
大家好,我是蓝胖子,关于prometheus的入门教程有很多,拿我之前学prometheus的经历来讲,看了很多教程,还是会对prometheus的描点以及背后的统计原理感到迷惑,所以今天我们就来分析下这部分,来揭开其神秘的面纱。
我们先来看看prometheus里的数据模型是怎么样的,只有知道了数据结构,才能理解对后续这些数据如何描点,如何计算出相应指标值。
数据模型
prometheus中存的是时序数据,时序数据有个特点是每条数据都有一个时间戳,并且时序数据都有一个metric_name(指标名),和一系列的label,以及当前指标的值value。当用prometheus web控制台查询出来的就是一条条时序数据,如下图所示:

时序数据描述一个指标的表达式可以归纳为:
metric_name{label_name1=label_val1,label_name2=label_val2,....}
表达式开头是指标名,{}里的就是指标的标签。
在prometheus中,如果指标名和标签完全相同,那么将会认为他们是同一个指标,将一个指标不同时间戳的时序数据称为指标的样本。
这里要特别明确一点,用过prometheus 客户端的同学都知道prometheus有四大指标类型Counter,Guage,Histogram,Summary,但无论是哪种指标类型在prometheus服务端这边都是按照上述的指标格式进行存储的,prometheus server在存储时并不会去存特定某个指标是什么指标类型。
理解了prometheus server存储数据的类型,我们再来看看对prometheus server 进行查询时的数据返回类型。
prometheus server提供了两个api对外提供查询,分别是query 和query_range ,在prometheus中 用vector 类型表示单个时间点的指标数据,用matrix 表示一组时间点的指标数据。所以query_range api只能返回matrix 类型的数据。我们用prometheus web控制台演示下。
首先来看下在table列进行查询时涉及的查询,在table列进行查询会调用到query 的api,其返回结果既可以是matrix 类型,也可以是vector 类型。

如上图所示,查询返回的是vector类型的数据 , 我们在table这一栏输入PromQl查询语句,默认是查出当前时间最新的指标,可以看到返回的result是一个数组,因为匹配查询语句的不止一个指标,接着返回了指标的时间戳以及对应的值val。
在table这一列除了查询某个指标的瞬时值,还可以查某段时间内的值,对应的prometheus server api的返回类型就将是matrix类型了 ,如下图所示,我们可以修改PromQl语句让其查1m内的数据:
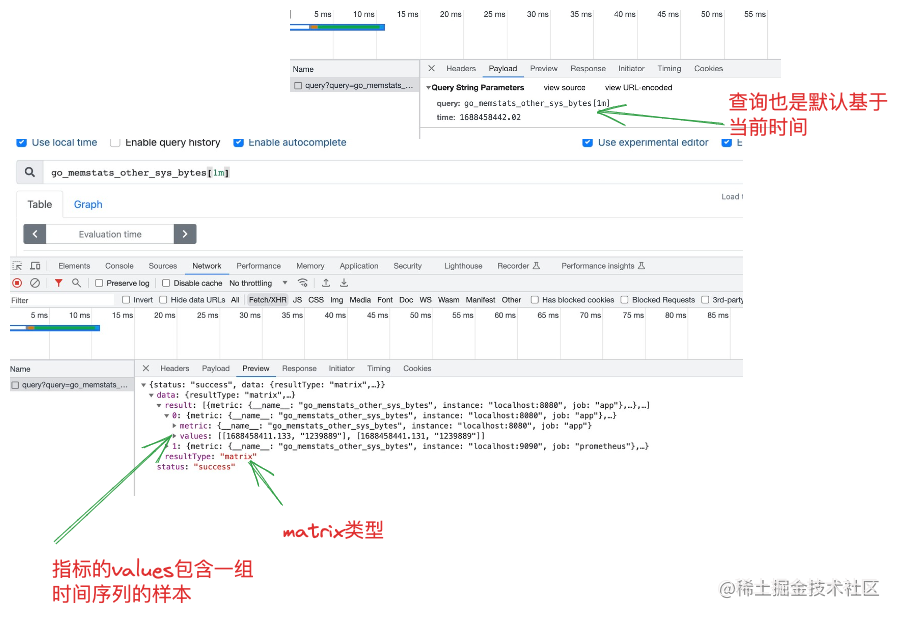
如上图所示,将查询语句改为go_memstats_other_sys_bytes{}[1m] 后返回的就是matrix类型的数据了,它表示一组时间点的数据。
其实看到这里,你应该能想到,prometheus绘图就是根据matrix类型的数据进行描点绘图的 。
描点原理
紧接着,我们就来看下prometheus的描点绘图原理。
首先要明确一点,绘图的原理本质上就是在一个个时间片段里进行描点,然后再将各个点连起来就形成了随时间变化的监控图Graph。所以在描点绘图时,用到的数据查询结果仅仅只能是matrix类型,因为只有它才能表示一个指标一组时间点的样本值。
我们再回顾下matrix数据格式是怎样的,
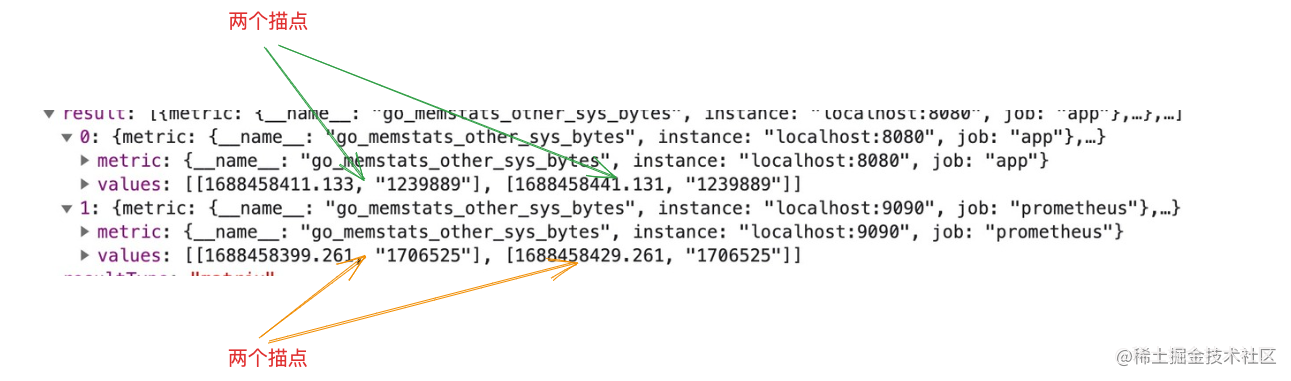
matrix数据格式的返回,每个指标都会携带一组时间点的样本,到时候描点时就是根据这些样本点的时间点为横坐标,样本的值为纵坐标进行绘图的。
接着,我们来看下绘图用到的查询数据api, 和在table栏进行查询不同,在绘图界面查询数据用到的api是query_range ,query_range返回的数据格式是matrix 类型的数据
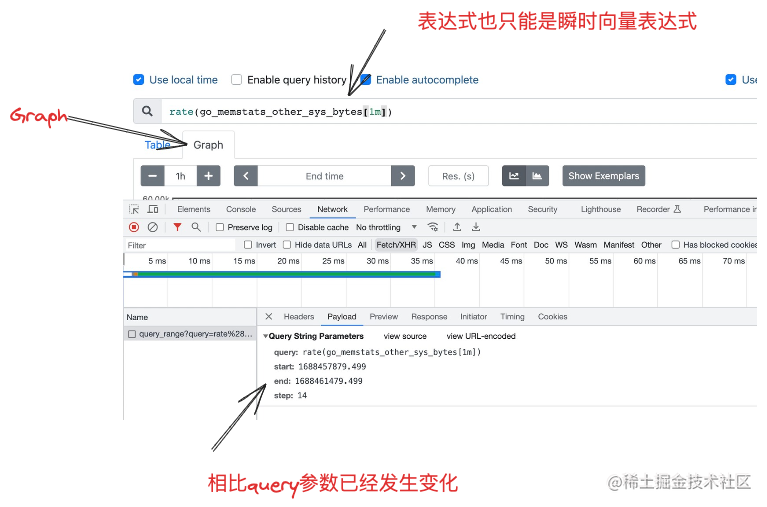
注意下query_range的参数,已经和query不同了,因为query毕竟只查基于某个时间点的数据,而query_range是查某段时间的数据,所以query_range有个开始时间start和结束时间end,除此以外,它还有个参数step,这个参数是表示将start和end之间的时间段按step步长分割为更小的时间段,然后在每个小的时间段内将会产生一个描点 。最后就是将指标的描点全部连接起来就是一个曲线了。
描点是如何计算出来的
知道了在每个小的时间段内,prometheus会产生一个描点,我们还需要知道描点究竟是如何计算出来的。
拿截图的表达式rate(go_memstats_other_sys_bytes[1m]) 举例,假设时间区间[start,end]被step分成了3小段。
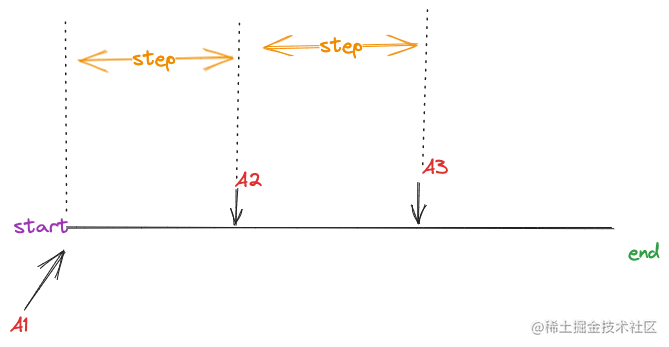
如上图,其中每段的开始时间戳分别是A1,A2,A3,按step进行累加,这3个小的时间段将会产生3个描点,每个描点计算规则如下:
val=rate函数(当前时间段与当前时间段减去1m这段时间内的所有样本)
每个描点,都会执行一次rate函数得到描点的value值,描点的时间戳则是每个小的时间段开始的时间,而计算的样本则是 每个小的时间段开始时间到 之前的1m的时间范围内筛选出来的。
histogram_quantile 表达式如何描点的?
上面的描点例子比较简单,我们来看一个复杂点的,这个也是Histogram 指标类型统计的原理。
如下,我们通常会用到histogram_quantile去计算服务接口时间的耗时情况。
histogram_quantile(0.99,rate(server_handle_seconds_bucket{}[1m]))
它描点的逻辑依然逃不开 将一个大的时间段分为小的时间段,并且每个小的时间段产生描点。也就是说,每个小的时间段也都会执行一次histogram_quantile 函数得到描点值,但histogram_quantile的样本值从哪里得来呢?
是在小的时间段内通过rate函数计算得到的,rate函数的样本来源也和刚才讲的一样,是当前时间段与当前时间段减去1m这段时间内的所有样本。
思考题
这样的确得到了3个描点,能绘制出曲线来,但最开始我在看到这个表达式还是很疑惑的,因为它将之前的每个直方图的指标都进行了rate计算,这样在用histogram_quantile计算最终分位数的时候不会导致结果变化吗?这就涉及到了histogram_quantile计算分为数的逻辑,有空我会在下篇文章继续分析。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
