
discovery支持文件、http、consul等自动发现targets,targets会被发送到scrape模块进行拉取。
一.整体框架
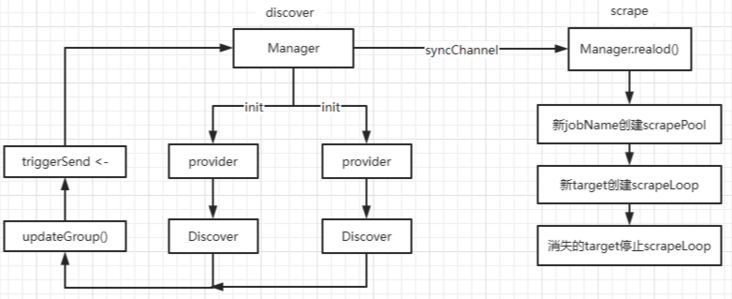
discovery组件通过Manager对象管理所有的逻辑,当有数据变化时,通过syncChannel将数据发送给scrape组件。
discovery组件会为每个Job_name创建一个provider对象,它包含Discover对象:
- Discover对象会自动发现target;
-
当有targets变化时:
- 首先,通过updateGroup()更新Manager中的targets对象;
- 然后,向Manager的triggerSend channel发送消息,告诉Manager要更新;
- 最后,Manager收到triggerSend channel中的消息,将Manager中的所有targets发送给syncChannel;
scrape组件接收syncChannel中的数据,然后使用reload()进行抓取对象更新:
- 若有新job,则创建scrapePool并启动它;
- 若有新target,则创建scrapeLoop并启动它;
- 若有消失的target,则停止其scrapeLoop;
二.discovery组件的代码入口
- 先创建provider和dicover对象;
- 再启动provider;
// discovery/manager.go
func (m *Manager) ApplyConfig(cfg map[string]sd_config.ServiceDiscoveryConfig) error {
.......
m.targets = make(map[poolKey]map[string]*targetgroup.Group)
//根据配置创建provider和discover对象
for name, scfg := range cfg {
failedCount += m.registerProviders(scfg, name)
}
//启动provder
for _, prov := range m.providers {
m.startProvider(m.ctx, prov)
}
return nil
}三.provider和discover对象的初始化
provider对象的初始化在Manager.registerProviders():
- 对自动发现的配置,为其每个配置创建provider和discover对象;
- 将provider对象加入m.providers;
// discovery/manager.go
// registerProviders returns a number of failed SD config.
func (m *Manager) registerProviders(cfg sd_config.ServiceDiscoveryConfig, setName string) int {
add := func(cfg interface{}, newDiscoverer func() (Discoverer, error)) {
t := reflect.TypeOf(cfg).String()
//创建Discover对象
d, err := newDiscoverer()
//构造provider对象
provider := provider{
name: fmt.Sprintf("%s/%d", t, len(m.providers)),
d: d,
config: cfg,
subs: []string{setName},
}
//加入m.providers
m.providers = append(m.providers, &provider)
}
// 对file_sd_configs中的每个配置,创建provider和discover
for _, c := range cfg.FileSDConfigs {
add(c, func() (Discoverer, error) {
return file.NewDiscovery(c, log.With(m.logger, "discovery", "file")), nil
})
}
......
for _, c := range cfg.KubernetesSDConfigs {
add(c, func() (Discoverer, error) {
return kubernetes.New(log.With(m.logger, "discovery", "k8s"), c)
})
}
………
}discover对象的创建,以file_sd.Discover为例:
// discovery/file/file.go
// 使用file_sd_config,创建file Discovery对象
func NewDiscovery(conf *SDConfig, logger log.Logger) *Discovery {
disc := &Discovery{
paths: conf.Files,
interval: time.Duration(conf.RefreshInterval),
timestamps: make(map[string]float64),
logger: logger,
}
fileSDTimeStamp.addDiscoverer(disc)
return disc
}discover是interface,不同的发现方式均实现了该interface:
// discovery/manager.go
type Discoverer interface {
Run(ctx context.Context, up chandiscover对象当发现有数据变化,会将数据写入Run()中的chan参数。
四.discover对象产生数据
每个provider对象启动时:
- 启动1个goroutine: 执行disover.Run()去自动发现targets;
- 启动1个goroutine: 执行m.update()更新数据并通知Manager;
// discovery/manager.go
func (m *Manager) startProvider(ctx context.Context, p *provider) {
ctx, cancel := context.WithCancel(ctx)
updates := make(chan []*targetgroup.Group)
m.discoverCancel = append(m.discoverCancel, cancel)
// 让provider中的discover对象,使用Run()去自动发现
// 当有数据变化,将数据写入updates
go p.d.Run(ctx, updates)
// 更新Manager中的targets并通知Manager
go m.updater(ctx, p, updates)
}1) goroutine1: p.d.Run()
以file.Discovery为例:
-
它感知file内容的变化,使用d.refresh()解析file内容:
- 通过fsnotify感知file变化;
- 使用Ticker定期刷新(默认5min);
- d.refresh()负责读文件,然后将结果发送到channel:
// discovery/file/file.go
func (d *Discovery) Run(ctx context.Context, ch chan// discovery/file/file.go
func (d *Discovery) refresh(ctx context.Context, ch chan2) goroutine2: m.updater()
该goroutine负责将接收并处理上一步chan中的数据:
- 首先,将接收的数据更新至m.targets中;
- 然后,向m.triggerSend这个chan发送消息;
// discovery/manager.go
func (m *Manager) updater(ctx context.Context, p *provider, updates chan []*targetgroup.Group) {
for {
select {
case Manager对象会接收并处理m.triggerSend消息:
- 收到m.triggerSend后,将Manager中的所有targets发送到m.syncChan;
- scrape组件会接收并处理syncChan;
// discovery/manager.go
func (m *Manager) sender() {
ticker := time.NewTicker(m.updatert)
defer ticker.Stop()
for {
select {
case 五.scrape组件接收数据
上一步讲到,discovery.Manager将当前所有的targets,发送到m.syncChan;
scrape组件会接收并处理m.syncChan中的数据:
// cmd/prometheus/main.go
func main() {
......
scrapeManager.Run(discoveryManagerScrape.SyncCh())
......
}scrapeManager.Run()收到数据后:
- 读取chan中的数据,更新至scrape.Manager.targets中;
- 发送triggerReload消息,由m.reload()进行处理;
// scrape/manager.go
func (m *Manager) Run(tsets m.reloader()处理m.triggerReload消息:
- 接收m.triggerReload消息;
- 调用m.reload()进行处理;
// scrape/manager.go
func (m *Manager) reloader() {
ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()
for {
select {
case m.reload()解析新的targetSets:
- 若有新job_name,则创建scrapePool;
- 对每个scrapePool进行sync();
func (m *Manager) reload() {
m.mtxScrape.Lock()
var wg sync.WaitGroup
for setName, groups := range m.targetSets {
// 新job_name配置,创建scrapePool
if _, ok := m.scrapePools[setName]; !ok {
scrapeConfig, ok := m.scrapeConfigs[setName]
sp, err := newScrapePool(scrapeConfig, m.append, m.jitterSeed, log.With(m.logger, "scrape_pool", setName))
m.scrapePools[setName] = sp
}
wg.Add(1)
// 并行的同步每个scrapePool
// Run the sync in parallel as these take a while and at high load can't catch up.
go func(sp *scrapePool, groups []*targetgroup.Group) {
sp.Sync(groups)
wg.Done()
}(m.scrapePools[setName], groups)
}
m.mtxScrape.Unlock()
wg.Wait()
}scrapePool.sync():
- 对新的target,创建scrapeLoop并执行;
- 对消失的target,停止其scrapeLoop并删除其对象;
// scrape/scrape.go
func (sp *scrapePool) sync(targets []*Target) {
for _, t := range targets {
t := t
hash := t.hash()
if _, ok := sp.activeTargets[hash]; !ok {
s := &targetScraper{Target: t, client: sp.client, timeout: timeout}
// 新target,创建scrapeLoop
l := sp.newLoop(scrapeLoopOptions{
target: t,
scraper: s,
limit: limit,
honorLabels: honorLabels,
honorTimestamps: honorTimestamps,
mrc: mrc,
})
sp.activeTargets[hash] = t
sp.loops[hash] = l
// 执行scrapeLoop
go l.run(interval, timeout, nil)
}
}
var wg sync.WaitGroup
for hash := range sp.activeTargets {
// 消失的target
if _, ok := uniqueTargets[hash]; !ok {
wg.Add(1)
go func(l loop) {
l.stop() //停止scrapeLoop
wg.Done()
}(sp.loops[hash])
delete(sp.loops, hash) //删除对象
delete(sp.activeTargets, hash)
}
}
wg.Wait()
}服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
