
第一版的NativeBuffering([上篇]、[下篇])发布之后,我又对它作了多轮迭代,对性能作了较大的优化。比如确保所有类型的数据都是内存对齐的,内部采用了池化机器确保真正的“零内存分配”等。对于字典类型的数据成员,原来只是“表现得像个字段”,这次真正使用一段连续的内存构架了一个“哈希表”。我们知道对于每次.NET新版本的发布,原生的JSON序列化(System.Text.Json)的性能都作了相应的提升,本篇文章通过具体的性能测试比较NativeBuffering和它之间的性能差异。
一、一种“特别”的序列化解决方案
二、Source Generator驱动的编程模式
三、序列化性能比较
四、原生类型性能“友好”
五、Unmanaged 类型“性能加速”
六、无需反序列化
七、数据读取的成本
一、一种“特别”的序列化解决方案
一般的序列化/发序列化都是数据对象和序列化结果(字符串或者单纯的字节序列)之间的转换。以下图为例,我们定义了一个名为Person的数据类型,如果采用典型的JSON序列化方案,序列化器会将该对象转换成一段具有JSON格式的字符串,这段字符串可以通过反序列化的方式“恢复”成一个Person对象。
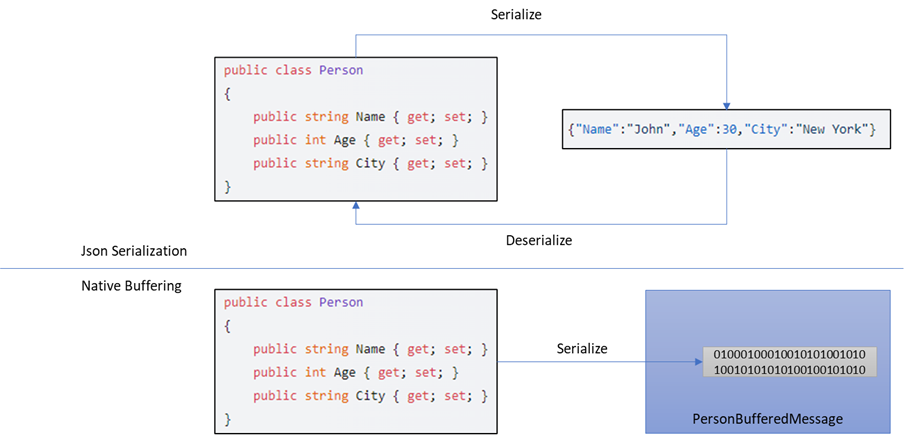
如果采用NativeBuffering序列化解决方案,它会引入一个新的数据类型PersonBufferedMessage,我们采用Source Generator的方式根据Person的数据结构自动生成PersonBufferedMessage类型。除此之外,PersonBufferedMessage还会为Person生成额外的方式将自身对象以字节的方式写入提供的缓冲区。
换句话说,Person对象会转换成一段连续的字节序列化,PersonBufferedMessage就是对这段字节序列的封装。它的数据成员(Name、Age和City)不再定义成“地段”,而被定义成“只读属性”,它能找到对应的数据成员在这段字节序列中的位置,从而将其读出来。为了提供数据读取的性能,所有的数据成员在序列化字节序列中总是按照“原生(Native)”的形式存储,并且确保是内存对齐的。也正是这个原因,NativeBuffering并不是一个跨平台的序列化解决方案。
二、Source Generator驱动的编程模式
NativeBuffering的整个编程围绕着“Source Generator”进行的,接下来我们简单演示一下如何使用它。我们在一个控制台程序中添加NativeBuffering相关的两个NuGet包NativeBuffering和NativeBuffering.Generator(使用最新版本),并定义如下这个数据类型Person。由于我们需要为Person生成额外的类型成员,我们必须将其定义成partial class。
[BufferedMessageSource] public partial class Person { public string Name { get; set; } public int Age { get; set; } public string[] Hobbies { get; set; } public string Address { get; set; } public string PhoneNumber { get; set; } public string Email { get; set; } public string Gender { get; set; } public string Nationality { get; set; } public string Occupation { get; set; } public string EducationLevel { get; set; } public string MaritalStatus { get; set; } public string SpouseName { get; set; } public int NumberOfChildren { get; set; } public string[] ChildrenNames { get; set; } public string[] LanguagesSpoken { get; set; } public bool HasPets { get; set; } public string[] PetNames { get; set; } public static Person Instance = new Person { Name = "Bill", Age = 30, Hobbies = new string[] { "Reading", "Writing", "Coding" }, Address = "123 Main St.", PhoneNumber = "555-555-5555", Email = "bill@gmail.com", Gender = "M", Nationality = "China", Occupation = "Software Engineer", EducationLevel = "Bachelor's", MaritalStatus = "Married", SpouseName = "Jane", NumberOfChildren = 2, ChildrenNames = new string[] { "John", "Jill" }, LanguagesSpoken = new string[] { "English", "Chinese" }, HasPets = true, PetNames = new string[] { "Fido", "Spot" } }; }
我们在类型上标注BufferedMessageSourceAttribute特性将其作为BufferedMessage的“源”。此时如果我们查看VS的Solution Explorer,就会从项目的Depedences/Analyers/NativeBuffering.Generator看到生成的两个.cs文件。我们使用的PersonBufferedMessage就定义在PersonBufferedMessage.g.cs文件中。为Person额外添加的类型成员就定义在Person.g.cs文件中。
我们使用下的代码来演示针对Person和PersonBuffered服务器托管网Message的序列化和反序列化。如下面的代码片段所示,我们利用Instance静态属性得到Person单例对象,直接调用其WriteToAsync方法(Person.g.cs文件会使Person类型实现IBufferedObjectSource接口,WriteToAsync方法使针对该接口定义的扩展方法)对自身进行序列化,并将作为序列化结果的字节序列存储到指定的文件(person.bin)文件中。
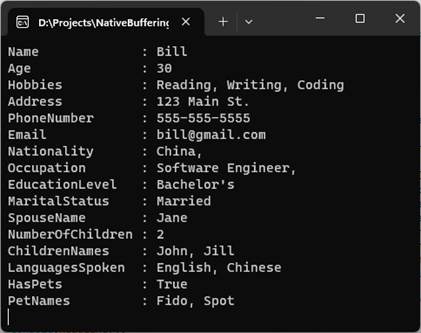
using NativeBuffering; var fileName = "person.bin"; await Person.Instance.WriteToAsync(fileName); using (var pooledBufferedMessage = await BufferedMessage.LoadAsync(fileName)) { var bufferedMessage = pooledBufferedMessage.BufferedMessage; Console.WriteLine( @$"{nameof(bufferedMessage.Name),-17}: {bufferedMessage.Name} {nameof(bufferedMessage.Age),-17}: {bufferedMessage.Age} {nameof(bufferedMessage.Hobbies),-17}: {string.Join(", ", bufferedMessage.Hobbies)} {nameof(bufferedMessage.Address),-17}: {bufferedMessage.Address} {nameof(bufferedMessage.PhoneNumber),-17}: {bufferedMessage.PhoneNumber} {nameof(bufferedMessage.Email),-17}:{bufferedMessage.Email} {nameof(bufferedMessage.Nationality),-17}:{bufferedMessage.Nationality}, {nameof(bufferedMessage.Occupation),-17}:{bufferedMessage.Occupation}, {nameof(bufferedMessage.EducationLevel),-17}:{bufferedMessage.EducationLevel} {nameof(bufferedMessage.MaritalStatus),-17}:{bufferedMessage.MaritalStatus} {nameof(bufferedMessage.SpouseName),-17}:{bufferedMessage.SpouseName} {nameof(bufferedMessage.NumberOfChildren),-17}:{bufferedMessage.NumberOfChildren} {nameof(bufferedMessage.ChildrenNames),-17}: {string.Join(", ", bufferedMessage.ChildrenNames)} {nameof(bufferedMessage.LanguagesSpoken),-17}: {string.Join(", ", bufferedMessage.LanguagesSpoken)} {nameof(bufferedMessage.HasPets),-17}:{bufferedMessage.HasPets} {nameof(bufferedMessage.PetNames),-17}: {string.Join(", ", bufferedMessage.PetNames)}"); }
然后我们调用BufferedMessage的静态方法LoadAsync加载该文件的内容。该方法会返回一个PooledBufferedMessage对象,它的BufferedMessage返回我们需要的PersonBufferedMessage对象。PersonBufferedMessage具有与Person一致的数据成员,我们将它们的内容一一输出,可以看出PersonBufferedMessage承载的内容与Person对象使完全一致的。
NativeBuffering之所以能供实现真正意义的“零内存分配”,得益于对“池化机制”的应用。LoadAsync方法返回的PooledBufferedMessage使用一段池化的缓存区来存储序列化的字节,当我们不再使用的时候,需要调用其Dispose方法缓存区释放到缓存池内。
三、序列化性能比较
接下来我们以就以上面定义的Person类型为例,利用BenchmarkDotNet比较一下NativeBuffering与JSON序列化在性能上的差异。如下面的代码片段所示,针对JSON序列化的Benchmark方法直接调用JsonSerializer的Serialize方法将Person单例对象序列化成字符串。
[MemoryDiagnoser] public class Benchmark { private static readonly Funcint, byte[]> _bufferFactory = ArrayPoolbyte>.Shared.Rent; [Benchmark] public string SerializeAsJson() => JsonSerializer.Serialize(Person.Instance); [Benchmark] public void SerializeNativeBuffering() { var arraySegment = Person.Instance.WriteTo(_bufferFactory); ArrayPoolbyte>.Shared.Return(arraySegment.Array!); } }
在针对NativeBuffering的Benchmark方法中,我们调用Person单例对象的WriteTo扩展方法对齐进行序列化,并利用一个ArraySegment结构返回序列化结果。WriteTo方法具有一个类型为Funcint, byte[]>的参数,我们使用它来提供一个存放序列化结果的字节数组。作为Funcint, byte[]>输入参数的整数代表序列化结果的字节长度,这样我们才能确保提供的字节数组具有充足的存储空间。
为了避免内存分配,我们利用这个委托从ArrayPoolbyte>.Shared表示的“数组池”中借出一个大小适合的字节数组,并在完成序列化之后将其释放。这段性能测试结果如下,可以看出从耗时来看,针对NativeBuffering的序列化稍微多了一点,但是从内存分配来看,它真正做到了内存的“零分配”,而JSON序列化则分配了1K多的内存。

四、原生类型性能“友好”
从上面展示的性能测试结果可以看出,NativeBuffering在序列化上确实可以不用分配额外的内存,但是耗时似乎多了点。那么是否意味着NativeBuffering不如JSON序列化高效吗?其实也不能这么说。NativeBuffering会使用一段连续的内存(而不是多段缓存的拼接)来存储序列化结果,所以它在序列化之前需要先计算字节数。由于Person定义的绝大部分数据成员都是字符串,这导致了它需要计算字符串编码后的字节数,这个计算会造成一定的耗时。
所以字符串不是NativeBuffering的强项,对于其他数据类型,NativeBuffering性能其实很高的。现在我们重新定义如下这个名为Entity的数据类型,它将常用的Primitive类型和一个字节数组作为数据成员
[BufferedMessageSource] public partial class Entity { public byte ByteValue { get; set; } public sbyte SByteValue { get; set; } public short ShortValue { get; set; } public ushort UShortValue { get; set; } public int IntValue { get; set; } public uint UIntValue { get; set; } public long LongValue { get; set; } public ulong ULongValue { get; set; } public float FloatValue { get; set; } public double DoubleValue { get; set; } public decimal DecimalValue { get; set; } public bool BoolValue { get; set; } public char CharValue { get; set; } public byte[] Bytes { get; set; } public static Entity Instance = new Entity { ByteValue = 1, SByteValue = 2, ShortValue = 3, UShortValue = 4, IntValue = 5, UIntValue = 6, LongValue = 7, ULongValue = 8, FloatValue = 9, DoubleValue = 10, DecimalValue = 11, BoolValue = true, CharValue = 'a', Bytes = Enumerable.Range(0, 128).Select(it => (byte)it).ToArray() }; }
然后我们将性能测试的两个Benchmark方法使用的数据类型从Person改为Entity。
[MemoryDiagnoser] public class Benchmark { private static readonly Funcint, byte[]> _bufferFactory = ArrayPoolbyte>.Shared.Rent; [Benchmark] public string SerializeAsJson() => JsonSerializer.Serialize(Entity.Instance); [Benchmark] public void SerializeNativeBuffering() { var arraySegment = Entity.Instance.WriteTo(_bufferFactory); ArrayPoolbyte>.Shared.Return(arraySegment.Array!); } }
再来看看如下的测试结果,可以看出NativeBuffering序列化的耗时差不多是JSON序列化的一半,并且它依然没有任何内存分配。

五、Unmanaged 类型“性能加速”
NativeBuffering不仅仅对Primitive类型“友好”,对于自定义的Unmanaged结构,更能体现其性能优势。原因很简单,Unmanaged类型(含Primitive类型和自定义的unmanaged结构)的内存布局就是连续的,NativeBuffering在进行序列化的适合不需要对它进行“分解”,直接拷贝这段内存的内容就可以了。
作为演示,我们定义了如下这个Foobarbazqux结构体,可以看出它满足unmanaged结构的要求。作为序列化数据类型的Record中,我们定义了一个Foobarbazqux数组类型的属性Data。Instance静态字段表示的单例对象的Data属性包含100个Foobarbazqux对象。
[BufferedMessageSource] public partial class Record { public Foobarbazqux[] Data { get; set; } = default!; public static Record Instance = new Record { Data = Enumerable.Range(1, 100).Select(_ => new Foobarbazqux(new Foobarbaz(new Foobar(111, 222), 1.234f), 3.14d)).ToArray()}; } public readonly record struct Foobar(int Foo, long Bar); public readonly record struct Foobarbaz(Foobar Foobar, float Baz); public readonly record struct Foobarbazqux(Foobarbaz Foobarbaz, double Qux);
我们同样只需要将性能测试的数据类型改成上面定义的Record就可以了。
[MemoryDiagnoser] public class Benchmark { private static readonly Funcint, byte[]> _bufferFactory = ArrayPoolbyte>.Shared.Rent; [Benchmark] public string SerializeAsJson() => JsonSerializer.Serialize(Record.Instance); [Benchmark] public void SerializeNativeBuffering() { var arraySegment = Record.Instance.WriteTo(_bufferFactory); ArrayPoolbyte>.Shared.Return(arraySegment.Array!); } }
这次NativeBuffering针对JSON序列化的性能优势完全是“碾压式”的。耗时:72us/3us。JSON序列化不仅带来了26K的内存分配,还将部分内存提升到了Gen1。

六、无需反序列化
对于序列化来说,NativeBuffering不仅仅可以避免内存的分配。如果不是大规模涉及字符串,它在耗时方面依然具有很大的优势。即使大规模使用字符串,考虑到JSON字符串最终还是需要编码转换成字节序列化,两者之间的总体耗时其实差别也不大。NativeBuffering针对反序列化的性能优势更是毋庸置疑,因为我们使用的BufferedMessage就是对序列化结果的封装,所以反序列化的成本几乎可以忽略(经过测试耗时在几纳秒)。
为了让大家能够感觉到与JSON分序列化的差异,我们将读取数据成员的操作也作为反序列化的一部分。如下面这个Benchmark所示,我们在初始化自动执行的Setup方法中,针对同一个Entity对象的两种序列化结果(字节数组)存储在_encodedJson 和_payload字段中。
[MemoryDiagnoser] public class Benchmark { private byte[] _encodedJson = default!; private byte[] _payload = default!; [GlobalSetup] public void Setup() { _encodedJson = Encoding.UTF8.GetBytes(JsonSerializer.Serialize(Entity.Instance)); _payload = new byte[Entity.Instance.CalculateSize()]; Person.Instance.WriteToAsync(new MemoryStream(_payload), true); } [Benchmark] public void DeserializeFromJson() { var entity = JsonSerializer.Deserialize(Encoding.UTF8.GetString(_encodedJson))!; Process(entity.ByteValue); Process(entity.SByteValue); Process(entity.ShortValue); Process(entity.UShortValue); Process(entity.IntValue); Process(entity.UIntValue); Process(entity.LongValue); Process(entity.ULongValue); Process(entity.FloatValue); Process(entity.DoubleValue); Process(entity.DecimalValue); Process(entity.BoolValue); Process(entity.CharValue); Process(entity.Bytes); } [Benchmark] public void DeserializeFromNativeBuffering() { unsafe { fixed (byte* _ = _payload) { var entity = new EntityBufferedMessage(new NativeBuffer(_payload)); Process(entity.ByteValue); Process(entity.SByteValue); Process(entity.ShortValue); Process(entity.UShortValue); Process(entity.IntValue); Process(entity.UIntValue); Process(entity.LongValue); Process(entity.ULongValue); Process(entity.FloatValue); Process(entity.DoubleValue); 服务器托管网Process(entity.DecimalValue); Process(entity.BoolValue); Process(entity.CharValue); Process(entity.Bytes); } } } [MethodImpl(MethodImplOptions.NoInlining)] private void Process(T expected) { } }
针对JSON反序列化的Benchmark方法利用JsonSerializer将解码生成的字符串反序列化成Entity对象,并调用Process方法读取每个数据成员。在针对NativeBuffering的Benchmark方法中,我们需要创建一个fixed上下文将字节数组内存地址固定,因为BufferedMessage的读取涉及很多Unsafe的内存地址操作,然后将这个字节数组封装成NativeBuffer对象,并据此将EntityBufferedMessage创建出来。这个方法的耗时花在后面针对数据成员的读取上。如下所示的两种“反序列”方式的测试结果。从如下所示的测试结果可以看出相对于NativeBuffering的无需反序列化,JSON反序列化的成本还是巨大的,不仅反映在耗时上,同时也反映在内存分配上。

七、数据读取的成本
上面的测试结果也体现了NativeBuffering针对数据读取的成本。和普通类型直接读取字段的值不同,NativeBuffering生成的BufferedMessage对象是对一段连续字节序列的封装,此字节序列就是序列化的结果。如下所示的是这段字节序列的布局:整个序列包括两个部分,后面一部分依次存储每个字段的内容,前面一部分则存储每个字段内容在整个字节序列的位置(偏移量)。
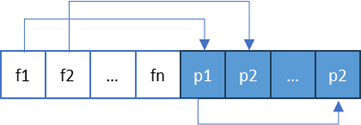
BufferedMessage的每个数据成员都是只读属性,针对数据成员的读取至少需要两个步骤:
- 根据数据成员的序号读取存储内容的偏移量;
- 将偏移量转换成内存地址,结合当前数据类型将数据读出来;
所以NativeBuffering最大的问题就是:读取数据成员的性能肯定比直接读取字段值要高。从上面的测试结果大体可以测出单次读取耗时大体在1-2纳米之间(24.87ns包括创建EntityBufferedMessage和调用空方法Process的耗时),也就是说1秒中可以完成5-10亿次读取。我想这个读取成本大部分应用是可以接受的,尤其是相对于它在序列化/反序列化在耗时和内存分配带来的巨大优势来说,读取数据成员带来时间损耗基本上可以忽略了。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
