
简介
使用自动化工具playwright根据输入关键词,获取b站所有的搜索结果的视频标题,视频链接。
一、css
观察网页结构,右键进入检查页获取css定位。先填充查找信息后点击搜索。
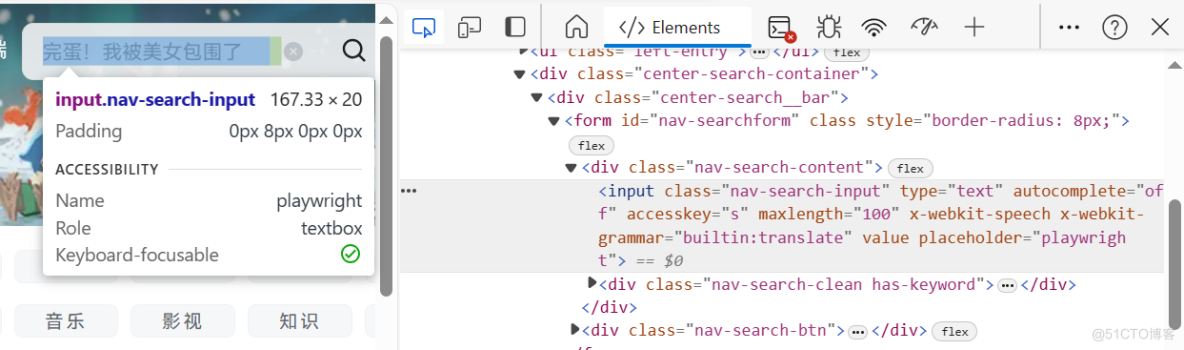
page.locator(".nav-search-input").fill(msg)
page.locator(".nav-search-btn").click()进入到搜索界面后,同样进行分析
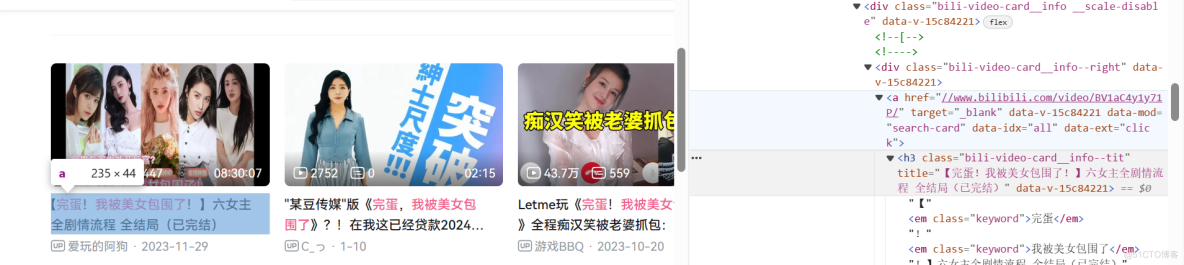
res = page1.locator(".bili-video-card__info--right > a").all()
for i in res:
link = "https:" + i.get_attribute("href")
title = i.locator("h3").inner_text()每获取一页进行点击下一页
try:
next_button.click()
page1.wait_for_timeout(1000)
except Exception:
break完整代码如下:
import csv
from playwright.sync_api import sync_playwright
def main(msg):
with sync_playwright() as p:
browser = p.chromium.launch(executable_path=r"C:UsersPCAppDataLocalms-playwrightchromium-1091chrome-winchrome.exe")
context = browser.new_context()
page = context.new_page()
page.goto("https://www.bilibili.com/")
with page.expect_popup() as page1_info:
page.locator(".nav-search-input").fill(msg)
page.locator(".nav-search-btn").click()
page1 = page1_info.value
page1.wait_for_timeout(1000)
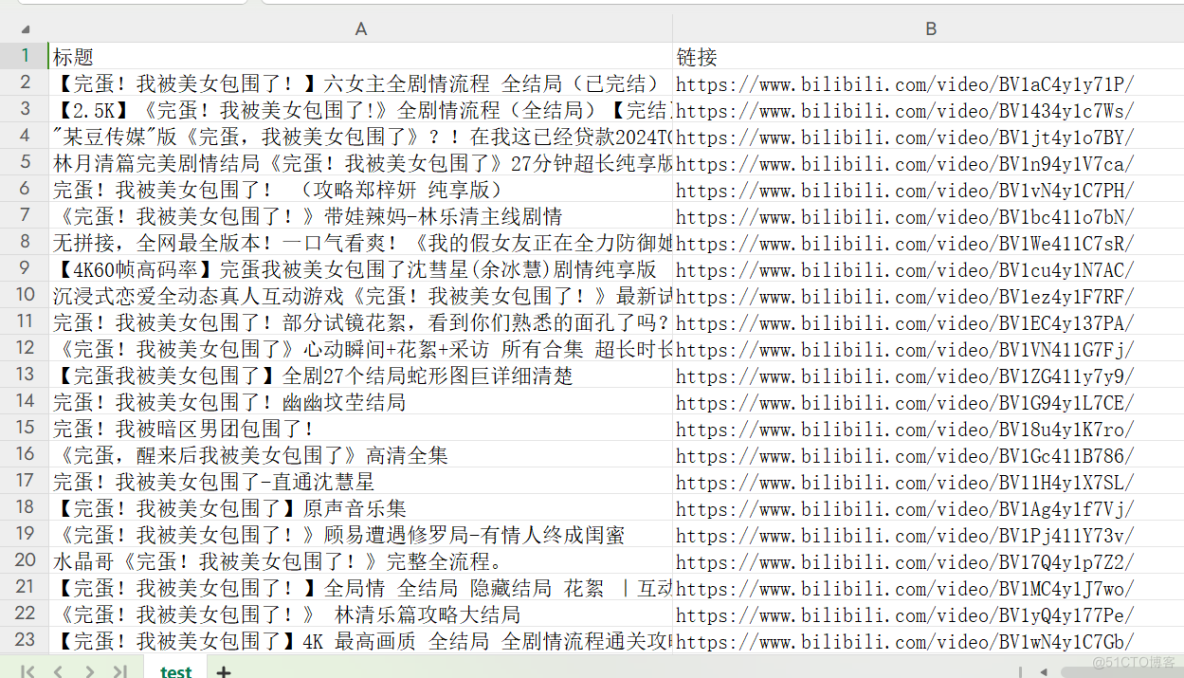
with open('test.csv', 'w', newline='', encoding='utf-8') as f:
col_names = ['标题', '链接']
writer = csv.DictWriter(f, fieldnames=col_names)
writer.writeheader()
while True:
res = page1.locator(".bili-video-card__info--right > a").all()
for i in res:
link = "https:" + i.get_attribute("href")
title = i.locator("h3").inner_text()
print(f"标题: {title}, 链接: {link}")
writer.writerow({'标题': title, '链接': link})
next_button = page1.get_by_role("button", name="下一页")
try:
next_button.click()
page1.wait_for_timeout(1000)
except Exception:
break
browser.close()
if __name__ == "__main__":
msg = input("请输入查询信息:")
main(msg)二、xpath
也支持使用xpath表达式
page.locator('xpath=//*[@id="nav-searchform"]/div[1]/input').fill(msg)观察xpath路径结构

只需修改中间的div[i]即可,但要注意首页和其他页的结构不一样。
完整代码:
import csv
from playwright.sync_api import sync_playwright
def main(msg):
with sync_playwright() as p:
browser = p.chromium.launch(headless=False,executable_path=r"C:UsersPCAppDataLocalms-playwrightchromium-1091chrome-winchrome.exe")
context = browser.new_context()
page = context.new_page()
page.goto("https://www.bilibili.com/")
with page.expect_popup() as page1_info:
page.locator('xpath=//*[@id="nav-searchform"]/div[1]/input').fill(msg)
page.locator('xpath=//*[@id="nav-searchform"]/div[2]').click()
page1 = page1_info.value
page1.wait_for_timeout(1000)
with open('test2.csv', 'w', newline='', encoding='utf-8') as f:
col_na服务器托管网mes = ['标题', '链接']
writer = csv.DictWriter(f, fieldnames=col_names)
writer.writeheader()
res = page1.locator('xpath=//*[@id="i_cecream"]/div/div[2]/div[2]/div/div/div/div[2]/div')
for i in range(1, 31):
try:
link = "https:" + res.locator(f'xpath=/div[{i}]/div/div[2]/div/div/a').get_attribute("href")
title = res.locator(f'xpath=/div[{i}]/div/div[2]/div/div/a/h3').get_attribute("title")
print(f"第1页!!!!!{i}!!!!!标题: {title}, 链接: {link}")
writer.writerow({'标题': title, '链接': link}服务器托管网)
except:
break
next_button = page1.get_by_role("button", name="下一页")
try:
next_button.click()
page1.wait_for_timeout(1000)
except Exception:
browser.close()
page = 1
while True:
page+=1
res = page1.locator('xpath=//*[@id="i_cecream"]/div/div[2]/div[2]/div/div/div[1]')
for i in range(1, 31):
try:
link = "https:" + res.locator(f'xpath=/div[{i}]/div/div[2]/div/div/a').get_attribute("href")
title = res.locator(f'xpath=/div[{i}]/div/div[2]/div/div/a/h3').get_attribute("title")
print(f"第{page}页!!!!!{i}!!!!!标题: {title}, 链接: {link}")
writer.writerow({'标题': title, '链接': link})
except:
break
next_button = page1.get_by_role("button", name="下一页")
try:
next_button.click()
page1.wait_for_timeout(1000)
except Exception:
break
browser.close()
if __name__ == "__main__":
msg = input("请输入查询信息:")
main(msg)服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
对于学习 Vue 的同学来说,封装 vue 组件是实现代码复用的重要一环。在 Vue 官网中非常详细地介绍了 vue 组件的相关知识,我这里简单摘取使用最频繁的几个知识点,带大家快速入门 vue 组件的使用。 快速入门 我们假设在页面上有很多地方都要用到一个计…
