
索引:高校检索数据的数据结构
索引能干吗呢‘?
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查
索引的种类:
B+Tree,hash,fulltext,R-Tree
索引的优点:
- 提高检索效率
- 降低排序成本–排序分组主要消耗的是我们的内存和CPU
索引的缺点:
- 更新索引的IO量
- 调整索引所导致的计算量
- 存储空间
是否需要创建索引?
- 交频繁的座位查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引
- 更新非常频繁的字段不适合创建索引
- 不会出现在where语句中的字段不该创建索引
聚集索引和非聚集索引
聚集索引的叶子节点就是数据节点
聚集索引的条件:
a.首先选择显示定义的主键为聚集索引;
b.如果没有则选择第一个非NULL的唯一索引;
c.以上都不满足就选择ROWID。
聚集索引表现:
- 索引的键值顺序决定了表中相应行的物理顺序,即表中行的存储顺序由聚集索引的键值顺序决定;
- 一个表只能有一个聚集索引;
- 索引列可能是多个(复合索引)。
适用场景(只针对innodb存储引擎,myisam不存在这说法)
a.主键列,该列在where子句中使用并且插入是随机的。
b.按范围存取的列,如pri_order > 100 and pri_order
c.在group by或order by中使用的列。
d.不经常修改的列,不能建立在自增列上。
e.在连接操作中使用的列。
非聚集索引的叶子节点为索引节点,但是有一个指针指向数据节点
非聚集索引就是普通索引,仅仅是对表创建索引不会影响表的物理存储顺序,非聚集索引的写入顺序由时间顺序决定。
非聚集索引:
对更新频繁的表来说,表上的非聚簇索引比聚集索引和根本没有索引需要更多的额外开销。对移到新页的每一行而言,指向该数据的每个非聚簇索引的页级行也必须更新,有时可能还需要索引页的分理。
适用场景
a.常用于计算函数如sum/count的列;
b.常用于join/order by/group by的列;
c.查寻出的数据不超过表中数据量的20%。
非聚集索引
比如说一张表table,有属性id,name,birthday,gender
其中id自增主键,name为索引
执行select * from table where id=1
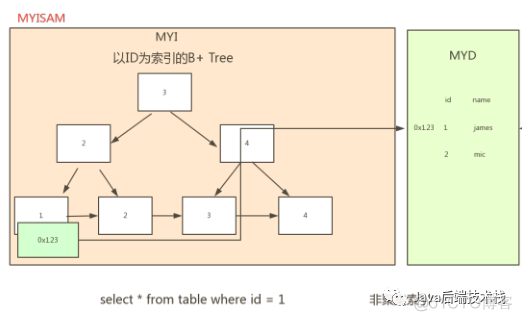
MYI为MYIISAM的索引表,MYD为MYISAM的数据表
这样咱们就先通过id=1在MYI查找0X123这个编码,然后拿着这个编码去MYD中获取对应的数据,
执行select * from table where name=’james’
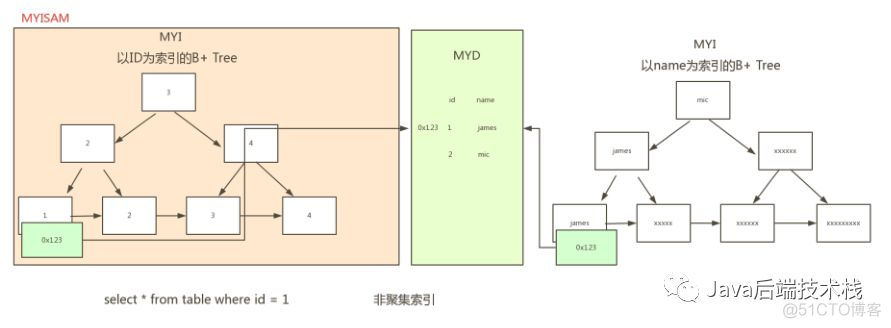
与上面的id为索引一样执行数据查找
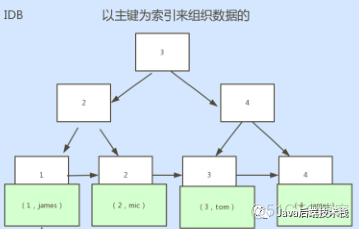
聚集索引–Innodb
执行select * from table where id=1,数据和索引是在同一张表中,
执行select * from table where name=’james’
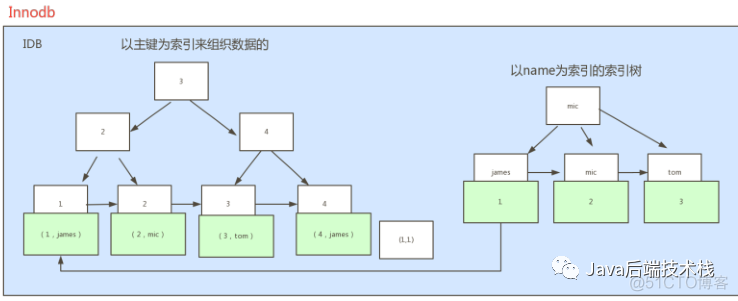
右边的树相当于是副的,如果查找name=’james’时,先在右边的副树上根据name查找到对应的id,然后通过id再来左边的树上查找对应的数据。
注意:如果name=’james’存在多条,则会返回多条数据,这就是咱们在使用mybatis查找一条数据时候会报一个异常,这个异常就是‘返回不止一条数据’。
最左前缀索引(多个列作为索引)
比如有一table1,属性a,b,c,d,其中a,b,c为一个索引
select * from table1 where a=1 and b=2 and c=1 则索引生效
select * from table1 where b=2 and a=1 and c=1 则索引失效
另外联合索引的第二列是默认会进行排序,
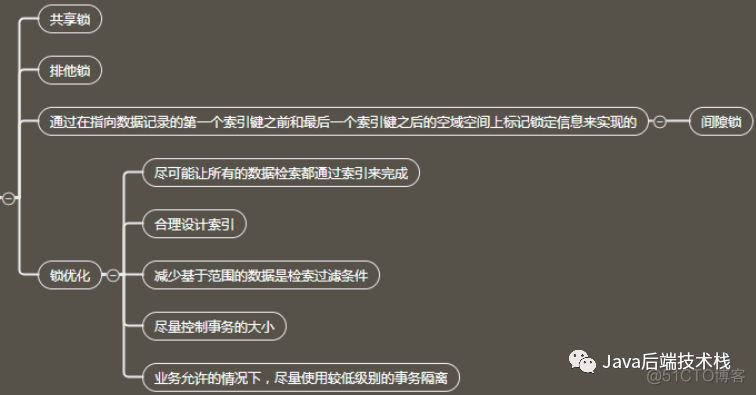
数据表相关锁
行锁
优点:粒度小
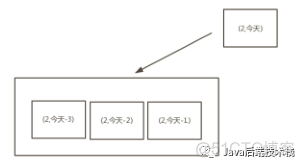
缺点:获取、释放所做的工作多,容易发生死锁,关于死锁
实现(Innodb)如下图
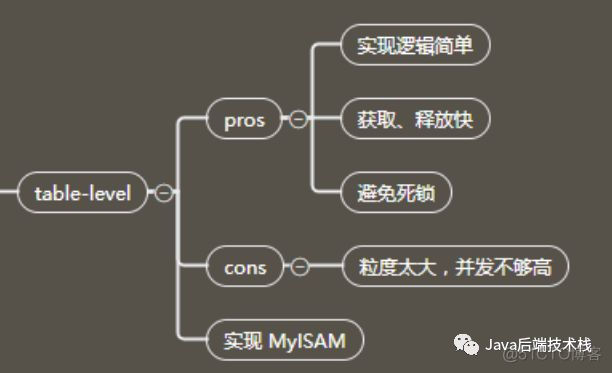
表锁
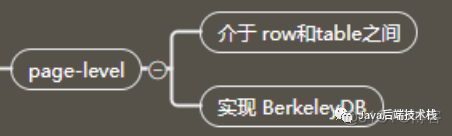
页锁
查看表级锁的竞争使用状态变量
show status like ‘table%’
查看行级锁的竞争使用状态变量
show status like ‘innodb_row_lock%’
写sql的时候注意一下几点:
- 永远使用小结果集驱动大结果集(join)
- 只取出自己想要的列(不要用select * from table)-数据量大、排序占用空间大
- 仅仅使用有效条件过滤(ken_length)
- 尽量避免使用复杂的join和子查询–锁资源
在select语句前面加上explain可以查看实行情况,然后针对性的进行对sql进行调整优化

圈起来的这几列是相对比较重要的,也就是你主要关注点。然后针对性的进行优化你的sql。至于这几列是各代表什么意义有什么区别,可以参照网上的,比如说:
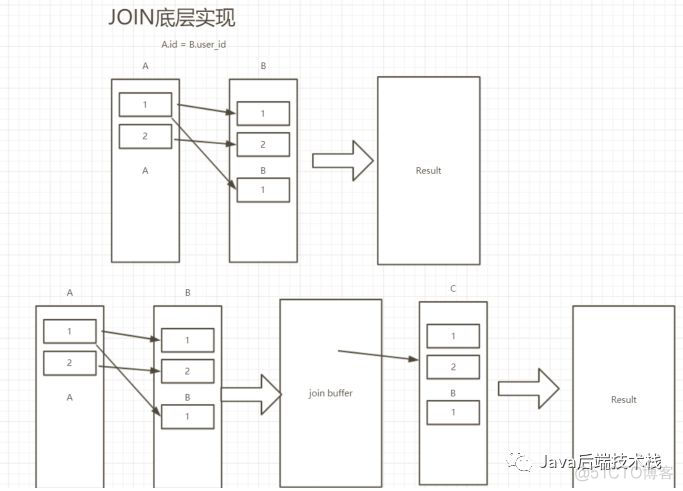
join
优化:
- 永远使用小结果集驱动大结果集
- 保证被驱动表上的join条件字段已经被索引
- join buffer(join_buffer_size)
查看join_buffer_size
show variable like ‘join_%’
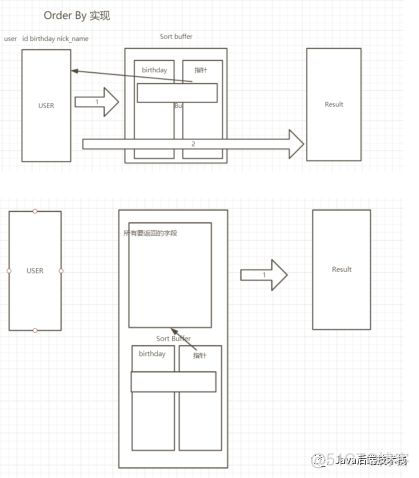
oder by
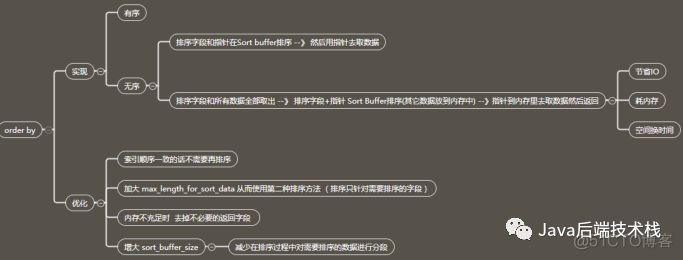
底层实现
最后总结一下性能优化:

服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
