
【问题描述】
开发有天碰到一个很奇怪的问题,他的场景是这样子的:
通过Canal来订阅MySQL的binlog, 当捕获到有数据变化时,回到数据库,反查该数据的明细,然后做进一步处理。
有一次,他碰到一个诡异的现象:
1. Canal收到消息,有一条主键id=31019319的数据插入
2. 11:19:51.081, 应用程序去反查数据库,11:19:51.084查询完毕,发现id=31019319的数据为空
3. 过几分钟后,开发去手工查数据库,发现id=31010319的数据是存在的,每次插入的时候,我们会在数据库记录插入时间,发现插入的时间是11:19:51.059。让开发感到困惑的是11:19:51.059写入的数据,11:19:51.081去查询,应该是能查到数据的呀。我们首先排除了读写分离,主从分离等场景,Canal订阅和数据库查询都是在Master上,所以这个问题就变得非常诡异了。
【问题分析】
因为中间夹杂着Canal, 而Canal是通过binlog读取的,这个问题我们可以简化为:当我们在master插入一条数据,该数据在master还没落库,但是在Slave却能查到。我们尝试重现这种场景。因为我们是采用GTID模式,GTID也就是全局事务编号,我们通过跟踪GTID来调试问题。
我们创建一个测试表如下:
CREATE TABLE `gtid_debug` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
此时,在Master和Slave上,分别收集到的GTID信息如下:
| 角色 | @@global_gtid_executed | @@port |
|---|---|---|
| Master | be7945f1-3613-11ec-8353-98039ba5775a:1-16 | 3306 |
| Slave | be7945f1-3613-11ec-8353-98039ba5775a:1-16 | 3307 |
我们在Master上开启gdb调试,在函数ReplSemiSyncMaster::commitTrx上设置断点。
步骤1:
在Master上,开启Session1, 插入一条数据:
insert into gtid_debug(name)values('test1'); 此时会hit到断点。
步骤2:
在Slave上,开启Session2, 查看GTID:
| 角色 | @@global_gtid_executed | @@port |
|---|---|---|
| Slave | be7945f1-3613-11ec-8353-98039ba5775a:1-17 | 3307 |
也就是说,事务在Slave上,开始走字了。
我们进行如下查询:可以看到,在Slave这条记录能被查询到。
slave>select * from test.gtid_debug;
| ID | NAME |
| ---- | ----- |
| 1 | test1 |
步骤3:
在Master上,我们开启Session3, 查看GTID, 这个session也会被断点中断,我们继续执行下一步,直到查询结果返回。注意,此时Session1还停留在断点上,未提交成功。
| 角色 | @@global_gtid_executed | @@port |
|---|---|---|
| Master | be7945f1-3613-11ec-8353-98039ba5775a:1-16 | 3306 |
并进行如下查询,返回结果为空:
master>select * from test.gtid_debug;
Empty set 所以我们重现了问题,也就是说,在Master插入数据,事务还没有提交,但在Slave就能查到了。 Slave跑的比Master还快。
【原因分析】
重现了问题后,我们对问题进行分析,并查看了相应代码,发现是半同步复制的模式导致,半同步复制有两种模式: After_Sync(5.7版本默认)模式和After_Commit(5.6版本默认)模式。我们线上的版本是5.7,所以采用的是After_Sync模式。
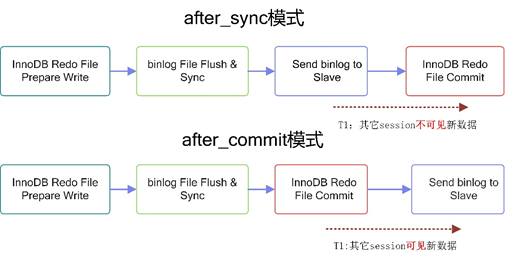
从上图可以看到,一个事务在半同步模式下提交,无论是after_sync还是after_commit,都要经历4个阶段:
1. InnoDB Redo File Prepare Write
2. Binlog File Flush & Sync
3. InnoDB Redo File Commit (同时释放事务持有的锁)
4. Send binlog to SlaveAfter_Commit模式的四个阶段顺序为: 1->2->3->4, 而after_sync模式的顺序为1->2->4->3.
在5.7默认的after_sync模式下,确实存在先发送binlog到Slave, 然后再进行事务提交的场景。这时候大家会问了,为啥5.7把半同步复制改为after_sync模式了?这主要是因为after_commit机制存在数据丢失的风险。我们可以设想一下,在3->4的T1时间段,新数据对其它Session已经可见,突然Master挂了,MySQL进行主从切换,这时事务在Master上完成,如在Slave上不存在,切换后,业务会发现之前能查到的数据又没了。
而在after_sync模式下,其执行的顺序为1->2->4->3. 也就是说Master在收到Slave的应答之后,才Commit事务。在3->4的T1时间段内,因事务还未Commit,新数据对其它Session还不可见,所以看上去像比Slave跑的更慢。具体可以参考网上关于这两种模式的讨论。
【解决建议】
我们分析清楚问题之后,解决的方法就比较简单了。不建议改为after_commit模式,虽然改为after_commit模式,可以保证事务在Master落地后,Canal才会读到消息,但存在主从切换事务丢失的风险。我们的解决方法,是在Canal消息处理时,延后1秒再处理。这样解决方法比较合理。因为一般来讲,业务对消息的实时性不是特别高。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
