

StoneDB开源地址
https://github.com/stoneatom/stonedb

作者:张烜玮
当多个事务操作同一行数据时,会出现各种并发问题。MySQL 通过四个隔离级别来解决这些问题:
读未提交隔离级别最宽松,基本上不进行隔离,因此实现非常简单。读提交隔离级别是每次执行语句(包括查询和更新语句)时,都会生成一个一致的视图,以确保当前事务可以看到其他事务提交的数据。可重复读隔离级别的实现是每个事务在打开时都会生成一个一致的视图。当其他事务提交时,它不会影响当前事务中的数据。为了确保这一点,MySQL 通过多版本控制机制 MVCC 实现。串行化隔离级别的隔离级别相对较高,是通过锁定实现的,因此 MySQL 有一套锁定机制。
提交读取和可重复读取隔离级别都依赖于 MVCC 多版本控制机制的实现。今天我们将讨论 MySQL 中的 MVCC 多版本控制机制。

MVCC 基本原理
MVCC 机制使用read-view机制和undo log版本链比较机制,使得不同的事务根据数据版本链比较规则读取相同数据的不同版本。
undo log 版本链
当一个事务被打开时,它首先会申请一个事务 ID:transaction-id
当一个事务修改一行数据时,MySQL 会保留修改前的 undo 回滚日志,并将事务 ID:transaction id 分配给版本记录中的trx_id字段。
将这些 undo 日志连接起来形成历史版本链,如图所示:
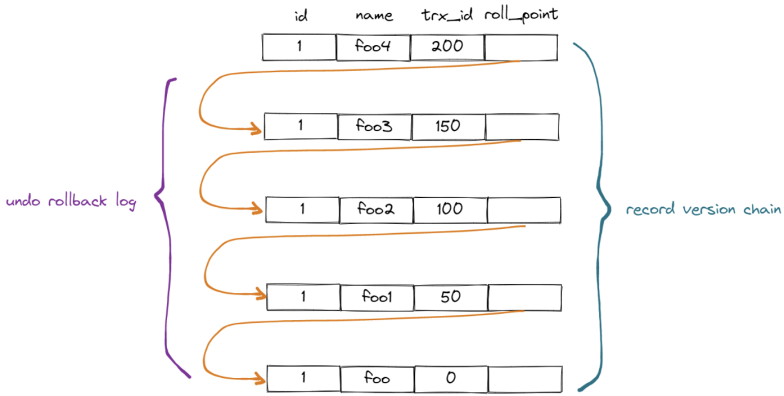
请注意,此处记录的版本并非真实的物理实体。实际上,只有最新的记录存在于真实的物理实体中,其他历史记录都是从 undo 日志中推导出来的。
一致性视图
可重复读隔离级别和读提交隔离级别是通过生成一个一致的视图来实现的,即读视图。什么是一致性视图?
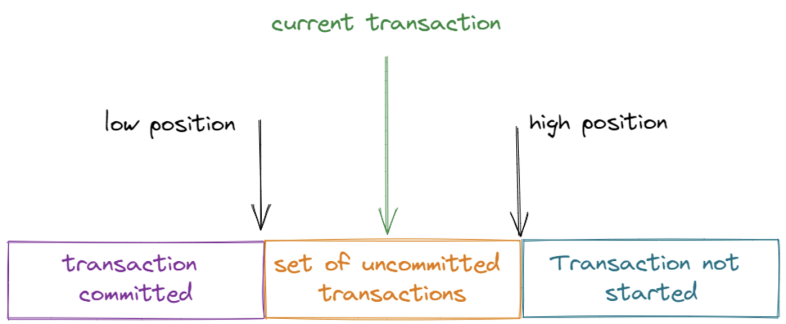
当事务启动时,InnoDB 为事务构造一个数组,以存储事务启动时处于活动状态的所有事务 ID。Active 表示它已启动,但未提交。
数组中 id 的最小值为低位,最大值+1 记录为高位,即一致性视图。
每个事务进行查询时,都会根据一致性视图的可见性规则,推导出撤销日志版本链中对应的数据。
下面我们结合源码分析下一致性视图 ReadView 类的主要构成
classReadView{
...
/**任何trx_id大于等于该值的记录都不应该被读到*/
trx_id_tm_low_limit_id;//highposition
/**任何trx_id小于该值的记录都可以读取到*/
trx_id_tm_up_limit_id;//lowposition
/**生成该ReadView的事务的txn_id.*/
trx_id_tm_creator_trx_id;
/**生成ReadView时,当前系统中所有活跃事务的txn_id列表*/
ids_tm_ids;
}
由分析可知 ReadView 类中的 m_low_limit_id 变量对应的是上图中的高位,m_up_limit_id 变量对应的是低位,在下面具体的案例分析中我们还是使用高位和低位来描述一致性视图 ReadView。

可见性规则的应用
-
如果当前事务
id落在紫色部分,则表示该版本是已提交事务或由当前事务本身生成,并且该数据是可见的。
-
如果当前事务
id落在蓝色部分,则表示该版本是由未来启动的事务生成的,肯定是不可见的。
-
如果当前事务
id位于橙色部分,则包括两种情况:
A.如果行trx_id在数组中,则表示此版本是由尚未提交且不可见的事务生成的。
B.如果行trx_id不在数组中,则表示此版本由已提交的事务生成,可见。
下面我们以可重复读隔离级别为例,分析一些典型的并发事务可见性判断场景。
Case 1
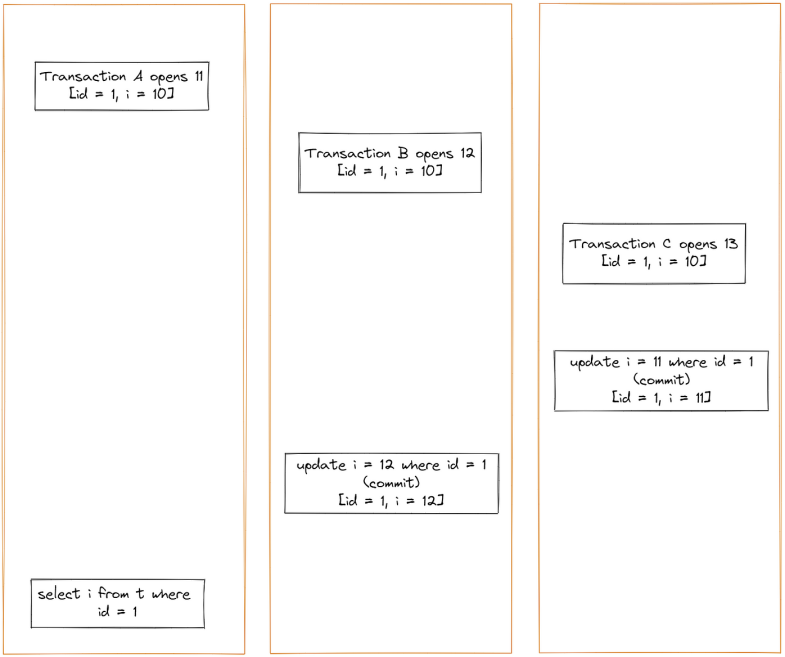
在图中,事务 A 查询的是什么i?让我们先分析一下。
按照从上到下打开事务的顺序,每个事务对应的一致性视图如下:
一致性视图数组transaction A [11]
一致性视图数组transaction B [11,12]
一致性视图数组transaction C [11,12,13]
当事务 A 查询时,undo 日志版本链为:
{trx_id=11,id=1,i=10,roll_pointer=0}{trx_id=13,id=1,i=11,roll_pointer=1}{trx_id=12,id=1,i=12,roll_pointer=2}
{}表示版本记录。
表示回滚日志 undo log。
当事务 A 查询时,事务 B 和事务 C 属于未来事务,对事务 A 不可见。
因此,事务 A 查询的数据是通过按照 undo 日志不断向前回滚和回滚到最新数据记录获得的:i=10。
Case 2
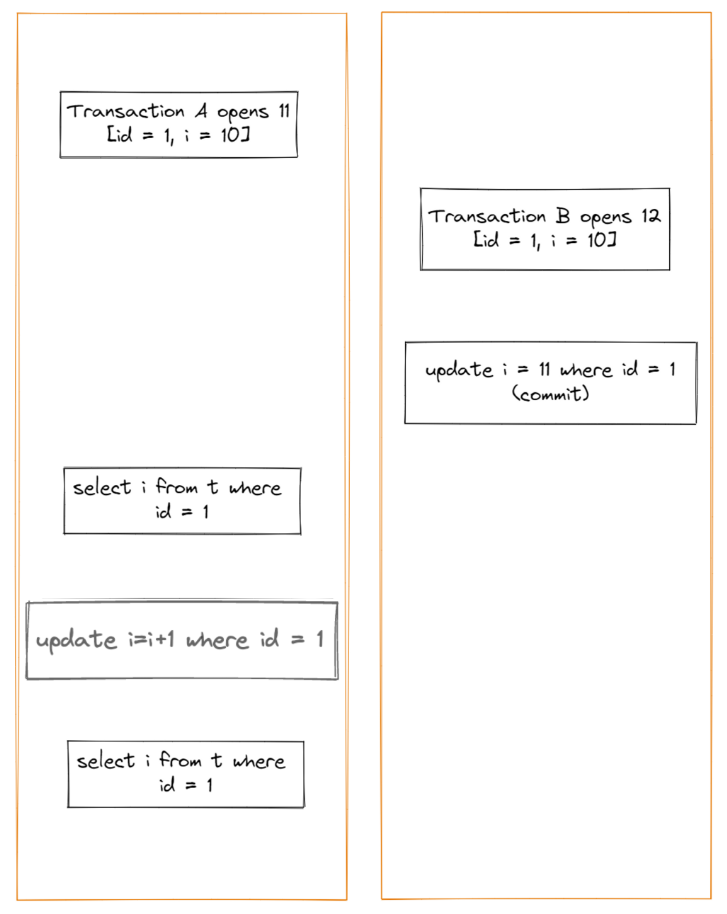
事务 A 的两次 SELECT 的查询结果分别是什么?
根据 ReadView 的可见性规则,对于事务 A,事务 B 是一个未来的事务,对事务 A 不可见,所以第一次的查询结果为 i=10。
对于第二次的查询,按照可重复读隔离级别的可见性规则,事务 A 应该无法感知事务 B 中的更新,但是查询结果是 i=12 而不是 i=11,这是为什么呢?
因为当事务 A 要去更新数据的时候,就不能再在历史版本上更新了,否则事务 B 的更新就丢失了。因此,事务 A 此时的 update i=i+1 必须应该在当前最新版本数据 (即 i=11) 的基础上进行的操作。所以,这里就用到了这样一条规则:更新数据都是先读后写的,而这个读,只能读当前的值,称为“「当前读」”(与之对应的是走 MVCC 逻辑的快照读)。
所以只要事务中有 update 语句,则 update 语句以当前读取模式读取版本记录中的最新数据,然后执行更新操作,因此上图中的查询结果为 i=12。
以下两种查询方法也是当前读取:
selectkfromtwhereid=1lockinsharemode;
selectkfromtwhereid=1forupdate;
以上是 MVCC 机制的可见性判断,其是可重复读和读提交隔离级别的实现原理。(下文以 RR 和 RC 代替)

ReadView 相关源码分析
ReadView 创建
当我们在进行查询操作的时候,在我们开启一个事务的时候,系统会依据隔离级别,在相应的位置通过trx_assign_read_view 函数来创建一个属于该事务的 ReadView,在该事务的执行周期内会对于每个要访问的记录与该 ReadView 进行可见性判断。
对于 RC 隔离级别和 RR 隔离级别下,ReadView 的产生时机不同:
-
RR 只在第一次进行快照读 SELECT 时生成一个 ReadView
-
RC 则需要在每一次进行快照读 SELECT 前生成一个 ReadView。
我们依然以 RR 为例分析源码流程:
在事务启动的 trans_begin 函数最终会调用到innobase_start_trx_and_assign_read_view函数
以下代码取自该函数:
if(trx->isolation_level==TRX_ISO_REPEATABLE_READ){
trx_assign_read_view(trx);
trx_assign_read_view调用view_o服务器托管网pen函数用来创建一个 Read View,具体为其成员变量复制是在prepare 函数中完成的:
voidReadView::prepare(trx_id_tid){
ut_ad(trx_sys_mutex_own());
m_creator_trx_id=id;
//与purge策略相关,本文暂不讨论
m_low_limit_no=trx_get_serialisation_min_trx_no();
m_low_limit_id=trx_sys_get_next_trx_id_or_no();
//将当前只读事务的id拷贝到view中的m_ids。
if(!trx_sys->rw_trx_ids.empty()){
copy_trx_ids(trx_sys->rw_trx_ids);
}else{
m_ids.clear();
}
...
}
可见性判断
上文讲解了建立 ReadView 的过程,使用聚簇索引判断可见性的函数入口是lock_clust_rec_cons_read_sees,判断逻辑即为前文的 ReadView 可见性规则,篇幅有限此处不展开。
我们主要讨论查询语句的查询字段只有二级索引的情况,那么系统只会读取二级索引的页的记录,不会回表去读取聚簇索引的页记录。但是,版本链的头结点在聚簇索引中,不在二级索引中,通过二级索引的记录无法直接找到版本链。在这种情况下如何使用 MVCC?
二级索引页的头部有一个 page_max_trx_id 表示修改过该页的最大事务 id。
执行 SELECT 时命中该页,如果 ReadView 的 min_trx_id 比该页的 page_max_trx_id 大,说明这个二级索引页修改的事务已经提交,该页的所有记录对本事务的本次查询可见。
否则,就要对“在二级索引页找到的匹配条件的记录”进行回表操作,在聚簇索引对应的记录中按照之前所说的规则找到可见版本:
boollock_sec_rec_cons_read_sees(
constrec_t*rec,
constdict_index_t*index,
constReadView*view)
{
...
//取索引页上的PAGE_MAX_TRX_ID字段。
trx_id_tmax_trx_id=page_get_max_trx_id(page_align(rec));
ut_ad(max_trx_id>0);
return(view->sees(max_trx_id));
}
ReadView:sees直接返回PAGE_MAX_TRX_ID是否小于 ReadView 初始化时的最小事务 id,也就是判断修改页上记录的最大事务 id 是否在快照生成的时候已经提交了。
boolsees(trx_id_tid)const{
return(id}
参考文献
MySQL 官方文档[1]
数据库内核月报[2]
Reference
MySQL 官方文档: https://www.notion.so/MySQL-MVCC-b33cae19f3224bf2925143c2b1d85a61?pvs=21
[2]
数据库内核月报: http://mysql.taobao.org/monthly/2015/12/01/
StoneDB 介绍
同时,StoneDB 使用多存储引擎架构的设计,事务引擎具有数据强一致特性,具备完整的事务并发处理能力,使得 StoneDB 可以替代 MySQL 数据库满足在线事务处理场景的需求,使用 MySQL 的用户,通过 StoneDB 可以实现 TP+AP 混合负载,分析性能提升 10倍以上,不需要进行数据迁移,也无需与其他 AP 集成,弥补 MySQL 分析领域的空白。
 Github:https://github.com/stoneatom/stonedb
Github:https://github.com/stoneatom/stonedb Gitee:https://gitee.com/StoneDB/stonedb
Gitee:https://gitee.com/StoneDB/stonedb 社区官网:https://stonedb.io/
社区官网:https://stonedb.io/ 哔哩哔哩:https://space.bilibili.com/1154290084
哔哩哔哩:https://space.bilibili.com/1154290084 Twitter:https://twitter.com/StoneDataBase
Twitter:https://twitter.com/StoneDataBase Linkedin:https://www.linkedin.com/in/stonedb/
Linkedin:https://www.linkedin.com/in/stonedb/加入微信群:添加社区助理-小石侠;加入钉钉群:扫描下方钉钉群二维码。







本文分享自微信公众号 – StoneDB(StoneDB2021)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 【深入浅出 Yarn 架构与实现】6-3 NodeManager 分布式缓存
不要跳过这部分知识,对了解 NodeManager 本地目录结构,和熟悉 Container 启动流程有帮助。 一、分布式缓存介绍 主要作用就是将用户应用程序执行时,所需的外部文件资源下载缓存到各个节点。YARN 分布式缓存工作流程如下: 客户端将应用程序所需…
