

当前,科学计算需求急剧增加,基于CPU-GPU异构系统的异构计算在科学计算领域得到了广泛应用,OpenCL由于其跨平台特性在异构计算领域渐为流行,其调度困难的问题也随之暴露,传统的OpenCL任务调度需要在编码阶段确定调度方案,这种人工调度难度高、适应性差、效率低下、且存在资源竞争问题。MultiCL通过扩展OpenCL标准使得命令队列和设备解耦,实现了自适应调度,并为不同程度的开发人员提供了不同的调度方法,缓解了OpenCL的调度难题。
1 OpenCL基本介绍
Open服务器托管网CL是第一个面向异构系统通用目的并行编程的开放式、免费标准,适用于跨CPU、GPU和其他处理器的异构混合编程。OpenCL通过创建一个高效的、底层的编程接口,实现了独立于硬件、操作系统和应用程序的并行计算生态系统的基础层。OpenCL用于协调主机和支持OpenCL标准的异构计算设备间的并行计算,并且具有明确的跨平台编程语言。
OpenCL是在异构系统上进行编程的行业标准。OpenCL不仅仅是一种编程语言,更是用于异构系统编程的行业标准框架。相较于CUDA,OpenCL程序可在不同供应商的硬件上移植,具有良好的功能可移植性。但是由于OpenCL作为一个底层通用框架,为程序员开放了大量硬件细节,这样的好处是编程人员提供了大量的程序优化空间,但是也造成了OpenCL程序不具备良好的性能可移植性,即相同程序在移植过程中会造成极大的性能差异。同时对于程序员而言,任务的划分以及调度完全由编程人员指定,编程人员难以感知和预测整体系统的运行状态和负载情况,使得程序难以达到最优效率。
OpenCL架构为了实现跨平台的异构计算,包含以下部分:
- OpenCL平台层:OpenCL平台层允许主机程序发现OpenCL设备并调用该设备参与计算,并为特定设备或设备组创建上下文。
- OpenCL运行时:OpenCL运行时允许主机程序在上下文创建后对其进行操作,OpenCL运行时为OpenCL程序提供了软件支持。
- OpenCL编译器:OpenCL编译器根据内核和设备扩展信息将内核文件编译为可执行文件。编译器支持基于并行扩展的ISO C99(ISO/IEC 9899:1999-Programming languages)语言的子集。OpenCL编译器可根据即时编译和二进制加载两种方式创建可执行文件。
OpenCL架构可分为平台模型、执行模型、存储模型和编程模型。
2 MultiCL
OpenCL标准要求开发人员在程序编码阶段就确定OpenCL程序的调度方案,使OpenCL面临调度难度高、适应性差、资源竞争、效率低下等问题。为了解决上述问题Ashwin M等人在SunCL基础上进一步开发的OpenCL任务级并行调度框架,该框架提供了跨厂商的OpenCL运行时支持。MultiCL实现了上下文级别的全队列调度和针对特定命令队列的本地调度功能,作者以此为基础实现了OpenCL任务的动态调度。
OpenCL内核调度策略取决于编程模型,开发者必须事先明确程序中所包含的内核调度的方案,为了实现OpenCL的自适应任务调度,Ashwin M等人对OpenCL API进行了扩展。表1描述了MultiCL的扩展属性。
表1 MultiCL扩展属性
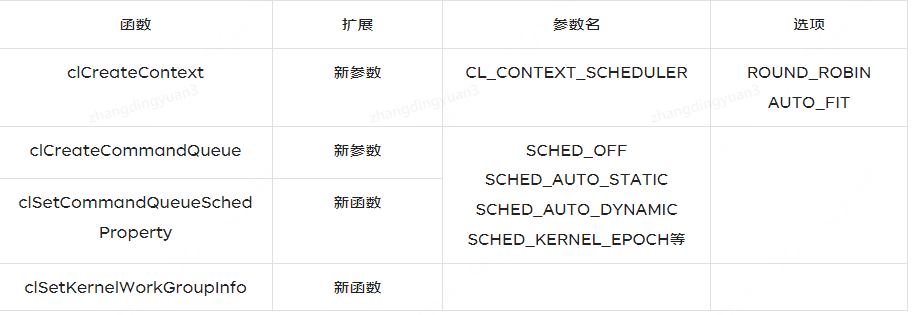
为了表达全局队列调度机制,MultiCL框架扩展了一个新的上下文属性CL_CONTEXT_SCHEDULER,该扩展属性实现了上下文级别的OpenCL自适应调度,采用CL_CONTEXT_SCHEDULER创建的上下文,该上下文关联的命令队列与OpenCL设备解耦合,即创建OpenCL命令队列是不用指定OpenCL设备,从上下文层面解决了OpenCL内核调度需要在编码阶段完成的问题。OpenCL上下文属性包含两个参数,分别对应了两种全局调度策略:循环调度(ROUND_ROBIN)和自适应调度(AUTO_FIT)。循环调度是在触发调度程序时,将命令队列调度到下一个可用设备上,在实际运行过程中,由于GPU设备支持多内核同时执行,该方案调度时选择计算资源充足的设备进行调度,这种方法会有最小的调度开销,但是并不总是选择最佳的队列-设备映射。自动调度策略是MultiCL框架提出的基于内核预执行的动态调度策略,MultiCL框架将根据动态调度策略选择最佳的队列-设备映射。
同时为了实现本地调度策略,对OpenCL API命令调度队列属性进行了扩展,添加了SCHEDAUTO或SCHEDOFF,分别确定特定的队列是选择自动调度模式还是手动调度模式。MultiCL框架给用户提供了选项,用户可以选用SCHED_OFF标志手动指定调度方案,用户也可以在创建命令队列时添加SCHED_AUTO标志来实现自动调度,其中包括静态调度(SCHED_AUTO_STATIC)和动态调度(SCHED_AUTO_DYNAMIC)。针对命令队列属性的修改旨在作为调度的微调参数,针对不同程度的OpenCL开发人员,制定了不同程度的调度策略。对于具有丰富经验的开发人员,可以直接忽略MultiCL框架提供的命令队列参数,选择手动调度所有队列,便于开发人员根据异构系统底层特点实现任务划分和内核优化,对于中等级别的开发人员,对底层架构有一定了解,可根据OpenCL内核的负载类型(例如:SCHED_IO_BOUND, SCHED_COMPUTE_BOUND等)选择命令队列属性作为系统的调度提示,便于MultiCL框架根据OpenCL内核类型提示构建微型内核和进行调度,对于初级开发人员,则可以采用MultiCL框架提供的自适应动态调度,由MultiCL运行时决定内核调度方案,该方式会带来一定的运行时开销。
MultiCL扩展的clSetCommandQueueSchedProperty命令用于标记调度程序区域,并可以在需要时设置更多调度程序标志,例如使用以下属性:SCHED_COMPUTE_BOUND,SCHED_MEM_BOUND,SCHED_IO_BOUND或SCHED_ITERATIVE指定队列中的预期计算类型,与clCreateCommandQueue的扩展参数相对应,该函数便于调度方案优化。OpenCL内核启动命令的参数包括命令队列,内核对象和内核的启动配置。MultiCL为了自动调度的方便,实现了新的OpenCL API命令clSetKernelWorkGroupInfo,用于设定内核配置参数,MultiCL框架在OpenCL内核调度命令加入命令队列前就可以获取内核的工作组和工作组中工作项信息,便于MultiCL框架进行内核调度。
MultiCL运行时设计如图1所示。
使用SCHED_OFF标志创建的用户命令队列将静态映射到所选设备(由开发人员在编码阶段指定映射方案),而使用SCHED_AUTO标志创建的命令队列将由MultiCL自动调度。MultiCL框架将OpenCL内核启动命令加入队列后,如果该命令队列是SCHED_OFF标志创建的命令队列,则采用静态调度方案,MultiCL运行时保留了SunCL运行时静态调度方案的部分,给开发人员保留了静态硬编码调度的功能。如果该命令队列是以SCHED_AUTO标志创建的,则交由自适应调度器映射到设备池中某一设备。上述调度过程包含了设备静态分析(在clGetPlatformIds读取设备信息阶段进行),内核静态分析(clBuildProgram,clCreateProgramWithSource构建程序阶段进行),内核动态分析(clEnqueue*命令阶段)和设备映射。MultiCL动态调度模块通过独立线程与OpenCL程序执行并发执行,利用OpenCL初始化阶段开销隐藏MultiCL运行时内核分析和设备分析带来的开销。
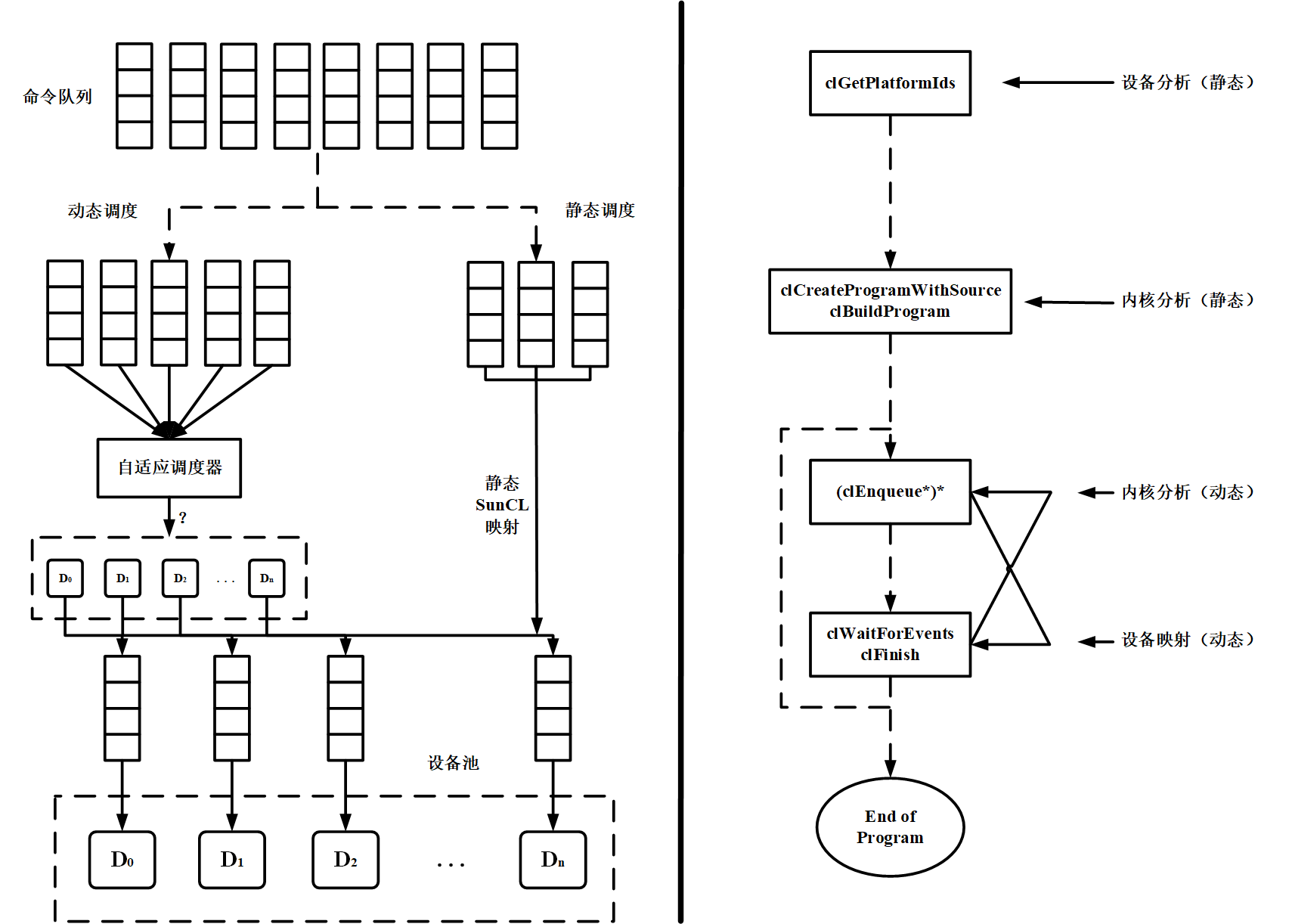
图1 MultiCL运行时结构图
MultiCL动态调度包含三个主要的运行时模块:设备分析器、内核分析器和任务调度器。
- 设备分析器,用于收集和分析设备的性能(内存,计算能力和I/O);
- 内核分析器,分析和预测内核在不同设备上的执行时间;
- 任务调度器,将SCHED_AUTO标记的命令队列中的任务调度到设备上。上述三个运行时模块在MultiCL对OpenCL标准扩展的基础上实现了OpenCL任务的动态调度。设备分析器和内核分析器分别对OpenCL设备和内核进行分析,判断OpenCL设备与内核的契合程度,为任务调度器提供数据基础。
设备分析器是在OpenCL clGetPlatformIds命令调用期间执行的设备概要分析器。设备分析器从设备概要文件中检索OpenCL设备的概要信息。如果文件中不存在该设备的概要信息,则MultiCL运行时将运行数据带宽和指令吞吐量基准测试,并将测得的指标作为静态信息存入设备概要文件中。基准测试源于SHOC基准测试NVIDIA SDK,这些基准测试是MultiCL运行时的一部分。仅当系统配置发生更改时(例如,在系统中添加新设备或从中删除设备)时,才需要再次运行基准测试。
内核分析器通过性能建模或性能预测技术来估计内核执行时间。MultiCL为了减少内核分析器所带来的时间开销,采用每个设备运行一次微型内核服务器托管网,并将相应的执行时间存储为内核配置文件的一部分。该微型内核由微型仿真技术创建,并将其调度到系统中的每一个参与计算的设备上运行,该内核划分单个工作组工作项,并记录该微型内核在每个设备上的相对性能。这种方式会给当前程序带来潜在的运行时开销,但是MultiCL采用的微型内核在运行时优化后,实验验证其运行时开销很小,有时可以忽略不计。同时该方式也能较为准确的反映内核在不同设备上的运行差异。微型内核创建发生在OpenCL clCreateProgramWithSource和clBuildProgram命令期间。MultiCL运行时拦截clCreateProgramWithSource调用,并为每个内核创建一个迷你内核对象,通过拦截clBuildProgram调用,将带有新微型内核的程序构建为单独的二进制文件。尽管此方法使OpenCL的构建时间增加了一倍,但作者认为这是初始设置成本,不会改变程序的实际运行时间。
任务调度器将获取每一个OpenCL命令队列,并将关联的命令队列添加到就绪队列池中进行调度。MultiCL仅通过概要设备信息文件和内核配置文件得到任务映射方案。MultiCL运行时读取每个队列的聚合内核配置文件,任务调度器采用使命令队列内核执行时间最短的策略来确定理想的队列-设备映射,最大限度地减少并发执行时间。动态调度方法保证了理想的内核-设备映射,同时OpenCL平台下的设备数量不多,因此调度产生的开销可以忽略不计。调度程序将命令队列映射到设备后,该队列将从队列池中删除。
3 总结
OpenCL首次提出了面向异构系统通用目的并行编程的开放式标准,适用于跨CPU、GPU和其他处理器的异构混合编程。而MultiCL通过对OpenCL标准的扩展,以在上下文全级别和命令队列本地级别进行静态和动态调度。MultiCL是一个运行时系统,通过设备分析器,内核分析器和任务调度器完成了OpenCL的动态调度,同时保留了OpenCL本身由开发人员指定的静态调度方法,MultiCL运行时优化使开发人员能够专注于应用程序级别的数据和任务分解,而不是设备级别的体系结构详细信息和设备调度,极大减轻了OpenCL开发难度,为以后的任务调度研究提供了良好的软件支持。但是,MultiCL也引入了预执行开销,降低了程序执行效率,同时其预执行评估方案难以反映内核实际运行状态,尚待进一步优化。
作者:京东物流靳紫薇
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
