
一、概述
最近 ChatGPT 和其公司 OpenAI 特别火:ChatGPT 3, ChatGPT 3.5, New Bing, ChatGPT 4…
怀着学习的心态,这几天访问了 OpenAI 的博客, 上边关于 AI 的内容,确实隔行如隔山,完全看不明白。😂
但是翻看过程中,惊喜发现有 2 篇与 Kubernetes 使用相关的文章:
- 2018 年 1 月:Scaling Kubernetes to 2,500 nodes (openai.com)
- 2021 年 1 月:Scaling Kubernetes to 7,500 nodes (openai.com)
这不碰到老本行了嘛,学习下~
以下为读后笔记,也加入了自己的思考:针对 OpenAI 现状,如何进一步优化监控、镜像拉取、容器编排相关架构。
二、读后笔记
2.1 Dota 2 的 OpenAI 是跑在 Kubernetes 上的

💪💪💪
Dota2 游戏镜像大约是 17GB😛
2.2 OpenAI 如何使用 Kubernetes
2.2.1 用途
Kubernetes 在 OpenAI 主要用于深度学习,主要使用的是 Kubernetes Job.
2.2.2 选择 Kubernetes 原因
Kubernetes 提供了
- 快速的迭代周期
- 合理的可扩展性
- 标准样板
2.2.3 Kubernetes 集群规模
- 集群运行在 AZure 上
- 2018 年博文,集群 Node 规模为 2500 多
- 2021 年博文,集群 Node 规模为 7500 多
2.2.4 Kubernetes 超大规模使用过程中遇到的问题
- etcd
- Kube masters
- Docker 镜像拉取
- 网络
- KubeDNS
- 机器的 ARP 缓存
2.2.5 Kubernetes 配套工具
-
监控:
- DataDog(商业监控)
- Prometheus + Grafana
-
日志:
- fluentd
-
网络:
- 刚开始是 Flannel
- 后面是 Azure 的 VMSSes CNI 插件
2.3 Kubernetes 超大规模发现的问题及解决
2.3.1 Etcd
2.3.1.1 问题描述
集群 500 节点后,刚开始是 kubectl 使用卡;另外通过 DataDog 监控发现磁盘写入延迟飙升至数百 ms,尽管每台机器都使用 30,5 IOPS 的 P000 SSD。
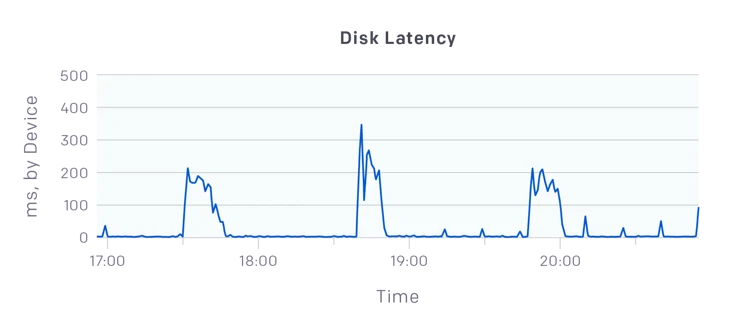
后面解决之后,加到 1000 节点,发现 etcd 延迟再次变高;发现 kube-apiservers 从 etcd 读取的速率超过 500MB/s
另一个 1,000 个节点后的故障是达到了 etcd 的硬存储限制(默认为 2GB),这导致它停止接受写入。
2.3.1.2 解决方案
- 将每个节点的 etcd 目录移动到本地临时磁盘,该临时磁盘是直接连接到实例的 SSD,而不是网络连接的 SSD。切换到本地磁盘使写入延迟达到 200us,etcd 变得健康!(根据我们之前的 Azure 使用经验,其网络 SSD 确实性能不太行😂)
-
1000 节点时出现的问题,在于
- 启用了审计日志
- 启用了 Prometheus 对 APIServer 的监控
- 这导致出现了许多缓慢的查询和对事件的 LIST API 的过度调用
- 根本原因:默认设置 fluentd 和 Datadog 的监控过程是从集群中的每个节点查询 API 服务器。”我们”只是简单地更改了这些进程,使其轮询不那么激进,并且 apiserver 上的负载再次变得稳定
- 将 Kubernetes Events 存储在一个单独的 etcd 集群中,这样事件创建中的峰值不会影响主 etcd 实例的性能。配置如后面的代码段
- 我们用标志
--quota-backend-bytes增加了最大 etcd 大小。
--etcd-servers-overrides=/events#https://0.example.com:2381;https://1.example.com:2381;https://2.example.com:2381最后,etcd 和 APIServer 都运行在专用节点上。避免相互影响。
在 7500 节点时,有 5 个 etcd 节点。
2.3.2 API Server
在 7500 节点时,有 5 个 API 服务器,并且每个 API 服务器使用的堆内存高达 70GB.
2.3.3 Docker 镜像拉取
2.3.3.1 问题描述
Dota 容器会在一段时间内处于 pending 状态——但对于其他容器也是如此。
解决之后,发现有报错:rpc error: code = 2 desc = net/http: request canceled, 表明由于缺乏进度,镜像拉取已被取消。
还有个问题,OpenAI 的 Kubernetes 组件镜像是默认从 gcr.io 拉取的,但是 gcr.io 可能失败或超出配额(机器用的 NAT 公网 IP 是同一个,很容易超出配额).
2.3.3.2 解决方案
kubelet 有一个 --serialize-image-pulls 默认为 true 的标志,表示 Dota 镜像拉取阻塞了所有其他镜像。
将 --serialize-image-pulls 改为 false; 将 Docker 根目录移动到了实例附加的 SSD(而不是网络 SSD)
针对第二个问题,大镜像需要太长时间的 pull 和提取,或者当有大量积压的镜像需要拉取时。为了解决这个问题,我们将 kubelet 的 --image-pull-progress-deadline 标志设置为 30 分钟,并将 Docker 守护进程的 max-concurrent-downloads 选项设置为 10。第二个选项没有加快大镜像的提取速度,但允许镜像队列并行拉取。
为了解决这个 gcp.io 失败的问题,”我们”通过使用 docker image save -o /opt/preloaded_docker_images.tar 和docker image load -i /opt/preloaded_docker_images.tar,在 Kubernetes worker 的机器镜像中预装了这些 Docker 镜像。 为了提高性能,我们对常见的 OpenAI 内部镜像如 Dota 镜像的白名单做了同样的处理。
2.3.3.3 🤔笔者思考
关于 OpenAI 碰到的 Docker 镜像拉取的问题,都是非常典型的大规模 Kubernetes 会碰到的问题,其实有更好的解决方案:P2P 镜像解决方案,典型就是 DragonFly.
DragonFly 提供高效、稳定、安全的基于 P2P 技术的文件分发和镜像加速系统,并且是云原生架构中镜像加速领域的标准解决方案以及最佳实践。其最大的优势就是:
- 基于 P2P 的文件分发:通过利用 P2P 技术进行文件传输,它能最大限度地利用每个对等节点(Peer)的带宽资源,以提高下载效率,并节省大量跨机房带宽,尤其是昂贵的跨境带宽。
- 预热:P2P 加速可预热两种类型数据 image 和 file, 用户可以在控制台操作或者直接调用 api 进行预热。
2.3.4 网络
Flannel 在这种超大规模场景下肯定是撑不住的,刚开始 OpenAI 采用了非常简单暴力的解决方案(也适合他们的使用场景): pod 配置使用 HostNetwork:
...
hostNetwork: true
...
dnsPolicy: ClusterFirstWithHostNet后面是改为使用 Azure 的 VMSSes CNI 插件。
2.3.4.1 🤔笔者思考
其实 OpenAI 对 Kubernetes 的刚需是:容器编排,网络功能不是刚需,OpenAI 不用 Kubernetes CNI 也可以的。后面会延伸讨论一下。
2.3.5 ARP 缓存
另外一个可能经常会忽略的点是 ARP 缓存问题。
2.3.5.1 问题描述
有一天,一位工程师报告说,他们的 Redis 服务器的 nc -v 需要 30 多秒才能打印出连接已经建立。我们追踪到这个问题是由内核的 ARP 栈引起的。对 Redis pod 主机的初步调查显示,网络出了严重的问题:任何端口的通信都要挂上好几秒,而且无法通过本地 dnsmasq 守护进程解析 DNS 名称,dig 只是打印了一条神秘的失败信息:socket.c:1915: internal_send: 127.0.0.1#53: Invalid argument。dmesg 日志的信息量更大:neighbor table overflow! 这意味着 ARP 缓存的空间已经用完。ARP 是用来将网络地址(如 IPv4 地址)映射到物理地址(如 MAC 地址)的。
2.3.5.2 解决方案
在/etc/sysctl.conf中设置选项:
net.ipv4.neigh.default.gc_thresh1 = 80000
net.ipv4.neigh.default.gc_thresh2 = 90000
net.ipv4.neigh.default.gc_thresh3 = 100000在 Kubernetes 集群中调整这些选项尤其重要,因为每个 pod 都有自己的 IP 地址,会消耗 ARP 缓存的空间。
2.3.6 Prometheus 和 Grafana
由于大量的采集和查询,Prometheus 和 Grafana OOM 的频率也不低。
2.3.6.1 解决方案
-
Grafana: 本质上还是 Prometheus 的高基数问题,我之前介绍过,见这里:
- Prometheus 性能调优 – 什么是高基数问题以及如何解决?- 东风微鸣技术博客 (ewhisper.cn)
-
Prometheus: 重启后,WAL replay 是个问题,在 Prometheus 收集新指标和服务查询之前,通常需要花费数小时才能 replay 所有 WAL 日志。
- 使用
GOMAXPROCS=24配置,在 WAL replay 期间,Prometheus 试图使用所有的内核,对于拥有大量内核的服务器来说,这种争夺会扼杀所有的性能。
- 使用
2.3.6.2 🤔笔者思考
- Prometheus 近期版本性能会好很多,及时升级到最新版本会对性能问题大有帮助。比如:高基数,大内存,cpu 消耗较多等都有一定程度优化。
- Prometheus 在这么大规模集群情况下,建议创建多个 node role 为 monitoring 的高配机器(也挂本地 SSD), 供 Prometheus 专用。
- 或者更近一步,可以选择兼容 Prometheus 的其他方案,如:VictoriaMetrics(适合存储为块存储场景) 和 Grafana Labs 发布的 Mimir(适合存储为对象存储场景).
2.4 OpenAI Kubernetes 的使用场景及推荐的替换方案
这里详细描述一下 OpenAI Kubernetes 的使用场景:
- 主要用到的资源类型是 Job
- 对于 OpenAI 的许多工作负载,单个 Pod 占据了整个节点
- OpenAI 当前的集群具有完整的平分带宽,不会考虑任何机架或网络拓扑
- OpenAI 不太依赖 Kubernetes 负载均衡,HTTPS 流量很少,不需要 A/B 测试,蓝/绿或金丝雀
- Pod 通过 SSH 使用 MPI 在其 Pod IP 地址上直接相互通信 (hostNetwork),而不是通过 service endpoint 进行通信
- 服务发现是有限的
- 有一些 PersistentVolume,但 blob 存储的可伸缩性要高得多
- 避免使用 Overlay 网络,因为会影响网络性能
2.4.1 🤔笔者思考
看完 Scaling Kubernetes to 7,500 nodes (openai.com) 这篇,其实会发现 OpenAI 对 Kubernetes 的使用和普通 IT 公司差异还是比较大的。
OpenAI 最主要用的是:Kubernetes 的容器编排, 特别是对 Job 的调度能力。
其他 Kubernetes 功能,用的很少或几乎没有,如:
- 存储 CSI 用的很少,主要使用的是 blob 存储
- 网络 CNI 用了,但 Pod 主要用的是 hostNetwork
- DNS 用的也不多
- Service 用的很少,Pod 主要用的是 hostNetwork
- Ingress (即上文说的 Kubernetes 负载均衡)用的很少,因为 Kubernetes 集群主要用于实验(现在随着 ChatGPT 的大规模使用可能会用的比之前多一些)
- Kubernetes 的一些高级发布策略,如 A/B 测试,蓝/绿或金丝雀也不需要
所以我个人认为(观点仅供参考), Kubernetes 对于 OpenAI 来说,还是有些过于复杂和功能冗余的。
OpenAI 真正需要的,是一个纯粹的容器编排解决方案,特别是对 Job 的调度能力。
所以我觉得啊,不考虑用户规模,不考虑 Kubernetes 是容器编排领域的事实上的标准的话,HashiCorp 的 Nomad 反而是更合适的解决方案。以下是具体理由:
- Nomad 是一个易于使用、灵活和高性能的工作负载调度器,可以部署混合的微服务、批处理、容器化和非容器化应用。
- GPU 支持:Nomad 为 GPU 工作负载(如机器学习(ML)和人工智能(AI))提供内置支持。Nomad 使用设备插件来自动检测和利用来自硬件设备(如 GPU、FPGA 和 TPU)的资源。
- 经过验证的可扩展性:Nomad 乐观地并发,可提高吞吐量并减少工作负载的延迟。Nomad 已被证明可以在实际生产环境中扩展到 10K+ 节点的集群。
- 简单性:Nomad 作为单个进程运行,外部依赖性为零。 运维人员可以轻松配置、管理和扩展 Nomad。开发人员可以轻松 定义并运行应用程序。
- Nomad 的其中 2 个 调度器: Batch 和 System Batch, 非常契合 OpenAI 的使用场景。
- Nomad 并不附带服务发现及网络的相关功能,只是在 1.3 版本以后, 增加了内置的本地服务发现(SD),使得 Consul 或其他第三方工具非必要。Nomad 的服务发现并不是要取代这些工具。相反,它是一个替代品,可以更容易地测试和部署更简单的架构。

2.5 横向扩展小技巧
另外,惊喜的发现 OpenAI 的博文中竟然提到了 Kubernetes 横向扩展的小技巧,OpenAI 将其称为:CPU & GPU balloons.
笔者这里详细向大家介绍一下:
2.5.1 横向扩展的时间悖论
首先,OpenAI 的横向扩展需求涉及 2 个层面:
- Kubernetes 集群层面的 Node 扩展,通过 Cluster AutoScaler 实现(这里 OpenAI 用的是自己开发的,一般各个公有云都提供对应的 Cluster AutoScaler 插件), 为的是快速横向扩展 Node
- Pod 层面的 横向扩展 (HPA), 为的是快速横向 Pod 的数量。
但是,在流量或业务量飙升的情况下,Node (也就是云虚拟机)的扩展并不像 Pod 那么迅速,一般是需要几分钟的初始化和启动的时间,进而影响到 Pod 的横向扩展,导致无法及时响应业务飙升的需求。
2.5.2 解决方案概述
为此,解决方案就是 CPU & GPU balloons, 具体如下:
在新 Node 上创建新 Pod 所需的时间由四个主要因素决定:
- HPA(Horizontal Pod Autoscaler) 响应时间。
- Cluster Autoscaler 响应时间。
- Node 配置时间
- Pod 创建时间
这里主要耗时是 Node 配置的时间,这主要取决于云提供商。
一个新的计算资源在 3 到 5 分钟内完成配置是很标准的。
在新 Node 上创建新 Pod 所需的时间预估需要 7 min 左右。
如果你需要一个新的 Node,你如何调整自动缩放以减少 7 分钟的缩放时间?
大部分时间花在了 Node 配置上,由于你不能改变云供应商提供资源的时间,所以就需要一个变通办法:
即:主动创建节点(超配),这样当你需要它们时,它们已经被配置好了。
始终确保有一个备用节点可用:
- 创建一个节点并将其留空(其实是放置一个 balloon pod 来占用该节点)。
- 如果空节点中有 Pod (非 balloon pod) 就会创建另一个空节点。
这里,可以运行具有足够 requests 的 deployment 来保留整个节点。
可以将此 pod 视为占位符 — 它旨在保留空间,而不是使用任何资源。
一旦创建了一个真正的 Pod,您就可以逐出占位符并部署 Pod。
具体怎么实现呢?
2.5.3 具体实现
- 具有 requests 的 Pod
- Pod 部署优先级 (PodPriorityClass) 和抢占
如果您的节点实例是 2 vCPU 和 8GB 内存,那么 Pod 的可用空间应该为 1.73 vCPU 和 ~5.9GB 内存 (OS, kubelet, kubeproxy 等需要预留一定资源),以使得 Pod 独占该 Node。
具体资源需求可以如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: registry.k8s.io/pause
resources:
requests:
cpu: '1739m'
memory: '5.9G'然后,要确保在创建真正的 Pod 后立即逐出该 Pod,需要使用 优先级和抢占。
Pod 优先级表示 Pod 相对于其他 Pod 的重要性。
当无法调度 Pod 时,调度程序会尝试抢占(逐出)优先级较低的 Pod 来调度挂起的(优先级较高的) Pod。
可以使用 PodPriorityClass 在集群中配置 Pod 优先级:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: 'Priority class used by overprovisioning.'由于 Pod 的默认优先级是 0,而超配的 PriorityClass 的值是 -1,所以当集群的空间耗尽时,这个 Pod 会被首先驱逐。
之前的 Deployment 可以调整为:(spec 中 增加 priorityClassName 为 overprovisioning)
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: reserve-resources
image: registry.k8s.io/pause
resources:
requests:
cpu: '1739m'
memory: '5.9G'当集群中没有足够的资源时,占位的 pod 会被抢占,新的 pod 会取代它们的位置。
由于占位 pod 变得不可调度,它迫使 Cluster Autoscaler 向集群添加更多节点。
🎉🎉🎉
三、总结
本文通过学习 OpenAI 博客中 Kubernetes 相关博文,学到了很多超大规模 Kubernetes 集群下的调优技巧。
在这里梳理了 OpenAI 遇到的性能问题及解决方案,同时就横向扩展小技巧(占位🎈) 进行了详细说明。
同时,结合笔者的经验,也做出一些延伸思考:
-
在 Kubernetes 集群中,
- Metrics 监控:推荐使用 VictoriaMetrics 和 Grafana Labs 发布的 Mimir 替换 Prometheus
- 镜像工具:推荐使用 DragonFly, 利用 P2P 和预热功能缓解镜像拉取问题
- 在容器/批处理编排调度解决方案中,可以尝试选择 HashiCorp 的 Nomad 替换 Kubernetes.
以上。
参考文档
- Scaling Kubernetes to 2,500 nodes (openai.com)
- Scaling Kubernetes to 7,500 nodes (openai.com)
- Prometheus 性能调优 – 什么是高基数问题以及如何解决?- 东风微鸣技术博客 (ewhisper.cn)
- 大规模 IoT 边缘容器集群管理的几种架构 -2-HashiCorp 解决方案 Nomad – 东风微鸣技术博客 (ewhisper.cn)
- Architecting Kubernetes clusters — choosing the best autoscaling strategy (learnk8s.io)
- Grafana 系列文章(一):基于 Grafana 的全栈可观察性 Demo(包括 Mimir) – 东风微鸣技术博客 (ewhisper.cn)
三人行, 必有我师; 知识共享, 天下为公. 本文由东风微鸣技术博客 EWhisper.cn 编写.
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
