
相关文章
数据库系列:MySQL慢查询分析和性能优化
数据库系列:MySQL索引优化总结(综合版)
数据库系列:高并发下的数据字段变更
数据库系列:覆盖索引和规避回表
数据库系列:数据库高可用及无损扩容
数据库系列:使用高区分度索引列提升性能
数据库系列:前缀索引和索引长度的取舍
数据库系列:MySQL引擎MyISAM和InnoDB的比较
数据库系列:InnoDB下实现高并发控制
数据库系列:事务的4种隔离级别
数据库系列:RR和RC下,快照读的区别
数据库系列:MySQL InnoDB锁机制介绍
数据库系列:MySQL不同操作分别用什么锁?
数据库系列:业内主流MySQL数据中间件梳理
数据库系列:大厂使用数据库中间件解决什么问题?
1 介绍
在笔者的这篇文章《构建高性能索引(策略篇)》中,我们详细讨论了如何设计高质量索引,里面多个地方提及可能导致索引失效的场景。
这边咱们重新梳理下,以枚举的方式来梳理出所有可能出现索引失效的点,避免RD同学们踩坑。
2 数据准备及验证
2.1 数据准备
1、创建两个表:员工表和部门表
/*部门表,存在则进行删除 */
drop table if EXISTS dep;
create table dep(
id int unsigned primary key auto_increment,
depno mediumint unsigned not null default 0,
depname varchar(20) not null default "",
memo varchar(200) not null default ""
);
/*员工表,存在则进行删除*/
drop table if EXISTS emp;
create table emp(
id int unsigned primary key auto_increment,
empno mediumint unsigned not null default 0,
empname varchar(20) not null default "",
job varchar(9) not null default "",
mgr mediumint unsigned not null default 0,
hiredate datetime not null,
sal decimal(7,2) not null,
comn decimal(7,2) not null,
depno mediumint unsigned not null default 0
);
2、创建两个函数:生成随机字符串和随机编号
/* 产生随机字符串的函数*/
DELIMITER $
drop FUNCTION if EXISTS rand_string;
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmlopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i 3、编写存储过程,模拟500W的员工数据
/*建立存储过程:往emp表中插入数据*/
DELIMITER $
drop PROCEDURE if EXISTS insert_emp;
CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
/*set autocommit =0 把autocommit设置成0,把默认提交关闭*/
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO emp(empno,empname,job,mgr,hiredate,sal,comn,depno) VALUES ((START+i),rand_string(6),'SALEMAN',0001,now(),2000,400,rand_num());
UNTIL i = max_num
END REPEAT;
COMMIT;
END $
DELIMITER;
/*插入500W条数据*/
call insert_emp(0,5000000);
4服务器托管网、编写存储过程,模拟120条部门数据
/*建立存储过程:往dep表中插入数据*/
DELIMITER $
drop PROCEDURE if EXISTS insert_dept;
CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i+1;
INSERT INTO dep( depno,depname,memo) VALUES((START+i),rand_string(10),rand_string(8));
UNTIL i = max_num
END REPEAT;
COMMIT;
END $
DELIMITER;
/*插入120条数据*/
call insert_dept(0,120);
5、建立关键字段的索引,这边是跑完数据之后再建索引,会导致建索引耗时长,但是跑数据就会快一些。
# 这边建立一个复合索引,包含 depno(部门编号)、empname(员工姓名)、job(工作岗位)。
create index idx_depno_empname_job on emp(depno,empname,job);
2.2 验证过程
在 MySQL 中建设合理高效的索引是提升检索性能的最有效方式,因为索引可以快速地定位表中的某条记录,达到提高数据库查询的速度的目的。
大多数情况下都(默认)采用B+树来构建索引,我们下面也默认使用InnoDB引擎来举例。
2.2.1 违反最左匹配原则
如下图,b+树的数据项是复合的数据结构,比如(empname,depno,job)这种(即构建一个联合索引)时,b+树是按照从左到右的顺序来建立搜索树的。
示例:
1、当以(‘brand’,106,’SALEMAN’)这样的数据来检索的时候,b+树会优先比较empname来确定下一步的所搜方向,如果empname相同再依次比较depno和job,最后得到检索的数据。
2、但如果是(106,’SALEMAN’)这样,没有empname的数据来的时候,b+树就不知道下一步该查哪个节点,因为empname就是第一个比较因子,必须要先根据empname来搜索才能知道下一步去哪里查询。
3、再比如当(‘brand’,’SALEMAN’)这样的数据来检索时,b+树可以用empname来指定搜索方向,但下一个字段depno的缺失,所以只能把名字等于 ‘brand’ 的数据都扫描出来,然后再匹配职位是SALEMAN的数据了。
这个重要特征就是索引的最左匹配原则,按照这个原则执行索引效率特别高。
我们试试在b+树上分析和举例:
下图中是3个字段(depno,empname,job)的联合索引,数据以depno asc,empname asc,job asc这种排序方式存储在节点中的,
排序原则:
1、索引以depno字段升序
2、depno相同时,以empname字段升序,
3、empname相同的时候,以job字段升序
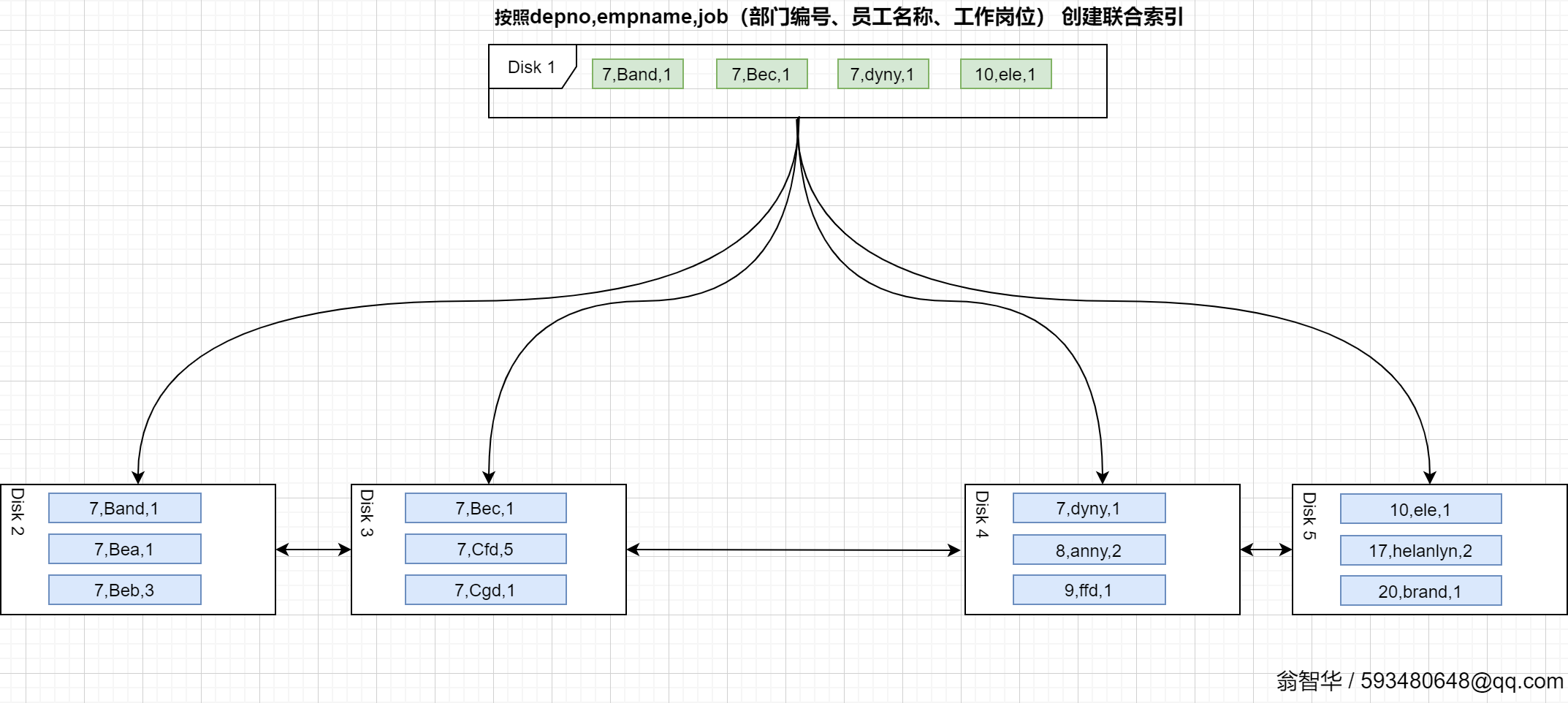
第一位置
检索depno=7的记录
由于页中的记录是以depno asc,empname asc,job asc这种排序方式存储的,所以depno字段是有序的,可以通过二分法快速检索到,步骤如下:
1、将Disk1加载到内存中
2、在内存中对Disk1中的记录采用二分法找,可以确定depno=7的记录位于{7,Brand,1}和{7,dyny,1}关联的范围内,这两个所指向的页分别是 Disk2 和 Disk4。
3、加载页Disk2,在Disk2中采用二分法快速找到第一条depno=7的记录,然后通过链表向下一条及下一页开始扫描,直到在Disk4中找到第一个不满足depno=7的记录为止。
第一+第二位置
检索depno=7 and empname like ‘B%’的记录
步骤跟上面是一致的,可以确定depno=1 and empname like ‘B%’的记录位于{7,Band,1}和{7,Bec,1}关联的范围内,查找过程和depno=7查找步骤类似。

第二位置
检索empname like ‘C%’的记录
这种情况通过Disk1页中的记录,无法判断empname like ‘C%’ 的记录在哪些页中的,只能逐个加载索引树的页,对所有记录进行遍历,然后进行过滤,此时索引无效。
# 验证脚本:未使用到了索引,全表扫描
mysql> explain select empno,empname,job from emp where empname like 'C%';
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4982087 | 11.11 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
第三位置
检索job=8的记录
这种情况和查询 empname like ‘C%’ 也一样,也只能扫描所有叶子节点,索引也无效。
# 验证脚本:未使用到了索引,全表扫描
mysql> explain select empno,empname,job from emp where job=8;
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4982087 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
第二+第三位置
empname和job一起查
这种原理跟前面两个一致,无法使用索引,只能对所有数据进行扫描。
第一+第三位置
按照(depno,job)字段顺序检索
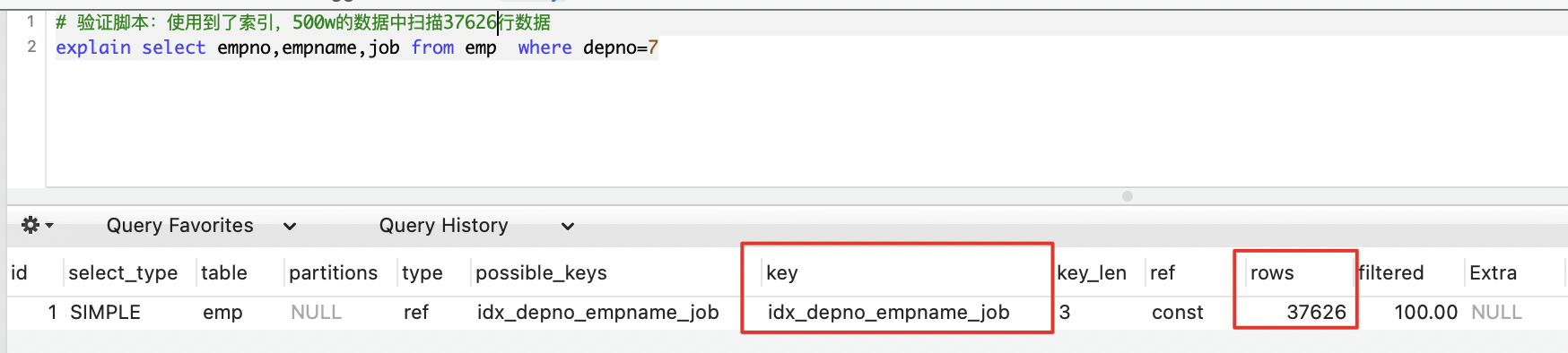
这种仅使用到索引中的depno字段了,通过depnon确定范围之后,加载所有depno下的数据,再对job条件进行过滤。如果的depno查出来的数据基数巨大,也会慢。
比如我们的测试数据中 depno=16 的数据有50W左右,也是比较多的。
# 验证脚本:未使用到了索引,但仅覆盖了depno,所以扫描行数也有 37626 行
mysql> explain select empno,empname,job from emp where depno=7 and job=8;
+----+-------------+-------+------------+------+-----------------------+-----------------------+---------+-------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------------+-----------------------+---------+-------+-------+----------+-----------------------+
| 1 | SIMPLE | emp | NULL | ref | idx_depno_empname_job | idx_depno_empname_job | 3 | const | 37626 | 10.00 | Using index condition |
+----+-------------+-------+------------+------+-----------------------+-----------------------+---------+-------+-------+----------+-----------------------+
1 row in set, 2 warnings (0.01 sec)
停止匹配的条件
检索depno=1 and empname>” and job=1的记录
据上面的图,这种检索方式只能先确定depno=1 and empname>”所在页的范围,然后对这个范围的所有页进行遍历,job字段在这个查询的过程中,是无法确定数据在哪些页的,此时我们说job是不走索引的,只有depno、empname能够有效的确定索引页的范围。
2.2.2 索引列使用函数
当我们不恰当的使用索引所对应的字段的时候,可能会导致索引失效,比如查询的过程没有保证独立的列,
这个独立的列是指索引对应的列不能作用在函数中。如下:
mysql> select * from emp where id = 4990000;
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4990000 | 4990000 | PWmulY | SALEMAN | 1 | 2021-01-23 16:46:24 | 2000 | 400 | 102 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (0.002 sec)
mysql> select * from emp where ABS(id) = 4990001;
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4990001 | 4990001 | fXtdiH | SALEMAN | 1 | 2021-01-23 16:46:24 | 2000 | 400 | 107 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (2.007 sec)
耗时分别是 0.002、2.007,使用explain分析后发现作用在函数的时候没有走索引,变成全表扫描:
mysql> explain select * from emp where id = 4990000;
+----+-------------+-------+-------+--------------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+--------------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | emp | const | PRIMARY,idx_emp_id | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+-------+-------+--------------------+---------+---------+-------+------+-------+
1 row in set
mysql> explain select * from emp where ABS(id) = 4990001;
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 4952492 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
1 row in set
2.2.3 计算表达式导致索引无效
索引对应的列也不能作用于计算表达式中:
mysql> select * from emp where id = 4990000;
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4990000 | 4990000 | PWmulY | SALEMAN | 1 | 2021-01-23 16:46:24 | 2000 | 400 | 102 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (0.002 sec)
mysql> select * from emp where id+1 = 4990001;
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4990000 | 4990000 | PWmulY | SALEMAN | 1 | 2021-01-23 16:46:24 | 2000 | 400 | 102 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (1.762 sec)
耗时分别是 0.002、1.762,使用explain分析后发现作用在表达式的时候没有走索引,变成全表扫描:
mysql> explain select * from emp where id = 4990000;
+----+-------------+-------+-------+--------------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+--------------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | emp | const | PRIMARY,idx_emp_id | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+-------+-------+--------------------+---------+---------+-------+------+-------+
1 row in set
# 下面这种是不行的
mysql> explain select * from emp where id+1 = 4990001;
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 4952492 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
1 row in set
# 下面这种是可以的
mysql> explain select * from emp where id = 4990001-1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | emp | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
2.2.4 类型转换(自动或手动)导致索引失效
mysql> select * from emp where empname ='LsHfFJA';
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4582071 | 4582071 | LsHfFJA | SALEMAN | 1 | 2021-01-23 16:46:03 | 2000 | 400 | 106 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set
从这个数据中我们可以看出 empname为字符串类型的,depno为数值类型的,这两个上面都有独立的索引,我们来看两个语句:
mysql> select * from emp where empname =1;
Empty set, 65535 warnings (2.57 sec)
mysql> explain select * from emp where empname =1;
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4982087 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
mysql> select count(*) from emp where depno ='106';
+----------+
| count(*) |
+----------+
| 500195 |
+----------+
1 row in set (0.000 sec)
mysql> select count(*) from emp where depno =106;
+----------+
| count(*) |
+----------+
| 500195 |
+----------+
1 row in set (0.001 sec)
1、第一个查询,即便是在empname上建了索引,耗时依旧达到2s多。那是因为empname是字符串类型,字符串和数字比较的时候,会将字符串强制转换为数字,然后进行比较,所以整个查询变成了全表扫描,一个个抽出每条数据,将empname转换为数字和1进行比较。从第二个explain语句中也印证了这个算法。
2、 第三个和第四个查询,depno是int类型的,两个查询效率一致,都是正常利用索引快速检索。这是因为数值类型的字段,查询匹配的值无论是字符串还是数值都会走索引。
2.2.5 模糊查询(Like)左边包含%号
下面看两个查询,都采用了模糊查询,但是使用%开头会造成无法从页面确定扫描的位置,导致索引无效,继而全表扫描。
mysql> select * from emp where empname like 'LsHfFJA%';
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4582071 | 4582071 | LsHfFJA | SALEMAN | 1 | 2021-01-23 16:46:03 | 2000 | 400 | 106 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (0.000 sec)
mysql> select * from emp where empname like '%LsHfFJA%';
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4582071 | 4582071 | LsHfFJA | SALEMAN | 1 | 2021-01-23 16:46:03 | 2000 | 400 | 106 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (2.034 sec)
上面第一个查询可以利用到name字段上面的索引,下面的查询是无法确定需要查找的值所在的范围的,只能全表扫描,无法利用索引,所以速度比较慢,这个过程上面有说过。
2.2.6 条件使用or关键字(OR 前后存在非索引的列)
在 WHERE 子句中,OR 前后的条件列不属于索引列,那么索引会失效。
以下面的语句为例子,使用And就可以使用到索引,Or就会全表扫描。
原理其实很好理解,使用And的时候,我们在搜索树上先找到第一个条件字段(就是覆盖索引的depno),然后再缩小范围查找mgr字段。
但如果使用了Or,代表我的条件是两个,都得搜寻,才能找出所有数据。而未覆盖索引的那个条件依旧需要全表扫描。
# 语句1:是用到索引
mysql> explain select empno,empname,job from emp where depno=1 and mgr=1;
+----+-------------+-------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ref | idx_depno_empname_job | idx_depno_empname_job | 3 | const | 3705 | 10.00 | Using where |
+----+-------------+-------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
# 语句2:全表扫描
mysql> explain select empno,empname,job from emp where depno=1 or mgr=1;
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | idx_depno_empname_job | NULL | NULL | NULL | 4982087 | 10.74 | Using where |
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
# 语句3:全表扫描
mysql> explain select empno,empname,job from emp where mgr=1 or depno=7 ;
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | idx_depno_empname_job | NULL | NULL | NULL | 4982087 | 10.74 | Using where |
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
这种情况的优化方式就是在Or的时候两边列都覆盖入索引,就可以避免全表扫描
2.2.7 条件使用in关键字
in方式检索数据,我们还是经常用的。
平时我们做项目的时候,建议少用表连接,比如电商中需要查询订单的信息和订单中商品的名称,可以先查询查询订单表,然后订单表中取出商品的id列表,采用in的方式到商品表检索商品信息,由于商品id是商品表的主键,所以检索速度还是比较快的。
通过id在500万数据中检索100条数据,看看效果:
mysql> select * from emp a where
a.id in (800000, 800001, 800002, 800003, 800004, 800005, 800006, 800007, 800008, 800009, 800010, 800011, 800012, 800013,
800014, 800015, 800016, 800017, 800018, 800019, 800020, 800021, 800022, 800023, 800024, 800025, 800026, 800027, 800028,
800029, 800030, 800031, 800032, 800033, 800034, 800035, 800036, 800037, 800038, 800039, 800040, 800041, 800042, 800043, 800044,
800045, 800046, 800047, 800048, 800049, 800050, 800051, 800052, 800053, 800054, 800055, 800056, 800057, 800058, 800059, 800060,
800061, 800062, 800063, 800064, 800065, 800066, 800067, 800068, 800069, 800070, 800071, 800072, 800073, 800074, 800075, 800076,
800077, 800078, 800079, 800080, 800081, 800082, 800083, 800084, 800085, 800086, 800087, 800088, 800089, 800090, 800091, 800092,
800093, 800094, 800095, 800096, 800097, 800098, 800099);
+--------+--------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+--------+--------+---------+---------+-----+---------------------+------+------+-------+
| 800000 | 800000 | qVFqPY | SALEMAN | 1 | 2021-01-23 16:43:02 | 2000 | 400 | 105 |
| 800001 | 800001 | KVzJXL | SALEMAN | 1 | 2021-01-23 16:43:02 | 2000 | 400 | 107 |
| 800002 | 800002 | vWvpkj | SALEMAN | 1 | 2021-01-23 16:43:02 | 2000 | 400 | 102 |
............
| 800099 | 800099 | roxtAx | SALEMAN | 1 | 2021-01-23 16:43:02 | 2000 | 400 | 107 |
+--------+--------+---------+---------+-----+---------------------+------+------+-------+
100 rows in set (0.001 sec)
耗时1毫秒左右,还是相当快的。
这个相当于多个分解为多个唯一记录检索,然后将记录合并。所以这个其实也是快的,只要in里面的数据不是极端海量的即可。
单次查询选择的数据范围很大,比如占整个表的30%以上时,MySQL优化器可能会认为全表扫描比使用索引更快,因此选择不使用索引。这是因为全表扫描可能避免了索引查找和回表的开销,从而在某些情况下提供了更好的性能。
所以使用 in 在结果集中不能超过30%。
2.2.8 使用 not in 或 not exists
情况同于 2.2.7 节
2.2.9 条件中使用比较算法
如下代码:
- 第一个语句中使用了不等比较 (!= 或者) 导致索引失效,不等于需要所有索引数据拿出来比较,所以等同于全表扫描,也是慢的。
- 第二个语句中使用了比较符,虽然走索引,但是扫描数据超过30%,编译器会认为全表扫描性能比走索引更好,就不走索引了。这点可参考 2.2.7 节
- 第三个语句扫描的数据量(122054)远低于500w的30%,走索引。查询执行计划中包含Using index condition和Using MRR时,意味着正在使用高效的索引和存储引擎优化技术来加速查询。
# 使用不等比较(!= 或者) 导致索引失效
mysql> explain select * from emp where depno 7;
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | idx_depno_empname_job | NULL | NULL | NULL | 4982087 | 52.45 | Using where |
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
# 扫描数据量超30%,不走索引
mysql> explain select * from emp where depno > 7;
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | idx_depno_empname_job | NULL | NULL | NULL | 4982087 | 50.00 | Using where |
+----+-------------+-------+------------+------+-----------------------+------+---------+------+服务器托管网---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
# 扫描数据量少,走索引
mysql> explain select * from emp where depno 3 总结
总结一下常见失效场景:
- 违反最左匹配原则
- 索引列使用函数计算
- 索引列使用计算表达式
- 索引列进行类型转换(自动或手动)
- 模糊查询(Like)左边包含%号
- 条件使用OR关键字,且在 OR 前后存在非索引的列
- 条件使用in关键字,且查询结果超过30%数据比
- 条件使用 not in 或 not exists,且查询结果超过30%数据比
- 条件中使用不等号(!= 或 )
除此之外,还有一些索引覆盖,规避回表的策略,我们后面的篇章再讨论。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 基于 Webpack 插件体系的 Mock 服务
背景 在软件研发流程中,对于前后端分离的架构体系而言,为了能够更快速、高效的实现功能的开发,研发团队通常来说会在产品原型阶段对前后端联调的数据接口进行结构设计及约定,进而可以分别同步进行对应功能的实现,提升研发速率。除了常见的研发流程提效之外,对于一些特殊的无…
