
标题党一下,顺便蹭一下 OpenAI Sora大模型的热点,主要也是回顾一下扩散模型的原理。
1. 简单理解扩散模型
简单理解,扩散模型如下图所示可以分成两部分,一个是 forward,另一个是 reverse 过程:
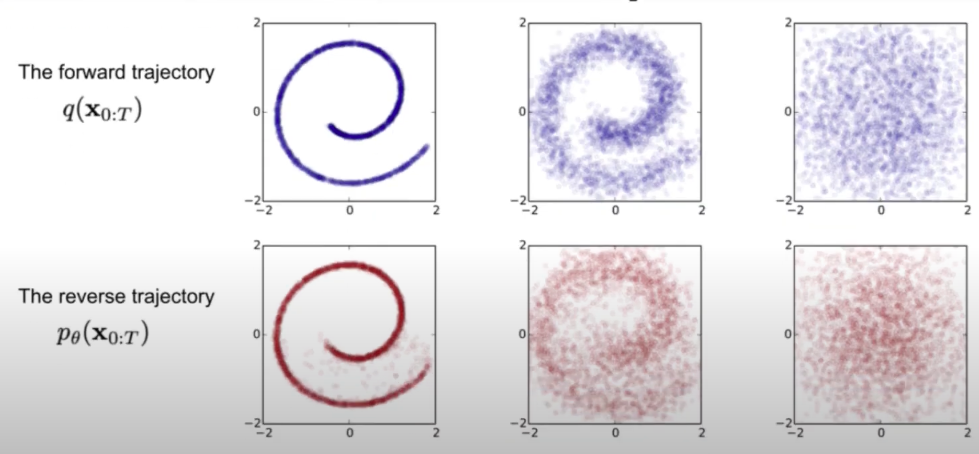
- forward:这是加噪声的过程,表示为(q(X_{0:T})),即在原图(假设是(t_0)时刻的数据,即(X_0))的基础上分时刻(一般是 T 个时刻)逐步加上噪声数据,最终得到(t_T)时刻的数据(X_T)。具体来说我们每次加一点噪声,可能加了 200 次噪声后得到服从正态分布的隐变量,即(X_t=X_0+ z_0+ z_1+…+ z_{t-1})每个时刻加的噪声会作为标签用来在逆向过程的时候训练模型。
- reverse:这很好理解,其实就是去噪过程,是(q(X_{0:T}))的逆过程,表示为(P_theta(X_{0:T})),即逐步对数据(X_T)逆向地去噪,尽可能还原得到原图像。逆向过程其实就是需要训练一个模型来预测每个时刻的噪声 (z_T),从而得到上一时刻的图像,通过迭代多次得到原始图像,即(X_0=X_t-z_t-z_{t-2}-…-z_1)。模型训练会迭代多次,每次的输入是当前时刻数据(X_t),输出是噪声(z_t),对应标签数据是(overline z_{t-1}),损失函数是(mse(z_t,overline z_{t-1}))
怎么理解这两个过程呢?一种简单的理解方法是我们可以假设世界上所有图像都是可以通过加密(就是 forward 过程)表示成隐变量,这些隐变量人眼看上去就是一堆噪声点。我们可以通过神经网络模型逐渐把这些噪声去掉,从而得到对应的原图(即 reverse 过程)。
2. 前向过程的数学表示

前向过程简单理解就是不断加噪声,加噪声的特点是越加越多:
- 前期加的噪声要少一点,这样是为了避免加太多噪声会导致模型不太好学习;
- 而当噪声量加的足够多后应该增加噪声的量,因为如果还是每次只加一点点,其实差别不大,而且这会导致前向过程太长,那么对应逆向过程也长,最终会增加计算量。所以噪声的量会有超参数(beta_t)控制。t 越大,(beta_t)的值也就越大。
那我们可以很自然地知道,t 时刻的图像应该跟 t-1时刻的图像和噪声相关,所以有
]
其中(alpha_t=1-beta_t), (z_1)是服从 (0,1) 正太分布的随机变量。常见的参数设置是(beta_t)从 0.0001 逐渐增加到0.002,所以(alpha_t)对应越来越小,也就是说噪声的占比逐渐增大。
我们同样有(X_{t-1}=sqrt{alpha_{t-1}}X_{t-2}+sqrt{1-alpha_{t-1}}z_2),此时我们有
X_{t},&=,{sqrt{a_{t}}}({sqrt{a_{t-1}}}X_{t-2}+{sqrt{1-alpha_{t-1}}}z_{2})+{sqrt{1-alpha_{t}}}z_1 \
&=sqrt{a_{t}a_{t-1}}X_{t-2}+(sqrt{(a_{t}(1-alpha_{t-1})}z_{2}+sqrt{1-alpha_{t}}z_{1}) \
&= sqrt{a_{t}a_{t-1}}X_{t-2}+sqrt{1-alpha_talpha_{t-1}}z_2 \
&= sqrt{a_{t}a_{t-1}}X_{t-2}+tilde{z}_2 notag
end{align}
]
因为(z_1,z_2)都服从正太分布,且(mathcal{N}(0,sigma_{1}^{2})+mathcal{N}(0,sigma_{2}^{2})simmathcal{N}(0,(sigma_{1}^{2}+sigma_{2}^{2}))),所以公式(2)的括号内的两项之和得到一个新的服从均值为 0, 方差是(sqrt{(a_{t}(1-alpha_{t-1})}^2+sqrt{1-alpha_{t}}^2=1-alpha_talpha_{t-1})的变量(tilde z_2simmathcal{N}(0,1-alpha_talpha_{t-1}))。
我们不断递归能够得到(X_t)和(X_0)的关系如下:
X_t&=sqrt{overline{alpha}_t}X_0+overline{z}_t \
&=sqrt{overline{alpha}_t}X_0+sqrt{1-overline{alpha}_t}{z}_t
end{align}
]
其中(overline{alpha}_t=alpha_talpha_{t-1}…alpha_{1}), (overline{z}_t)是均值为 0,方差(sigma=1-overline{alpha}_t)的高斯变量, (z_t)服从(0,1)正态分布。可以看到给定0 时刻的图像数据(X_0),我们可以求得任意t时刻的(overline{alpha}_t)和与之有关的(overline z_t),进而得到对应的(X_t)数据,至此前向过程就结束了。
3. 逆向过程的数学表示
3.1 贝叶斯公式求解
扩散模型在应用的时候主要就是 reverse 过程,即给定一组随机噪声,通过逐步的还原得到想要的图像,可以表示为(q(X_0|X_t))。但是很显然,我们无法直接从 T 时刻还原得到 0 时刻的数据,所以退而求其次,先求(q(X_{t-1}|X_t))。但是这个也没那么容易求得,但是由贝叶斯公式我们可以知道
]
我们这里考虑扩散模型训练过程,我们默认是知道(X_o)的,所以有
]
解释一下上面的公式:因为我们可以人为设置噪声分布,所以正向过程中每个时刻的数据也是知道的。例如,假设噪声(z)是服从高斯分布的,那么(X_1=X_0+z),所以(q(X_1,X_0))是可以知道的,同样(q(X_{t-1},X_0),q(X_t,X_0))也都是已知的服务器托管网,更一般地,(q(X_t|X_{t-1},X_0))也是已知的。所以上面公式的右边三项都是已知的,要计算出左边的结果,就只需要分别求出右边三项的数学表达式了。
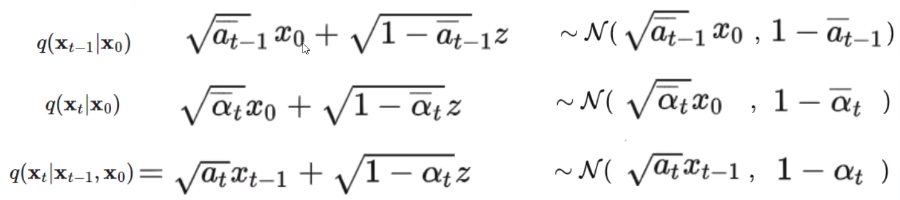
上面三个公式是推导后的结果,省略了亿些步骤,我们待会解释怎么来的,这里先简单解释一下含义,我们看第一行,(z)就是服从正态分布(均值为 0,方差为 1)的变量,为方便理解其它的可以看成常数,我们知道 (a+sqrt{b}z)会得到均值为 a,方差为 b 的服从高斯分布的变量,那么第一行最右边的高斯分布应该就好理解了。其余两行不做赘述,同理。
3.2 高斯分布概率密度分布计算
下面公式中左边的概率分布其实就是右边三项概率分布的计算结果。
]
我们假设了噪声数据服从高斯分布(mathcal{N}(mu,sigma^2)),并且知道高斯分布的概率密度函数是(exp{(-frac{1}{2}frac{(x-mu)^2}{sigma^2})})。结合上面已经给出的三项的高斯分布情况,例如
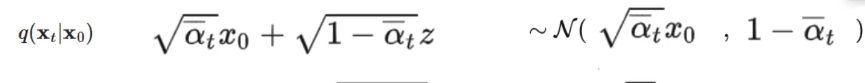
我们可以求得(q(X_t|X_0))的概率密度函数为(exp(-frac{1}{2}frac{(X_t-sqrt{overline{a_t}}X_0)^2}{1-overline{a_t}})),其它两项同理,它们计算后得到的最终的概率密度函数为:
]
其中上面公式中(beta_t=1-alpha_t)。接着我们把上面公式的平方项展开,以(X_{t-1})为变量(因为此时我们的目的是求得(X_{t-1}))合并同类项整理一下最后可以得到
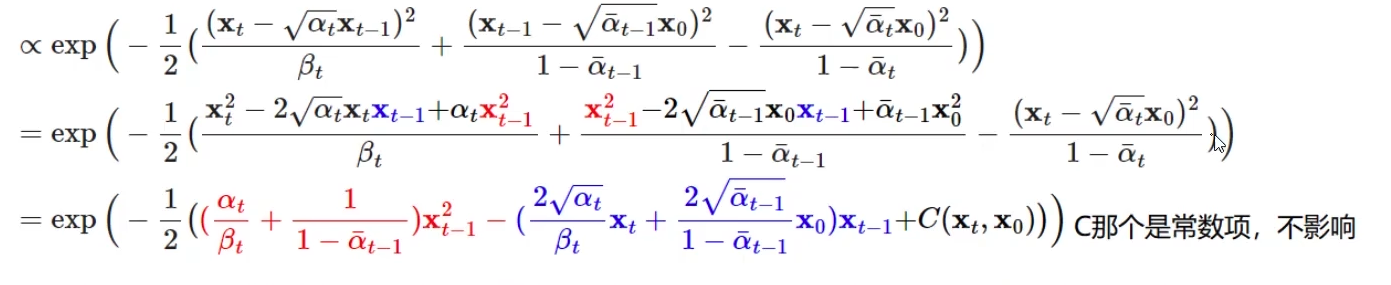
我们在对比一下(exp{(-frac{1}{2}frac{(x-mu)^2}{sigma^2})}=exp(-frac{1}{2}(frac{1}{sigma^2}x^2-frac{2mu}{sigma^2}x+frac{mu^2}{sigma^2})))就能知道上面公式中对应的方差和均值:
- 方差
]
方差等式中的(alpha,beta)都是与分布相关的固定值,即给定高斯分布后,这些变量的值是固定的,所以方差是固定值。
- 均值
]
均值跟(X_t)和(X_0)有关 ,但是此时的已知量是(X_t),而(X_0)是未知的。不过我们可以估计一下(X_0)的值,通过前向过程我们知道 (X_t=sqrt{overline{a}_t}X_0+sqrt{1-overline{a}_t}z_t),那么可以逆向估计一下 (X_0=frac{1}{sqrt{overline{a}_t}}(X_t-sqrt{1-overline{a}_t}z_t))。不过需要注意的是,这里的(X_0)只是通过(X_t)估算得到的,并不是真实值。所以均值表达式还可以进一步简化,即
]
每个时刻的均值和方差的表达式就都有了。不过,每个时刻的方差是个定值,很容易求解,而均值却跟变量(z_t)相关。如果能求解得到(z_t),那么只要给定一个t 时刻的随机噪声填满的图像(X_t),我们就能知道该时刻噪声的均值和方差,那么我们就可以通过采样得到上一时刻的噪声数据
]
(epsilon)是服从(0,1)的正态分布的随机变量。至此,我们只需要引入神经网络模型来预测 t 时刻的(z_t),即(z_t=text{diffusion_model}(x_t)),模型训练好后就能得到前一时刻的(X_{t-1})了。
那么要训练模型,我们肯定得有标签和损失函数啊。具体而言:
- (x_t)是模型的输入
- (z_t)就是模型的输出
- 标签其实就是 forward 过程中每个时刻产生的噪声数据(hat{z}_t)
- 所以损失函数等于(text{loss}=mse(z_t, hat{z}_t))
4. 代码实现
接下来我们结合代码来理解一下上述过程。
4.1 前向过程(加噪过程)
给定原始图像(X_0)和加噪的超参数(alpha_t=1-beta_t)可以求得任意时刻对应的加噪后的数据(X_t),即
X_t&=sqrt{overline{alpha}_t}X_0+overline{z}_t\
&=sqrt{overline{alpha}_t}X_0+sqrt{1-overline{alpha}_t}{z}_t
end{align}
]
其中(overline{alpha}_t=alpha_talpha_{t-1}…alpha_{1}), (overline{z}_t)是均值为 0,标准差(sigma=sqrt{1-overline{alpha}_t})的高斯变量。
下面是具体的代码实现,首先是与噪声相关超参数的设置和提前计算:
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
from torchvision import transforms
# 定义线性beta时间表
def linear_beta_schedule(timesteps, start=0.0001, end=0.02):
# 在给定的时间步数内,线性地从 start 到 end 生成 beta 值
return torch.linspace(start, end, timesteps)
T = 300 # 总的时间步数
betas = linear_beta_schedule(timesteps=T) # ,迭代100个时刻
# 预计算不同的超参数(alpha和beta)
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, axis=0) # 累积乘积
alphas_cumprod_prev =服务器托管网 F.pad(alphas_cumprod[:-1], (1, 0), value=1.0) # 前一个累积乘积
sqrt_recip_alphas = torch.sqrt(1.0 / alphas) # alpha的平方根倒数
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod) # alpha累积乘积的平方根
sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - alphas_cumprod) # 1-alpha累积乘积的平方根
posterior_variance = betas * (1.0 - alphas_cumprod_prev) / (1.0 - alphas_cumprod) # 计算后验分布q(x_{t-1}|x_t,x_0)的方差
接下来是具体的前向过程的计算,其中get_index_from_list函数是为了快速获得指定 t 时刻对应的超参数的值,支持批量图像操作。forward_diffusion_sample则是前向扩散采样函数。
def get_index_from_list(vals, time_step, x_shape):
"""
返回传入的值列表vals(如_t 或者_t)中特定时刻t的值,同时考虑批量维度。
参数:
vals: 一个张量列表,包含了不同时间步的预计算值。
time_step: 一个包含时间步的张量,其值决定了要从vals中提取哪个时间步的值。
x_shape: 原始输入数据的形状,用于确保输出形状的一致性。
返回:
一个张量,其形状与原始输入数据x_shape相匹配,但是在每个批次中填充了特定时间步的vals值。
"""
batch_size = time_step.shape[0] # 获取批量大小
out = vals.gather(-1, time_step.cpu()) # 从vals中按照时间步收集对应的值
# 重新塑形为原始数据的形状,确保输出与输入在除批量外的维度上一致
return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(time_step.device)
# 前向扩散采样函数
def forward_diffusion_sample(x_0, time_step, device="cpu"):
"""
输入:一个图像和一个时间步
返回:图像对应时刻的噪声版本数据
"""
noise = torch.randn_like(x_0) # 生成和x_0形状相同的噪声
sqrt_alphas_cumprod_t = get_index_from_list(sqrt_alphas_cumprod, time_step, x_0.shape)
sqrt_one_minus_alphas_cumprod_t = get_index_from_list(sqrt_one_minus_alphas_cumprod, time_step, x_0.shape)
# 计算均值和方差
return sqrt_alphas_cumprod_t.to(device) * x_0.to(device) + sqrt_one_minus_alphas_cumprod_t.to(device) * noise.to(
device
), noise.to(device)
image = Image.open('xiaoxin.jpg').convert('RGB')
img_tensor = transforms.ToTensor()(image)
for idx in range(T):
time_step = torch.Tensor([idx]).type(torch.int64)
img, noise = forward_diffusion_sample(img_tensor, time_step)
plt.imshow(transforms.ToPILImage()(img)) # 绘制加噪图像
4.2 训练

我们忽略具体的模型结构细节,先看看训练流程是怎样的:
if __name__ == "__main__":
model = SimpleUnet()
T = 300
BATCH_SIZE = 128
epochs = 100
dataloader = load_transformed_dataset(batch_size=BATCH_SIZE)
device = "cuda" if torch.cuda.is_available() else "cpu"
logging.info(f"Using device: {device}")
model.to(device)
optimizer = Adam(model.parameters(), lr=0.001)
for epoch in range(epochs):
for batch_idx, (batch_data, _) in enumerate(dataloader):
optimizer.zero_grad()
# 对一个 batch 内的数据采样任意时刻的 time_step
t = torch.randint(0, T, (BATCH_SIZE,), device=device).long()
x_noisy, noise = forward_diffusion_sample(batch_data, t, device) # 计算得到指定时刻的 加噪后的数据 和 对应的噪声数据
noise_pred = model(x_noisy, t) # 预测对应时刻的噪声
loss = F.mse_loss(noise, noise_pred) # 计算噪声预测的损失值
loss.backward()
optimizer.step()
这里我们忽略模型架构的具体细节,只需要知道每次模型的计算需要 噪声图像(x_noisy) 和 对应的时刻t即可。
4.2 逆向过程(去噪采样过程)

给定某一时刻的数据(X_t),该时刻的均值(mu)和方差(sigma)如下
]
]
通过对(mathcal{N}(tildemu_t,tildesigma_t^2))分布进行采样得到上一时刻的数据(X_{t-1}=tildemu_t+tildesigma_tepsilon),(z_t)是模型训练收敛后,在给定噪声图像和对应时刻 t 后计算得到的噪声数据,(epsilon)是正态分布随机变量。
实现代码如下:
@torch.no_grad()
def sample_timestep(model, x, t):
"""
使用模型预测图像中的噪声,并返回去噪后的图像。
如果不是最后一个时间步,则在此图像上应用噪声。
参数:
model - 预测去噪图像的模型
x - 当前带噪声的图像张量
t - 当前时间步的索引(整数或者整数型张量)
返回:
去噪后的图像张量,如果不是最后一步,返回添加了噪声的图像张量。
"""
# 从预设列表中获取当前时间步的beta值
betas_t = get_index_from_list(betas, t, x.shape)
# 获取当前时间步的累积乘积的平方根的补数
sqrt_one_minus_alphas_cumprod_t = get_index_from_list(sqrt_one_minus_alphas_cumprod, t, x.shape)
# 获取当前时间步的alpha值的平方根的倒数
sqrt_recip_alphas_t = get_index_from_list(sqrt_recip_alphas, t, x.shape)
# 调用模型来预测噪声并去噪(当前图像 - 噪声预测)
model_mean = sqrt_recip_alphas_t * (x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t)
# 获取当前时间步的后验方差
posterior_variance_t = get_index_from_list(posterior_variance, t, x.shape)
if t == 0:
# 如Luis Pereira在YouTube评论中指出的,论文中的时间步t有偏移
return model_mean
else:
# 生成与x形状相同的随机噪声
noise = torch.randn_like(x)
# 返回模型均值加上根据后验方差缩放的噪声
return model_mean + torch.sqrt(posterior_variance_t) * noise
for i in reversed(range(0, T)):
t = torch.tensor([i], device='cpu', dtype=torch.long)
img = sample_timestep(model, img, t)
5. 总结
- 前向过程:
给定原始图像(X_0)和加噪的超参数(alpha_t=1-beta_t)可以求得任意时刻对应的加噪后的数据(X_t),即
X_t&=sqrt{overline{alpha}_t}X_0+overline{z}_t\
&=sqrt{overline{alpha}_t}X_0+sqrt{1-overline{alpha}_t}{z}_t
end{align}
]
其中(overline{alpha}_t=alpha_talpha_{t-1}…alpha_{1}), (overline{z}_t)是均值为 0,标准差(sigma=sqrt{1-overline{alpha}_t})的高斯变量。
- 逆向过程
给定某一时刻的数据(X_t),该时刻的均值(mu)和方差(sigma)如下
]
]
通过对(mathcal{N}(tildemu_t,tildesigma_t^2))分布进行采样得到上一时刻的数据(X_{t-1}=tildemu_t+tildesigma_tepsilon),(z_t)是模型训练收敛后,在给定噪声图像和对应时刻 t 后计算得到的噪声数据,(epsilon)是正态分布随机变量。迭代 t 次后即可得到 0 时刻的图像了。
参考
- 文章参考:https://www.bilibili.com/video/BV14o4y1e7a6/?vd_source=ab1abaf624904be0ec84e180d5b6bd9a
- 代码参考:https://github.com/chunyu-li/ddpm/blob/HEAD
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
