
文章目录
- 一、什么是索引
- 1、索引初体验
- 2、索引图解
- 3、索引类型
- 二、索引存储模型推演
- 1、二分查找
- 2、二叉查找树(BST Binary Search Tree)
- 3、平衡二叉树(AVL Tree)(左旋、右旋)
- (1)平衡二叉树的调整
- (2)平衡二叉树的索引
- (3)AVL树用于存储索引数据
- 4、多路平衡查找树(B Tree) (分裂、合并)
- (1)查找实例
- (2)B Tree保持平衡的秘诀
- 5、B+树(加强版多路平衡查找树)
- (1)B+Tree搜索过程
- (2)B+Tree带来的优势
- 6、为什么不用红黑树?
- 6、hash索引
- (1)哈希索引的特点
- (2)注意
- 三、B+Tree的落地实现
- 1、认识MySQL数据存储文件
- 2、MyISAM
- (1)MyISAM索引机制
- 3、InnoDB
- (1)聚集索引(聚簇索引)
- (2)二级索引
- (3)一个表没有主键
二分查找的思想,也叫折半查找,每次都把候选数据缩小了一半。如果数据已经排过序的话,这种方式效率比较高。所以首先,我们可以考虑使用有序数组作为索引的数据结构。有序数组的等值查询和比较查询效率非常高,但是更新数据的时候会出现一个问题,可能要挪动大量的数据(改变index),所以只适合存储静态的数据。为了支持频繁的修改,比如插入数据,我们需要采用链表,但是链表的话,如果是单链表,它的查找效率还是不够高。所以,有没有可以使用二分查找的链表呢?为了解决这个问题,BST(Binary Search Tree)也就是我们所说的二叉查找树就诞生了。
二叉查找树的 特点是什么?左子树所有的节点都小于父节点,右子树所有的节点都大于父节点。投影到平面以后,就是一个有序的线性表。二叉查找树既能够实现快速查找,又能够实现快速插入。但是二叉查找树有一个问题:就是它的查找耗时是和这棵树的深度相关的,在最坏的情况下时间复杂度会退化成O(n)。什么情况是最坏的情况呢? 还是刚才这一批数字,如果我们插入的数据刚好是有序的,它会变成链表(我们把这种树叫做“斜树”),这种情况下不能达到加快检索速度的目的,和顺序查找效率是没有区别的。 造成它倾斜的原因是什么呢? 因为左右子树深度差太大,这棵树的左子树根本没有节点——也就是它不够平衡。 所以,我们有没有左右子树深度相差不是那么大,更加平衡的树呢?这个就是平衡二叉树,叫做Balanced binary search trees,或者AVL树(AVL是发明这个数据结构的两位作者的名字简写:G.M.Adelson-Velsky和E.M.Landis)。
AVL Trees(Balanced binary search trees) 平衡二叉树的定义:左右子树深度差绝对值不能超过1。比如左子树的深度是2,右子树的深度只能是1、2、3,这个时候我们再按顺序插入数据,不会变成一棵“斜树”。 那它的平衡是怎么做到的呢?怎么保证左右子树的深度差不能超过1呢?
Balanced Tree就是我们说的多路平衡查找树,叫做B Tree(B代表平衡)。跟AVL(平衡二叉树)一样,B树在枝节点和叶子结点存储键值、数据地址、节点引用。它有一个特点:分叉数(路数)永远比关键字数多1。 比如我们画的这棵树,每个节点存储两个关键字,那么就会有三个指针指向三个子节点(当然肯定不只存3个这么少)。
B Tree的效率已经很高了,为什么MySQL还要对B Tree进行改良,最终使用了B+Tree呢?总体上来说,这个B树的改良版本解决的问题比B Tree更全面。我们来看一下InnoDB里面的B+树的存储结构: MySQL中的B+Tree有几个特点: 1、它的关键字的数量是跟路数相等的;2、B+Tree的根节点和枝节点中都不会存储数据,只有叶子结点才存储数据。 搜索到关键字不会直接返回,会到最后一层的叶子节点。比如我们搜索id = 28,虽然在第一层直接命中了,但是全部的数据在叶子节点上面,所以我还要继续往下搜索,一直到叶子节点。3、B+Tree的每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个叶子节点的第一个数据,形成了一个有序链表的结构。
在navicat工具中,创建索引,索引方式还有一种是HASH索引,以KV的形式检索数据,也就是说,它会根据索引字段生成哈希码和指针,指针指向数据。
(1)哈希索引的特点
1、它的事件复杂度是O(1),查询速度比较快。因为哈希索引里面的数据不是按顺序存储的,所以不能用于排序。
2、我们在查询数据的时候要根据键值计算哈希码,所以它只能支持等值查询(= IN),不支持范围查询(> = 3、如果字段重复值很多的时候,会出现大量的哈希冲突(采用拉链法解决),效率会降低。
(2)注意
在InnoDB中,不能显式地创建一个哈希索引(所谓的支持哈希索引指的是AHI,自适应哈希,它是InnoDB自动为buffer pool中的热点页创建的索引)。
memory存储引擎可以使用Hash索引。
三、B+Tree的落地实现
1、认识MySQL数据存储文件
首先,MySQL的数据都是文件的形式存放在磁盘中的,我们可以找到这个数据目录的地址。在MySQL中有这么一个参数,我们来看一下:
show variables like 'datadir';每个数据库有一个目录,我们新建了一个叫做test的数据库,那么这里就有一个test的文件夹。
数据库里面的几张表,进入test目录之后,发现这里面有一些跟我们创建的表名对应的文件。
在这里我们能看到,每张InnoDB的表有两个文件(.frm和.ibd),MyISAM的表有三个文件(.frm、.MYD、.MYI)。
有一个是相同的文件.frm。.frm是MySQL里面表结构定义的文件,不管你建表的时候选用任何一个存储引擎都会生成。
主要是其他两个文件,实现了MySQL不同存储引擎的索引。
2、MyISAM
在MyISAM里面,有另外两个文件:
一个是.MYD文件,D代表Data,是MyISAM的数据文件,存放数据记录,比如我们的user_myisam表的所有的表数据。
一个是.MYI文件,I代表Index,是MyISAM的索引文件,存放索引,比如我们在id字段上面创建了一个主键索引,那么主键索引就是在这个索引文件里面。一个索引就会有一棵B+Tree,所有的B+Tree都在这个myi文件里面。
也就是说,在MyISAM里面,索引和数据是两个独立的文件。
(1)MyISAM索引机制
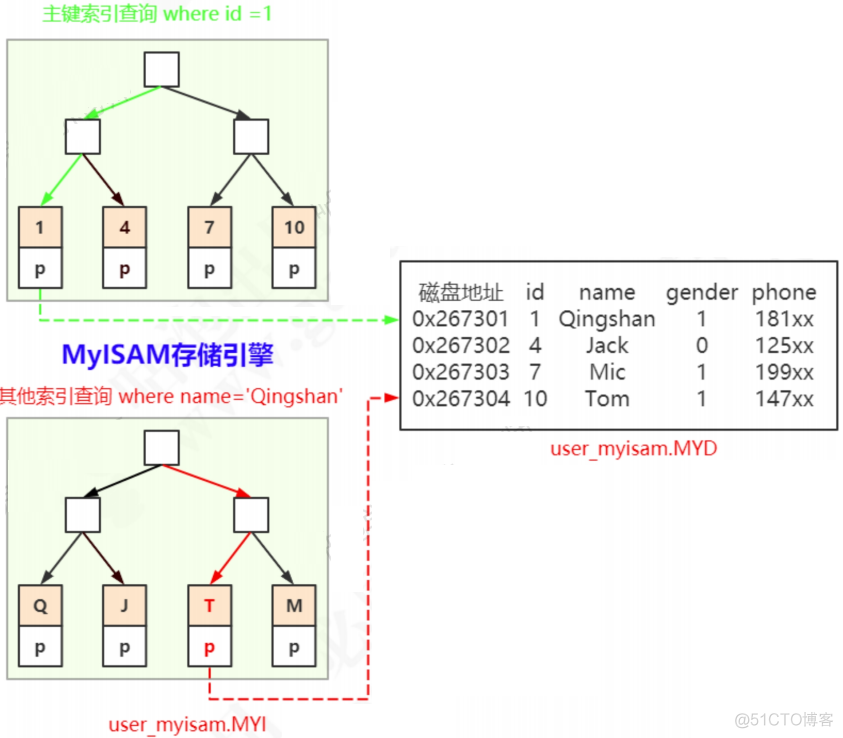
MyISAM的B+Tree里面,叶子节点存储的事数据文件对应的磁盘地址。所以从索引文件.MYI中找到键值后,会到数据文件.MYD中获取相应的数据记录。
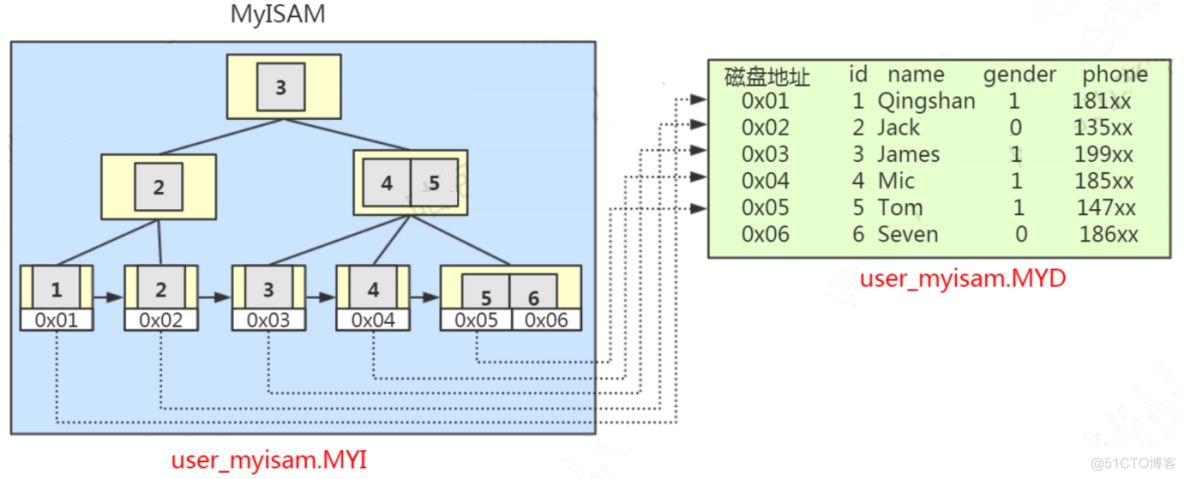
除了主键索引,在MyISAM中,其他索引也在这个.MYI文件里面。
-- name字段创建索引
ALTER TABLE user_innodb DROP INDEX idx_user_name;
ALTER TABLE user_innodb ADD INDEX idx_user_name (name);非主键索引跟主键索引存储和检索数据的方式是没有任何区别的,一样是在索引文件里面找到磁盘地址,然后到数据文件里面获取数据。
3、InnoDB
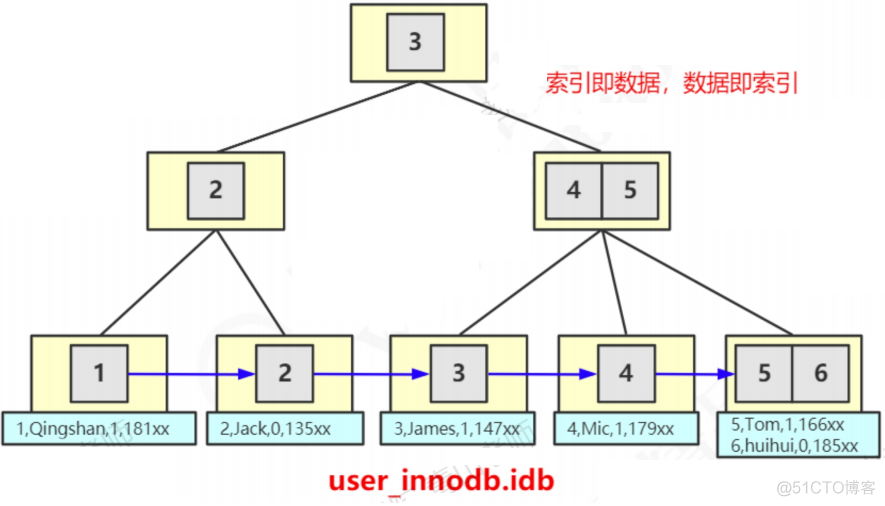
与MyISAM不同,在InnoDB的某个索引的叶子节点上,它直接存储了我们的数据。
所以,为什么说在InnoDB中索引即数据,数据即索引,就是这个原因。
但是会有一个问题,一张InnoDB的表可能有很多个索引,数据肯定是只有一份的,那数据在哪个索引的叶子节点上呢?
(1)聚集索引(聚簇索引)
InnoDB引入了聚集索引(聚簇索引)的概念。索引键值的逻辑顺序跟表数据行的物理存储顺序是一致的。
InnoDB组织数据的方式就是(聚集)索引组织表(clustered index organize table)。如果说一张表创建了主键索引,那么这个主键索引就是聚集索引,决定数据行的物理存储顺序。
(比如字典的目录是按拼音排序的,内容也是按拼音排序的,按拼音排序的这种目录就叫聚集索引)
那么问题来了,主键索引之外的索引,会不会也把完整记录在叶子节点放一份呢?答案是并不会,因为这会带来额外的存储空间浪费和计算消耗。
它们的叶子结点上没有数据怎么检索完整数据?比如我们在name字段上面建的普通索引。
(2)二级索引
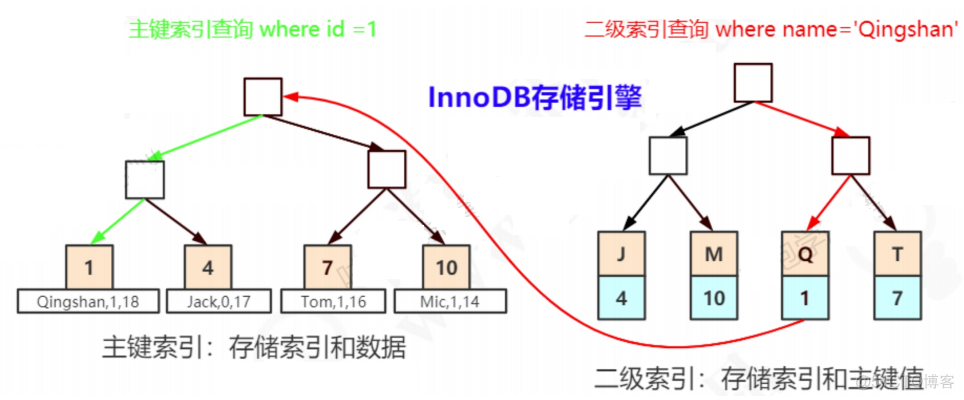
InnoDB中,主键索引和辅助索引是有一个主次之分的。如果有主键索引,那么主键索引就是聚集索引。其他的索引统一叫做“二级索引”(secondary index)。
二级索引存储的是二级索引的键值,例如在name上建立索引,节点上存的是name的值,qingshan tom等等(很明显,它的键值逻辑顺序跟物理行的顺序不一致)。
而二级索引的叶子节点存的是这条记录对应的主键的值。比如qingshan id = 1,jack id = 4等等。
所以,二级索引检索数据的流程是这样的:
当我们用name索引查询一条记录,它会在二级索引的叶子节点找到name=zhangsan,拿到主键,也就是id=1,然后再到主键索引的叶子节点拿到数据。
为什么不存地址而存键值呢?因为地址会发生变化。
从这个角度来说,因为主键索引比二级索引少扫描了一棵B+Tree(避免了回表),它的速度相对会快一些。
(3)一个表没有主键
一张表没有主键怎么办?完整的记录放在哪个索引的叶子节点?数据放在那里?
1、如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引。
2、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引。
3、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐藏的聚集索引,它会随着记录的写入而主键递增。
select _rowid name from t;服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: Helm实战案例一:在Kubernetes上使用Helm搭建Prometheus Operator监控
目录 一.系统环境 二.前言 三.Prometheus Operator简介 四.helm安装prometheus-operator 五.配置prometheus-operator 5.1 修改grafana的svc类型 5.2 查询grafana的账号密码 …
