
智慧作业最近上线「个性化手册」(简称个册)功能,一份完整的个性化手册分为三部分:
- 学情分析:根据学生阶段性的学习和考试情况进行学情分析、归纳、总结,汇总学情数据;
- 精准推荐:推荐算法基于学情数据结合知识图谱进行精准练习题推荐;
-
错题回顾:错题的阶段性回顾复习。
第一部分学情分析的PDF由Node.js加工,与Java后端通过消息队列RabbitMQ进行数据交互,本文简单记录一下Node.js批量加工PDF服务的架构模式,以及基于现阶段发现的问题,梳理未来的迭代规划和演进方向。
业务特征
个册三个部分的PDF数据来源不同,生产逻辑独立由不同的服务生产,最终将三份PDF合并为一份,还要支持班级所有学生批量生产和压缩打包,所以这个功能在技术角度最主要的特征就是环节多、耗时长:
- 环节多意味着在各个服务之间存在较多的网络通信和数据交互,核心挑战在于如何设计低耦合、高可用的服务架构;
-
耗时长一方面体现在多个环节的总耗时,另一方面体现在三个PDF生产服务各自的加工耗时。
基于以上业务特征,PDF加工服务架构设计的一个大方向就是将长耗时任务异步处理,各服务之间逻辑解耦,通过消息队列进行数据交互。
技术选型
服务端生成PDF通常有两种方案:
- 第一种是使用 pdfkit 之类的工具通过代码绘制,这种方案最大的问题是可渲染的内容类型有限,定制化不足;
- 第二种是创建 headless browser用html渲染后截取pdf,这种方案的架构相对复杂,但是可以支持所有web端的内容类型。
个册第一部分学情分析的某一页长这个样子:
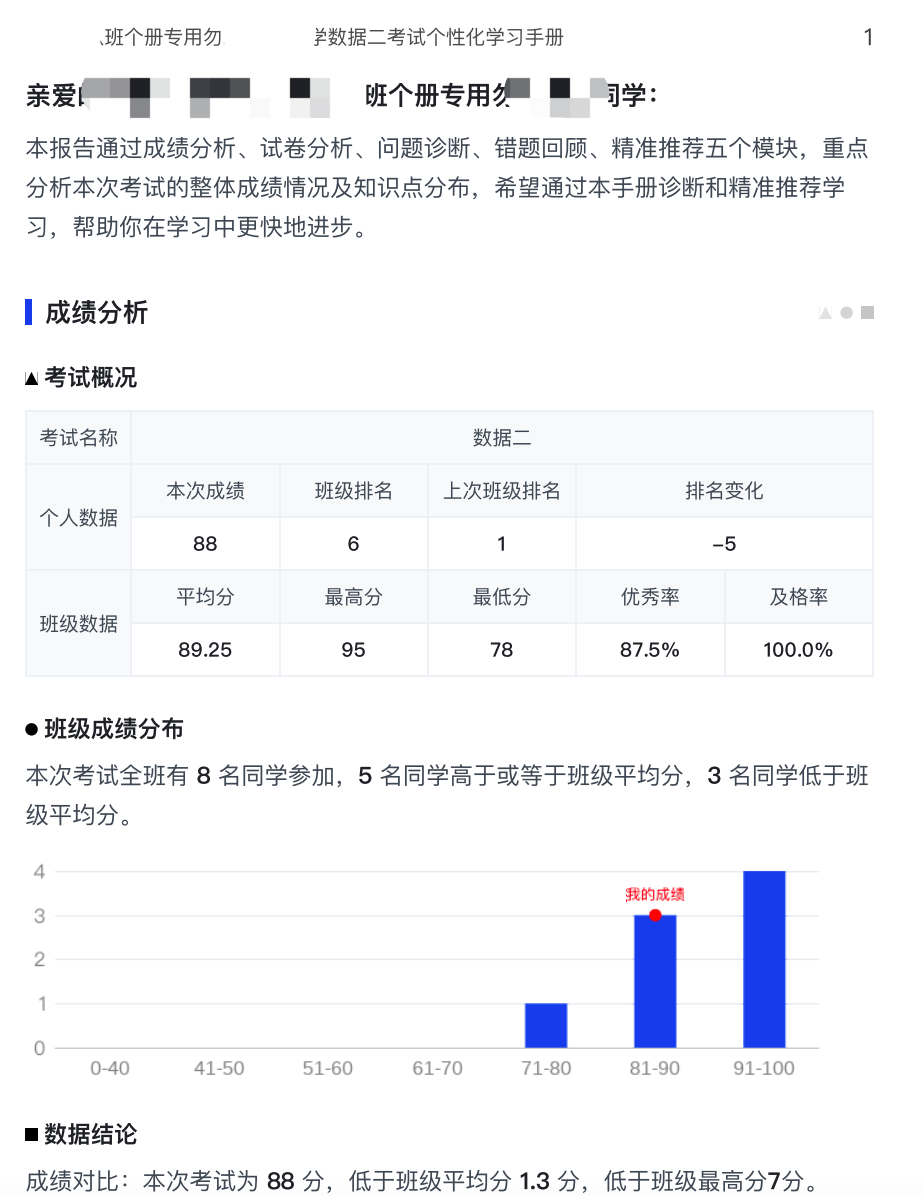
仅这一页就涵盖文本、表格、图表以及各种自定义图案,内容类型多样并且后续迭代可能增加更多定制化内容,第一种方案的局限性很难满足需求,所以最终选定 headless browser 方案。
具体到 headless browser 的技术选型就非常有限了,可选的无非就是 Selenium/PhantomJS 这类老招牌,或者 Puppeteer/Playwright 这类新玩家。
严格来说Selenium只是一种类似按键精灵的工具,可通过代码在浏览器中模拟人的操作,本身并不是浏览器,所以需要搭配第三方浏览器使用,比如PhantomJS。
Selenium/PhantomJS 的最大的优点就是生态健全,支持多种编程语言,有相对繁荣的技术社区;缺点就是稳定性和性能较差,Selenium的稳定性出了名的糟糕,PhantomJS五年前就停止维护了。这哥俩通常用在对稳定性要求不是很高的场景,比如爬虫。
与之形成鲜明对比的,Puppeteer/Playwright 最大的优点就是稳定性高,性能更优;缺点就是对编程语言的支持有限,生态和技术社区相对没那么健全。
个册的业务特征一是对稳定性和性能要求很高;二是不要求跨浏览器(Playwright支持浏览器类型更丰富)。最终综合考虑API易用性、稳定性、性能、社区、风险等因素,在 Puppeteer 和 Playwright 之间选择了 Puppeteer。既然选定了 Puppeteer,配套的自然就是 Node.js了。
Puppeteer 和 Playwright 的对比可以参考这篇文章:Playwright vs Puppeteer: Core Differences。
这个需求是我第一次使用Puppeteer,还没完全摸透,下文涉及到Puppeteer相关的方案如果有问题,欢迎讨论指点。
实现方案
智慧教育的分层架构如下:
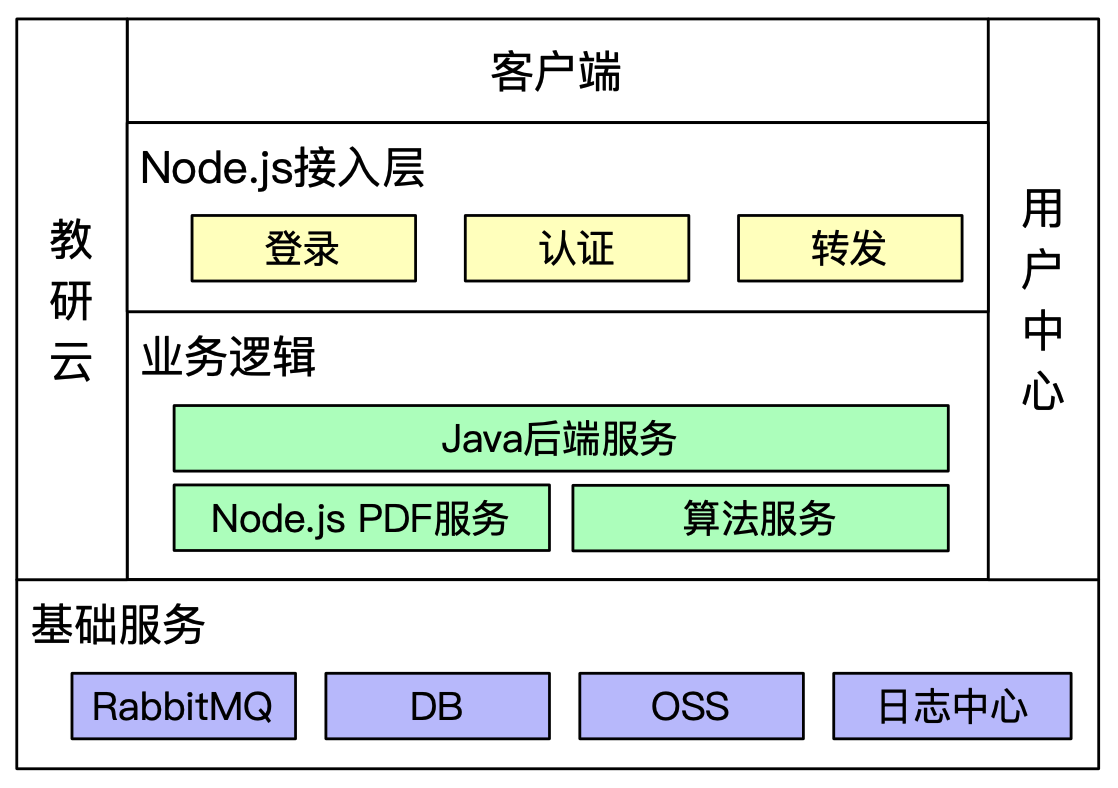
Node.js PDF服务是本次需求新增的,为了方便分离部署和优化,PDF服务单独建立一个服务,不涉及Node.js接入层的改动。下图是个册PDF加工的完整流程:
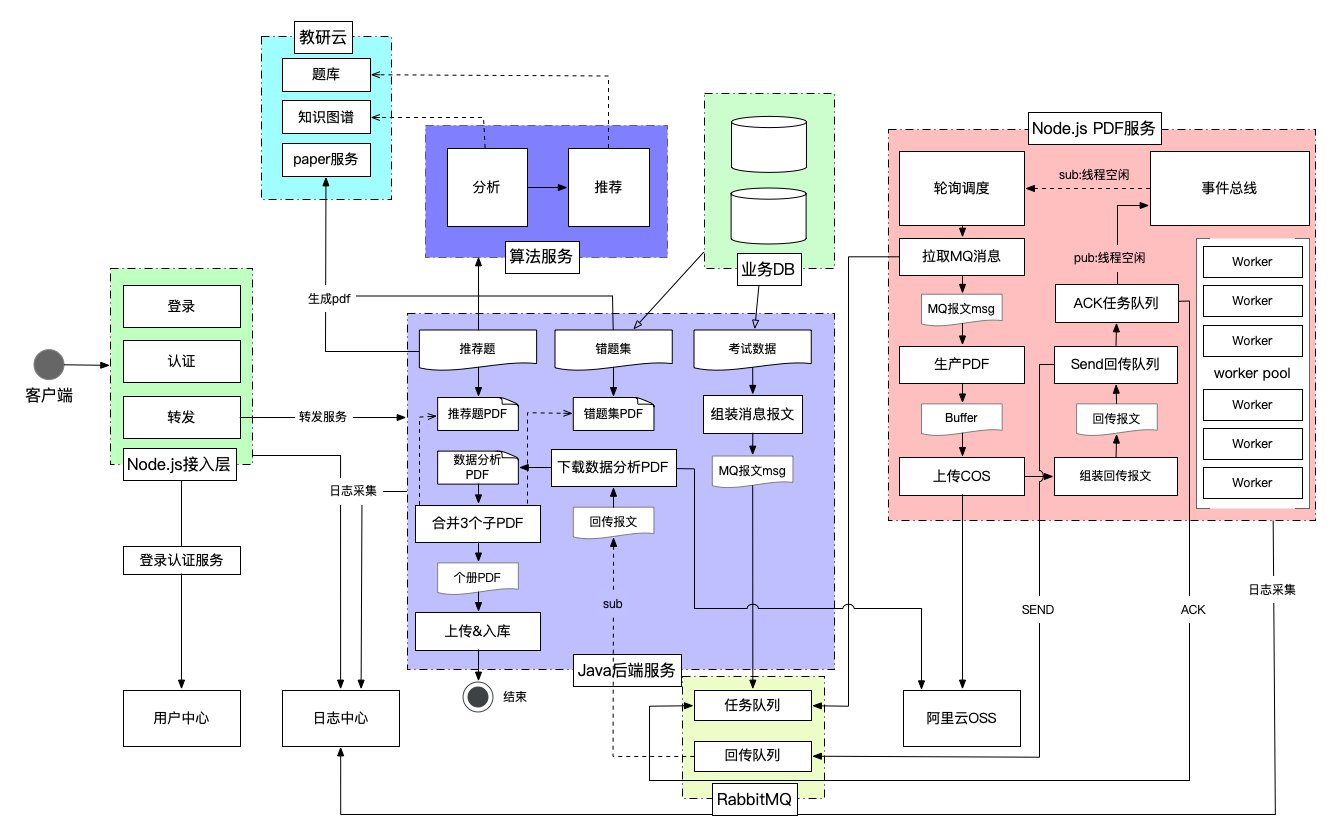
每个环节的具体流程不细讲,Node.js PDF加工服务的细节下文详解。与Node.js PDF服务相关最关键的是与Java后端的数据交互流程。Java后端与Node.js PDF服务通过 RabbitMQ 消息队列进行数据交互,建立两个队列:
| 队列 | 生产者 | 消费者 | 说明 |
|---|---|---|---|
| 任务队列 | Java后端 | Node.js PDF服务 | Java 向队列中发送个册渲染数据,Node.js 消费 |
| 回传队列 | Node.js PDF服务 | Java后端 | Node.js 向队列中发送pdf加工结果数据,Java 消费 |
这部分没啥好讲的,Node.js与Java之间按照约定的数据规范组装数据即可,下面详细介绍一下Node.js加工pdf的具体逻辑。
这一版个册的第一部分学情分析控制在3页,早期规划的个册PDF大约25页左右,技术调研和架构设计都是基于这个预期进行的,所以现在这套模式多少有点杀鸡用牛刀的意思,不过前期打好基础给后续迭代留些空间也是好事。
单份PDF加工流程
为了更方便理解,在介绍pdf加工流程之前,有必要先简要一下Node.js PDF服务的架构,以及与PDF加工逻辑最相关的 worker角色。
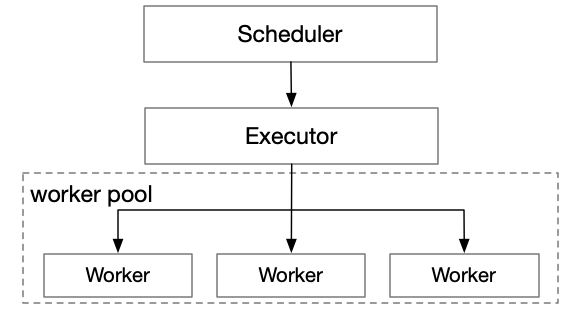
Node.js PDF服务架构最核心的三个角色:
- Scheduler:负责轮询调度,发起任务;
- Executor:负责任务前置和后置相关逻辑,包括worker pool管理、worker 调度、MQ任务队列消息拉取、MQ回传队列消息发送等;
-
Worker:负责实质执行任务,包括pdf渲染、生产、上传OSS;
三者的关系如下所示:
Scheduler和 Executor的具体逻辑以及三个角色之间的调度逻辑下文再详解,PDF文件的实质生产逻辑都集中在 Worker中,流程如下:
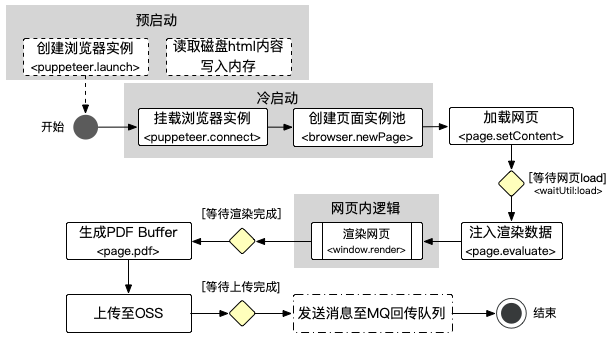
图中「发送消息至MQ回传队列」实质是由 Executor执行,此处画出方便理解完整流程。
预启动
图中虚线部分的预启动是在启动 Node.js 服务之前执行的逻辑,预启动完成之后 Node.js 服务被拉起,所以预启动的耗时是一次性的。
预启动过程执行两个动作:
- 读取磁盘中的html文件内容,写入内存,为后续环节「加载网页」提供数据;
- 创建 Puppeteer browser 实例。
上图中只画出pdf加工逻辑相关的预启动工作,实际上预启动还包含一些其他逻辑,比如建立 MQ 连接信道。
冷启动(废弃)
虽然冷启动在后来开发过程中被废弃,但通过这个事情发现自己的不足,还是值得记录一下的。
最初之所以设想冷启动环节,是因为尝试用 worker 模拟多线程。每个worker会创建一个browser实例和多个page实例(目前是3个),如下所示:
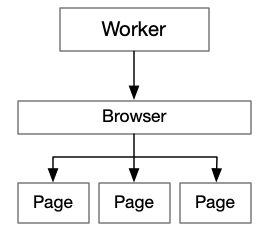
这样做的目的是将每个worker的负载上限固定,便于服务器资源规模预估,避免服务器某个节点负载过高,进而也可以避免k8s集群pod的纵向伸缩。
k8s纵向伸缩的取舍见仁见智,我个人不太建议使用。
如果任务队列长时间为空会触发缓存清理逻辑,销毁browser和page实例以节省服务器资源,再次发起任务会触发冷****启动。冷启动执行两件事情:
- 链接/创建browser实例
- 创建page实例
另外增加一个标识位_mounted代表冷启动是否完成,代码如下:
public async run(){
if(!this._mounted){
// 触发冷启动
this._mount();
}
// ...其他逻辑
}
private async _mount(){
if(!this._browser?.isConnected()){
// 链接browser
this._browser = await puppeteer.connect({
browserWSEndpoint: this._wsEndpoint
});
}
// 创建page实例
if(isEmpty(this._pages)){
for(let i =0;i乍看起来似乎没啥问题,但实际跑一跑代码会发现,在任务调度密集的时候,run函数短时间内被调用多次(具体的调度策略下文讲解),worker会触发多次冷启动,虽然不影响业务逻辑,但会引起服务器资源暴涨,这是因为冷启动会创建新的browser和page实例,但是旧实例并没有被清理,仍然在执行任务。
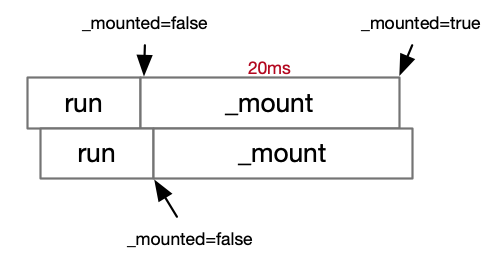
冷启动被调用多次的根本原因是Node.js不是多线程,如下图所示,假设冷启动耗时20ms,在此期间再次调用run函数,标识位_mounted还未被设置为true,就会又触发一次冷启动。
有没有解法?
当然有。多线程编程解决竞态最常用的就是:加锁。既然想模拟多线程那就彻底一点,把锁逻辑也加上呗。
worker本身是有“锁”的,每个worker有3个page实例,只有当存在空闲实例(busy为false)时run函数才可以执行,但是这个锁机制并不能避免多次冷启动问题,因为冷启动完成之前page实例还未被创建。
可能会有人说,那就加个限制,page实例不存在时也不让run函数执行不就得了?这么做的话run函数永远都不会被执行啊大聪明。

既然worker已有的锁不行,那就再加个冷启动锁,冷启动之前锁定,冷启动之后解锁。这么做当然是可以的,但是会增加逻辑复杂度,worker有两种锁,对后期迭代维护无疑是埋雷。
其实之所以有冷启动无非就是为了省点内存,用时间换空间,一个browser实例+3个空白page实例总共100m左右的内存,这年头内存这么便宜,为了省这点空间把逻辑搞那么复杂完全得不偿失。什么叫过度设计,这就是过度设计。

所以后来索性把冷启动过程干掉了,browser和page实例的创建放在worker初始化逻辑里。
public async init() {
/**
* 尽量禁用掉不需要的功能,提高性能
*/
this._browser = await puppeteer.launch({
headless: true,
args: [
'--incognito',
'--disable-gpu',
'--disable-dev-shm-usage',
'--disable-setuid-sandbox',
'--no-first-run',
'--no-sandbox',
'--no-zygote',
'--single-process'
]
});
this._wsEndpoint = this._browser.wsEndpoint();
// _mount函数逻辑不改动,调用_mount函数放在初始化逻辑中
await this._mount();
}
加载网页
网页通过page.setContent(html)函数加载本地html文件,与通过page.goto(url)加载远程URL相比,既节省了部署网页的服务器资源,同时速度也更快:
| 时间消耗 | 执行时机 | 性能瓶颈 | 其他 | |
|---|---|---|---|---|
| 远程URL |
|
运行时 | 网络IO | 异步下载html引用的静态资源会增加额外耗时 |
| 本地html |
|
预启动阶段 | 文件IO+常驻内存 |
上文提到过,本地html文件在预启动阶段提前从磁盘读取存放于内存,运行时无需实时读取。所以文件IO的耗时不算在pdf加工逻辑总耗时中,而加载远程URL只能在运行时执行,会增长pdf加工的总时长。
另外,加载的本地html文件中不能存在静态资源引用,比如js和css必须全部以行内
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
