
随着企业数据规模的不断增长,数据库用户的关键业务系统面临着存储和处理庞大数据量的挑战。这不仅意味着更昂贵的 IT、数据成本,还包括更多的资源消耗和管理复杂性。为了满足企业的需求,云原生虚拟数仓 PieCloudDB Database 通过一系列的创新技术手段帮助企业降低成本并提高效率。
云原生虚拟数仓 PieCloudDB 从产品设计到产品研发,都注重为用户降本增效。PieCloudDB 采用存算分离架构,在冷热数据分析、数据波峰波谷场景下能显著降本增效。PieCloudDB 服务器托管网云上云版的按需付费模式可以保证用户成本效益最大化。除此之外,PieCloudDB 在数据压缩上也做了许多优化,打造自适应压缩方案,显著减少存储空间的需求,从而降低硬件成本。 同时也可以减少数据备份和恢复过程的时间和成本。本文将主要介绍 PieCloudDB 是如何在保证性能的前提下,采用多种自适应压缩与编码技术,为企业降本增效。
PieCloudDB 压缩与编码
1 支持 ZSTD
ZSTD(Zstandard)是一种高性能的无损压缩算法,由 Facebook 于2016年开源,算法旨在提供快速的压缩和解压缩速度,并同时达到较高的压缩比。以下是 ZSTD 的一些特点:
- 高性能: ZSTD 提供了非常快速的压缩和解压缩速度,在许多情况下甚至比其他流行的压缩算法更快。它采用了多级搜索、动态字典、预测模型等优化技术,以实现卓越的性能。
- 可调节的压缩比: ZSTD 支持可调节的压缩级别,允许你根据需要进行速度和压缩比之间的权衡。较低的压缩级别可以提供更快的速度,而较高的压缩级别则会获得更高的压缩比。
- 兼容性: ZSTD 的压缩格式是自包含的,这意味着你可以在不同平台和系统上使用压缩的数据,而无需依赖特定的库或工具。
基于以上特点,而且 ZSTD 在压缩率上优于目前 PieCloudDB 的压缩算法,所以我们在 PieCloudDB 中支持了 ZSTD。
1.1 压缩方式选择
PieCloudDB 创建 table 时,可以通过 compresstype 字段选择压缩方式,如果未设置则默认为 ZSTD:
CREATE TABLE ctbl_none (s text) WITH (compresstype = 'none');服务器托管网
CREATE TABLE ctbl_pglz (s text) WITH (compresstype = 'pglz');
CREATE TABLE ctbl_zstd (s text) WITH (compresstype = 'zstd');
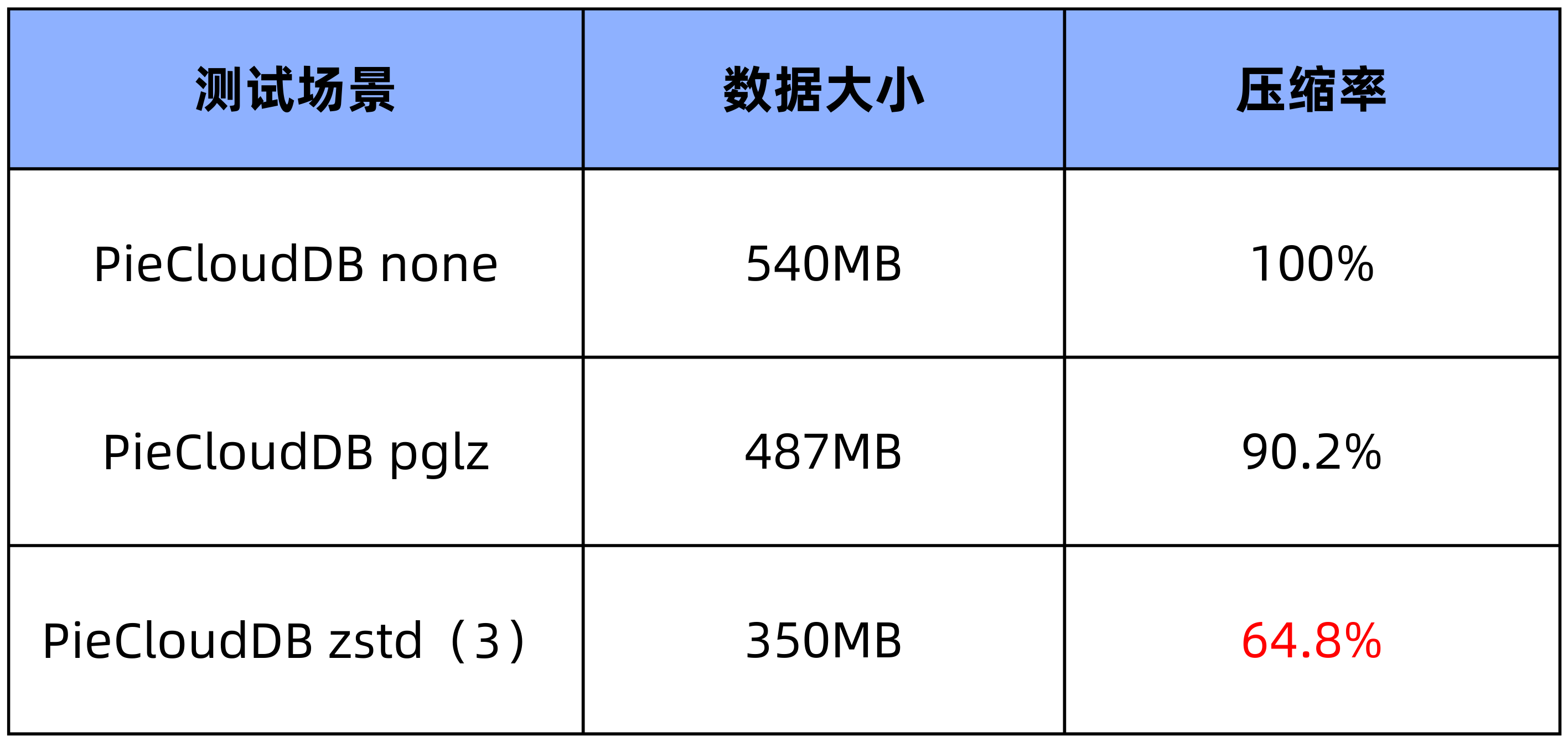
1.2 压缩效率对比
对于 500 列的宽表,导入脚本随机生成的 86400 条数据的 CSV 文件(536MB),在不同压缩方式的 table 中所占大小:
PieCloudDB 无压缩(集群大小为1):

PieCloudDB pglz (集群大小为1):
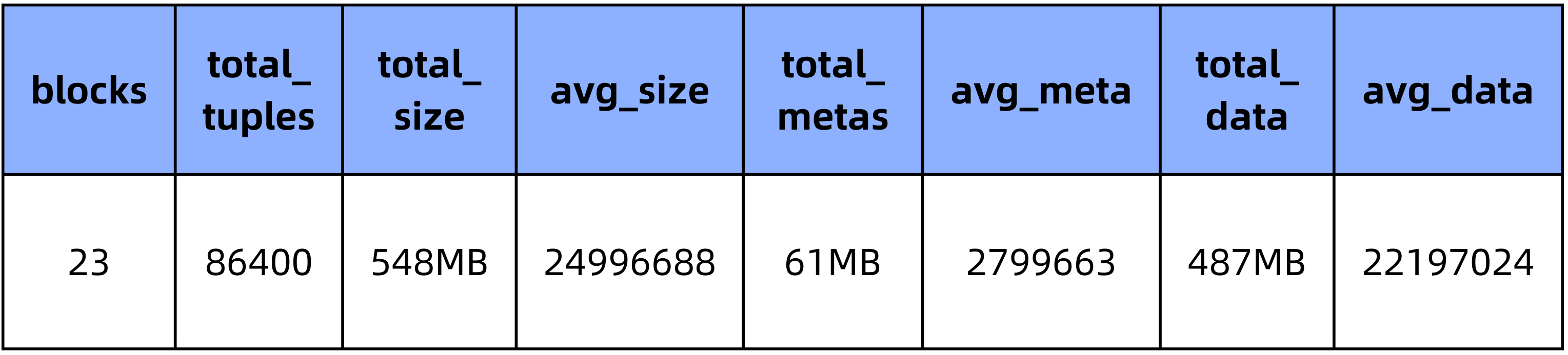
PieCloudDB zstd(3) (集群大小为1):
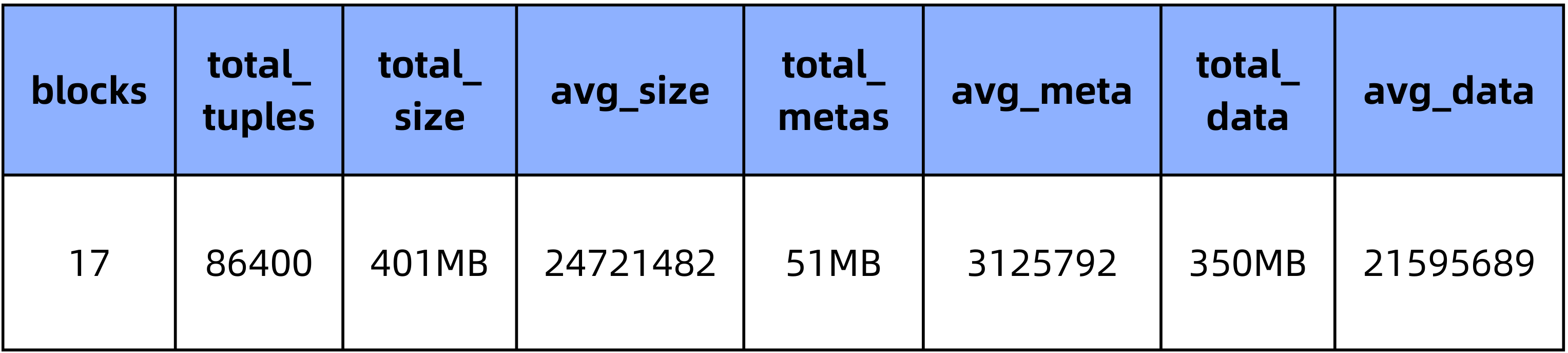
1.3 测试统计
2 HLL 支持 Sparse 表示
PieCloudDB 的存储系统简墨使用了一种行列混存的格式,每个文件块中都包含了表的部分行数据。为了统计表中每一列的唯一值数量,PieCloudDB 采用了 HLL(Hyperloglog)结构来进行基数估计。过去,HLL 只使用了一种称为”dense”的表示方式,其中一个 HLL 结构占用约 12KB 的空间(一个 HLL 16384个桶,每个桶 6bit),但对于宽表来说,每个文件块中的 HLL 结构就会变得非常庞大。举个例子,如果一个宽表有 1500 列,那么每个文件块的 HLL 部分将占用大约 18MB 的空间。
针对这个问题,考虑到宽表在一个文件块中不会有很多行数据,因此 HLL 中的很多桶都是空的,那么可以采用 RLE(run length encoding) 的方式来作为 HLL 的 Sparse 表示,RLE 的基本原理:
- 连续序列检测: RLE 首先扫描待压缩的数据序列,检测连续出现相同的数据项。
- 计数: 对于每个连续序列,RLE 计算该序列中数据项的数量,并将其转换成一个计数值。
- 编码: RLE 将原始数据序列替换为一组(数据项,计数值)的对,表示连续出现的数据项和其数量。
- 存储: 最后,压缩后的数据可以按照顺序存储为一系列数据对,以减小存储空间。
2.1 压缩效率对比
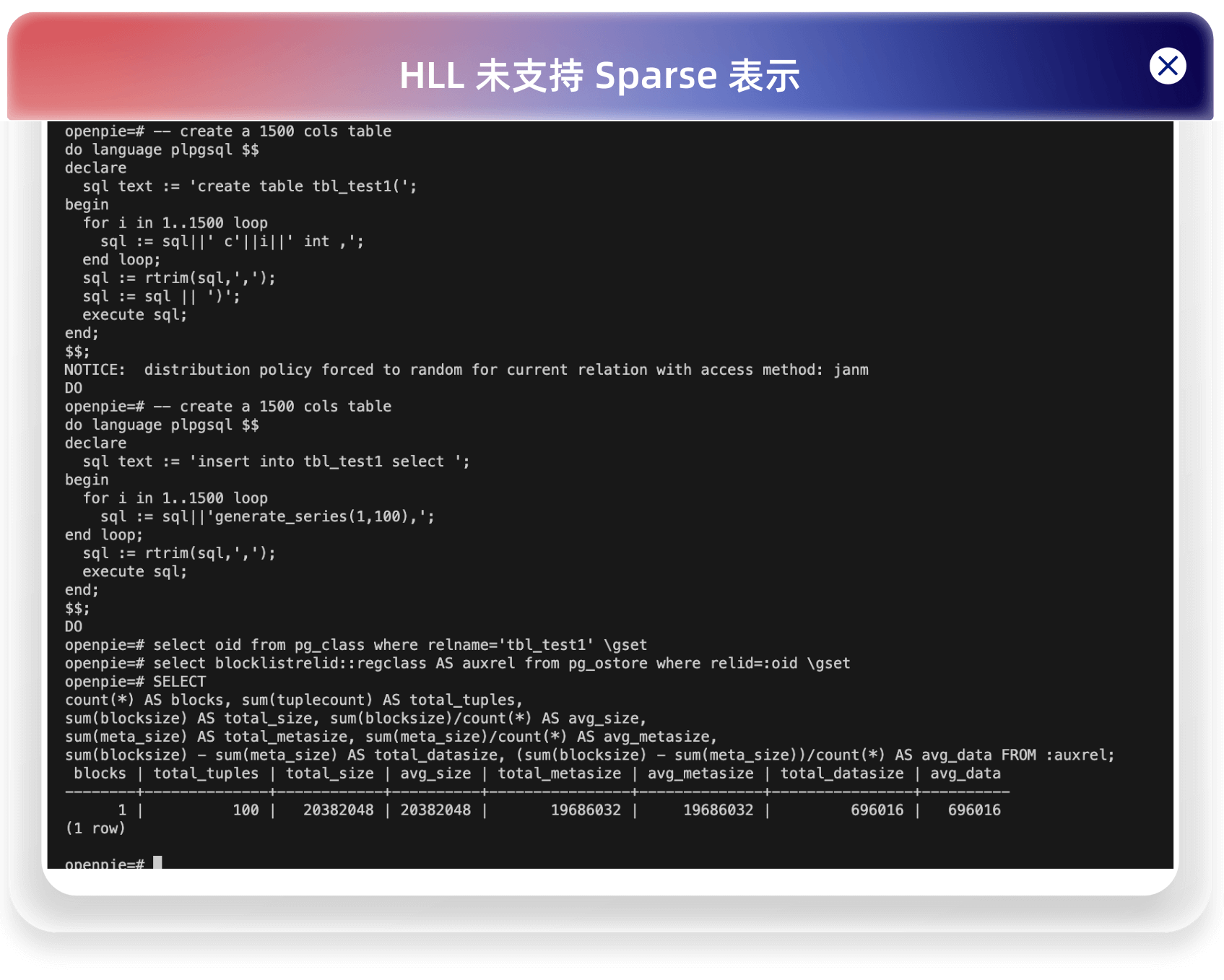
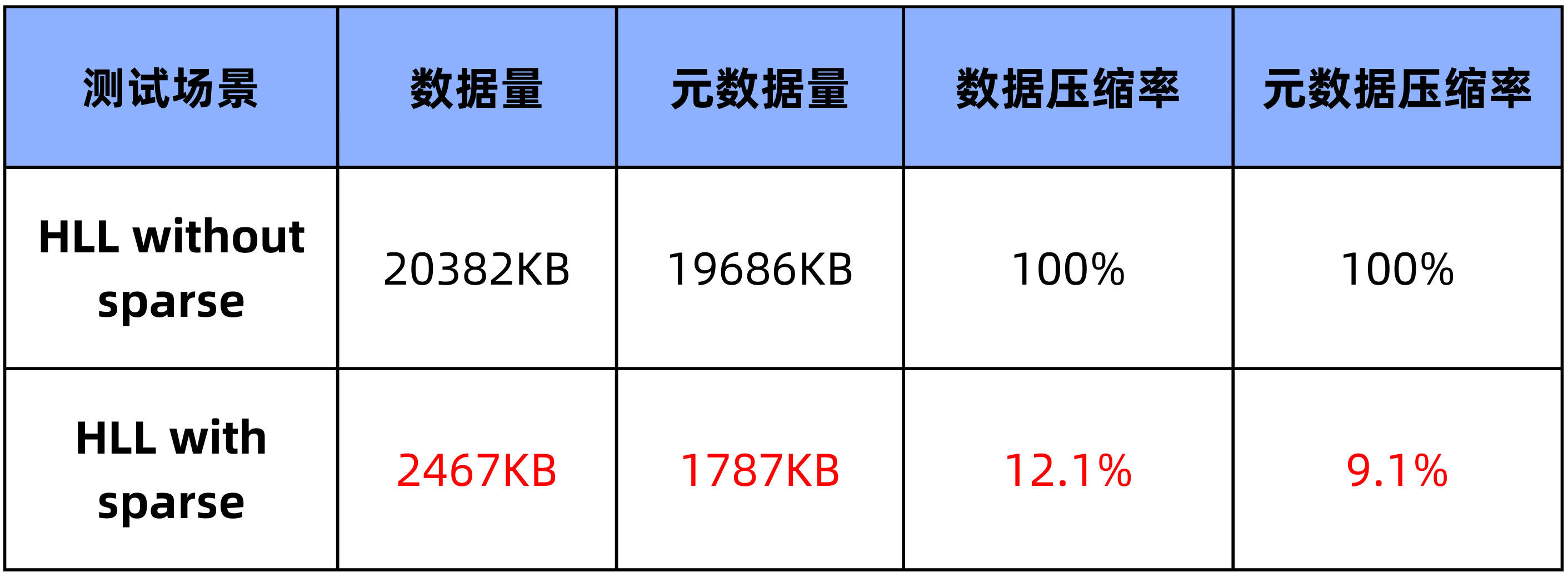
对于初始情况下,如果是 dense 表示,就算 HLL 的桶全为空,也需要 12KB 的空间,而对于 Sparse 表示,只需要 2B。这在基数较低的情况下,减少空间是非常明显的。如下对于一个 1500 列的简墨表,插入 100 行数据,HLL 支持 Sparse 表示前后所占空间对比:
HLL 未支持 Sparse 表示:
HLL 支持 Sparse 表示:
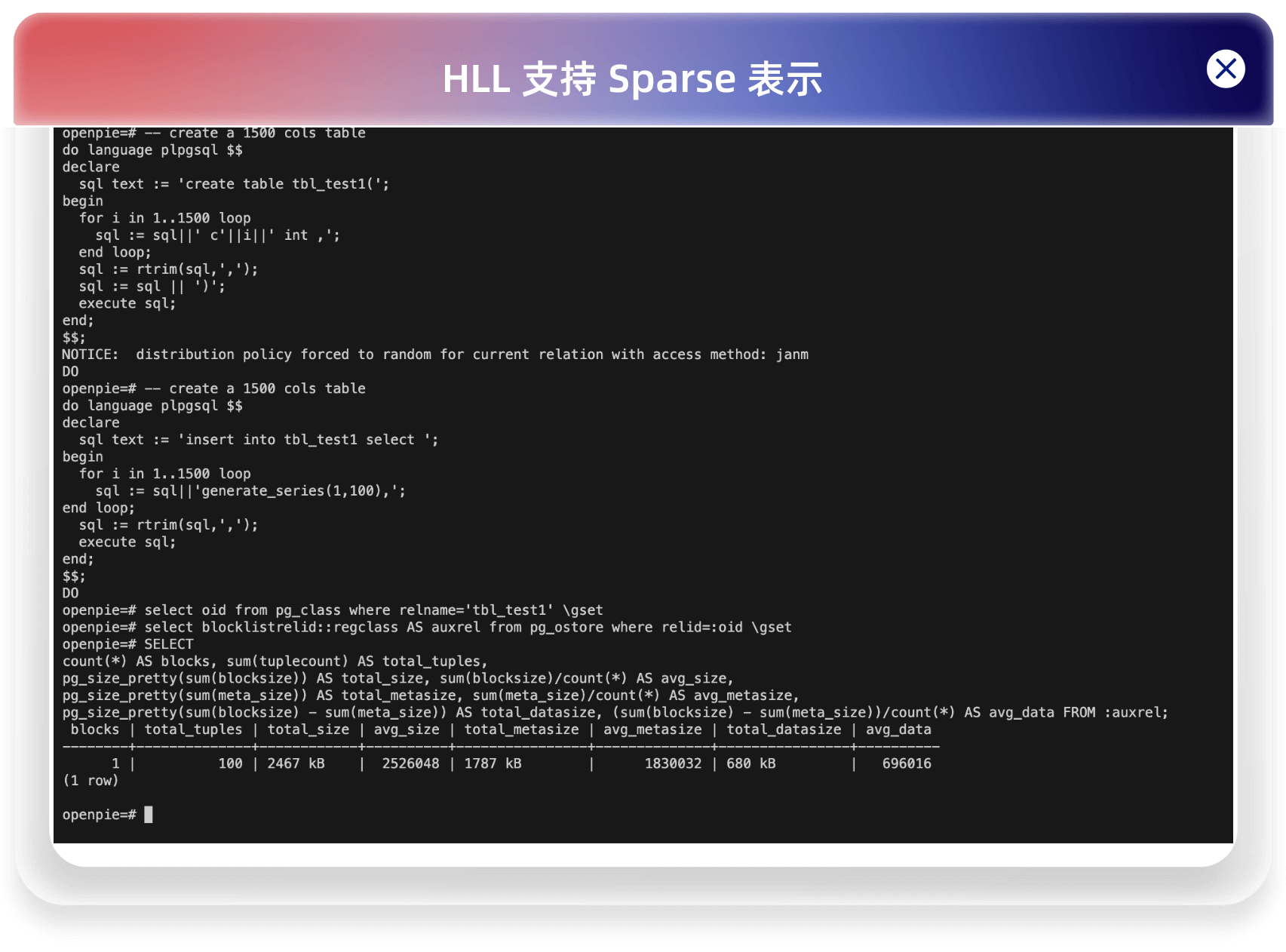
2.2 测试统计
3 Delta Encoding
Delta Encoding(增量编码)是一种数据压缩技术,用于存储具有连续性或重复性的数据。它通过记录相邻数据之间的差异来减小存储空间。
基本原理如下:
- 初始值:选择一个初始值作为基准。这可以是前一个数据点、第一个数据点或任何其他适当的值。
- 计算差异:对于每个后续的数据点,计算其与前一个数据点之间的差异。这可以使用简单的减法运算来实现。
- 存储差异:将计算得到的差异值存储起来。通常,差异值会以二进制形式进行编码,并存储在适当的数据结构中(如数组)。
- 重建原始数据:在需要使用数据时,通过累计差异值和基准值来重建原始数据。从基准值开始,依次加上累积的差异值即可得到原始数据的序列。
3.1 压缩效率对比
Delta Encoding 的优点是能够有效地处理连续或重复的数据,并且在存储空间方面表现出色。它特别适合对时间序列数据、排序的列表或其他具有递增或递减趋势的数据进行压缩。
PieCloudDB 对于变长数据存储,通过 offsets 来存储每个数据的长度。而对于某些类型,如 Decimal,前后数据之间 offset 变化相等,采用Delta Encoding 的方式,可以显著减少 offsets 的存储空间。特别对于 Decimal 这种本身数据就很短的类型,可能就更明显了。
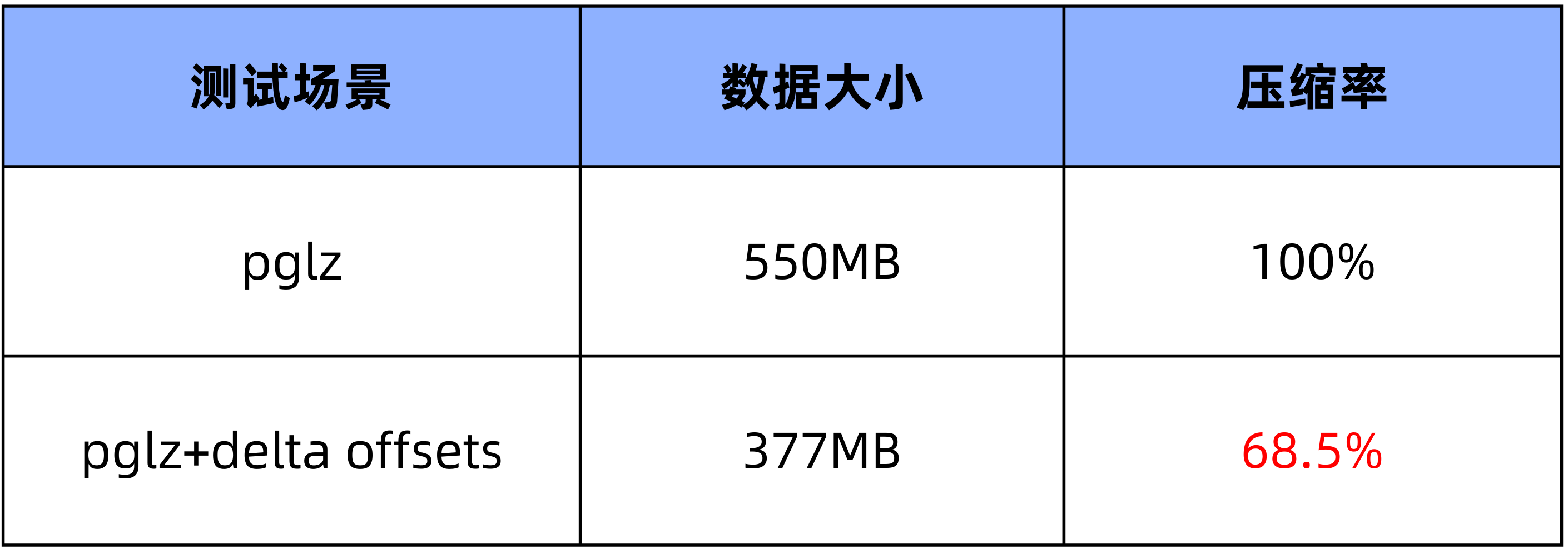
例如 1500 列类型为 NUMERIC(20,10) 的宽表,在未使用 Delta Encoding 情况下为 550MB,使用 Delta Encoding 后为 377MB,结果如下图所示:

3.2 测试统计
4 总结展望
PieCloudDB 将打造自适应压缩,通过支持 ZSTD、HLL sparse representation、Delta Encoding,在通用数据、元数据、字符串类型数据上大幅降低的存储大小。后续,PieCloudDB 会持续优化迭代压缩方法,支持拓展更多的编码方式,例如 Dict Encoding、BIT_PACKED、RLE 等,根据数据类型的不同,选择合适的编码方式,从而达到更好的压缩比。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: Glide transform CircleCrop()圆图,Kotlin
Glide transform CircleCrop()圆图,Kotlin import android.os.Bun服务器托管网dle import android.widget.ImageView import androidx.appcompat.app…
