
系列文章目录和关于我
一丶前言
之前在学习netty源码的时候,经常看netty hash时间轮(HashedWheelTimer)的出现,时间轮作为一种定时调度机制,在jdk中还存在Timer和ScheduledThreadPoolExecutor。那么为什么netty要重复造轮子昵,HashedWheelTimer又是如何实现的,解决了什么问题?
这一篇将从Timer–>ScheduledThreadPoolExecutor–>HashedWheelTimer 依次进行讲解,学习其中优秀的设计。
二丶Timer
1.基本结构
Timer 始于java 1.3,原理和内部结构也相对简单,
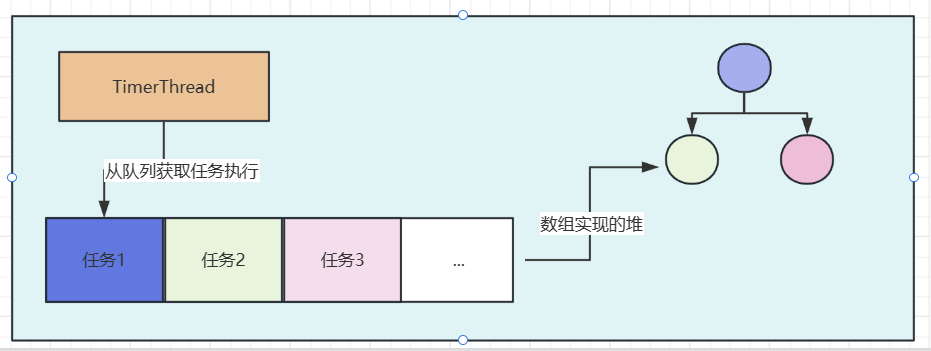
如上图所示,Timer内部存在一个线程(TimerThread实例)和一个数组实现的堆
TimerThread运行时会不断从数组中拿deadline最早的任务,进行执行。为了更快的拿到dealline最早的任务,Timer使用数组构建了一个堆,堆排序的依据便是任务的执行时间。
Timer中只存在一个线程TimerThread来执行定时任务,因此如果一个任务耗时太长会延后其他任务的执行
并且TimerThread不会catch任务执行产生的异常,也就是说如果一个任务执行失败了,那么TimerThread的执行会终止
2.源码
2.1 TimerThread 的执行
如下是TimerThread 执行的源码
- 基于等待唤醒机制,避免无意义自旋
- 每次都拿任务队列中ddl最早的任务
- 如果周期任务,会计算下一次执行时间,重新塞到任务队列中
- 巧妙的使用了 period 等于0,小于0,大于0进行非周期运行任务,fixed delay,fixed rate的区分
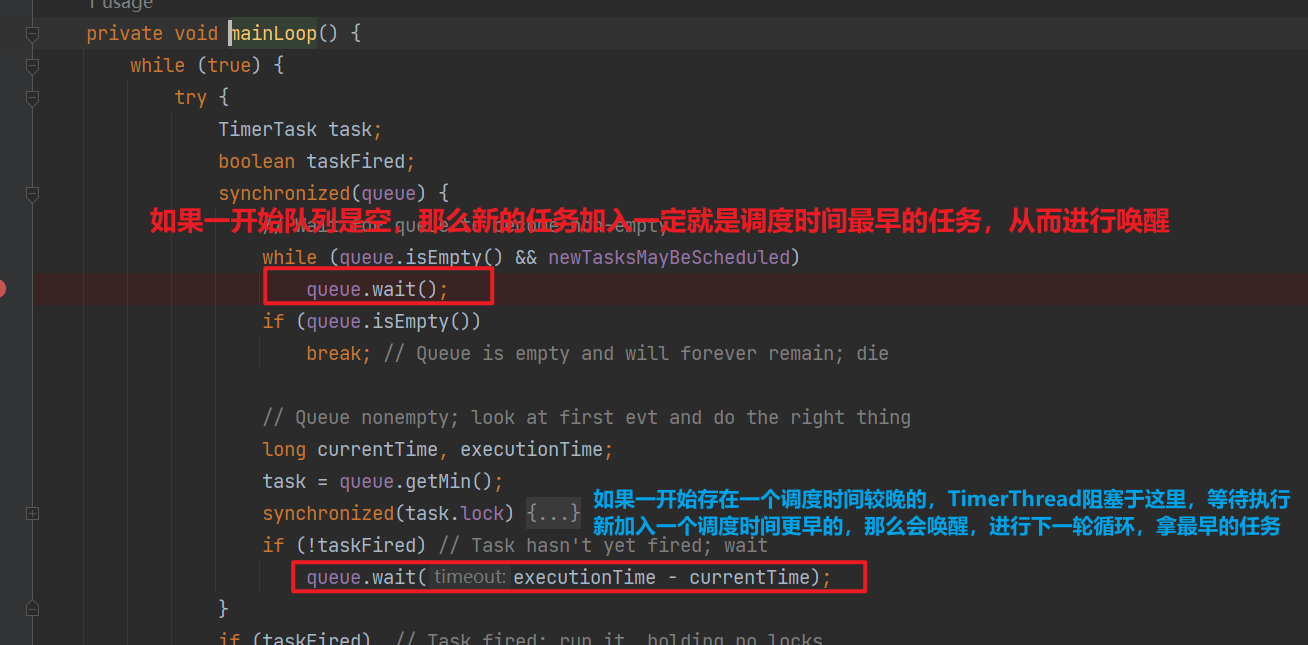
private void mainLoop() {
while (true) {
try {
TimerTask task;
boolean taskFired;
// 对队列上锁,也就是提交任务和拿任务是串行的
synchronized(queue) {
// 如果Timer被关闭newTasksMayBeScheduled会为false
// 这里使用等待唤醒机制来阻塞TimerThread直到存在任务
while (queue.isEmpty() && newTasksMayBeScheduled)
queue.wait();
// 说明newTasksMayBeScheduled 为false 且没任务,那么TimerTask的死循环被break,
if (queue.isEmpty())
break;
long currentTime, executionTime;
task = queue.getMin();
// 对任务上锁,避免并发执行,TimerTask 使用state记录任务状态
synchronized(task.lock) {
// 任务取消
if (task.state == TimerTask.CANCELLED) {
queue.removeMin();
continue;
服务器托管网 }
currentTime = System.currentTimeMillis();
executionTime = task.nextExecutionTime;
// 需要执行
if (taskFired = (executionTime这段代码笔者认为有一点可以优化的,那就是在判断任务是否需要执行,根据period计算执行时间的时候,会在持有任务队列锁的情况下,拿任务锁执行——但是判断任务是否需要执行,根据period计算执行时间 这段时间其实是可以释放队列锁的!这样并发的能力可以更强一点,可能Timer的定位也不是应用在高并发任务提交执行的场景,毕竟内部也只有一个线程,所以也无伤大雅。
2.2 任务的提交
任务的提交最终都调用到sched(TimerTask task, long time, long period)方法
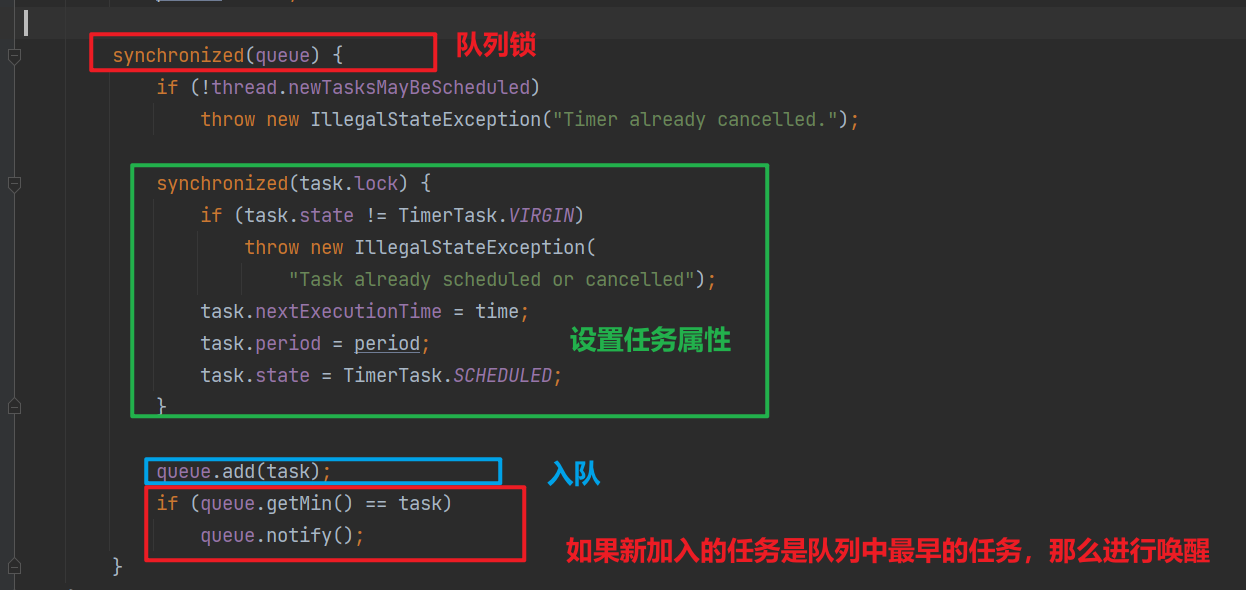
这里比较有趣的是,加入到队列后,会判断当前任务是不是调度时间最早的任务,如果是那么进行唤醒!这么处理的原因可见下图解释:
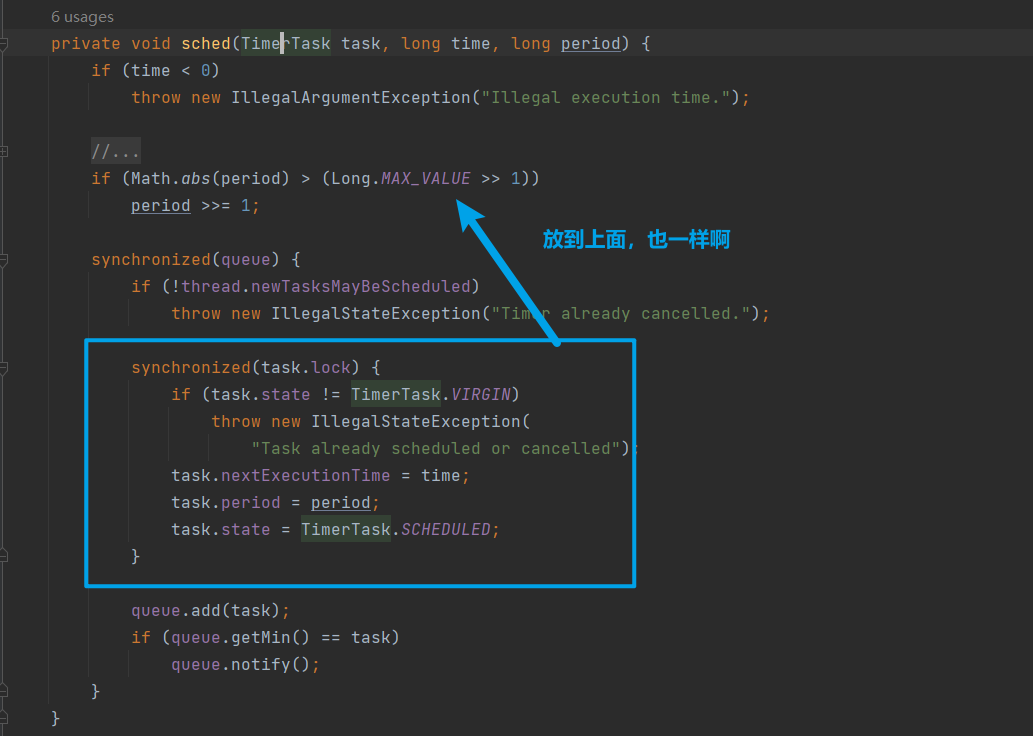
同样我不太理解为什么,Timer的作者要拿到队列锁,后拿任务锁,去复制TimerTask的属性,完全可以将TimerTask的修改放在队列锁的外面,如下
2.3 队列实现的堆

可以看到新增任务需要进行fixUp,调整数组中的元素,实现小根堆,这里时间复杂度是logN
3.Timer的不足
- 单线程:如果存在多个定时任务,那么后面的定时任务会由于前面任务的执行而delay
- 错误传播:一个定时任务执行失败,那么会导致Timer的结束
- 不友好的API:使用Timer执行延迟任务,需要程序员将任务保证为TimerTask,并且TimerTask无法获取延迟任务结果
三丶ScheduledThreadPoolExecutor
java 1.5引入的juc工具包,其中ScheduledThreadPoolExecutor就提供了定时调度的能力
- 其继承了ThreadPoolExecutor,具备多线程并发执行任务的能力。
- 更强的错误恢复:如果一个任务抛出异常,并不会影响调度器本身和其他任务
- 更友好的API:支持传入Runnable,和Callable,调度线程将返回ScheduledFuture,我们可以通过ScheduledFuture来查看任务执行状态,以及获取任务结果
由于ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,其中执行任务的线程运行逻辑同ThreadPoolExecutor(《JUC源码学习笔记5——1.5w字和你一起刨析线程池ThreadPoolExecutor源码,全网最细doge》)
1.基本结构
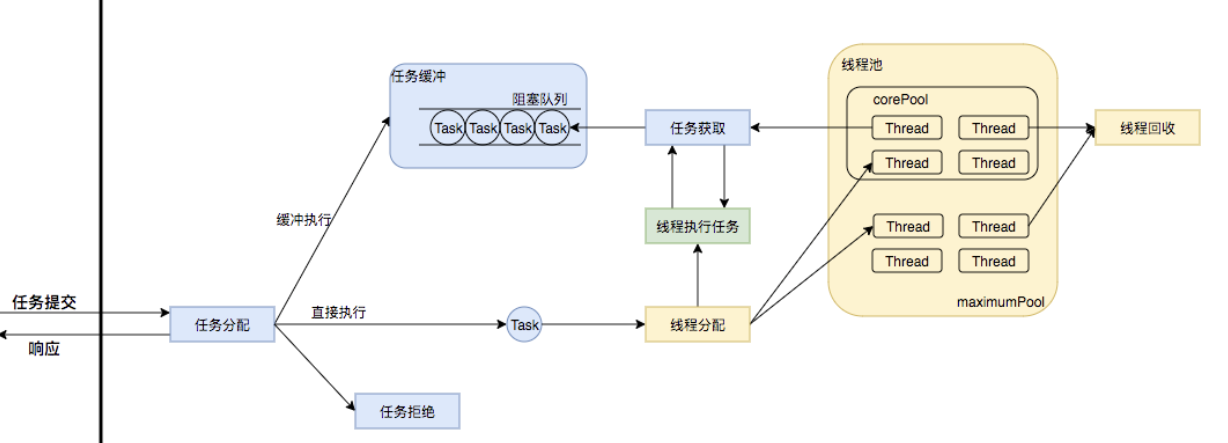
ScheduleThreadPoolExecutor内部结构和ThreadPoolExecutor类似,不同的是内部的阻塞队列是DelayedWorkQueue——基于数组实现的堆,依据延迟时间进行排序,堆顶,依据Condition等待唤醒机制实现的阻塞队列;另外堆中的元素是ScheduledFuture
2.源码
2.1 ScheduledFutureTask的执行
public void run() {
// 是否周期性,就是判断period是否为0。
boolean periodic = isPeriodic();
// 检查任务是否可以被执行。
if (!canRunInCurrentRunState(periodic))
cancel(false);
// 如果非周期性任务直接调用run运行即可。
else if (!periodic)
ScheduledFutureTask.super.run();
// 如果成功runAndRest,则设置下次运行时间并调用reExecutePeriodic。
else if (ScheduledFutureTask.super.runAndReset()) {
setNextRunTime();
// 需要重新将任务放到工作队列中
reExecutePeriodic(outerTask);
}
}
可以看到任务实现周期执行的关键在于任务执行完后会再次被放到延迟阻塞队列中,ScheduledFutureTask的父类是FutureTask,其内部使用volatile修饰的状态字段来记录任务运行状态,使用cas避免任务重复执行(详细可看《JUC源码学习笔记7——FutureTask源码解析》)
2.2 DelayedWorkQueue
交给ScheduledThreadPoolExecutor执行的任务,都放在DelayedWorkQueue中,下面我们看看DelayedWorkQueue是如何接收任务,以及获取任务的逻辑
2.2.1 offer接收任务
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture> e = (RunnableScheduledFuture>)x;
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = size;
if (i >= queue.length)
// 容量扩增50%。
grow();
size = i + 1;
// 第一个元素
if (i == 0) {
queue[0] = e;
setIndex(e, 0);
} else {
// 插入堆尾。
siftUp(i, e);
}
// 如果新加入的元素成为了堆顶,则原先的leader就无效了。
if (queue[0] == e) {
leader = null;
// 那么进行唤醒,因为加入的任务延迟时间是最短的,可能之前队列存在一个延迟时间更长的任务,导致有线程block了,这时候需要进行唤醒
available.signal();
}
} finally {
lock.unlock();
}
return true;
}
可以看到大致原理和Timer中的阻塞队列类似,但是其中出现了leader(DelayedWorkQueue中的Thread类型属性)目前我们还不直到此属性的作用,需要我们结合take源码进行分析
2.2.2 take获取任务
public RunnableScheduledFuture> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
// 上锁
lock.lockInterruptibly();
try {
for (;;) {
// 堆顶元素,也就是延迟最小的元素,马上就要执行的任务
RunnableScheduledFuture> first = queue[0];
// 如果当前队列无元素,则在available条件上无限等待直至有任务通过offer入队并唤醒。
if (first == null)
available.await();
else {
// 延迟最小任务的延迟
long delay = first.getDelay(NANOSECONDS);
// 如果delay小于0说明任务该立刻执行了。
if (delay 整个原理看下来并不复杂,无非是以及Condition提供的等待唤醒机制实现任务的延迟的执行。
但是代码中存在leader相关的操作,这才是DelayedWorkQueue的精华,下面我们对这个leader机制进行学习
2.2.3 Leader-Follower 模式
DelayedWorkQueue中的leader是一个Thread类型的属性,它指向了用于在队列头等待任务的线程。用于最小化不必要的定时等待
当一个线程成为leader线程时,它只等待下一个延迟过去,而其他线程则无限期地等待。在leader从take或poll返回之前,leader线程必须向其他线程发出信号,除非其他线程在此期间成为引导线程。每当队列的头被一个过期时间较早的任务替换时,leader字段就会通过重置为null而无效,并向一些等待线程(但不一定是当前的leader)发出信号。
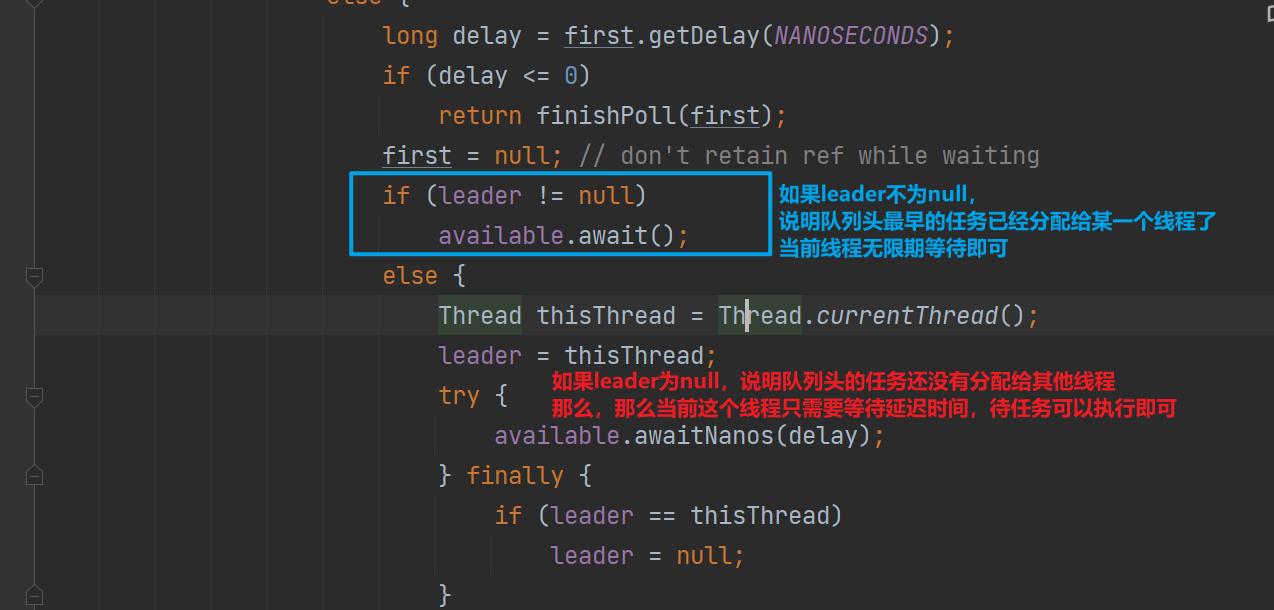
这么说可能不是很好理解,我们结合代码进行分析,如下是take中的一段:
-
如果leader 不为null,让前来拿任务的线程无限期等待
-
为什么要这么做——减少无意义的锁竞争,最早执行的任务已经分配给leader了,
follower只需要等着即可
-
follower等什么?——等leader拿到任务后进行唤醒,leader拿到任务,那么接下来follower需要执行后续的任务了;或者堆中插入了另外一个延迟时间更小的任务
-
-
如果leader为null,那么当前线程成为leader
-
这意味着堆顶延迟时间最短的任务交由当前线程执行,当前线程只需要等待堆顶任务延迟时间结束即可
-
leader什么时候被唤醒:
延迟时间到,或者堆中插入了另外一个延迟时间更小的任务
-
这里就可以看出Leader-Follower是怎么减少无意义的锁竞争的,leader是身先士卒的将第一个任务拦在身上,让自己的Follower可以进行永久的睡眠(超时等待),只有leader拿到任务准备执行了,才会唤醒自己的Follower——太温柔了,我哭死。下面我们看看leader唤醒Follower的代码
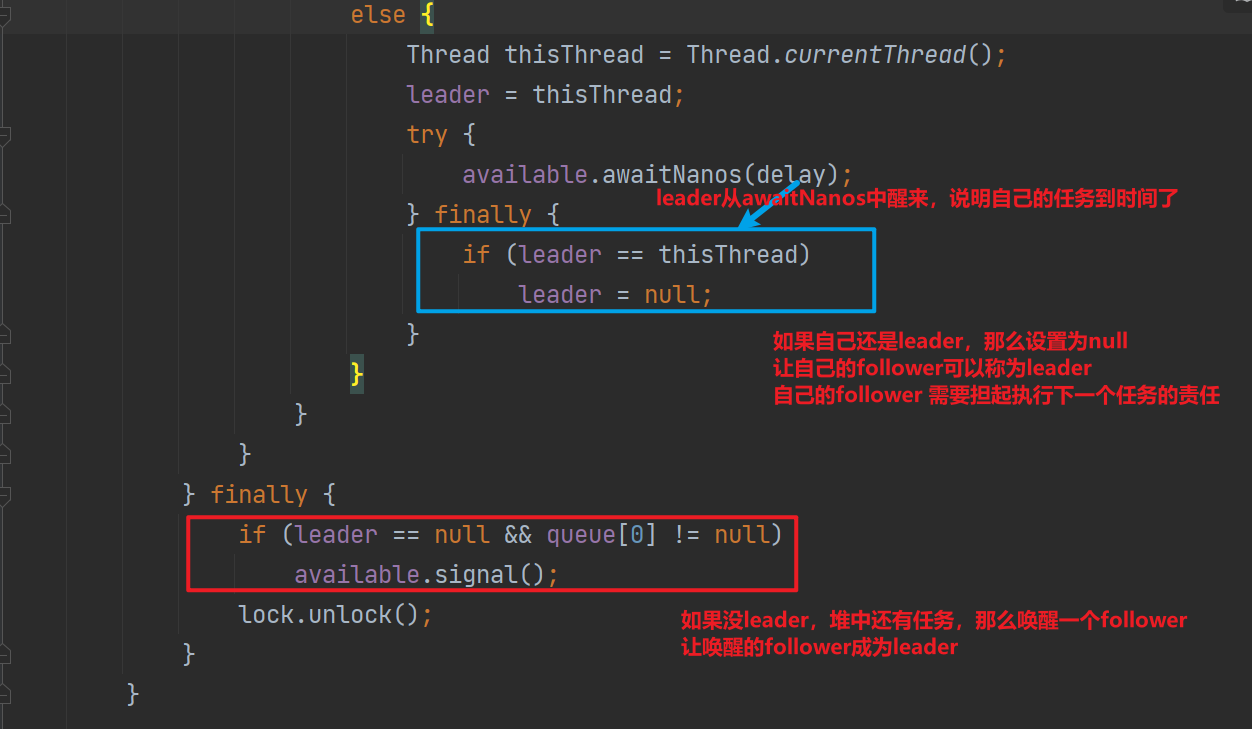
上面展示了leader任务到时间后的代码逻辑,可以看到leader任务到期后会设置leader为null(这象征了leader的交接,leader去执行任务了,找一个follower做副手),然后如果堆中有任务,那么唤醒一个follower,紧接着前leader就可以执行任务了
其实还存在另外一种case,那就是leader在awaitNanos的中途,存在另外一个更加紧急的任务被塞到堆中
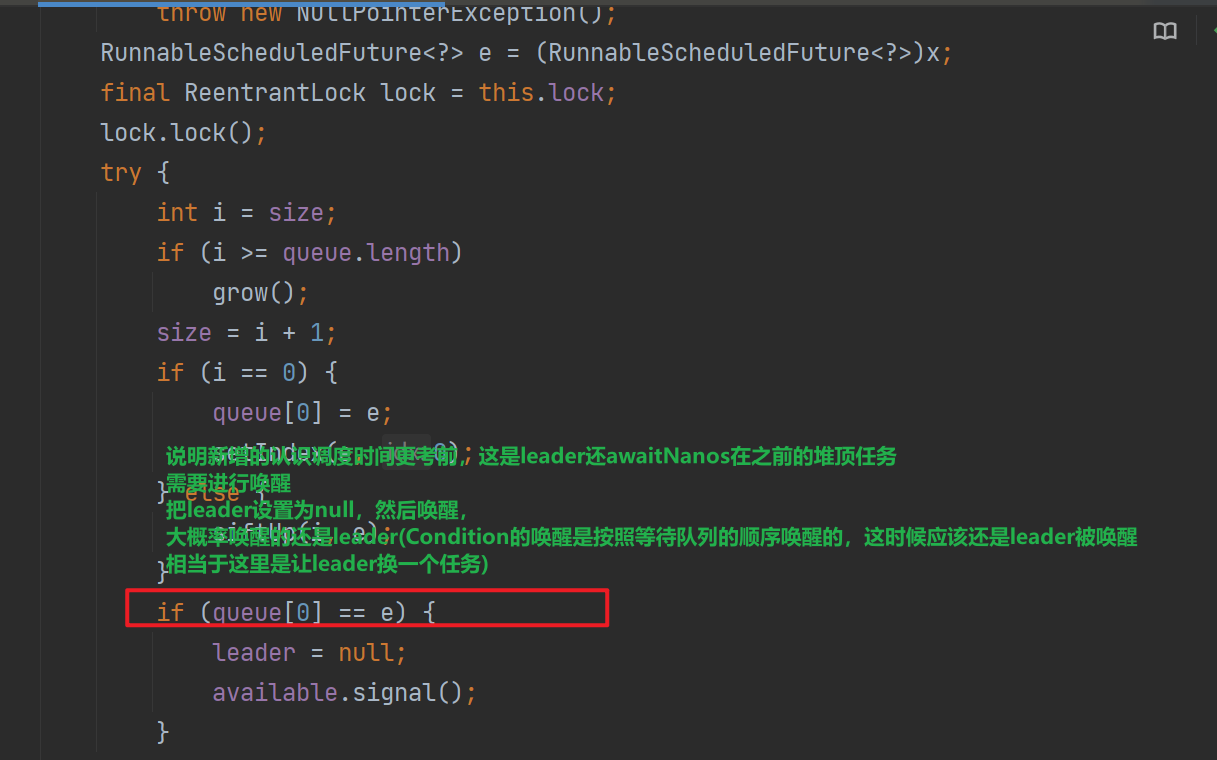
可以看到这里的leader-follower模式,可以有效的减少锁竞争,因为leader在拿到任务后会唤醒一个线程,从而让follower可以await,而不是无意义的获取DelayedWorkQueue的锁,看有没有任务需要执行!
-
优点
- 减少锁竞争:通过减少同时尝试获取下一个到期任务的线程数量,降低了锁竞争,从而提高了并发性能。
- 节省资源:避免多个线程在相同的时间点上唤醒,减少了因竞争而造成的资源浪费。
- 更好的响应性:由于 leader 线程是唯一等待到期任务的线程,因此它能够快速响应任务的到期并执行它,而无需从多个等待线程中选择一个来执行任务。
-
缺点
- 潜在的延迟:如果 leader 线程因为其他原因被阻塞或者执行缓慢,它可能会延迟其他任务的执行,因为没有其他线程在等待那个特定的任务到期(比如leader倒霉的很久没用获得cpu时间片)。
- 复杂性增加:实现 leader-follower 模式需要更多的逻辑来跟踪和管理 leader 状态,这增加了代码的复杂性。(代码初看,完全看球不同)
- 故障点:leader 线程可能成为单点故障。如果 leader 线程异常退出或被中断,必须有机制来确保另一个线程能够取代它成为新的 leader。(这里使用的finally关键字)
最后,在DelayQueue中也使用了leader-follower来进行性能优化
3.ScheduledThreadPoolExecutor优缺点
-
优点
- 任务调度: ScheduledThreadPoolExecutor 允许开发者调度一次性或重复执行的任务,这些任务可以基于固定的延迟或固定的频率来运行。
- 线程复用: 它维护了一个线程池,这样线程就可以被复用来执行多个任务,避免了为每个任务创建新线程的开销。
- 并发控制: 线程池提供了一个限制并发线程数量的机制,这有助于控制资源使用,提高系统稳定性。
- 性能优化: 使用内部 DelayedWorkQueue 来管理延迟任务,可以减少不必要的线程唤醒,从而提高性能。
- 任务同步: ScheduledThreadPoolExecutor 提供了一种机制来获取任务的结果或取消任务,通过返回的 ScheduledFuture对象可以控制任务的生命周期。
- 异常处理: 它提供了钩子方法(如 after服务器托管网Execute),可以用来处理任务执行过程中未捕获的异常。
-
缺点
-
资源限制: 如果任务执行时间过长或者任务提交速度超过线程池的处理能力,那么线程池可能会饱和,导致性能下降或新任务被拒绝。
DelayedWorkQueue是无界队列,因此任务都会由核心线程执行,大量提交的时候没用办法进行线程的增加
-
存在大量定时任务提交的时候,性能较低:基于数组实现的堆,调整的时候需要logN的时间复杂度完成
-
四丶HashedWheelTimer 时间轮
1.引入
笔者学习HashedWheelTimer的时候,问chatgpt netty在哪里使用了时间轮,chatgpt说在IdleStateHandler(当通道有一段时间未执行读取、写入时,触发IdleStateEvent,也就是空闲检测机制),但是其实在netty的IdleStateHandler并不是使用HashedWheelTimer实现的空闲检测,依旧是类似ScheduledThreadPoolExecutor的机制(内部使用基于数组实现的堆)
笔者就质问chagpt:”你放屁.jpg”

chatgpt承认了错误,然后说它推荐这么做,因为HashedWheelTimer在处理大量延迟任务的时候性能优于基于数组实现的堆。
下面我们就来学习为什么时间轮在处理大量延迟任务的时候性能优于基于数组实现的堆。
2.时间轮算法
时间轮算法(Timewheel Algorithm)是一种用于管理定时任务的高效数据结构,它的核心思想是将时间划分为一系列的槽(slots),每个槽代表时间轮上的一个基本时间单位。时间轮算法的主要作用是优化计时器任务调度的性能,尤其是在处理大量短时任务时,相比于传统的数据结构(如最小堆),它能显著降低任务调度的复杂度。
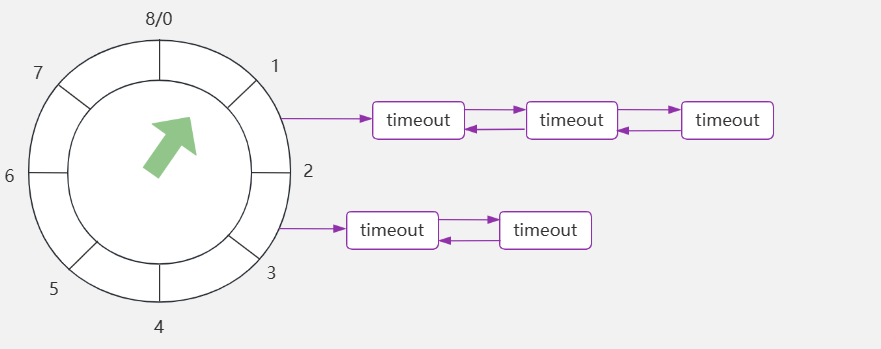
如下是时间轮的简单示意,可以看到多个任务使用双向链表进行连接
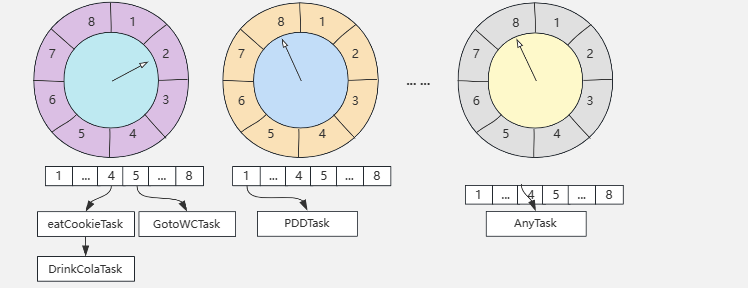
还存在多层次的时间轮(模拟时针分针秒针)对于周期性很长的定时任务,单层时间轮可能会导致槽的数量过多。为了解决这个问题,可以使用多层时间轮,即每个槽代表的时间跨度越来越大,较低层级代表短时间跨度,较高层级代表长时间跨度
从这里可以看出时间轮为什么在存在大量延迟任务的时候性能比堆更好: 时间轮的插入操作通常是常数时间复杂度(O(1)),因为它通过计算定时任务的执行时间与当前时间的差值,将任务放入相应的槽中,这个操作与定时任务的总数无关。 在堆结构中,插入操作的时间复杂度是O(log N),其中N是堆中元素的数量。这是因为插入新元素后,需要通过上浮(或下沉)操作来维持堆的性质
3.HashedWheelTimer基本结构
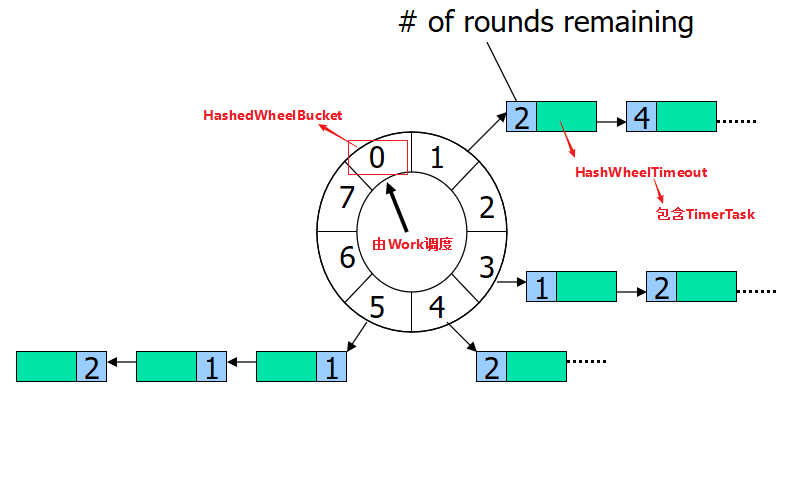
-
时间轮(Wheel):
时间轮是一个固定大小的数组,数组中的每个元素都是一个槽(bucket)。
每个槽对应一个时间间隔,这个间隔是时间轮的基本时间单位。
所有的槽合起来构成了整个时间轮的范围,例如,如果每个槽代表一个毫秒,那么一个大小为1024的时间轮可以表示1024毫秒的时间范围。 -
槽(Bucket):每个槽是一个链表,用于存储所有计划在该槽时间到期的定时任务。
任务通过计算它们的延迟时间来确定应该放入哪个槽中。
-
指针(Cursor or Hand):
时间轮中有一个指针,代表当前的时间标记。这个指针会周期性地移动到下一个槽,模拟时间的前进。每次指针移动都会检查相应槽中的任务,执行到期的任务。
-
任务(TimerTask):
任务通常是实现了TimerTask接口的对象,其中包含了到期执行的逻辑。
任务还包含了延迟时间和周期性信息,这些信息使得时间轮可以正确地调度每个任务 -
工作线程(Worker Thread):
HashedWheelTimer通常包含一个工作线程,它负责推进时间轮的指针,并处理到期的定时任务。
4.使用demo
public class HashedWheelTimerDemo {
public static void main(String[] args) {
// 创建HashedWheelTimer
HashedWheelTimer timer = new HashedWheelTimer();
// 提交一个延时任务,将在3秒后执行
TimerTask task1 = new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
System.out.println("Task 1 executed after 3 seconds");
}
};
timer.newTimeout(task1, 3, TimeUnit.SECONDS);
// 提交一个周期性执行的任务,每5秒执行一次
TimerTask task2 = new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
System.out.println("Task 2 executed periodically every 5 seconds");
// 重新提交任务,实现周期性执行
timer.newTimeout(this, 5, TimeUnit.SECONDS);
}
};
timer.newTimeout(task2, 5, TimeUnit.SECONDS);
// 注意:在实际应用中,不要忘记最终停止计时器,释放资源
// timer.stop();
}
}
5.源码
5.1 创建时间轮
HashedWheelTimer构造方法参数有
- threadFactory:负责new一个thread,这个thread负责推动时钟指针旋转。
- taskExecutor:Executor负责任务到期后任务的执行
- tickDuration 和 timeUnit 定义了一格的时间长度,默认的就是 100ms。
- ticksPerWheel 定义了一圈有多少格,默认的就是 512;
- leakDetection:用于追踪内存泄漏。
- maxPendingTimeouts:最大允许等待的 Timeout 实例数,也就是我们可以设置不允许太多的任务等待。如果未执行任务数达到阈值,那么再次提交任务会抛出RejectedExecutionException 异常。默认不限制。
构造方法主要的工作:
-
创建HashedWheelBucket数组
每一个元素都是一个双向链表,链表中的元素是HashedWheelTimeout
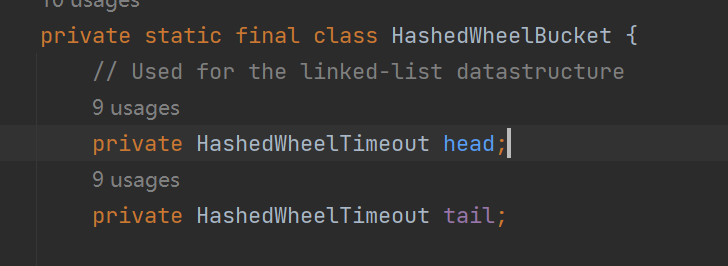
默认情况下HashedWheelTimer中有512个这样的元素
-
创建workerThread,此Thread负责推动时钟的旋转,但是并没用启动该线程,当第一个提交任务的时候会进行workerThread线程的启动
5.2 提交延时任务到HashedWheelTimer
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
// 统计等待的任务数量
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
// 大于阈值,抛出异常
if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
pendingTimeouts.decrementAndGet();
throw new RejectedExecutionException("Number of pending timeouts ("
+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "
+ "timeouts (" + maxPendingTimeouts + ")");
}
// 启动workerThread ,只启动一次
start();
// 计算任务ddl
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// Guard against overflow.
if (delay > 0 && deadline 其中workerThread的启动如下
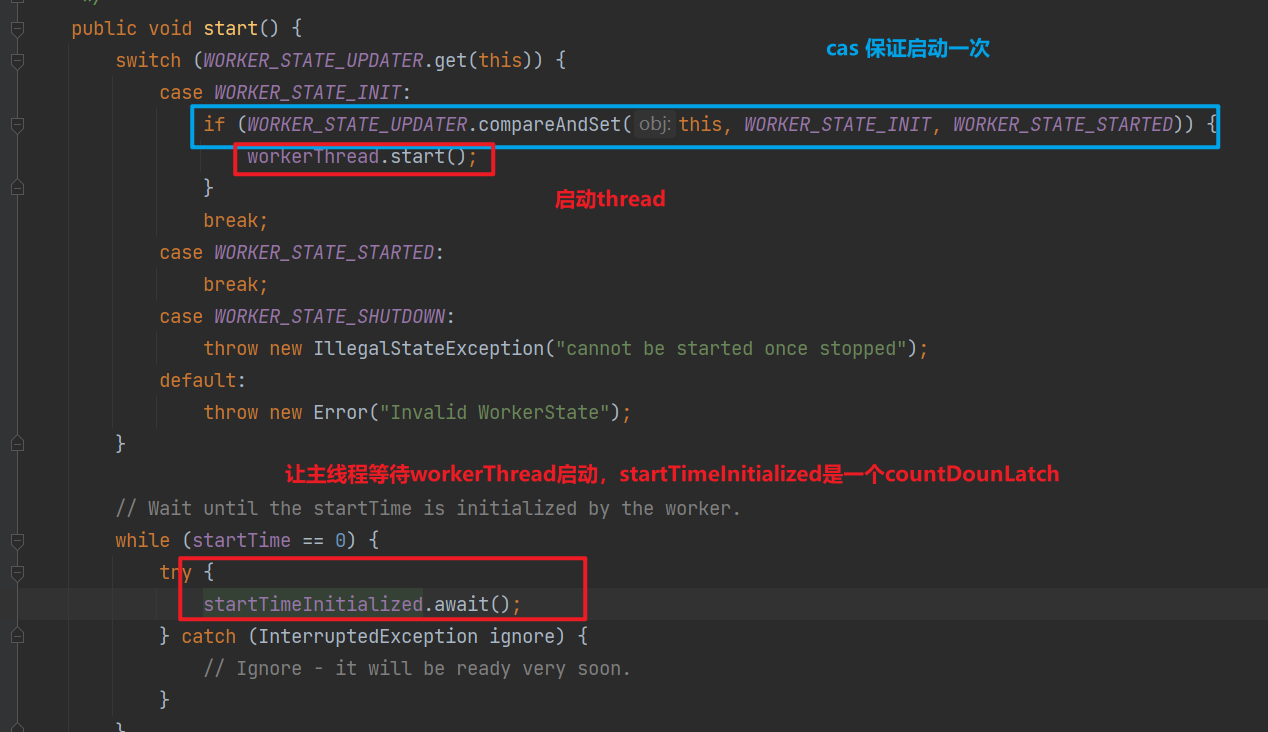
至此我们直到延时任务被加入到timeouts,timeouts是一个mpsc队列,之所以使用mpsc,是因为可能存在多个生产者提交任务,但是消费任务的只有workerThread,mpsc在这种场景下性能更好。
那么workerThread的工作逻辑是什么昵
5.3 workerThread工作
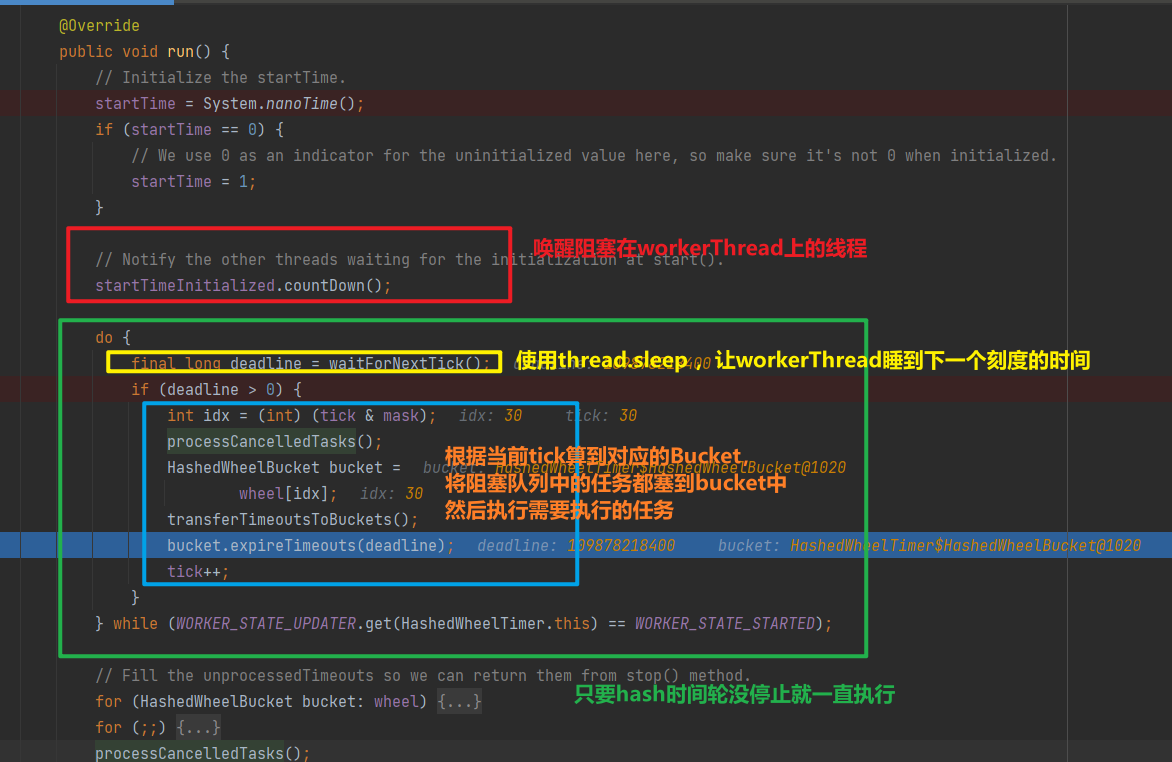
-
waitForNextTick类似于模拟时钟上指针的走动,依赖Thread#sleep
-
当到下一个刻度的时候,会先处理下取消的任务,其实就是对应bucket中删除(双向链表的删除)
-
然后将mpsc队列中的任务都放到buckets中去
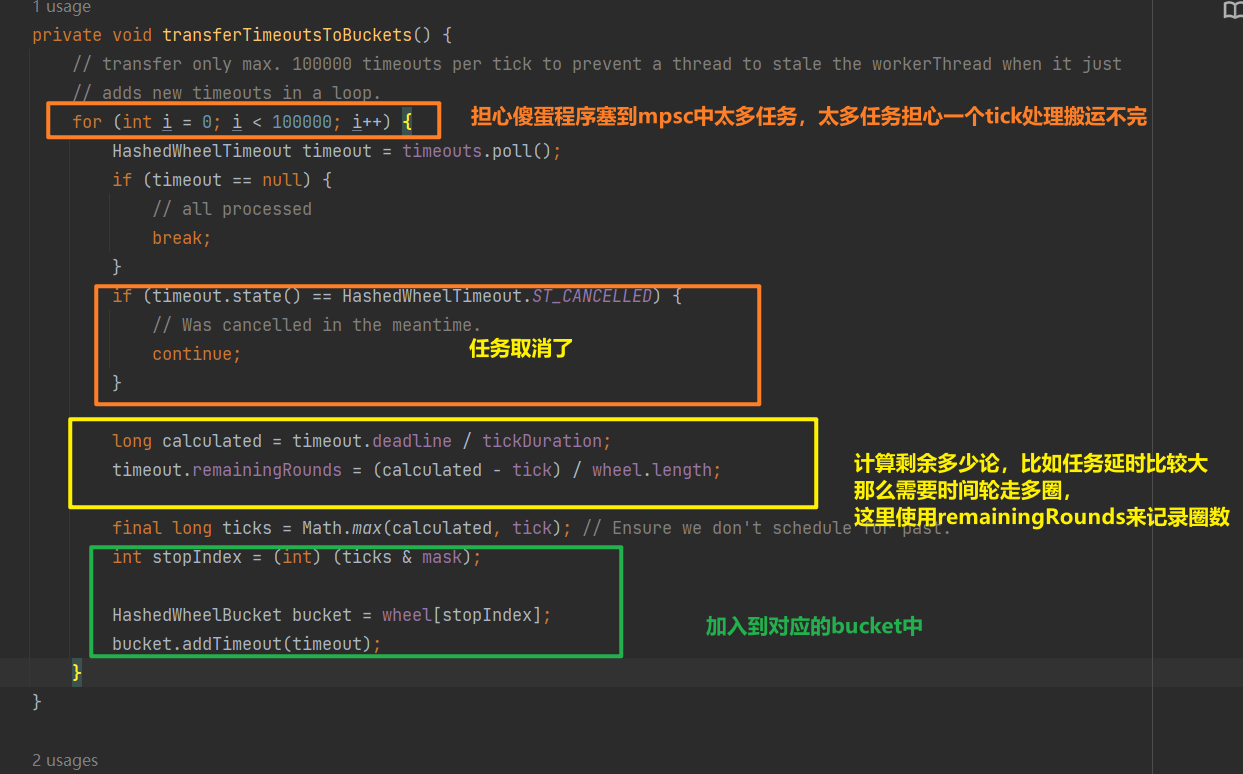
这里使用了mpsc主要是考虑如果没加一个任务都直接放到时间轮,那么锁竞争太激烈了,可能会导致抢锁阻塞了一段时间导致任务超时。有点消息队列削峰的意思。
-
接下来就是找到当tick对应的bucket的,然后执行这个bucket中所有需要执行的任务
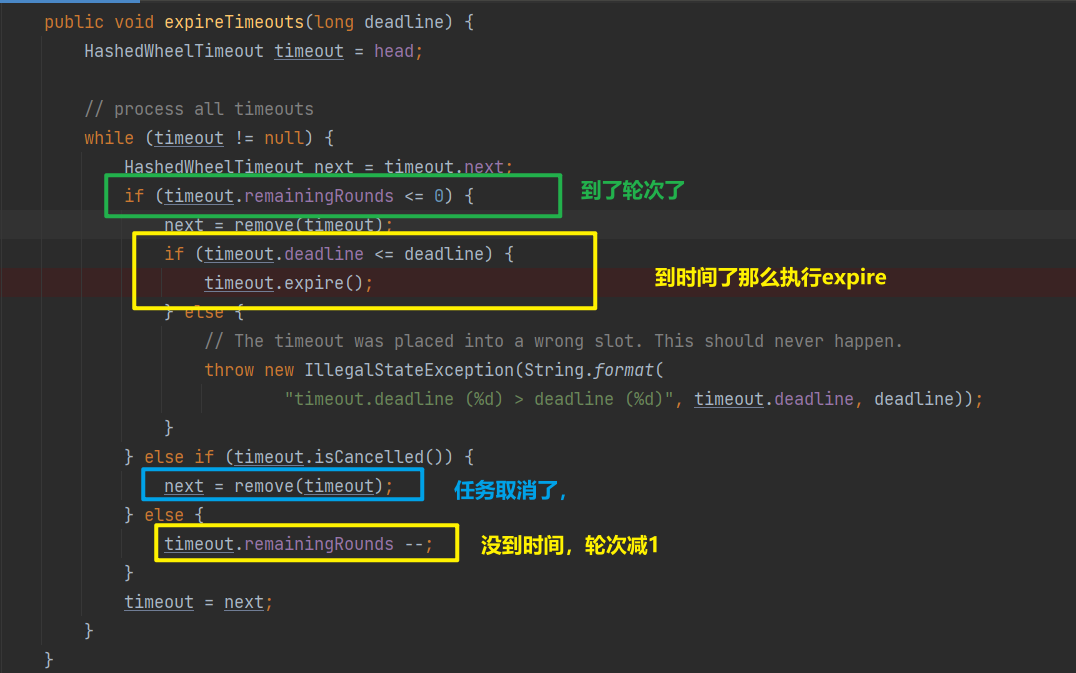
可以看到其实就是遍历双向链表,找到需要执行任务,任务的执行调用expire方法,逻辑如下:
直接交给线程池执行,之前之前还会尝试修改状态,这里其实和用户取消任务由竞争关系,也就是说如果任务提交到线程池,那么取消也无济于事了。
6.品一品优秀的设计
笔者认为这里优秀的设计主要是在于MPSC的应用
- 线程安全: HashedWheelTimer通常由一个工作线程来管理时间轮的推进和执行任务。如果允许多个线程直接在时间轮的桶(bucket)中添加任务,就必须处理并发修改的问题,这将大大增加复杂性和性能开销。MPSC队列允许多个生产者线程安全地添加任务,而消费者线程(也就是HashedWheelTimer的工作线程)则负责将这些任务从队列中取出并放入正确的时间槽中。
- 性能优化: 使用MPSC队列可以减少锁的竞争,从而提高性能。由于任务首先被放入队列中,工作线程可以在合适的时间批量处理这些任务,这减少了对时间轮数据结构的频繁锁定和同步操作。
7.时间轮的优点和缺点
7.1优点
- 高效的插入和过期检查: 添加新任务到时间轮的操作是常数时间复杂度(O(1)),而检查过期任务也是常数时间复杂度,因为只需要检查当前槽位的任务列表。
- 可配置的时间粒度: 时间轮的槽数量(时间粒度)是可配置的,可以根据应用程序的需要调整定时器的精度和资源消耗。
- 处理大量定时任务: HashedWheelTimer尤其适合于需要处理大量定时任务的场景,例如网络应用中的超时监测。
7.2缺点
- 有限的时间精度: 由于时间轮是以固定的时间间隔来划分的,所以它的时间精度受到槽数量和槽间隔的限制,不能提供非常高精度的定时(如毫秒级以下)。这是小根堆优于时间轮的地方
- 槽位溢出: 单个槽位可能会有多个任务同时过期,如果过期任务的数量非常大,可能会导致任务处理的延迟。这里netty使用线程去执行任务,但是线程池可能存在没用可用线程带来的延迟
- 系统负载敏感: 当系统负载较高时,定时器的准确性可能会降低,因为HashedWheelTimer的工作线程可能无法准确地按照预定的时间间隔推进时间轮。
- 任务延迟执行: 如果任务在其预定的执行时间点添加到时间轮,可能会出现任务执行时间稍微延后的情况,因为会先塞到MPSC然后等下一个tick才被放到bucket然后才能被执行。
在选择使用HashedWheelTimer时,需要根据应用场景的具体需求权衡这些优缺点。对于需要处理大量网络超时检测的场景,HashedWheelTimer常常是一个合适的选择。然而,如果应用程序需要高度精确的定时器,或者对任务执行的实时性有严格的要求,可能需要考虑ScheduledThreadPoolExecutor(Timer就是个垃圾doge)。
五丶思考
ScheduledThreadPoolExecutor和HashedWheelTimer 各有优劣,需要根据使用场景进行权衡
- 关注任务调度的及时性:选择ScheduledThreadPoolExecutor
- 存在大量调度任务:选择HashedWheelTimer
二者的特性又是由其底层数据结构决定
- 为了维持小根堆的特性,每次向ScheduledThreadPoolExecutor中新增任务都需要进行调整,在存在大量任务的时候,这个调整的开销maybe很大(都是内存操作,感觉应该还好)
- 为了让任务的新增时间复杂度是o(1),HashedWheelTimer 利用hash和数组o(1)的寻址能力,但是也是因为数组的设计,导致任务的执行需要依赖workerThread每隔一个tick进行调度,丧失了一点任务执行的及时性
这一篇最大的收获还是ScheduleThreadPoolExecutor中使用的leader-follower模式,以及HashedWheelTimer中mpsc 运用,二者都是在减少无意义的锁竞争!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: .net下优秀的MQTT框架MQTTnet使用方法,物联网通讯必备
MQTTnet 是一个高性能的MQTT类库,支持.NET Core和.NET Framework。 MQTTnet 原理: MQTTnet 是一个用于.NET的高性能MQTT类库,实现了MQTT协议的各个层级,包括连接、会话、发布/订阅、QoS(服务质量)等。…
