
基础知识
是什么
概念
分布式文件存储数据库,提供高可用、可扩展、易部署的数据存储解决方案。
结构

BSON存储类型
类似JSON的一种二进制存储格式。相比于JSON,提供更丰富的类型支持。
优点是灵活,缺点是空间利用率不佳。
| 类型 | 说明 | 解释 | 举例 |
|---|---|---|---|
| String | 字符串 | UTF-8编码为合法字符串。 | {name:“李四”} |
| Integer | 整型 | 根据服务器可分为32、64位。 | {age:1} |
| Boolean | 布尔值 | {flag:true} | |
| Double | 双精度浮点值 | {number:3.14} | |
| ObjectId | 对象ID | 用于创建文档的ID | {_id:new Object()} |
| Array | 数组 | {top:[85,63,42]} | |
| Timestamp | 时间戳 | { ts: new Timestamp() } | |
| Object | 内嵌文档 | {obj:{age:18}} | |
| Null | 空值 | 空值或未定义的对象 | {key:null} |
| Date或者 ISODate | 格林尼治 时间 | 日期时间,用Unix日期格 式来存储当前日 期或时 间。 | {birth:new Date()} |
| Code | 代码 | 可包含js代码 | {x:function(){}} |
其它特殊类型File:
- 二进制转码小于16M,可用 Base64 存储。
- 二进制转码大于16M,可用 GridFS 存储。
什么时候使用MongoDB
应用特征
| 应用特征 |
|---|
| 不需要事务 |
| 不需要复杂join |
| 新应用,需求变动,数据模型无法确定,需要快速迭代开发 |
| 应用需要2000以上QPS |
| 应用需要TB、PB级别的数据存储 |
| 应用发展迅速,需要快速水平扩展 |
| 要求数据不丢失 |
| 应用需要99.999%高可用 |
| 应用需要大量地理位置查询、文本查询 |
适用场景
- 网站数据:适合实时插入、更新、查询,并要求具备复制、高度伸缩性。
- 缓存:高性能,可作为基础信息设置的缓存层。
- 存储大尺寸、低价值的数据。
- 高伸缩场景。合适组成几十上百的数据库集群。内置高可用解决方案以及MapReduce引擎。
- 用于对象、JSON数据的存储。BSON格式合适文档化格式的存储和查询。
行业应用场景
- 游戏场景。用户信息、装备信息、积分等,内嵌文档存储,方便查询、更新。
- 物流场景。存储订单信息,通过内嵌文档形式,一下子就可以把订单的所有变更信息查询出来。
- 社交场景。存储用户信息、朋友圈,查找附近的人等。
- 物联网场景。存储设备的接入信息,以及设备上报的日志。
- 直播。用户信息、礼物信息。
GUI工具
MongoDB Compass Community
- MongoDB提供GUI MongoDB工具
- 借助内置模式可视化,用户可以分析文档并显示丰富的结构。为了监控服务器的负载,它提供了数据库操作的实时统计信息
- Compass有两个版本:Enterprise(付费),Community(免费)
- 适用于Linux,Mac或Windows
MongoBooster
- 是MongoDB CLI界面中非常流行的GUI工具。它正式名称为MongoBooster
- NoSQLBooster是一个跨平台,它带有一堆MongoDB 工具来管理数据库和监控服务器
- 这个Mongodb工具包括服务器监控工具,Visual Explain Plan,查询构建器,SQL查询,
- ES2017语法支持等等…
- 适用于Linux,Mac或Windows
Navicat
基础命令
连接
mongo --username root --password --host localhost --port 27017
数据库
当前数据库
db
所有数据库
show dbs
show databases
切换数据库
use
创建数据库
use
删除当前数据库
db.dropDatabase()
集合操作
所有集合(表)
show collections
show tables
查看集合命令帮助
db..help()
删除集合
db.. drop()
插入操作
单条插入
db.collection>.insertOne(
{xm:"张三",age:23}
)
db.myt.insertOne(
{xm:"张三",age:23}
)
多条插入
db.collection>.insertMany([
{xxx},
{xxx}
])
db.myt.insertMany([
{xm:"李四",age:24},
{xm:"王五",age:25},
{xm:"赵六",age:26},
{xm:"李四",age:34},
{xm:"王五",age:35},
{xm:"赵六",age:36}
])
查询操作
基础查询
| 操作 | 格式 | 对比 |
|---|---|---|
| = | {key:value} | where a = 1 |
| > | {key:{$gt:value}} | where a > 1 |
| {key:{$lt:value}} | where a | |
| >= | {key:{$gte:value}} | where a >= 1 |
| {key:{$lte:value}} | where a | |
| != | {key:{$ne:value}} | where a != 1 |
等值查询
db..find({:})
db.myt.find({xm:"张三"})
IN查询
db..find({:{:}})
db.myt.find({xm:{$in:["张三","李四"]}})
AND查询
db..find({:,:})
db.myt.find({xm:"李四", age:34})
db.myt.find({xm:"李四", age:{$gt:30}})
范围查询
db.myt.find({xm:"李四", age:{$gt:30}})
OR查询
db..find({$or:[{:},{:}]})
db.myt.find( {$or: [ {xm: "李四"}, {age: {$lt: 26}} ] } )
AND+OR查询
db..find({:, $or:[{:},{:}]})
类似于:select * from t where a = 1 and ( b = 1 or b = 2)
db.myt.find( { xm:"李四", $or:[{age:{$lt: 25}},{age:35}] } )
!=查询
db..find({:{$ne:}})
db.myt.find({xm:{$ne:"李四"}})
分页查询
db..find().sort({:}).limit(单页数)
升序:db.myt.find().sort({age:1}).limit(3)
降序:db.myt.find().sort({age:-1}).limit(3)
数组查询
等值查询
db.myt.insertOne( {xm:"孙八",age:28,size:{h:165,w:54},tags:["家财万贯","不惑之年"]} )
db.myt.find({tags:["家财万贯","不惑之年"]})
包含查询
db.myt.find({tags:{$all:["家财万贯"]}})
在指定下标下进行查询
db.myt.find( {"tags.2":{$lt:65}} )
db.myt.insertMany([
{xm:"李四",age:43, size:{h:165,w:54}, tags:["不惑之年","家财万贯", 78]},
{xm:"王五",age:61, size:{h:167,w:56}, tags:["花甲","家财万贯", 65]},
{xm:"赵六",age:54, size:{h:174,w:64}, tags:["知天命", 59]},
])
数组长度等于n的文档
db.myt.find( {tags:{$size:3}} )
查询null或者丢失的字段
db.myt.find( {tags: null} )
删除操作
删除所有
db.myt.deleteMany({})
按条件删除
db..deleteMany( { : { : }, ... } )
db.my2.deleteMany( {xm:"王五"})
只删除一个符合条件的
db..deleteOne( { : } )
db.my2.deleteOne( {xm:"李四"} )
更新操作
更新格式
db.集合名.update(
query>,
update>,
{
upsert: boolean>,
multi: boolean>,
writeConcern: document>
}
)
-- 更新一个
updateOne()
-- 更新所有符合条件的
updateMany()
-- 文档替换。多个匹配结果也只替换一个。
replaceOne()
- query:查询条件
-
update:set操作,包括:
- $set:设置字段值。
- $unset :删除指定字段。
- $inc :增加指定数值。
- upsert(可选):默认false。不存在更新的记录时是否新增。
- multi (可选):默认false。只更新找到的第一条记录。
-
writeConcern (可选):指定写操作的回执行为。如 写操作是否需要确认。包括
{ w: , j: , wtimeout: }字段。- w :默认1。
- n:指定写操作传播到的成员数量,即比如 写操作 要求得到n个MongoDB实例或副本集的主要成员的确认。
- 0:不要求确认写操作。
- ” majority”:要求写操作得到大多数成员( members[n].votes 值大于0的成员 )的确认。
- j:确认写操作是否写入硬盘日志。确认的数量由
w值来指定。 - wtimeout :指定
write concern的时间限制,w > 1时生效。- 超过指定时间之后,写操作返回error,不管最后是否执行成功;超时之前的成功操作的数据也不会撤销。
- 未指定 或值为 0 时不会限制时间,写操作将无限制等待。
- w :默认1。
符号对照表
| 字段运算符 | 说明 |
|---|---|
| $currentDate | 将指定字段的值设置为当前日期 |
| $inc | 增加指定数值 |
| $min | 字段值小于指定值才更新 |
| $max | 字段值大于指定值才更新 |
| $mul | 字段值与指定值相乘 |
| $rename | 重命名字段 |
| $set | 设置字段值 |
| $setOnInsert | 如果更新操作导致插入文档,则设置指定字段的值。单纯的修改无影响。 |
| $unset | 删除指定字段 |
| 数值运算符 | 说明 |
| $ | 充当占位符。更新与查询条件匹配的第一个元素。 |
| $[] | 充当占位符。更新数组中与查询条件匹配的文档中的所有元素 |
| $addToSet | 只有元素不在数组中时才添加到数组。 |
| $pop | 删除数组第一或最后一个元素 |
| $pull | 删除符合匹配条件的所有元素 |
| $push | 添加元素到数组 |
| $pullAll | 删除数组中所有匹配的元素 |
| 修饰符 | 说明 |
| $each | 遍历 |
| $position | 指定下标 |
| $slice | |
| $sort |
注意点
- 写操作在单一文档上是原子性。
- 设定
_id之后不要更新。
更新案例
db.my2.update(
{xm:"李四"},
{
$set:{age:25},
$currentDate:{lastModified:true}
}
)
-- 注:当前日期写入到lastModified字段,字段不存在则创建
db.my2.update(
{xm:"李四"},
{
$set:{age:25},
$currentDate:{lastModified:true}
},
{ multi: true }
)
文档替换
db.my2.replaceOne(
{xm:"王五"},
{xm:"王五", age:34,size:{h:168,w:62}}
)
聚合操作
聚合操作分类
聚合管道
文档进入多阶段的管道,这些文档将转化为聚合结果。
db.orders.aggregate([
{ $match: { status: "A" } }, -- 一阶段
{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } } -- 二阶段
])
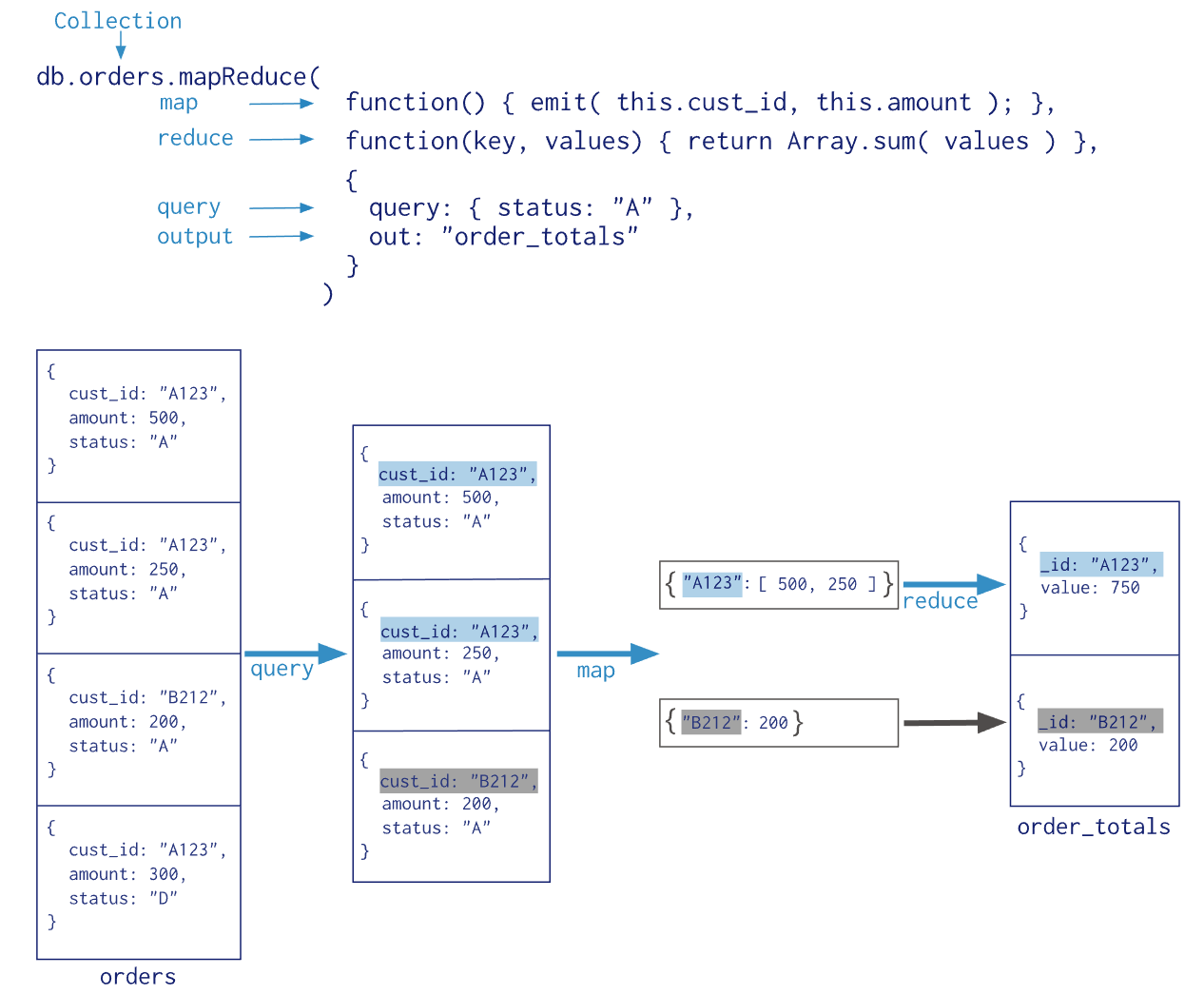
Map-Reduce
单用途聚合操作
测试数据
-- 测试数据:
db.authors.insertMany([
{ "author" : "Vincent", "title" : "Java Primer", "like" : 10 },
{ "author" : "Vincent", "title" : "Java Primer", "like" : 10 },
{ "author" : "della", "title" : "iOS Primer", "like" : 30 },
{ "author" : "benson", "title" : "Android Primer", "like" : 20 },
{ "author" : "Vincent", "title" : "Html5 Primer", "like" : 40 },
{ "author" : "louise", "title" : "Go Primer", "like" : 30 },
{ "author" : "yilia", "title" : "Swift Primer", "like" : 8 }
])
单目的聚合操作
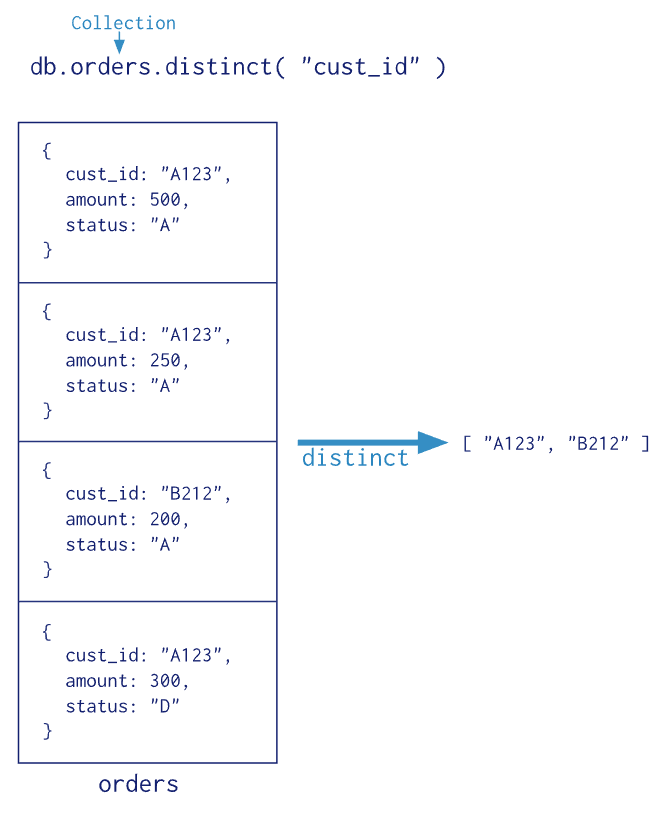
单目的聚合命令常用的有:count() 、 distinct() 和group()
db.authors.find({like:{$lt:20}}).count()
db.authors.distinct("like")
聚合管道操作
格式说明
一般用于统计数据。常用操作:
- $match :过滤数据。
- $project :修改传入文档的结构。可用于重命名、增加、删除域、创建计算结果和嵌套文档。
- $group :集中文档,统计结果。
- $sort :排序。
- $limit :限制返回的结果数。
db.authors.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
])
-- like、author为字段名称
db.authors.aggregate([
{ $match: { author: {$in:["louise", "della"]} } },
{ $group: { _id: "$like", total: { $sum: "$like" } } }
])
筛选
db.authors.aggregate(
{"$match": {"like": {"$gt" : 10} }}
)
分组
-- _id 、count 对应 select user_id as id , sum(xxx) as count
db服务器托管网.authors.aggregate(
{"$match": {"like": {"$gte" : 25} }},
{"$group": {"_id": "$author", "count": {"$sum": 1}}}
)
多字段分组
db.authors.aggregate(
{"$match": {"like": {"$gte" : 25} }},
{"$group": {"_id": {a:"$author",b:"$like"}, "count": {"$sum": 1}}}
)
分组取最值
db.authors.aggregate(
{"$group": {"_id": "$author", "count": {"$max": "$like"}}}
)
分组取平均值
db.authors.aggregate(
服务器托管网 {"$group": {"_id": "$author", "count": {"$avg": "$like"}}}
)
分组结果写入Set集合
-- 根据author字段分组,分组结果写入名为like的集合
db.authors.aggregate(
{"$group": {"_id": "$author", "like": {"$addToSet": "$like"}}}
)
{ "_id" : "Vincent", "like" : [ 40, 10 ] }
{ "_id" : "yilia", "like" : [ 8 ] }
{ "_id" : "della", "like" : [ 30 ] }
{ "_id" : "benson", "like" : [ 20 ] }
{ "_id" : "louise", "like" : [ 30 ] }
分组结果写入List集合
db.authors.aggregate(
{"$group": {"_id": "$author", "like": {"$push": "$like"}}}
)
{ "_id" : "Vincent", "like" : [ 10, 40, 10 ] }
{ "_id" : "yilia", "like" : [ 8 ] }
{ "_id" : "della", "like" : [ 30 ] }
{ "_id" : "benson", "like" : [ 20 ] }
{ "_id" : "louise", "like" : [ 30 ] }
$project案例:结果中排除字段、字段重命名
0不显示此字段、1显示此字段。
-- 结果集不显示_id字段
db.authors.aggregate(
{"$match": {"like": {"$gte" : 10} }},
{"$project": {"_id": 0, "author":1, "title": 1}}
)
-- 重命名
db.authors.aggregate(
{"$match": {"like": {"$gte" : 10} }},
{"$project": {"_id": 0, "author":1, "B-Name": "$title"}}
)
$limit案例、排序
db.authors.aggregate(
{"$match": {"like": {"$gte" : 10} }},
{"$group": {"_id": "$author", "count": {"$sum": 1}}},
{"$sort": {"count": -1}},
{"$limit": 1}
)
算数表达式案例
add 指定字段值加 n
-- like字段值 + 1
db.authors.aggregate(
{"$project": {"newLike": {"$add": ["$like", 1]}}}
)
{ "_id" : ObjectId("63b2b63e653186ee23d724b3"), "newLike" : 11 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b4"), "newLike" : 31 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b5"), "newLike" : 21 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b6"), "newLike" : 41 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b7"), "newLike" : 31 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b8"), "newLike" : 9 }
{ "_id" : ObjectId("63b2d5a7653186ee23d724b9"), "newLike" : 11 }
subtract 指定字段值减 n
db.authors.aggregate(
{"$project": {"newLike": {"$subtract": ["$like", 2]}}}
)
{ "_id" : ObjectId("63b2b63e653186ee23d724b3"), "newLike" : 8 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b4"), "newLike" : 28 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b5"), "newLike" : 18 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b6"), "newLike" : 38 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b7"), "newLike" : 28 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b8"), "newLike" : 6 }
{ "_id" : ObjectId("63b2d5a7653186ee23d724b9"), "newLike" : 8 }
multiply 乘法
db.authors.aggregate(
{"$project": {"newLike": {"$multiply": ["$like", 10]}} }
)
{ "_id" : ObjectId("63b2b63e653186ee23d724b3"), "newLike" : 100 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b4"), "newLike" : 300 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b5"), "newLike" : 200 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b6"), "newLike" : 400 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b7"), "newLike" : 300 }
{ "_id" : ObjectId("63b2b63e653186ee23d724b8"), "newLike" : 80 }
{ "_id" : ObjectId("63b2d5a7653186ee23d724b9"), "newLike" : 100 }
divide 除法
db.authors.aggregate(
{"$project": {"newLike": {"$divide": ["$like", 10]}} }
)
mod 余数
db.authors.aggregate(
{"$project": {"newLike": {"$mod": ["$like", 3]}} }
)
substr 字符串截取
db.authors.aggregate(
{"$project": {"newTitle": {"$substr": ["$title", 1, 2] } }}
)
concat 字符串拼接
db.authors.aggregate(
{"$project": {"newTitle": {"$concat": ["$title", "(", "$author", ")"] }
}}
)
toLower 字符串转大、小写
db.authors.aggregate(
{"$project": {"newTitle": {"$toLower": "$title"} }}
)
-- 大写
db.authors.aggregate(
{"$project": {"newAuthor": {"$toUpper": "$author"} }}
)
日期表达式案例
获取日期任意一部分
$year、$month、$dayOfMonth、$dayOfWeek、$dayOfYear、$hour、$minute、$second
-- 给示例数据补充字段
db.authors.update(
{},
{"$set": {"publishDate": new Date()}},
true,
true
)
-- 查询月份
db.authors.aggregate(
{"$project": {"month": {"$month": "$publishDate"}}}
)
运算符案例
cmp 大小比较
$cmp: [exp1, exp2]
- 等于返回 0
- 小于返回一个负数
- 大于返回一个正数
db.authors.aggregate(
{"$project": {"result": {"$cmp": ["$like", 20]} }}
)
and 条件
$and:[exp1, exp2, ..., expN]
多个条件都为true时才返回true。
db.authors.aggregate(
{"$project":
{
"result": {
"$and": [{"$eq": ["$author", "Vincent"]}, {"$gt":["$like", 20]}]
}
}
}
)
or 条件
db.authors.aggregate(
{
"$project":
{
"result":
{
"$or": [{"$eq": ["$author", "Vincent"]}, {"$gt": ["$like",20]}]
}
}
}
)
not 不等于
db.authors.aggregate(
{"$project": {"result": {"$not": {"$eq": ["$author", "Vincent"]}}}}
)
cond 三元运算符
$cond: [booleanExp, trueExp, falseExp]
db.authors.aggregate(
{"$project": {
"result": {"$cond": [ {"$eq": ["$author", "Vincent"]}, "111", "222"
]}}
}
)
ifNull 非空
# 测试数据
db.authors.insertMany([
{ "title" : "Swift Primer", "like" : 8 }
])
db.authors.aggregate(
{"$project": {
"result": {"$ifNull": ["$author", "not exist is null"]}}
}
)
{ "_id" : ObjectId("63b2b63e653186ee23d724b3"), "result" : "Vincent" }
{ "_id" : ObjectId("63b2b63e653186ee23d724b4"), "result" : "della" }
{ "_id" : ObjectId("63b2b63e653186ee23d724b5"), "result" : "benson" }
{ "_id" : ObjectId("63b2b63e653186ee23d724b6"), "result" : "Vincent" }
{ "_id" : ObjectId("63b2b63e653186ee23d724b7"), "result" : "louise" }
{ "_id" : ObjectId("63b2b63e653186ee23d724b8"), "result" : "yilia" }
{ "_id" : ObjectId("63b2d5a7653186ee23d724b9"), "result" : "Vincent" }
{ "_id" : ObjectId("63b4d7177613bd03eda74636"), "result" : "not exist is null" }
MapReduce
格式说明
MongoDB不允许Aggregation Pipeline的单个聚合操作占用过多的系统内存,如果一个聚合操作消耗20%以上的内存,那么MongoDB直接停止操作,并向客户端输出错误消息。
所以 MapReduce 价值很大。
db.collection.mapReduce(
function() {emit(key,value);}, //map 函数,遍历collection 中所有的记录,并将 key 与 value 传递给 Reduce
function(key,values) {return reduceFunction}, //reduce 函数,处理Map传递过来的所有记录
{
out: collection,
query: document,
sort: document,
limit: number,
finalize: ,
verbose:
}
)
- out :存放统计结果的集合。
- query :满足条件的文档才调用map函数。
- sort :一般用于配合limit。优化分组。
- limit :发往map函数文档数量的上限。
- finalize :对reduce函数输出结果进行最后的处理。
- verbose :是否包括结果信息中的时间信息,默认false。
测试数据
db.posts.insert({"post_text": "测试mapreduce。", "user_name": "Vincent",
"status":"active"})
db.posts.insert({"post_text": "适合于大数据量的聚合操作。","user_name": "Vincent",
"status":"active"})
db.posts.insert({"post_text": "this is test。","user_name": "Benson",
"status":"active"})
db.posts.insert({"post_text": "技术文档。", "user_name": "Vincent",
"status":"active"})
db.posts.insert({"post_text": "hello word", "user_name": "Louise",
"status":"no active"})
db.posts.insert({"post_text": "lala", "user_name": "Louise",
"status":"active"})
db.posts.insert({"post_text": "天气预报。", "user_name": "Vincent",
"status":"no active"})
db.posts.insert({"post_text": "微博头条转发。", "user_name": "Benson",
"status":"no active"})
条件过滤、分组、求和
# 结果输出到 post_total 集合
# this代表当前集合
db.posts.mapReduce(
function() { emit(this.user_name,1); },
function(key, values) {return Array.sum(values)}, # 求和
{
query:{status:"active"}, # 过滤
out:"post_total"
}
)
# 查询结果集合
db.post_total.find()
# 可以换一种写法
var mapFunction1 = function() {
emit(this.user_name, 1);
};
var reduceFunction1 = function(key, values) {
return Array.sum(values);
};
db.posts.mapReduce(
mapFunction1,
reduceFunction1,
{ out: "post_total2" }
)
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
