
系列文章目录和关于我
零丶引入
在前面《Netty源码学习4——服务端是处理新连接的&netty的reactor模式》的学习中,我们了解到服务端是如何处理新连接的,即注册ServerSocketChannel对accept事件感兴趣,然后包装ServerSocketChannel为NioServerSockectChannel,最后由主Reactor在循环中利用selector进行IO多路复用产生事件,如果产生accept事件那么调用ServerSocketChannel#accept将其结果(SocketChannel)包装为NioSockectChannel,然后传播channelRead事件,然后由ServerBootstrapAcceptor 将NioSockectChannel注册到子Reactor中。

也就是说ServerBootstrapAcceptor 是派活的大哥,属于main reactor,而真正干活的是子reactor中的NioEventLoop,它们会负责后续的数据读写与写入。
这一篇我们就来学习NioSockectChannel是如何读取数据的。
一丶子Reactor打工人NioEventLoop处理Read事件
源码学习的入口和服务端处理accept事件一致
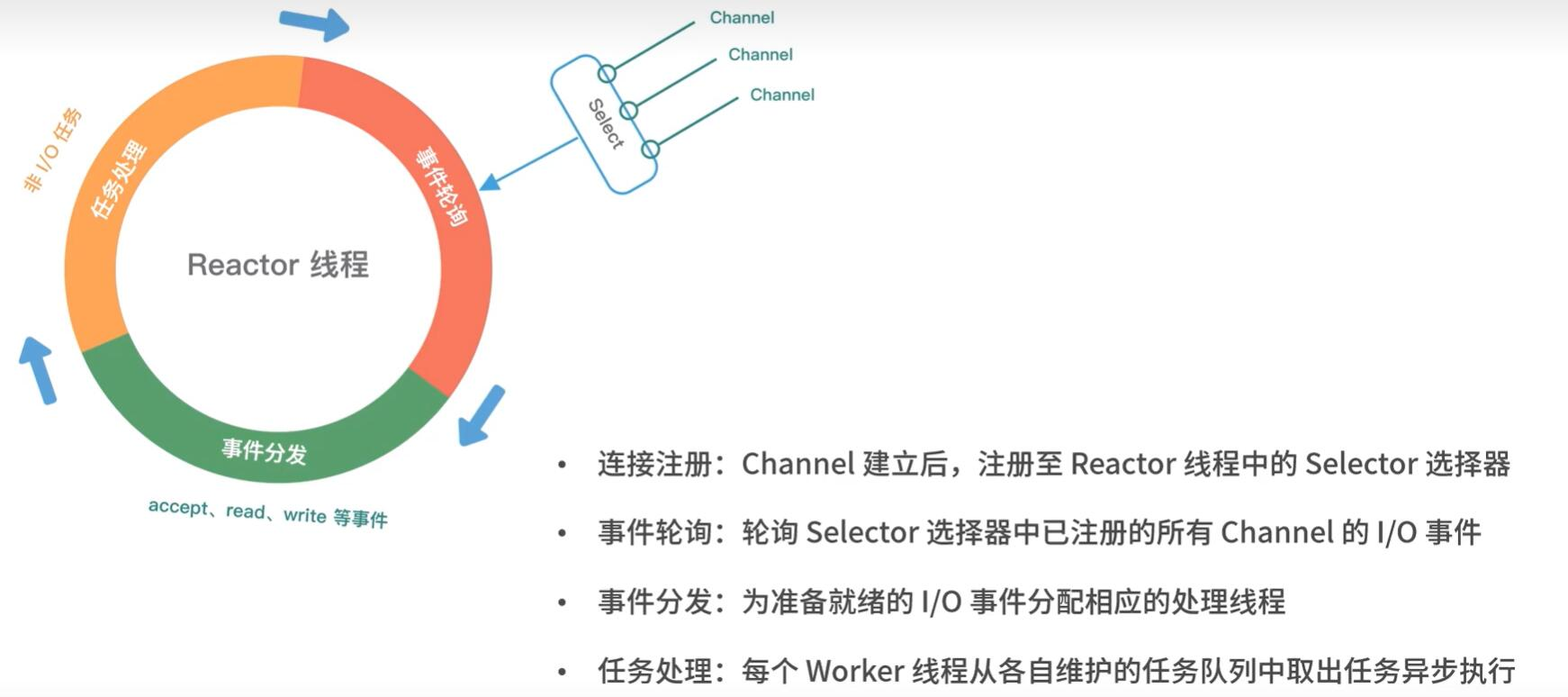
区别在于这里的Channel是NioSocketChannel,而不是NioServerSockectChannel,并且就绪的事件是READ(这是因为注册到Selector上附件是包装了SocketChannel的NioSocketChannel,感兴趣的事件是read)并且这里的线程是worker NioEventLoopGroup中的线程!
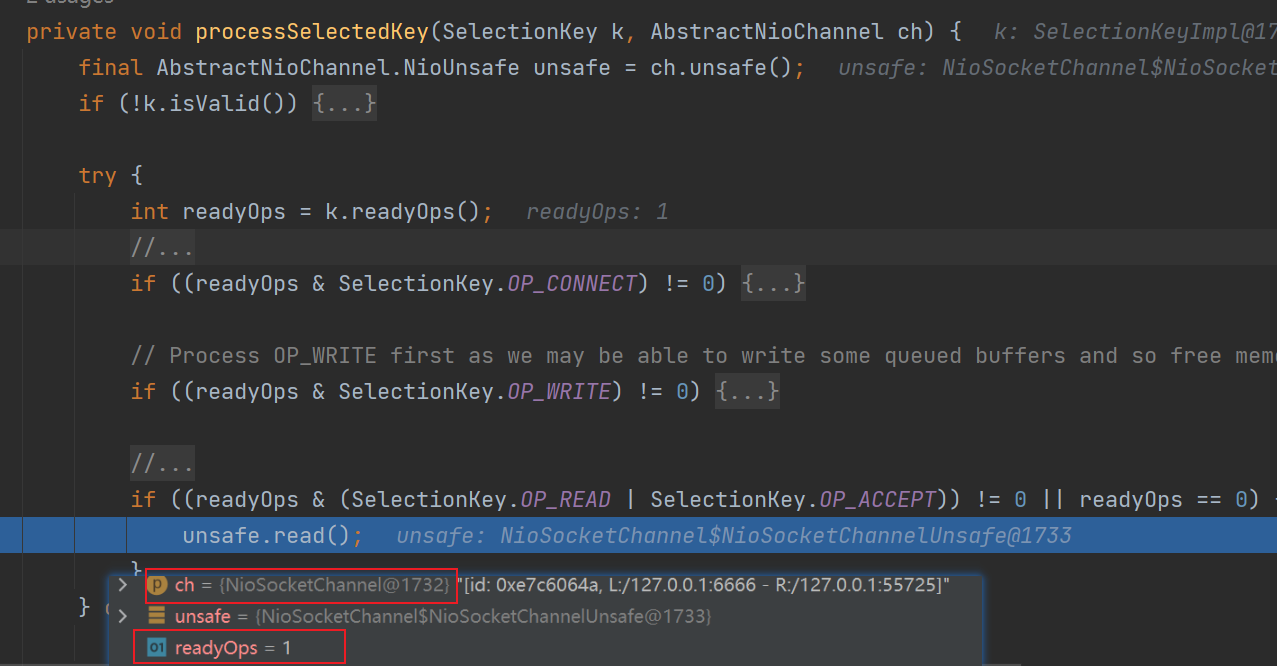
二丶NioSockectChannelUnsafe读取数据
可以看到子reactor线程读取客户端发送的数据,使用的是NioSockectChannelUnsafe#read方法。如下是read方法源码:
public final void read() {
final ChannelConfig config = config();
// 省略read-half相关处理
final ChannelPipeline pipeline = pipeline();
// ByteBuf分配器,默认为堆外内存+池化分配器
final ByteBufAllocator allocator = config.getAllocator();
// allocHandle用来控制下面读取流程
final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle();
allocHandle.reset(config);
ByteBuf byteBuf = null;
boolean close = false;
try {
do {
// allocHandle使用allocator来分配内存给byteBuf
byteBuf = allocHandle.allocate(allocator);
// doReadBytes读取数据到byteBuf,记录最后一次读取的字节数
allocHandle.lastBytesRead(doReadBytes(byteBuf));
// 小于0==>通道已到达流结束
if (allocHandle.lastBytesRead() -
可以看到每次读取到数据都会触发channelRead,读取完毕后会触发readComplete
我们的业务逻辑就需要自己实现ChannelHandler#channelRead和channelReadComplete进行数据处理(解码,执行业务操作,编码,写回)
-
可以看到是否继续读取客户端发送数据,是由allocHandle.c服务器托管网ontinueReading()决定的,并且读取客户端的数据会存放到ByteBuf中,ByteBuf的分配是
allocHandle.allocate(allocator)来控制
2.0 读取客户端发送的数据
我们先忽略ByteBufAllocator和RecvByteBufAllocator ,直接看看doReadBytes(byteBuf)是如何读取的数据

最终调用setBytes进行读取
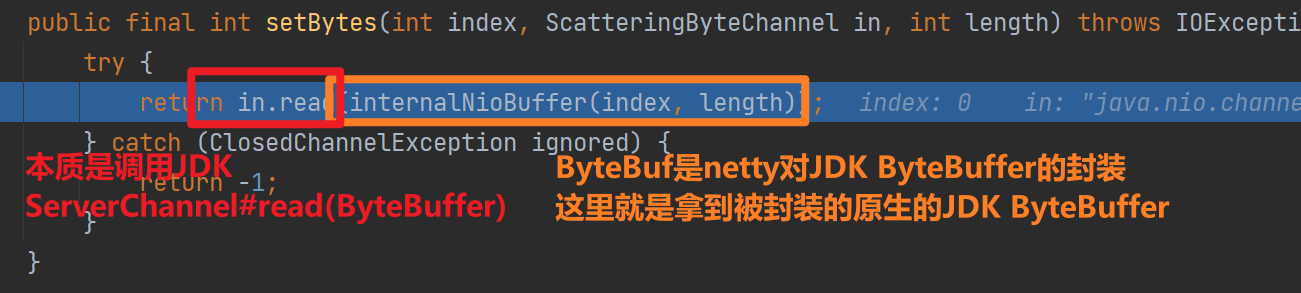
下面我们看看ByteBufAllocator和RecvByteBufAllocator 在这个过程中取到了什么作用
2.1 ByteBufAllocator
ByteBufAllocator的主要作用是分配和回收ByteBuf对象,以及管理内存的分配和释放。
- 内存池的管理机制,用于提高内存分配和回收的效率。
- 支持可选的内存池类型,如池化和非池化等,以根据应用程序的需求进行灵活的内存管理。

如上是ByteBufAllocator的具体实现
-
AbstractByteBufAllocator:这是一个抽象类,提供了一些通用的方法和逻辑,用于创建和管理ByteBuf实例。它是UnpooledByteBufAllocator和PooledByteBufAllocator的基类。
-
UnpooledByteBufAllocator:这是ByteBufAllocator的默认实现。它采用非池化的方式进行内存分配,每次都会创建新的ByteBuf对象,不会使用内存池。
-
PooledByteBufAllocator:这是使用内存池的ByteBufAllocator实现。它通过重用内存池中的ByteBuf对象来提高性能和内存利用率。PooledByteBufAllocator可以根据需求使用池化和非池化的ByteBuf实例。
-
PreferredDirectByteBufAllocator:偏好使用直接内存的分配器,ByteBufAllocator#buffer并没有说明是堆内还是堆外,PreferredDirectByteBufAllocator会优先使用堆内(装饰器模式)
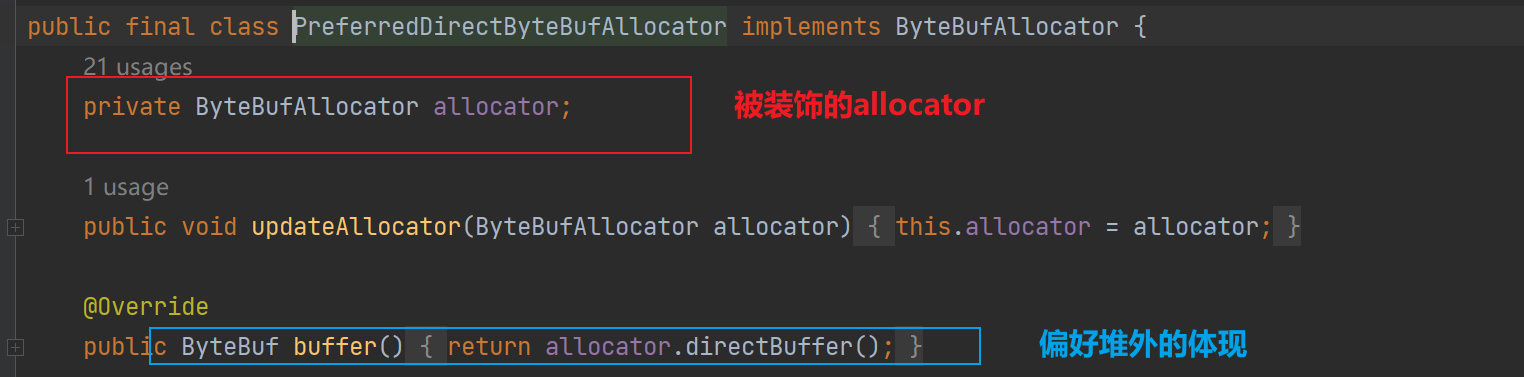
-
PreferHeapByteBufAllocator:偏好使用堆内内存的分配器
2.2 RecvByteBufAllocator 与 RecvByteBufAllocator.Handler
ByteBufAllocator是真正分配内存产生ByteBuf的分配器,但是在网络io中通常需要根据读取数据的多少动态调整ByteBuf的。默认情况下netty在读取客户端数据的时候使用的是AdaptiveRecvByteBufAllocator,顾名思义可以调整ByteBuf的RecvByteBufAllocator 实现。
也就是说,ByteBufAllocator是真正负责内存分配的,RecvByteBufAllocator是负责根据网络IO情况去调用ByteBufAllocator调整ByteBuf的。

- FixedRecvByteBufAllocator:固定分配器。该实现分配固定大小的ByteBuf,不受网络环境和应用程序需求的影响。适用于在已知数据量的情况下进行分配,不需要动态调整大小。
- AdaptiveRecvByteBufAllocator:自适应分配器。该实现根据当前的网络环境和应用程序的处理能力动态地调整ByteBuf的大小。可以根据实际情况自动增加或减少分配的大小,以优化性能。
- DefaultMaxMessagesRecvByteBufAllocator:根据最大消息数量的分配器。该实现根据应用程序的需求来控制ByteBuf的分配。可以设置最大消息数量,当达到该数量时,不再分配ByteBuf,以控制内存的使用。
- DefaultMaxBytesRecvByteBufAllocator:主要根据最大字节数来控制ByteBuf的分配。它与DefaultMaxMessagesRecvByteBufAllocator类似,但是以字节数为基础而不是消息数量。
- ServerChannelRecvByteBufAllocator:控制服务端接收缓冲区大小
其内部还有一个Handler,Handler才是真正实现这些逻辑的类,这样做法的好处在于解耦合——RecvByteBufAllocator和Handler是松耦合的,多个RecvByteBufAllocator可以基于相同的Handler。
三丶 AdaptiveRecvByteBufAllocator
如下是 AdaptiveRecvByteBufAllocator#HandleImpl在读取客户端数据的过程中取到的作用:
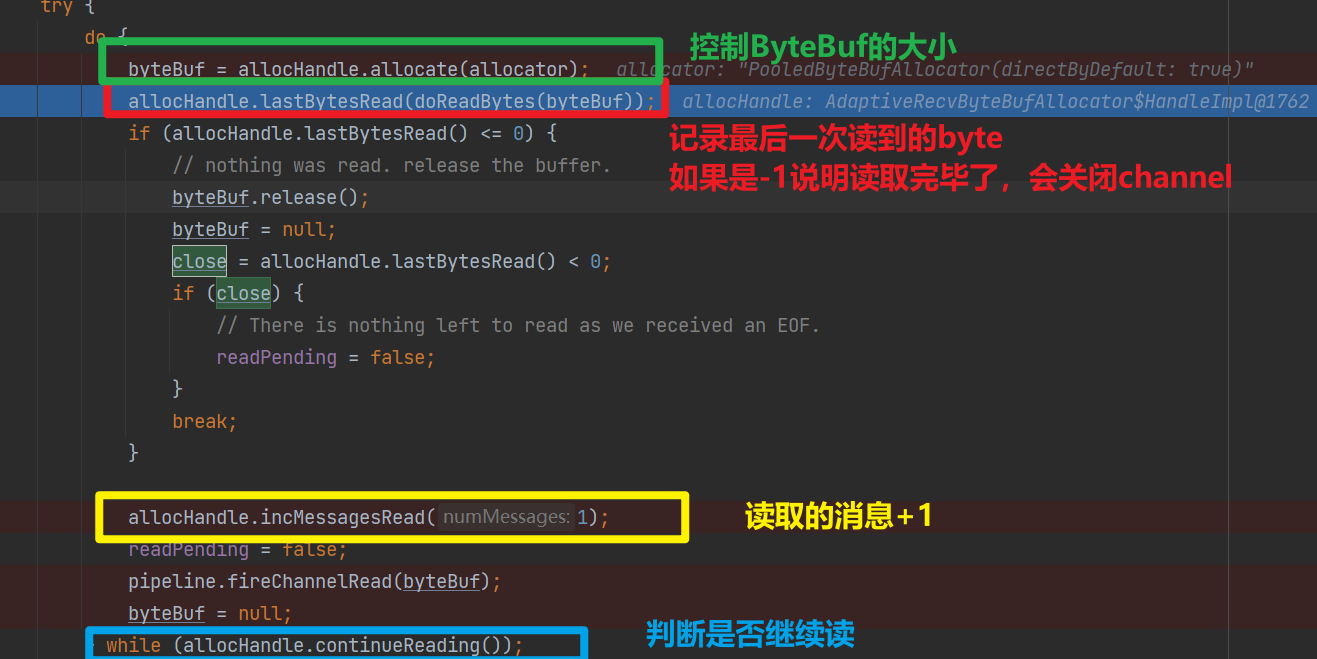
3.1 分配ByteBuf&控制ByteBuf大小

可以看到真正分配ByteBuf的是ByteBufAllocator,而大小是AdaptiveRecvByteBufAllocator#HandleImpl使用guess方法猜测出来的
首次guess会返回预设的值(2048)后续该方法根据之前读取数据的多少来“猜”这次使用多大ByteBuf比较合适
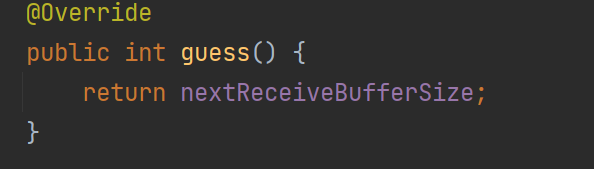
这个猜其实就是返回内存中记录的下一次大小,那么是怎么实现猜测的过程的昵?
3.2 “猜“——动态调整ByteBuf大小
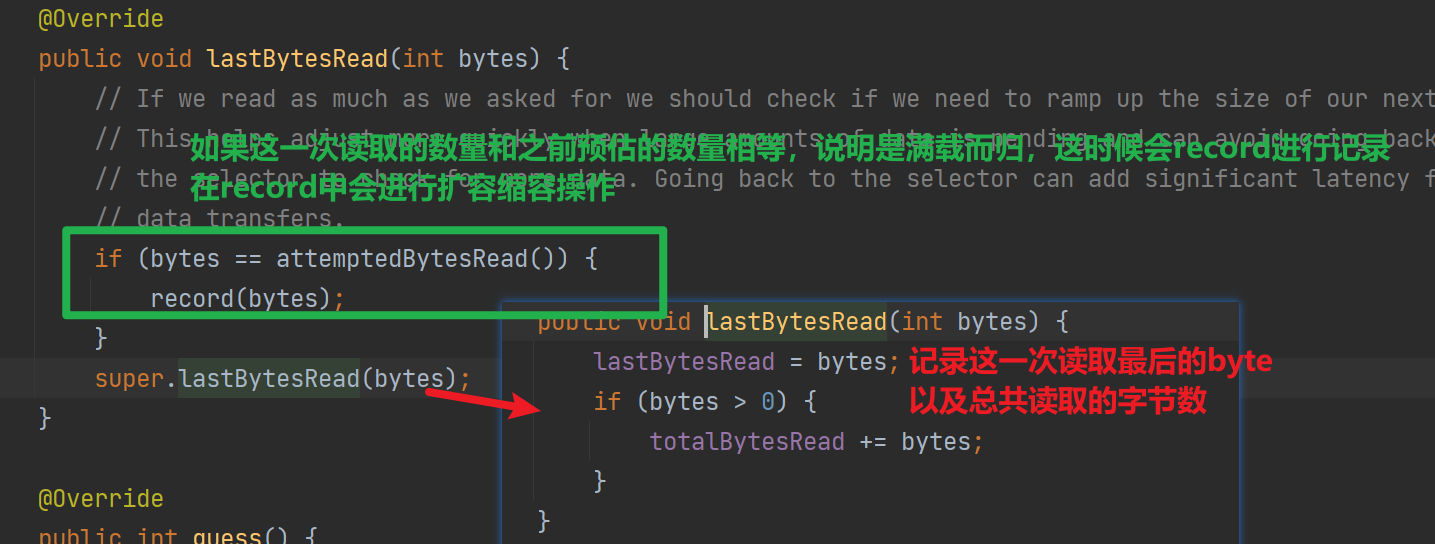
可以看到在记录读取数量的时候,如果是满载而归(比如上一次猜需要2048字节,由于客户端发送数据很多,读满了ByteBuf)会调用record进行记录和调整
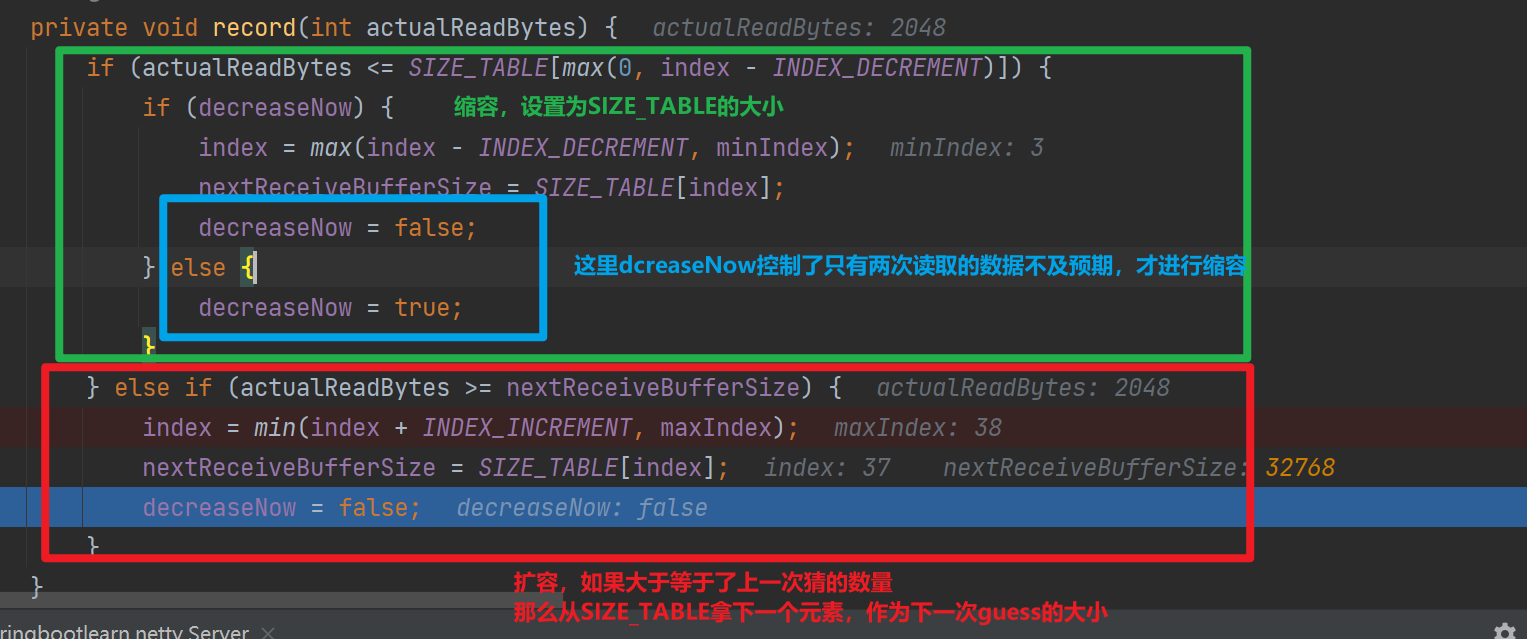
可以看到容量大小记录在了SIZE_TABLE中,SIZE_TABLE的初始化如下
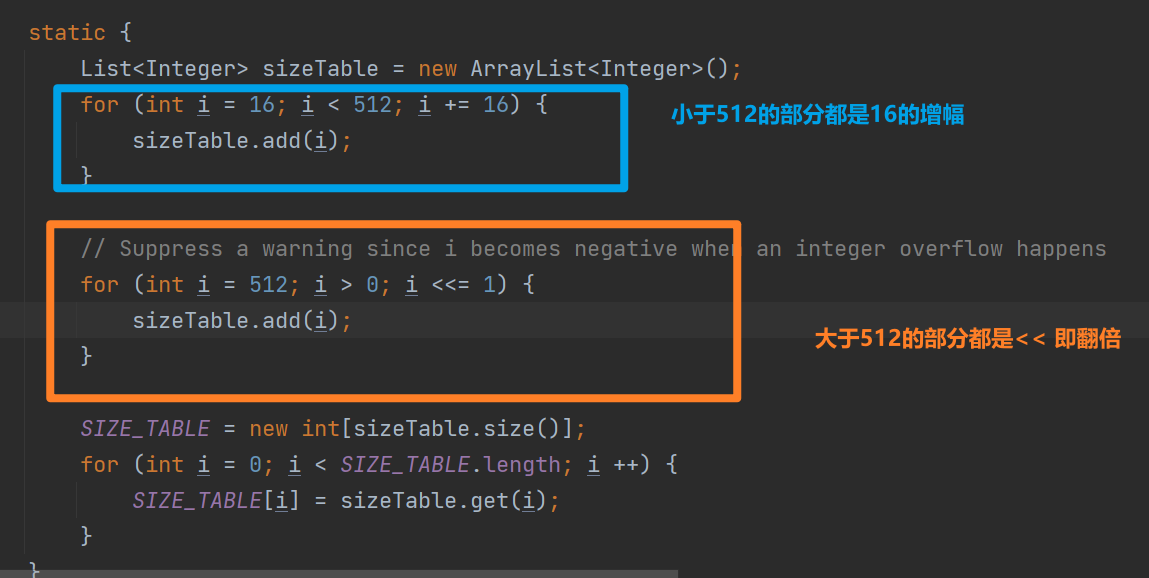
可以看到AdaptiveRecvByteBufAllocator#HandlerImpl调整的策略有以下特点
- 小于512的适合,容量大小增长缓慢,大于521的容量翻倍增加
- 扩容大胆,缩容需要两次判断
3.3 是否继续读取
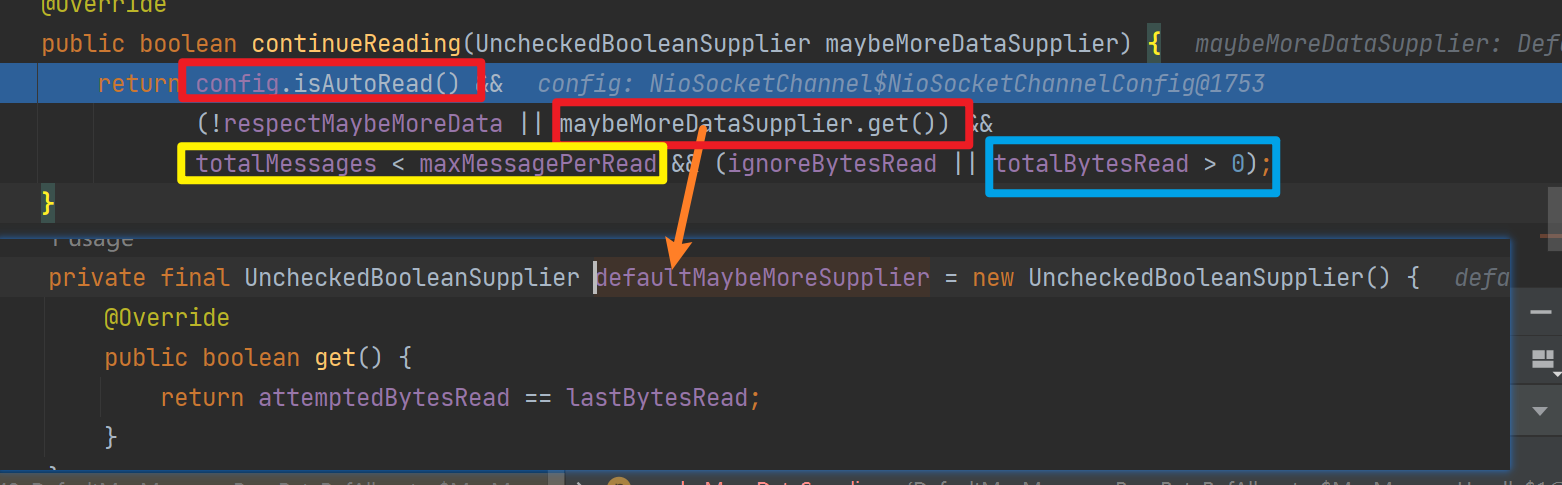
continueReading会判断是否继续读取:需要开启自动读,且maybe存在更多数据需要读取,且累计读取消息数小于最大消息数,且上一次读到了数据
-
自动读:默认情况下,Netty的Channel是处于自动读取模式的。这意味着当有新数据可读时,Netty会自动触发读事件,从Channel中读取数据并传递给下一个处理器进行处理。自动读适合在高吞吐量的场景开启,但是如果处理数据的速度跟不上读取数据速度会出现数据堆积,内存占用过高,rt增加的问题。
-
maybe存在更多数据需要读取:

其实就是判断上一次读取的字节数和预估的数量是否相等,也就是是否满载而归
-
累计读取消息数小于最大消息数
虽然一个NioServerChannel只会绑定到一个线程,但是一个线程可以注册多个NioServerChannel,so如果一个客户端疯狂发数据, 服务端不做干预,将导致这个线程上的其他Channel永远得不到处理
so netty设置maxMessagePerRead(单次read最多可以读取多少消息——指循环读取ServerChannel多少次)
四丶总结&启下
1.总结
这一篇我们看了服务器托管网NioServerChannel是如何读取数据的,其Unsafe依赖JDK原生的SocketChannel#read(ByteBuffer)来读取数据,但是netty在此之上做了如下优化
-
使用ByteBufAllocator优化ByteBuf的分配,默认使用池化的直接内存策略
内存池这一篇没用做过多学习,后续单独学习
-
使用AdaptiveRecvByteBufAllocator对读取过程进行优化
- guess会猜测多大的ByteBuf合适(每次读取后进行扩容or缩容)
- 内部是SIZE_TABLE记录容量大小,小于512的适合,容量大小增长缓慢,大于521的容量翻倍增加
- 扩容大胆——容量小了1次那么下一次使用SIZE_TABLE下一个下标对应的容量,缩容需要两次判断,连续两次不满足大小才进行缩容
- 在是否继续读取上雨露均沾——控制最多读取16次,并且会根据读取数据是否满载而归判断是否需要继续读取
2.启下
这一篇我们看到每一次循环读取NioSocketChannel数据后会触发channelRead,读取完毕后会触发readComplete,
我们的业务逻辑就需要自己实现ChannelHandler#channelRead和channelReadComplete进行数据处理(解码,执行业务操作,编码,写回)
那么netty中有哪些内置的编码解码器昵?下一篇我们再来唠唠
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
配置实例 R2 [r2]display current-configuration [V200R003C00] # sysname r2 # snmp-agent local-engineid 800007DB03000000000000 snmp-agent…
