
大家好,我是蓝胖子,mysql对大表(千万级数据)的ddl语句,在生产上执行时一定要千万小心,一不小心就有可能造成业务阻塞,数据库io和cpu飙高的情况。今天我们就来看看如何针对大表执行ddl语句。
通过这篇文章,你能了解到下面的知识点,
传统ddl 和online ddl的区别
mysql的ddl 经过了几个版本的演进,Online DDL这个特性是在MySQL5.6.7开始支持,在此之前mysql执行ddl语句时,会生成新表,然后将原表数据复制到新表,整个过程是会阻塞DML语句的。
而online ddl 定义其实就是在执行ddl语句时,不会阻塞dml语句,那么我们就称这样的ddl为online ddl。
ddl 的算法参数选项又分为 copy, Inplace, INSTANT ,其中copy就是之前传统ddl执行的过程,会阻塞dml语句。Inplace, INSTANT 算法执行期间 都是可以执行DML语句的,所以我们称使用这两种算法的ddl语句为online ddl。
但需要注意的是,并不是所有的ddl操作都支持这两种算法,具体什么ddl操作类型支持什么算法需要去查阅官方文档。
INSTAN服务器托管网T 算法是mysql8.0 以后新加的,它能在秒级别对千万级别的大表进行加字段操作,至于其他ddl 语句类型是不是也支持INSTANT 算法,需要去看下官网了,由于我们线上还是使用的mysql5.7 ,所以我还是会给予mysql5.7去进行分析。
在mysql5.7中,例如我们执行下面的ddl 加字段的语句,
ALTER TABLE tbl_name ADD COLUMN column_name column_definition
mysql会去判断当前执行的ddl语句类型能不能用online ddl inplace 方式,如果能用,那么它就会采用。
使用Inplace算法的ddl语句,执行过程分为3个阶段,
阶段1: Initialization初始化
在初始化阶段,服务器将考虑存储引擎功能、语句中指定的操作以及用户指定的ALGORITHM和LOCK选项,确定操作期间允许多少并发性。在此阶段,使用一个可升级MDL读锁来保护当前表定义。
阶段2:Execution执行
如果评估阶段发现ddl语句不能使用inplace算法,则会将mdl读锁升级为排它锁,阻塞DML语句执行。并且,这个阶段,会真正的执行ddl语句。
阶段3:Commit Table Definition 提交表定义
在提交表定义阶段,MDL读锁升级为MDL排他锁,以排除旧表定义并提交新表定义。一旦授予,独占MDL锁的持续时间就会很短。
可以看到如果使用inplcae 算法,只有在任务提交阶段(时间很短), ddl才会阻塞dml语句,因为任务提交阶段会持有MDL 排他锁,而DML 语句执行时需要获取MDL读锁,所以在此期间,DML语句会被阻塞。
具体哪些ddl操作类型支持Inplace 算法,可以查看官方文档链接,比如下面的mysql5.7的文档
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-operations.html
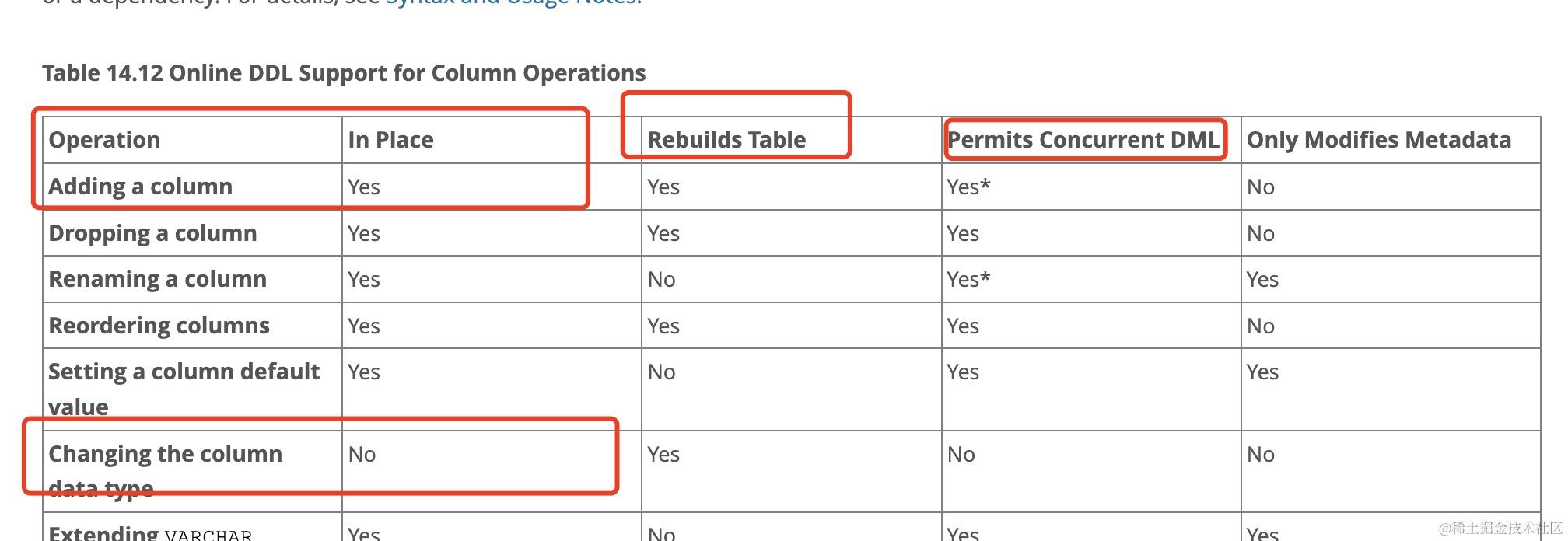
如下图所示,可以发现mysql5.7对加字段的ddl 支持inplace 算法,不过执行期间需要rebuild table即建立新表,并且运行并发的dml语句执行。但是改变字段数据类型ddl,则只能按copy算法进行执行。
inplace 算法不是不会产生数据的复制,只是复制期间,不会阻塞dml语句的执行。
mysql ddl 的陷阱
online ddl机制是否一定不会阻塞业务?
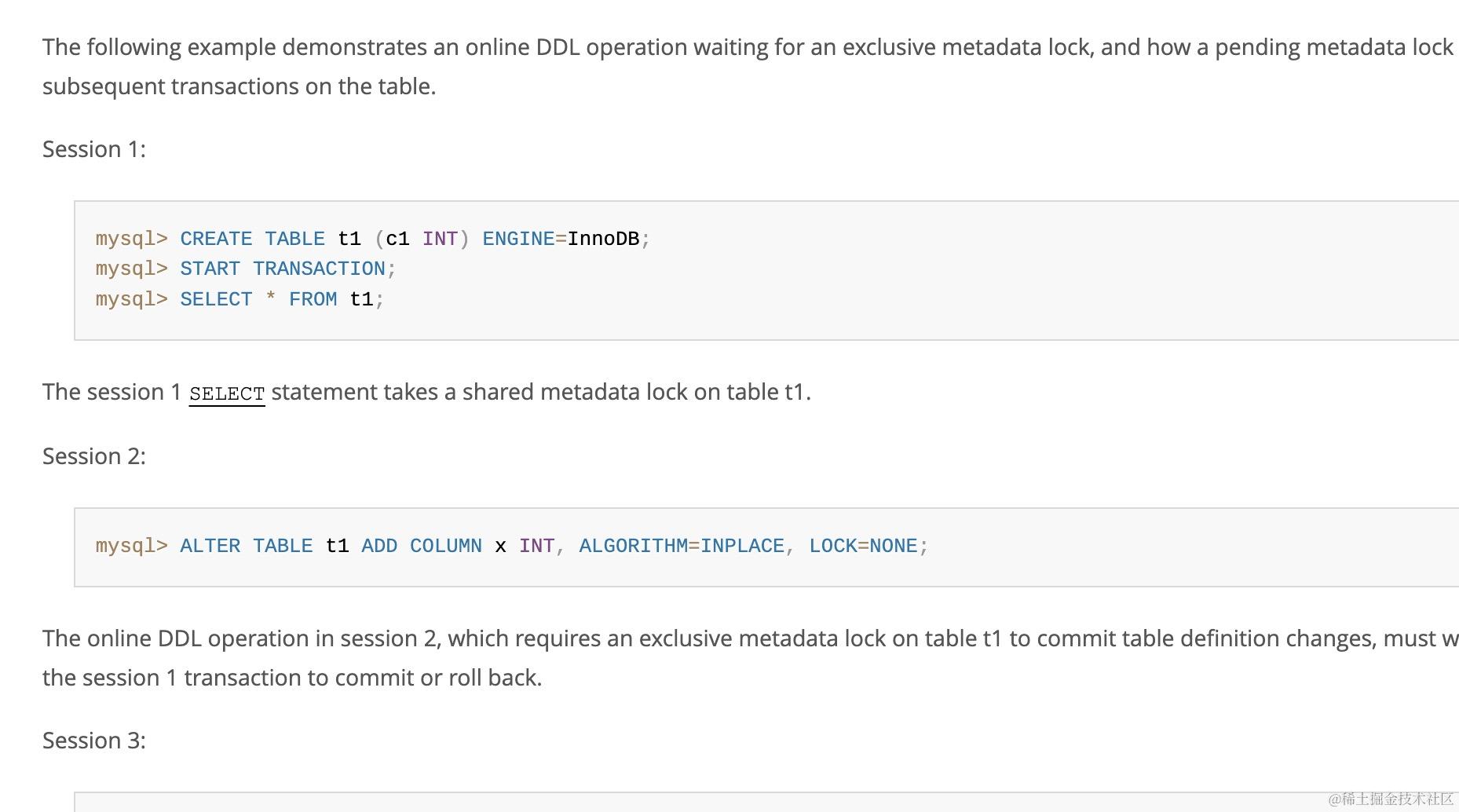
接着我们来看下ddl时使用inplcae 算法(online ddl)是不是一定不会阻塞业务,其实答案是显而易见的,业务也有可能阻塞,因为online ddl 在提交表定义阶段是会获取MDL排他锁的,如果有其他事务获取了MDL读锁,那么online ddl 语句也会阻塞住,从而导致发生在ddl语句执行时间点后面的那些需要获取MDL锁的sql阻塞掉。具体的操作例子可以查看mysql官方给出的一个例子,
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-performance.html
ddl 过程中从库的延迟性
ddl的第二个陷阱是要注意从库的延迟性,比如mysql5.7加新列,虽然默认可以使用inplace算法来让dml语服务器托管网句不阻塞,但是建立新列还是需要表的rebuild操作,如果是大表,整个过程还是很慢的,如果从库只开启了一个线程去执行主从复制,就会导致主从库间出现极大的延迟。
解决办法是开启并行复制,可以用下面的语句在从库上执行,查看从库是否开启了并行复制
SHOW VARIABLES LIKE 'slave_parallel_workers';
online ddl Duplicate entry…错误
虽然使用inplace算法的ddl (online ddl) 可以不阻塞业务操作,但是在大表上执行时,由于ddl过程比较长,还是有可能会出现Duplicate entry 错误。下面我来介绍下它出现的场景,比如一张几千万的表,里面有一个唯一键,在add column ddl期间,对表进行插入,并且插入的值刚好就触发了唯一键约束。那么最后ddl再快完成的时候就会出现这个错误。
这是由于add column ddl期间,会发生表的rebuild,相当于新建一个临时表然后对旧表进行拷贝,但是ddl期间还是允许业务修改,插入数据,所以online ddl将执行期间新的修改记录到一个叫做row_log的对象里,在ddl最后阶段,将mdl锁升级为排它锁,然后将row_log对象中的数据和新表的数据进行合并,这样就达到了ddl期间兼容dml操作的目的。
但是应用row log的过程是不允许报错,如果期间发生了报错就会导致ddl回滚,因为在ddl期间,记录了相同唯一键的数据,所以在应用row log的时候,产生了报错。
官方也给出了online ddl 报错的场景,连接如下
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-failure-conditions.html
其实我认为本质原因是mysql5.7 执行add column 的ddl时间还是太长了,在这么长时间里可能就会发生业务对相同唯一键的插入操作,如果能缩短ddl执行时间应该就能很大程度避免这种问题。
mysql8.0 在add column 时可以采用instance 算法,能达到秒级别的加新字段的操作,理论上可以避免这个错误。
如果不是mysql8.0 ,又想对千万级的大表添加字段,又要避免Duplicate entry 错误,那么可以使用pt-online-schema-change这个工具。
pt-online-schema-change 工具进行字段添加
下面我就来简单的介绍下pt-online-schema-change,它对表结构的修改原理是创建一张新表(拥有最新的表定义),然后在旧表上创建delete,update,insert的触发器,来对增量数据进行更新,对旧表数据采取insert ignore 新表 select 老表 LOCK S 的方式进行分块拷贝,最后拷贝完成后,在一个事务里对旧表进行删除,新表进行重命名,这样就完成了对表结构的变更。
同时在变更期间,你能够通过下面的参数控制从库延迟
-
–max-lag
- 默认1s
- 检查从库延迟的时间,如果超过,则停止copy data,休息–check-interval秒后,再重新开始copy数据
- 查看通过延迟时间,是通过从库show slave status,查看Seconds_Behind_Master
- 如果指定–check-slave-lag,该工具只检查该服务器的延迟,而不是所有服务器。
-
–check-interval
- 从库延迟超过指定的–max-lag,中断copy data休息的时间
- 默认为1s
下面是pt-online-schema-change 语句执行的完整示例,它同时会列出拷贝过程完成的百分比。
pt-online-schema-change --alter "add pkg_source tinyint(2) default 0 not null;" h=主机ip,P=端口,p=密码,u=用户名,D=数据库名,t=表明 --recursion-method=none --execute --statistics
如果你的ddl需要拷贝表,那么用pt-online-schema-change 工具再合适不过了。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
