
文章目录
-
- MySQL 索引分类
-
- 1、按存储方式区分
-
- (1)B+Tree 索引
-
- 1、BTree
- 2、B+Tree
- 3、BTree 个 B+Tree 的主要区别
- 4、MySQL为什么选择B+Tree
- (2)哈希索引
-
- 1、哈希索引的特点
- 2、使用逻辑区分
-
- (1)普通索引
- (2)唯一索引
- (3)主键索引
- (4)全文索引
- 3、按实际的使用情况区分
-
- (1)单列索引
- (2)组合索引
MySQL 索引分类
索引的类型和存储引擎有关,每种存储引擎所支持的索引类型不一定完全相同。MySQL 中的索引,可以从存储方式、使用逻辑和实际使用等不同角度来进行分类
1、按存储方式区分
- 索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。
- 这样的话,索引是使用过程中,就要产生磁盘对索引文件的
I/O消耗,相对于内存存取的消耗,I/O存取的消耗要更高。所以评价索引的优劣最重要的指标,就是在查找过程中磁盘I/O操作次数的复杂度,而索引的本质都是基于某种数据结构来设计的,所以,索引的数据结构要尽量减少查找过程中磁盘I/O的存取次数 - 根据数据结构存储方式的不同,
MySQL中常用的索引,在物理上分为B+Tree索引 和HASH索引两类,两种不同类型的索引各有其不同的适用范围
(1)B+Tree 索引
1、BTree
B+Tree 是BTree 的一种特殊变种
- BTree 是一个 多路平衡查找树(Balance Tree),多路也就是多叉的意思
- 所有叶子节点在同一高度,保证数据有序
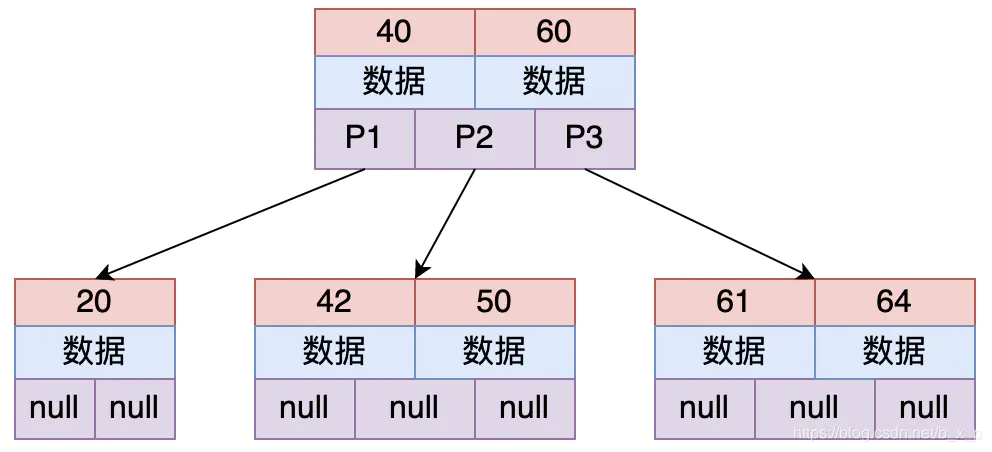
假设要从图中查找id = X的数据,BTREE 搜索过程如下:
- 取出根磁盘块,加载
40和60两个关键字。 - 如果
X = 40,则命中;如果X 走60走P1;如果40XP2;如果X = 60,则命中;如果X > 60走P3。 - 根据以上规则命中后,接下来加载对应的数据, 数据区中存储的是具体的数据或者是指向数据的指针。
2、B+Tree
B+Tree 在原有 BTree 的基础上补充了如下特性:
-
B+Tree根节点和支节点没有数据区,数据data全部存储在叶子节点中; - 每一个父节点的值,都包含在叶子节点中,是叶子节点中==最大(或最小)==的元素;
- 每一个叶子节点,都持有一个指向下一个叶子节点的指针,形成了有序链表
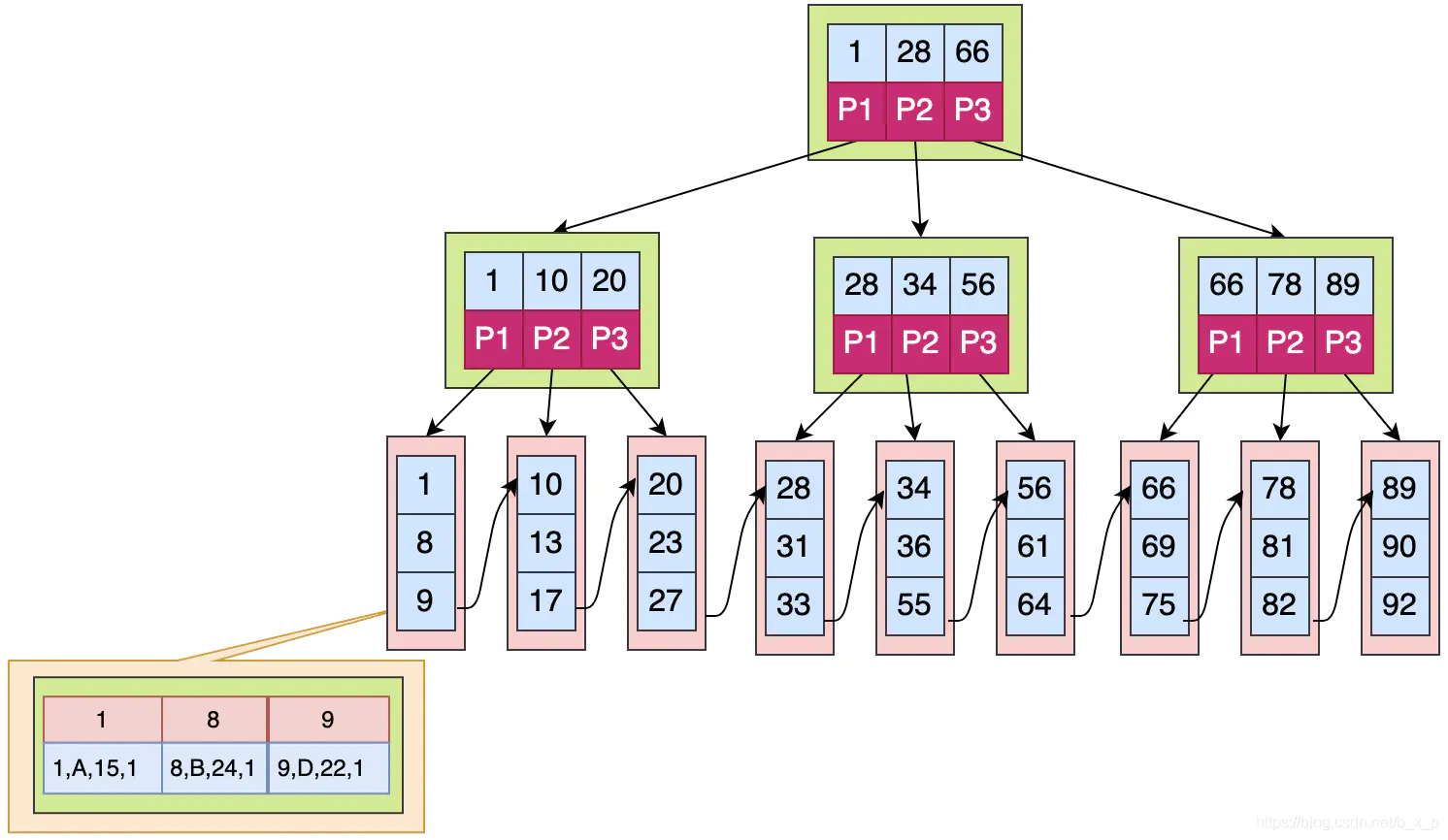
假设为字段ID添加索引,搜索X = 1的数据,**B+TREE** 搜索过程如下:
- 取出根磁盘块,加载
1,28,66三个关键字。 -
X 走P1,取出磁盘块,加载1,10,20三个关键字。 -
X 走P1,取出磁盘块,加载1,8,9三个关键字。 - 已经到达叶子节点,命中
1,加载对应数据节点
3、BTree 个 B+Tree 的主要区别
-
BTree的数据(或指向数据的指针)存在每个节点里,而B+Tree的数据(或指向数据的指针)仅存在叶子节点里,非叶子节点只有索引。 -
BTree的查找,可能会在任意一个节点停止,而B+Tree的查找相对稳定。 -
B+Tree的非叶子节点可以存储更多的索引值,阶数更高 -
B+Tree的叶子节点使用双向链表链接,提高顺序查询效率 - 相比于
BTree,B+Tree在区间查找方面更胜一筹
4、MySQL为什么选择B+Tree
-
B+Tree**全表扫描能力更强。**如果我们要根据索引去进行数据表的扫描,如果基于BTREE进行扫描,需要把整棵树遍历一遍,而B+TREE只需要遍历所有叶子节点即可(叶子节点之间形成有序列表)。 -
B+Tree排序能力更强 -
B+TREE**磁盘读写能力更强。**他的根节点和枝节点不保存数据区,所以根节点和枝节点同样大小的情况下,保存的关键字要比BTREE要多。所以,B+TREE读写一次磁盘加载的关键字比BTREE更多。 -
B+Tree查询性能稳定。B+Tree数据只保存在叶子节点,每次查询数据,查询IO次数一定是稳定的
(2)哈希索引
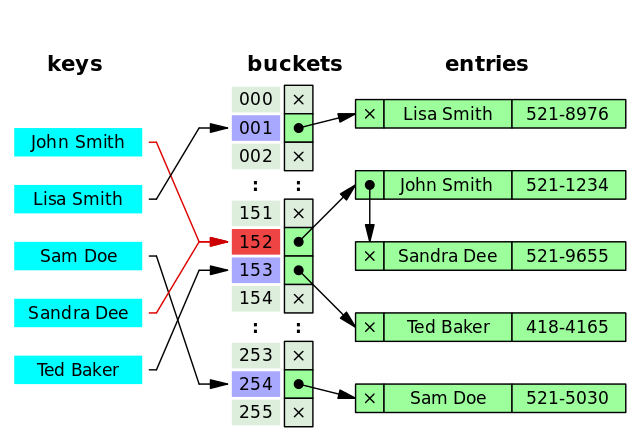
- 哈希索引也称为散列索引或
HASH索引。MySQL目前仅有MEMORY存储引擎和HEAP存储引擎支持这类索引。 - 哈希索引,是基于哈希表实现的一种索引结构。将字段的内容(
key)通过哈希算法,计算该字段的哈希值,用于访问哈希表结构中的对应索引,该索引指向数据行
1、哈希索引的特点
- 无法用于排序与分组;
- 只支持精确查找,无法用于部分查找和范围查找。
-
InnoDB存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在B+Tree索引之上再创建一个哈希索引,这样就让B+Tree索引具有哈希索引的优点,比如:快速的精准查找
2、使用逻辑区分
根据索引的具体用途,MySQL 中的索引在使用逻辑上分为以下 4 类:
(1)普通索引
- 普通索引也被称为辅助索引。是
MySQL中最基本的索引类型,它没有任何限制,唯一任务就是加快系统对数据的访问速度。 - 普通索引允许在定义索引的列中,插入重复值和空值
- 创建普通索引时,通常使用的关键字是 Index
示例:
在 tb_student 表中的 id 字段上建立名为 index_id 的索引
CREATE INDEX index_id ON tb_student(id);
(2)唯一索引
- 唯一索引与普通索引类似,不同的是,创建唯一性索引的目的:除了提高访问速度以外,同时还能避免数据出现重复。
- 唯一索引列的值必须唯一,允许有空值。如果是组合索引,则列值的组合必须唯一
- 创建唯一索引通常使用 UNIQUE关键字
示例:
在 tb_student 表中的 id 字段上建立名为 index_id 的索引
CREATE UNIQUE INDEX index_id ON tb_student(id);
(3)主键索引
- 主键索引就是专门为主键字段创建的索引,也属于索引的一种。主键索引是一种特殊的唯一索引,不允许值重复或者值为空。
- 创建主键索引通常使用
PRIMARY KEY关键字。不能使用CREATE ``INDEX语句创建主键索引,需要以创建或修改表结构的方式进行添加
示例:
在 tb_student 表中的 id 字段上添加主键索引
ALTER TABLE tb_student ADD PRIMARY KEY (id)
(4)全文索引
- 全文索引主要用来查找文本中的关键字,只能在
CHAR、VARCHAR或TEXT类型的列上创建。全文索引允许在索引列中插入重复值和空值。 - 不过对于大容量的数据表,生成全文索引非常消耗时间和硬盘空间。
- 创建全文索引使用 FULLTEXT关键字
示例:
在 tb_student 表中的 info 字段上建立名为 index_info 的全文索引
CREATE FULLTEXT INDEX index_info ON tb_student(info);
3、按实际的使用情况区分
(1)单列索引
- 单列索引就是索引只包含原表的一个列。在表中的单个字段上创建索引,单列索引只根据该字段进行索引。
- 单列索引可以是普通索引,也可以是唯一性索引,还可以是全文索引。只要保证该索引只对应一个字段即可。
(2)组合索引
- 组合索引也称为复合索引或多列索引。相对于单列索引来说,组服务器托管网合索引是将原表的多个列共同组成一个索引。
- 多列索引是在表的多个字段上创建一个索引。该索引指向创建时对应的多个字段,可以通过这几个字段进行查询。但是,只有查询条件中使用了这些字段中第一个字段时,索引才会被使用
示例:
在 tb_student 表中的 name 和 address 字段上建立名为 index_na 的索引。该索引创建好了以后,查询条件中必须有 name 字段才能使用索引
CREATE INDEX index_na ON tb_student(name,address);
- 一个表可以有多个单列索引,但这些索引不是组合索引。一个组合索引实质上为表的查询提供了多个索引,以此来加快查询速度。
- 比如:在一个表中创建了一个组合索引
(c1,c2,c3),在实际查询中,系统用来实际加速的索引有三个:单个索引(c1)、双列索引(c1,c2)和多列索引(c1,c2,c3)
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 解决因对EFCore执行SQL方法不熟练而引起的问题
前言 本文测试环境:VS2022+.Net7+MySQL 因为我想要实现使用EFCore去执行sql文件,所以就用到了方法ExecuteSqlAsync,然后就产生了下面的问题,首先因为方法接收的参数是一个FormattableString,它又是一个抽象类,…
