
1:思路
1:抓取页面
2:解析页面
3:链接数据库
4:写入数据库
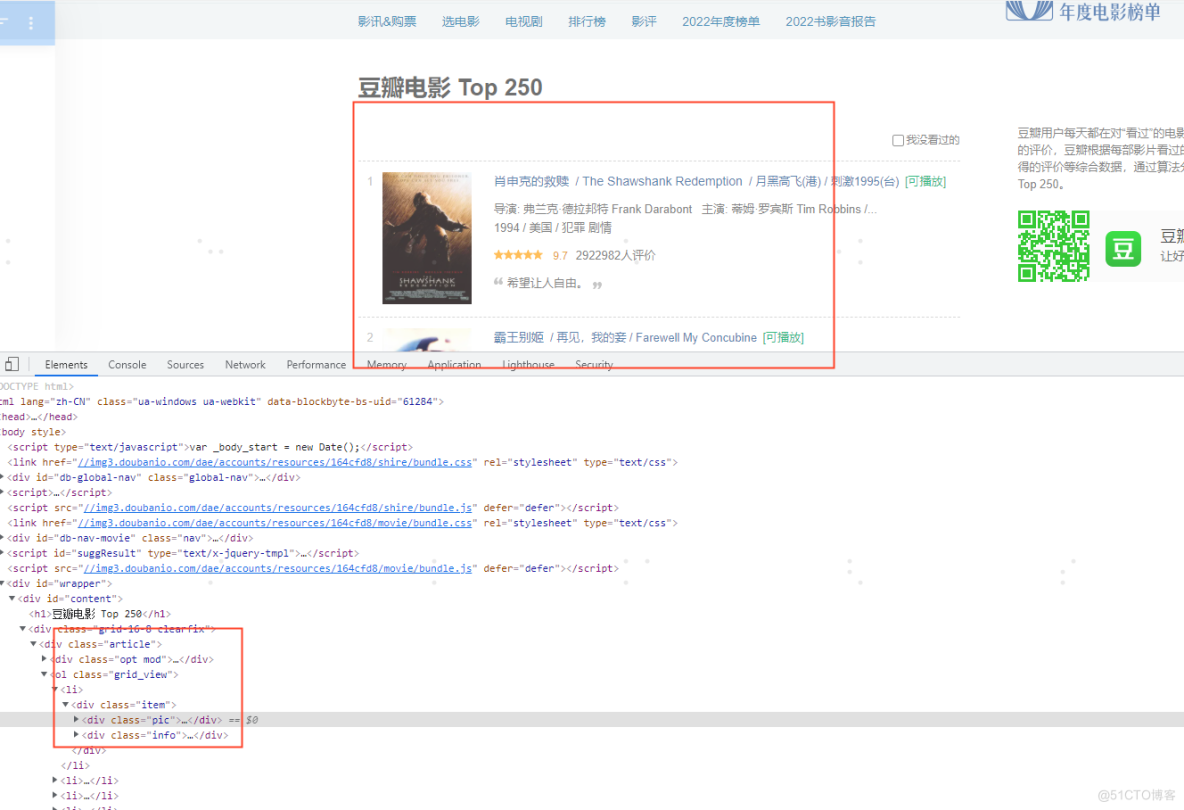
网页数据-元素分析
2:代码
import pymysql
import requests
from bs4 import BeautifulSoup
from pymysql.connections import Connection
def fetch_page(url):
"""
服务器托管网 抓取页面
:param url: 网页地址
:return: 网页的HTML代码
"""
Headers = {
#'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34'
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.3162 SLBChan/8'
}
response = requests.get(url=url, headers=Headers)
return response
def parse_page(response):
"""
解析页面
:param response: 网页源码
:return: 解析到的数据
"""
soup = BeautifulSoup(response.text, 'html.parser')
lilist = soup.select('html > body > div#wrapper ol > li')
fetched_data = []
for i in lilist:
# 电影标题
movieTitle = i.select('li > div.item > div.info > div.hd > a > span.title')
movieList = [i.text for i in movieTitle]
movieTitle = ''.join(movieList).replace(' ', ' ')
# 电影评分
movieScore = i.select_one('li div.bd > div.star > span.rating_num').text
# 电影评论人数
commPeople = i.sel服务器托管网ect_one('li div.bd > div.star > span:nth-child(4)').text[:-3]
# 中心思想
middIdea = i.select_one('li div.bd > p.quote > span.inq')
middIdea = middIdea.text if middIdea != None else ''
#图片地址
movUrl=i.select_one('li div.pic > a').img['src']
print('--url--',movUrl)
fetched_data.append((movieTitle, movieScore, commPeople, middIdea,movUrl))
return fetched_data
def write_to_db(conn: Connection, data):
"""
将数据写入数据库二维表
:param conn: 数据库连接对象
:param data: 保存数据的列表
"""
try:
with conn.cursor() as cursor:
cursor.executemany(
'insert into tb_movie '
' (mov_title, mov_rank, mov_count, mov_gist,mov_url) '
'values '
' (%s, %s, %s, %s,%s)',
data
)
conn.commit()
except pymysql.MySQLError as err:
conn.rollback()
raise err
def main():
conn = pymysql.connect(host='localhost', port=3306,
user='testysp', password='testysp',
database='test', charset='utf8mb4')
print('连接数据库--完成')
try:
for page in range(20):
response = fetch_page(f'https://movie.douban.com/top250?start={page * 25}')
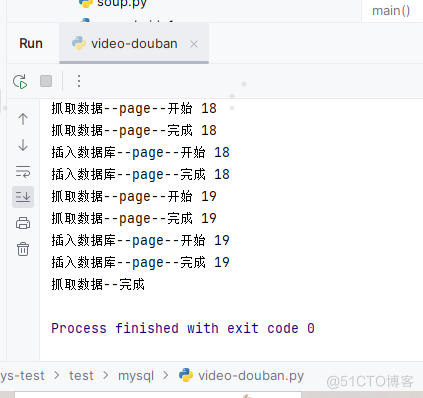
print('抓取数据--page--开始', page)
data = parse_page(response)
print('抓取数据--page--完成',page)
print('插入数据库--page--开始', page)
write_to_db(conn, data)
print('插入数据库--page--完成', page)
finally:
conn.close()
print('抓取数据--完成')
if __name__ == '__main__':
main()3:效果
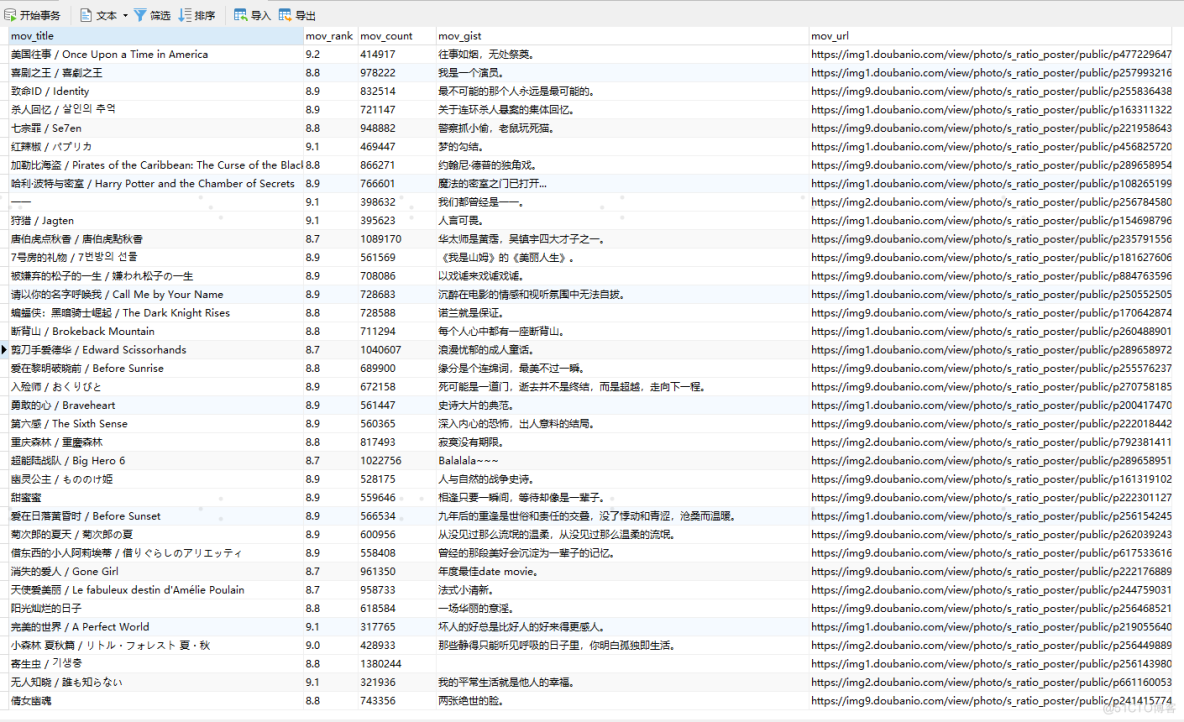
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 都说DevOps落地难,到底难在哪里?也许你还没找到套路
当你打开这篇文章的时候,也许你也在为DevOps的落地而苦恼,也许你的组织正在尝试DevOps转型,作为一线的实践者,说说我对这个“落地难”的看法,欢迎交流不同看法~ DevOps是实践摸索出来的,别人的终究是别人的 如下图所示,你可能在不同企业研发效能的分享…
