
如果需要处理的原图及代码,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice
本来不想碎碎念,但是我已经在图像后缀上栽倒两次了。而且因为无意犯错,根本找不到问题。不论是在深度学习的语义分割中,还是在图像处理的软件(Halcon, Cognex)中都载过跟头,于是痛定思痛,决定将自己的经验写进这篇博客中,如果看到这篇的看官,希望不要再犯了。
问题1:乱修改图像后缀名称,部分软件会报错(halcon error #5580:PNG:file is not a PNG file)
首先是下面的报错,因为openCV使用多了,我们经常会通过cv2.imread()加载出三通道的图像,所以默认图像都是BGR的,无论图像是png, bmp 还是 jpg。反正都可以读出三通道的,即使有时候无意将图像后缀命名为png或者jpg(或者我们网上下载的数据集中被修改了后缀),我们都不在意。但是实际上部分软件不会像opencv自动处理,我在这里就报错了。
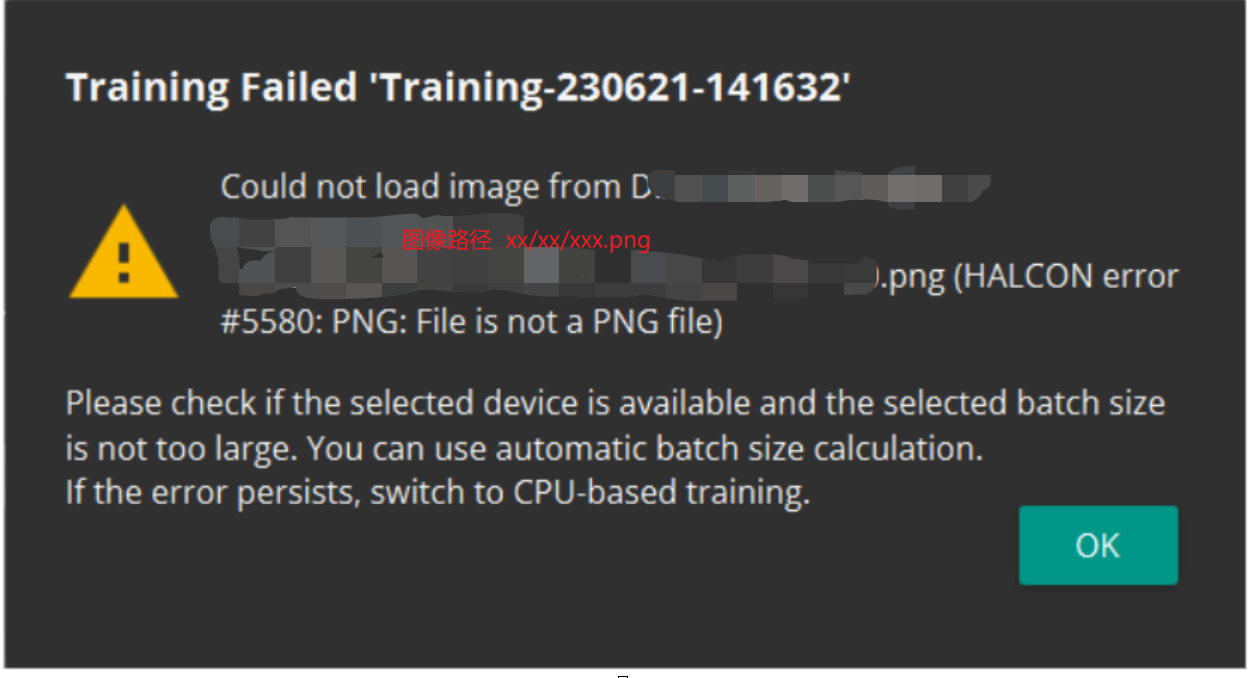
具体深入下去,就是下图,实际上图像后缀是jpg,但是我拿到的数据是png,而我直接喂入软件就报错如上:

实际上这两个图像都是png图像,但是可能就会出现有些人误命名,将其图像后缀命名为jpg。这就导致了上面的问题。
我们具体分析,当我们将图像后缀从.png修改为.jpg时,实际上并没有改变图像的编码方式和文件结构。而如我上面所说,OpenCV是一个功能强大的计算机视觉库,它可以根据文件的实际内容来识别图像格式,而不仅仅依赖于文件后缀。因此,OpenCV能够读取被错误命名的图像文件。
然而,其他一些软件可能只依赖于文件后缀来确定图像格式,而不会尝试解析文件内容。当你将图像后缀从.png修改为.jpg时,这些软件可能会尝试按照JPEG格式去解析该文件,但是由于文件实际上是一个PNG格式的图像,所以会报错并指出文件不是一个有效的PNG文件。
所以要正确地处理图像文件,建议使用正确的文件后缀来反映实际的图像格式。这样可以确保不同的软件能够正确地解析和处理图像文件。
问题2:图像随便保存为jpg,结果mask结果对不上
当我写这篇博客的时候,我发现也有网友有同样的问题,哈哈哈,于是我就更坚决了自己要写这个的原因。
首先复现一下下面问题,并解释一下。
我们就将输出的图像保存为图像(即jpg和png),然后读取出来,看看结果:
import sys
import os
import numpy as np
def count_pixel_values(image):
count_res = {}
# 统计像素值数量
pixel_counts = np.bincount(image.flatten())
# 显示结果
for pixel_value, count in enumerate(pixel_counts):
if count > 0:
count_res[pixel_value] = count
return count_res
# 读取一张图像,将其转换为灰度图
image = cv2.imread(r"./Abyssinian_1.png", 0)
# 创建二值图像
binary_image = np.zeros_like(image, dtype=np.uint8)
binary_image[image == 1] = 0 # 像素值1对应0像素
binary_image[image == 2] = 125 # 像素值2对应125像素
binary_image[image == 3] = 255 # 像素值3对应255像素
# 1, 我将二值图结果保存为jpg 和png,我们分别看看
# cv2.imwrite(r"./cat.png", binary_image)
# cv2.imwrite(r"./cat.jpg", binary_image)
# 2, 我分别打开png 和 jpg 的图像
png_mask = cv2.imread(r"./cat.png", 0)
jpg_mask = cv2.imread(r"./cat.jpg", 0)
print(np.array_equal(png_mask, binary_image), np.sum(png_mask != binary_image))
pixel_counts_png = count_pixel_values(png_mask)
print(pixel_counts_png)
print(np.array_equal(jpg_mask, binary_image), np.sum(jpg_mask != binary_image))
pixel_counts_jpg = count_pixel_values(jpg_mask)
print(pixel_counts_jpg)
# 使用sys.getsizeof()函数来获取图像对象的大小
# 使用os.path.getsize()函数来获取图像文件的大小
binary_image_memory_size = sys.getsizeof(binary_image)
png_mask_memory_size = sys.getsizeof(png_mask)
jpg_mask_memory_size = sys.getsizeof(jpg_mask)
print("二值图图像内存大小: {} 字节".format(binary_image_memory_size))
print("jpg二值图图像内存大小: {} 字节".format(png_mask_memory_size))
print("png二值图图像内存大小: {} 字节".format(jpg_mask_memory_size))
binary_image_file_size = os.path.getsize(r"./Abyssinian_1.png")
png_mask_file_size = os.path.getsize(r"./cat.png")
jpg_mask_file_size = os.path.getsize(r"./cat.jpg")
print("二值图图像文件大小: {} 字节".format(binary_image_file_size))
print("jpg二值图图像文件大小: {} 字节".format(png_mask_file_size))
print("png二值图图像文件大小: {} 字节".format(jpg_mask_file_size))
"""
True 0
{0: 22938, 125: 198766, 255: 18296}
False 8258
{0: 21455, 1: 701, 2: 414, 3: 234, 4: 95, 5: 27, 6: 7, 7: 4, 8: 1, 119: 2, 120: 27, 121: 147, 122: 259, 123: 517, 124: 839, 125: 195208, 126: 879, 127: 449, 128: 258, 129: 123, 130: 38, 131: 17, 132: 3, 248: 7, 249: 12, 250: 71, 251: 170, 252: 421, 253: 911, 254: 1625, 255: 15079}
"""
分析: 实际上我的binary_image图像只有1,2,3三个像素,即使我转换为0, 125, 255后,仍然只有三个像素 但是当我保存结果为PNG的时候,结果无误,仍然是三个像素 而我保存结果是JPG的时候,结果存在误差,为多个像素
结论: 当将二值化的图像保存为jpg的时候,会出现图像损坏,所以保存图像的时候,使用jpg需要谨慎 。
当我查看图像本身的大小的时候 :
二值图图像内存大小: 240120 字节 jpg二值图图像内存大小: 240120 字节 png二值图图像内存大小: 240120 字节 二值图图像文件大小: 2994 字节 jpg二值图图像文件大小: 3814 字节 png二值图图像文件大小: 18127 字节
在OpenCV中,图像保存为不同后缀(如PNG、JPEG、BMP)的文件时,它们的文件格式和存储方式是不同的,尽管它们可能在视觉上看起来相同。 这是因为不同的图像格式使用不同的压缩算法和编码方式来存储图像数据。这些格式有各自的优势和特点,适用于不同的应用和需求。
还有下面的:

比如我们查看一张特殊的png格式的mask图像,如下(特殊是因为是彩色的灰度图):
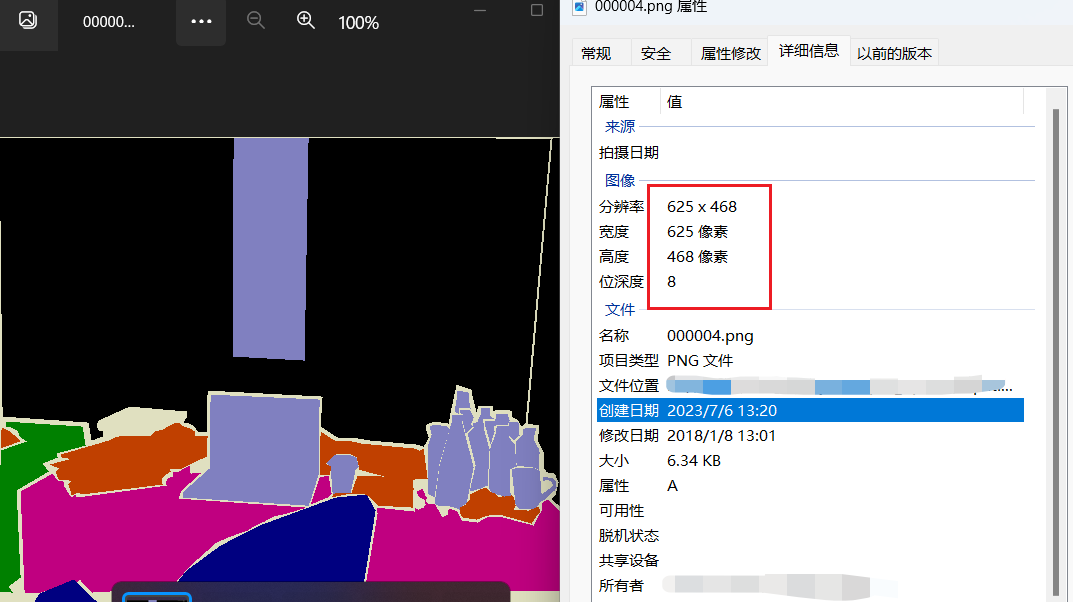
和一张正常的mask图像,如下:
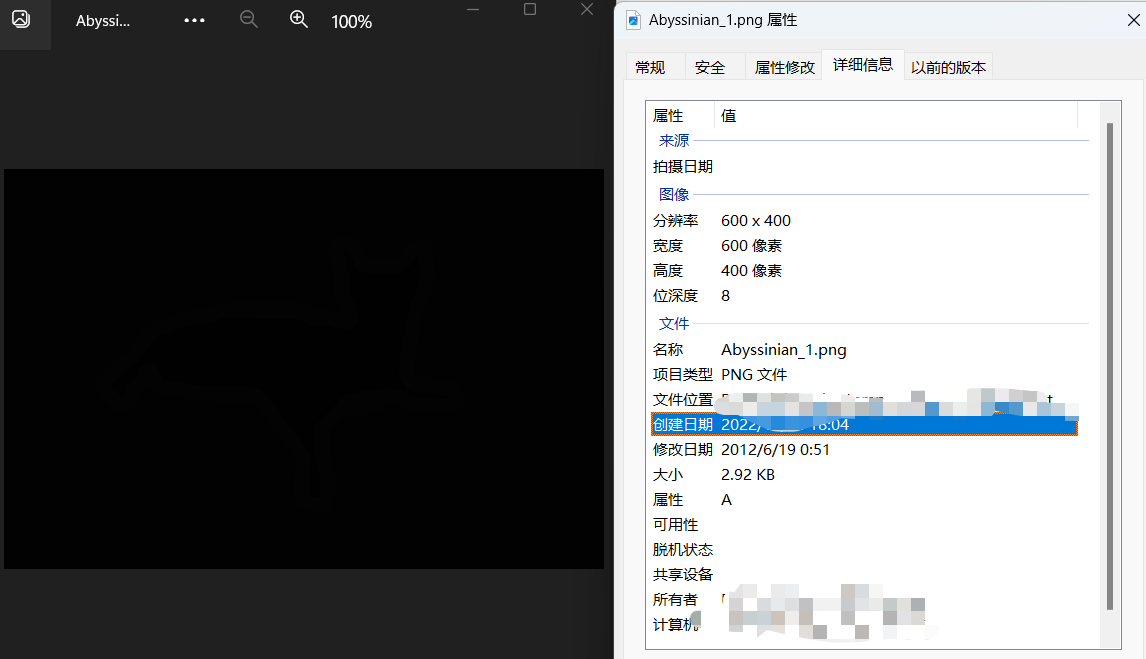
我们对比一下,实验如下:
import cv2
from PIL import Image
import numpy as np
"""
测试任务:
1,使用opencv直接读取png图像
2,使用opencv读取png图像,以原始的通道顺序读取PNG图像,而不进行任何颜色通道的转换
3,使用PIL库读取png图像
4,判断opencv读取的图像是否修改像素值
测试方案及结论:
1,使用语义分割的mask图像,像素只有1,2,3进行测试。
测试结果如下:
cv_img shape: (400, 600)
cv_origin_img shape: (400, 600)
pil_img_np shape: (400, 600)
0
0
pixel_counts_png_cv1: {1: 22938, 2: 198766, 3: 18296}
pixel_counts_png_cv2: {1: 22938, 2: 198766, 3: 18296}
pixel_counts_png_pil: {1: 22938, 2: 198766, 3: 18296}
测试结论:
对于像素只有1,2,3的图像,无论用什么读取结果都一样。
2, 测试我截图的那个哥们,我使用的是PNG图片,而且是8bit的深度,但是有些图像会不变,有些会变。
使用语义分割的mask图像,是彩色图像。
测试结果如下:
cv_img shape: (468, 625)
cv_origin_img shape: (468, 625, 3)
pil_img_np shape: (468, 625)
128589
1
pixel_counts_png_cv1: {0: 163911, 15: 16626, 72: 36210, 75: 5261, 95: 12644, 135: 37681, 220: 20167}
pixel_counts_png_cv2: {0: 584361, 64: 12644, 128: 133459, 192: 106702, 224: 40334}
pixel_counts_png_pil: {0: 163911, 2: 5261, 4: 16626, 13: 36210, 25: 12644, 39: 37681, 255: 20167}
385767
测试结论:
对于像素存在多个不同的pixel的话,可以看出opencv读取数据,会修改像素值。
"""
def count_pixel_values(image):
count_res = {}
# 统计像素值数量
pixel_counts = np.bincount(image.flatten())
# 显示结果
for pixel_value, count in enumerate(pixel_counts):
if count > 0:
count_res[pixel_value] = count
return count_res
# img_path = r"./Abyssinian_1.png"
img_path = r"./000004.png"
# opencv 直接读取图像(会默认转换为BGR)
cv_img = cv2.imread(img_path)
# 因为我们知道要对比的是单通道的图像,所以先转换为灰度图
cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGR2GRAY)
# opencv读取原始通道
cv_origin_img = cv2.imread(img_path, cv2.IMREAD_UNCHANGED)
# PIL 库读取image
pil_img = Image.open(img_path)
pil_img_np = np.array(pil_img)
print("cv_img shape: ", cv_img.shape)
print("cv_origin_img shape: ", cv_origin_img.shape)
print("pil_img_np shape: ", pil_img_np.shape)
print(np.sum(cv_img != pil_img_np))
print(np.sum(cv_origin_img != pil_img_np))
pixel_counts_png_cv1 = count_pixel_values(cv_img)
pixel_counts_png_cv2 = count_pixel_values(cv_origin_img)
pixel_counts_png_pil = count_pixel_values(pil_img_np)
print("pixel_counts_png_cv1: ", pixel_counts_png_cv1)
print("pixel_counts_png_cv2: ", pixel_counts_png_cv2)
print("pixel_counts_png_pil: ", pixel_counts_png_pil)
merge_cv = cv2.merge([cv_img, cv_img, cv_img])
merge_pil = cv2.merge([pil_img_np, pil_img_np, pil_img_np])
print(np.sum(merge_cv != merge_pil))
总结:对两个问题的分析和总结
上面的实验和错误点,都说明了一个问题。对于保存图像格式为png还是jpg,我们根本不清楚,也不是很理解这二者到底有啥区别,到底哪个保存像素高,哪个低。哪个占的内存大,哪个小。哪个改变像素,哪个保存原始像素,实际上都一脸懵逼。
于是我觉得要解决上面问题,首先必须了解其构成原理。下面详细学习一下。
1,图像后缀jpg, bmp, png的定义
1.1 JPG的定义
JPEG(Joint Photographic Experts Group)是一种常见的有损压缩位图图像格式,广泛用于存储和传输照片和其他真实场景图像。它的目标是通过压缩算法在图像质量和文件大小之间找到平衡。它通过牺牲一些细节来减小图像文件的大小。JPEG格式通常用于保存照片、彩色图像等,以便在网络上共享或用于显示,因为它可以在相对较小的文件大小下提供较好的视觉质量。
以下是JPEG图像格式的一些简介:
-
有损压缩:JPEG使用有损压缩算法,通过牺牲一些图像细节来减小文件大小。压缩程度可以通过调整压缩质量参数来控制,不同的压缩质量会导致不同程度的图像质量损失。
-
适用于连续色调图像:JPEG主要用于存储连续色调的图像,特别是照片和真实场景图像。它对颜色和亮度的变化有较好的表示能力,适用于自然图像的压缩和显示。
-
24位位深:JPEG支持真彩色图像,即每个像素使用24位(RGB三通道)来表示颜色。这使得JPEG可以表示约1677万种颜色。
-
可调压缩质量:JPEG允许用户根据需要选择不同的压缩质量。较高的压缩质量会产生较大的文件大小,同时保留更多的图像细节。较低的压缩质量会产生更小的文件大小,但会引入更明显的图像质量损失。
-
不支持透明度:JPEG不支持像PNG那样的透明度,它只能表示不透明像素。这使得它不适合用于需要透明背景的图像,如图标和叠加图像。
-
平台无关性:JPEG图像格式是平台无关的,可以在不同的操作系统和软件中进行读取和显示。
JPEG图像格式在图像压缩和存储领域具有广泛应用,特别是用于照片和真实场景图像。然而,由于有损压缩的特性,JPEG格式不适合用于需要精确无损表示和透明度的应用,如图形设计、图像处理和需要保留细节的专业应用。
1.2 PNG的定义
PNG(Portable Network Graphics)是一种无损的位图图像格式,广泛用于存储和传输图像。它的目标是提供一种比传统的GIF格式更好的替代方案,同时避免了GIF格式的一些限制和专利问题。它可以保留图像的原始质量和细节。PNG格式通常用于保存需要保持高质量且不损失细节的图像,例如图标、透明背景的图像等。
以下是PNG图像格式的一些简介:
-
无损压缩:PNG使用无损压缩算法,不会引入图像质量损失。相比于有损压缩格式如JPEG,PNG适用于那些需要保留细节和图像质量的应用,例如图像编辑、图形设计和Web图像。
-
Alpha通道支持:PNG支持透明度和半透明效果,通过Alpha通道可以定义像素的不透明度。这使得PNG成为合适的选择用于图像叠加和合成。
-
256级灰度和真彩色支持:PNG支持灰度图像(8位位深)和真彩色图像(24位位深)。真彩色PNG图像可以显示约1677万种颜色,提供更丰富和精确的颜色表示。
-
支持无损透明度:PNG的透明度支持不仅限于简单的完全透明和完全不透明,还可以定义不同的透明度级别,实现更复杂的透明效果。
-
平台无关性:PNG图像格式是平台无关的,可以在不同的操作系统和软件中进行读取和显示。
-
版权和专利:PNG是一种开放标准格式,没有涉及专利或版权限制。这使得PNG成为一种广泛采用的图像格式。
总体而言,PNG图像格式在保持图像质量、支持透明度和颜色表示方面具有优势,并被广泛应用于图像处理、Web图像、图形设计和其他需要保留图像细节和质量的应用中。
1.3 GIF的定义
GIF(Graphics Interchange Format)是一种常见的无损压缩位图图像格式,广泛用于存储和传输简单的动画和图形。GIF图像格式最初由CompuServe开发,后来成为互联网上最流行的图像格式之一。
以下是GIF图像格式的一些简介:
-
无损压缩:GIF使用无损压缩算法,不会引入图像质量损失。这使得它适用于存储和传输需要保留细节和图像质量的应用。
-
索引调色板:GIF使用调色板技术,其中图像中的每个像素值通过调色板中的索引来表示。调色板最多可以包含256种不同的颜色。
-
动画支持:GIF支持多帧动画,可以在一张图像文件中存储多个图像帧,通过控制帧间延迟时间来创建简单的动画效果。
-
透明度支持:GIF支持透明像素,其中一个颜色被定义为透明。这使得GIF图像可以显示透明背景,并与其他图像叠加。
-
简单图形和动画:GIF主要用于存储简单的图形、图标和动画。它对于图像的颜色数目和细节有一定的限制,通常不适用于照片和真实场景图像。
-
支持LZW压缩算法:GIF使用LZW(Lempel-Ziv-Welch)压缩算法来减小文件大小。该算法通过创建和使用字典来编码图像数据,以进一步压缩数据。
GIF图像格式在Web图像、图标、简单动画和图形设计中得到广泛应用。由于它的无损压缩和透明度支持,GIF图像通常用于需要保留图像质量和简单动画的情况。然而,由于调色板限制和对颜色和细节的限制,GIF不适用于需要更高质量和更丰富颜色表示的照片和真实场景图像。
1.4 BMP的定义
BMP(Bitmap)是一种常见的无压缩位图图像格式,它是Windows操作系统中最常见的图像格式之一。BMP图像格式以像素为单位存储图像数据,提供了对象的精确控制和编辑,以下是BMP图像格式的一些简介:
- 无压缩:BMP使用无压缩的位图数据存储图像,不会引入图像质量损失。它以原始像素数据的形式存储每个像素的颜色值,因此文件大小相对较大。
- 位深度:BMP支持不同的位深度,包括1位(黑白图像)、8位(256级灰度或调色板索引颜色)和24位(真彩色,约1677万种颜色)。高位深的BMP图像可以提供更精确的颜色表示和图像细节。
- 像素数据布局:BMP图像按行存储像素数据,每行的像素从左到右依次排列。每个像素可以使用RGB颜色模式(对于24位位深)或调色板索引(对于8位位深)来表示。
- 支持透明色:BMP图像可以指定一个颜色作为透明色,使得该颜色在图像显示时变为透明,适用于一些特殊效果的实现。
- 平台无关性:BMP图像格式是平台无关的,可以在不同的操作系统和软件中进行读取和显示。
- 大文件大小:由于无压缩的特性,BMP图像文件大小相对较大,对存储和传输的需求较高。这使得BMP不太适用于Web图像和需要节省存储空间的应用。
BMP图像格式适用于那些需要对图像进行精确编辑、保留图像细节和颜色准确性的应用。然而,由于文件大小较大和缺乏压缩,BMP图像在Web图像和存储空间受限的场景中使用较少。
1.5 常见的JPEG和PNG的区别
虽然我上面已经摘抄出了其定义,但是我估计大多数人不仔细看,所以我直接将常见的JPEG和PNG的区别整理如下。
JPEG和PNG是常见的图像格式,它们在图像压缩、质量损失、透明度支持等方面存在一些区别。下面是一些主要的区别:
-
压缩算法:
- JPEG使用有损压缩算法,它通过减少图像中的细节和颜色信息来减小文件大小。这导致在高压缩比下会损失一些细节,并产生一些压缩伪影。
- PNG使用无损压缩算法,它能够保持图像的原始质量和细节。它适用于保存需要保持高质量且不损失细节的图像,但文件大小通常比JPEG大。
-
颜色支持:
- JPEG主要适用于彩色图像,它能够显示数百万种颜色。
- PNG支持全彩色图像,并能够显示透明度。它还支持索引调色板,可以减小文件大小。
-
透明度支持:
- JPEG不支持透明度。任何图像中的透明部分将以黑色或白色进行填充。
- PNG支持透明度,并能够将图像中的某些部分设置为完全透明,以便与背景融合。
-
文件大小:
- JPEG在相同视觉质量下,文件大小通常比PNG要小。这使得它适用于在带宽受限的环境下传输图像,如网络传输。
- PNG文件大小通常比JPEG大,因为它使用无损压缩算法。这使得它适用于需要保持高质量的图像存储,如图标、透明背景等。
1.6 什么是图像位深
当我们看到一张数字图像时,我们常常会关注图像的颜色、细节和质量。这些特征与图像的位深(Bit Depth)密切相关。图像位深是指数字图像中每个像素所使用的二进制位数,用于表示颜色或亮度的信息量或精度。本文将介绍图像位深的定义、常见的位深类型以及它们之间的区别。
位深定义: 位深表示每个像素值所使用的二进制位数。较高的位深可以提供更多的颜色或灰度级别,从而实现更准确的颜色表示和更细致的图像细节。例如,一个8位位深的图像可以表示256个不同的亮度或颜色级别(0-255),而一个16位位深的图像可以表示65,536个级别。
常见的位深类型:
- 1位(2色):1位位深的图像只能表示两个颜色或灰度级别,通常为黑色和白色。
- 8位(256色):8位位深的图像可表示256个不同的颜色或灰度级别。这种位深常用于网页图像、简单的图形和图像处理应用。
- 24位(真彩色):24位位深的图像通常称为真彩色图像,因为它能够表示约1677万种颜色。这是最常见的图像位深,适用于照片、图像处理和显示应用。
- 32位(增强色彩):32位位深的图像在真彩色基础上加入了额外的通道,通常为透明度通道(Alpha通道)。这种位深常用于图像合成和透明效果。
位深之间的区别: 不同的位深具有不同的颜色精度和可表示范围。较高的位深可以提供更丰富的颜色或灰度级别,更好地保留图像的细节和质量。然而,较高的位深也需要更多的存储空间来保存图像数据,并对图像处理和显示的计算资源有更高的要求。
总结: 图像位深是指数字图像中每个像素所使用的二进制位数,用于表示颜色或亮度的信息量或精度。不同的位深可以提供不同的颜色精度和细节级别,常见的位深包括1位、8位、24位和32位。通过选择适当的位深,我们可以平衡图像质量和存储需求,以满足特定应用的需求。
2 如何查看真实的图像后缀
如果真的被修改了后缀,那么我们如何查看文件后缀呢,下面方法可以让其原形毕露。
2.1 常见的图像格式及其十六进制
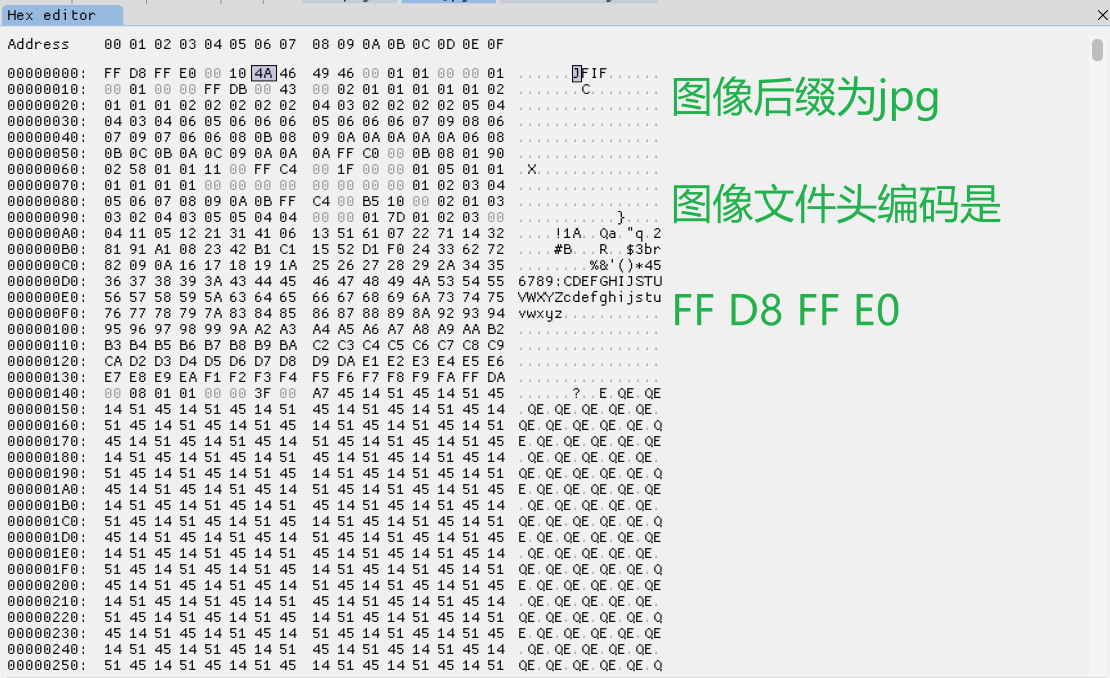
下面是一些常见图像格式及其文件头的十六进制表示:
-
JPEG/JPG:
- 文件头:FF D8 FF
- 文件尾(结束标记):FF D9
-
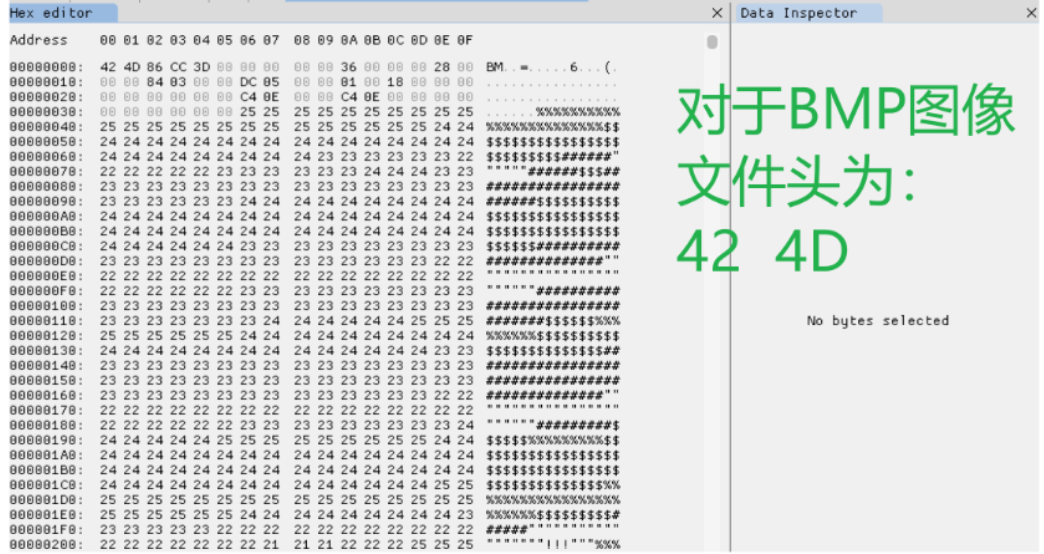
BMP:
- Windows BMP(非压缩)文件头:42 4D
- Windows BMP(压缩)文件头:42 4D
- OS/2 BMP文件头:42 4D
-
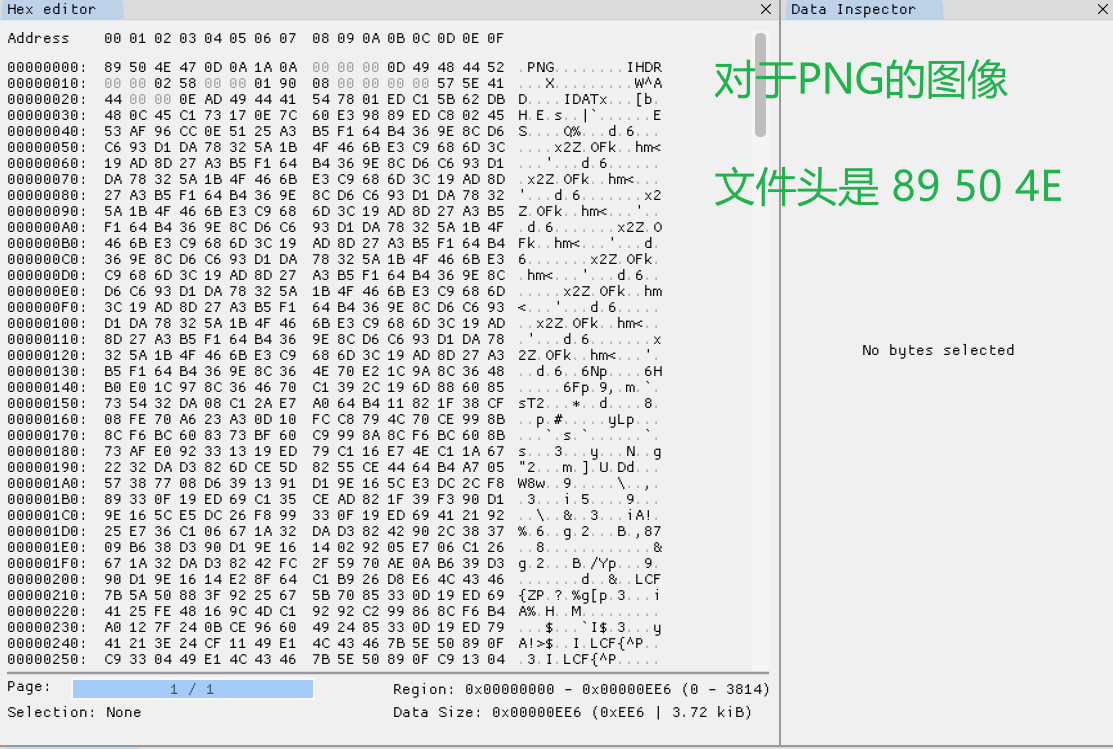
PNG:
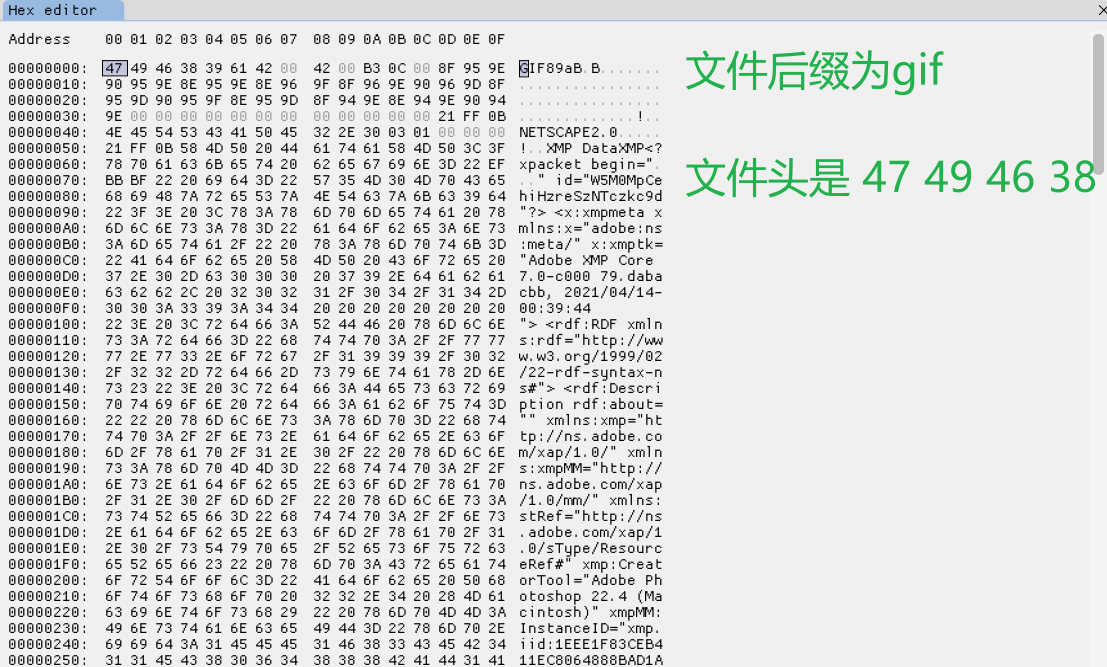
- 文件头:89 50 4E 47 0D 0A 1A 0A
- 文件尾(IEND标记):49 45 4E 44 AE 42 60 82
-
GIF:
- 文件头:47 49 46 38 39 61 或 47 49 46 38 37 61
- 文件尾(结束标记):00 3B
-
TIFF:
- Little-Endian(Intel)格式文件头:49 49 2A 00
- Big-Endian(Motorola)格式文件头:4D 4D 00 2A
-
ICO:
- 文件头:00 00 01 00
-
PSD (Photoshop):
- 文件头:38 42 50 53
-
WebP:
- 文件头:52 49 46 46 ?? ?? ?? ?? 57 45 42 50
-
SVG (可缩放矢量图形):
- 文件头:3C 73 76 67
这些是一些常见的图像格式及其文件头的十六进制表示。请注意,文件头的确切值可能因特定软件、文件版本或其他因素而有所变化。因此,在实际应用中,最好使用专门的图像处理库或工具来解析和处理不同图像格式的文件。
2.2 使用专门的工具解析图像
下面看看我们上面整理的文件头是否正确,下面查看四种常见的不同后缀的文件的文件头:
3,为什么opencv读取数据的格式都是BGR呢?
为了了解清楚,我还特意查了为什么opencv读取数据的格式是BGR而不是RGB呢?
OpenCV读取图像时将其表示为BGR(蓝绿红)通道顺序的像素排列。这是因为在许多计算机视觉应用中,BGR通道顺序是最常用的,尤其是在早期的彩色图像处理中。历史上,BGR通道顺序的选择与许多计算机视觉库和工具的设计有关,包括OpenCV。这些库和工具在早期的硬件和软件平台上的开发中,采用了BGR通道顺序的表示方式。
OpenCV读取图像为BGR的历史原因可以追溯到早期计算机视觉应用的发展和硬件限制。在计算机视觉领域的早期,主要应用是在基于CRT(阴极射线管)显示器的计算机系统上进行图像处理。在这些系统中,图像数据通常是以RGB(红绿蓝)通道顺序存储的,因为CRT显示器的光栅扫描方式是从左上角开始,按照RGB的顺序逐行扫描。
然而,在早期的计算机体系结构和操作系统中,处理图像数据的方式可能与显示器的存储方式不同。由于BGR通道顺序在一些早期图像处理库和工具中被采用,OpenCV也选择了这种通道顺序。
此外,早期的计算机系统在内存中存储图像数据时采用了连续的行优先(row-major)存储方式。而BGR通道顺序在这种存储方式下能够更好地利用内存的连续性,从而提高图像数据的读取效率。
尽管现代计算机和显示器普遍使用RGB通道顺序,但由于OpenCV的广泛应用和与现有代码的兼容性考虑,保持了BGR通道顺序作为默认的图像表示方式。
需要注意的是,虽然OpenCV默认将图像读取为BGR通道顺序,但可以使用适当的函数将图像转换为其他通道顺序,如前面提到的cv2.cvtColor()函数。这使得在OpenCV中进行RGB格式图像的处理仍然是可行的。
在现代计算机视觉领域,许多其他工具和库使用RGB(红绿蓝)通道顺序来表示图像。RGB通道顺序更符合人眼感知颜色的方式,因为光的三原色是红、绿和蓝。
4,python如何转换png到JPG,JPG到PNG
当然,OpenCV也是OK的,直接保存的时候设置图像后缀即可,但是因为我推荐使用PIL库。所以我的示例脚本都是使用PIL库实现的,代码如下:
from PIL import Image
"""
使用PIL库保存不同格式的图像(常见的转换,比如jpg转png, png转jpg)
这里验证的是:
1,将 jpg 转换为 png,并保存
2,将保存的png 读取出来再保存为 jpg
3,对于保存的jpg 和原始的jpg 看结果是否相等
结论:
False
原因:
JPEG格式对图像进行压缩时,会丢失一些细节和像素信息,因此还原回去的图像与原始的PNG图像可能存在一些差异。
将PNG图像保存为JPEG格式会引起一定程度的图像压缩损失,因为JPEG是一种有损压缩格式。因此,还原回去的图像和原始的img不会完全相等。
"""
# step1: 将 jpg 格式保存为png
img_jpg = Image.open("./test/cat.jpg")
# save()有两个参数,第一个是保存转换后文件的文件路径,第二个参数是要转换的文件格式。
img_jpg.save("./test/cat_jpg2png.png", "PNG")
#
img_png = Image.open("./test/cat_jpg2png.png")
img_png.save("./test/cat_jpg2png2jpg.jpg", "JPEG")
img_origin_jpg = Image.open("./test/cat.jpg")
img_convert_jpg = Image.open("./test/cat_jpg2png2jpg.jpg")
print(img_origin_jpg.getdata(), type(img_convert_jpg.getdata()))
#
pixels1 = list(img_origin_jpg.getdata())
pixels2 = list(img_convert_jpg.getdata())
print(pixels1 == pixels2)
# False
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: [ARM 汇编]高级部分—性能优化与调试—3.4.1 性能分析与优化策略
性能优化是嵌入式系统开发中的一个重要环节,尤其是在资源受限的环境下。性能优化的目标是提高代码执行速度、降低功耗和减少内存占用。在本章节中,我们将讨论性能分析与优化策略,并通过实例来学习如何应用这些策略。 性能分析方法 要优化程序性能,首先需要分析程序的瓶颈。通…
