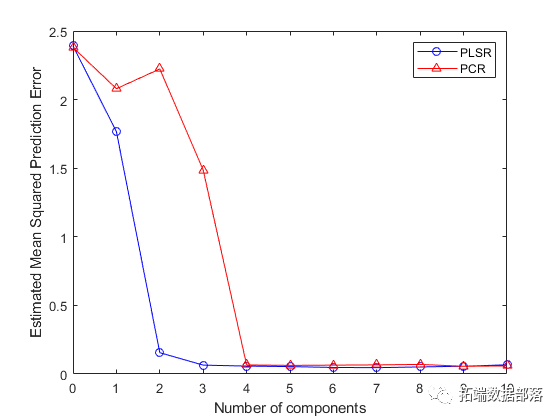
事实上,PCR中的第二个成分会增加模型的预测误差,这表明该成分中包含的预测变量的组合与其没有很强的相关性y。再次,这是因为PCR构建成分来解释X,而不是y。
模型简约
因此,如果PCR需要四个成分来获得与具有三个成分的PLSR相同的预测精度,那么PLSR模型是否更加简约?这取决于您考虑的模型的哪个方面。
PLS权重是定义PLS分量的原始变量的线性组合,即,它们描述了PLSR中的每个分量依赖于原始变量的权重。
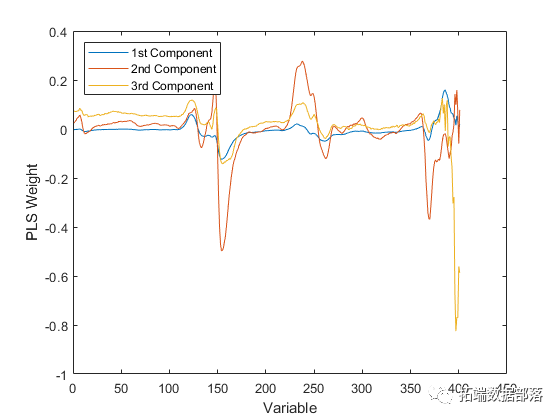
类似地,PCA载荷描述了PCR中每个成分依赖于原始变量的强度。
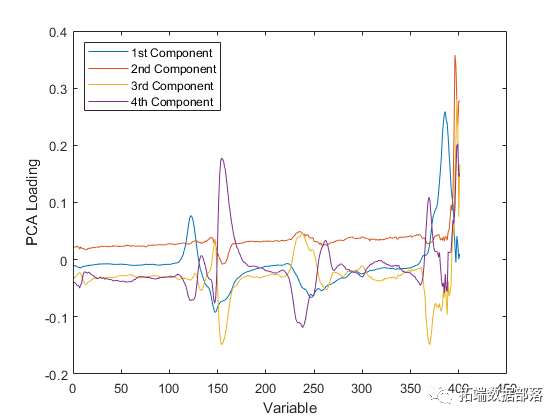
对于PLSR或PCR,可以通过检查每个成分最重要的变量来为每个成分提供有意义的解释。例如,利用这些光谱数据,可以根据汽油中存在的化合物解释强度峰值,然后观察特定成分的权重挑选出少量这些化合物。从这个角度来看,更少的成分更易于解释,并且由于PLSR通常需要更少的成分来充分预测因变量,因此会导致更简约的模型。
另一方面,PLSR和PCR都导致每个原始预测变量的一个回归系数加上截距。从这个意义上讲,两者都不是更简约,因为无论使用多少成分,两种模型都依赖于所有预测变量。更具体地,对于这些数据,两个模型都需要401个光谱强度值以进行预测。
然而,最终目标可能是将原始变量集减少到仍然能够准确预测因变量的较小子集。例如,可以使用PLS权重或PCA载荷来仅选择对每个成分贡献最大的那些变量。如前所示,来自PCR模型拟合的一些成分可主要用于描述预测变量的变化,并且可包括与因变量不强相关的变量的权重。因此,PCR会导致保留预测不必要的变量。
对于本例中使用的数据,PLSR和PCR所需的成分数量之间的差异不是很大,PLS权重和PCA载荷选择了相同的变量。其他数据可能并非如此。
有问题欢迎下方留言!

点击文末 “阅读原文”
获取全文完整资料。
本文选自《偏最小二乘回归(PLSR)和主成分回归(PCR)分析光谱数据》。
点击标题查阅往期内容
R语言实现偏最小二乘回归法 partial least squares (PLS)回归
Matlab中的偏最小二乘法(PLS)回归模型,离群点检测和变量选择
R语言实现偏最小二乘回归法 partial least squares (PLS)回归
R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归R语言Lasso回归模型变量选择和糖尿病发展预测模型
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
Python贝叶斯回归分析住房负担能力数据集
Python用PyMC3实现贝叶斯线性回归模型
R语言区间数据回归分析
R语言用LOESS(局部加权回归)季节趋势分解(STL)进行时间序列异常检测
PYTHON用时变马尔可夫区制转换(MRS)自回归模型分析经济时间序列
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
基于R语言实现LASSO回归分析
Python用PyMC3实现贝叶斯线性回归模型
使用R语言进行多项式回归、非线性回归模型曲线拟合
R语言中的偏最小二乘回归PLS-DAR语言生态学建模:增强回归树(BRT)预测短鳍鳗生存分布和影响因素
R语言实现偏最小二乘回归法 partial least squares (PLS)回归
Matlab中的偏最小二乘法(PLS)回归模型,离群点检测和变量选择
偏最小二乘回归(PLSR)和主成分回归(PCR)
R语言如何找到患者数据中具有差异的指标?(PLS—DA分析) R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归R语言Lasso回归模型变量选择和糖尿病发展预测模型
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
Python贝叶斯回归分析住房负担能力数据集
Python用PyMC3实现贝叶斯线性回归模型
R语言区间数据回归分析
R语言用LOESS(局部加权回归)季节趋势分解(STL)进行时间序列异常检测
PYTHON用时变马尔可夫区制转换(MRS)自回归模型分析经济时间序列
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
基于R语言实现LASSO回归分析
Python用PyMC3实现贝叶斯线性回归模型
使用R语言进行多项式回归、非线性回归模型曲线拟合
R语言中的偏最小二乘回归PLS-DA
R语言生态学建模:增强回归树(BRT)预测短鳍鳗生存分布和影响因素
R语言生态学建模:增强回归树(BRT)预测短鳍鳗生存分布和影响因素
R语言实现偏最小二乘回归法 partial least squares (PLS)回归
Matlab中的偏最小二乘法(PLS)回归模型,离群点检测和变量选择
偏最小二乘回归(PLSR)和主成分回归(PCR)
R语言如何找到患者数据中具有差异的指标?(PLS—DA分析)
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 零拷贝并非万能解决方案:重新定义数据传输的效率极限
PageCache有什么作用? 在我们前面讲解零拷贝的内容时,我们了解到一个重要的概念,即内核缓冲区。那么,你可能会好奇内核缓冲区到底是什么?这个专有名词就是PageCache,也被称为磁盘高速缓存。也可以看下windows下的缓存区:如图所示: 零拷贝进一步…
