
目录
这是我的gitee仓库:https://gitee.com/qin-laoda/python-exercises
有兴趣的小可爱们可以点进去看看,
_________________________________
下面我们来按照爬虫思路找一下我们要爬的网页,并获取数据
下面我以https://ggzyfw.fujian.gov.cn/business/list/来爬取想要的数据
首先我们进去找到该网页,打开开发者工具找到如下所示:

图中我们没有搜索到想要的内容,那我们就查看源代码看看,如图:

可以看出也没有找到我们想要的数据,那就有可能是被加密了,下面我们就找到对应的接口其看看
如下图:
 当我们随机点击一个看看就会发现,返回的是一堆看不懂的数据,其实这就是js加密后返回来的数据,下面我们就来进入正题
当我们随机点击一个看看就会发现,返回的是一堆看不懂的数据,其实这就是js加密后返回来的数据,下面我们就来进入正题
js是什么
-
JavaScript 是世界上最流行的语言之一,是一种运行在客户端的脚本语言 (Script 是脚本的意思)
-
脚本语言:不需要编译,运行过程中由 js 解释器( js 引擎)逐行来进行解释并执行
-
现在也可以基于 Node.js 技术进行服务器端编程
___________________________
下面我来说一些思路:
python代码跑爬虫,js代码去做参数加密
例如:
from:en
to:zh
query:hello
transtype:realtime
simple_means_flag:3
sign:54706.276099
token:12cb0bfe4bc476dc010333cfb8148927
domain:common
ts:1686129751591
sign是通过js加密的! ! ! !,要去找到网站的sign加密的位置,然后把这段js代码扣下来,放到js文件里面执行,执行的结果要和网页的一样 ,比如网页的sign:54706.276099,我们执行的结果也要是这样的
总结一小下:就是通过python代码运行js文件,js文件返回结果给python,然后python再利用
来发送请求
js文件的查找和扣代码
下面我来讲解怎么找到页面的js文件
以百度翻译为例https://fanyi.baidu.com/translate?aldtype=16047&query=hello%0D%0A%0D%0A&keyfrom=baidu&smartresult=dict&lang=auto2zh#en/zh/hello
第一步:
第二步:

第三步:

第四步:

第五步(找到含有对应内容的就是文件,然后打一个标记,再继续找直到找完全部):
 第六步让js代码运行到断点那里就慢慢那调试
第六步让js代码运行到断点那里就慢慢那调试
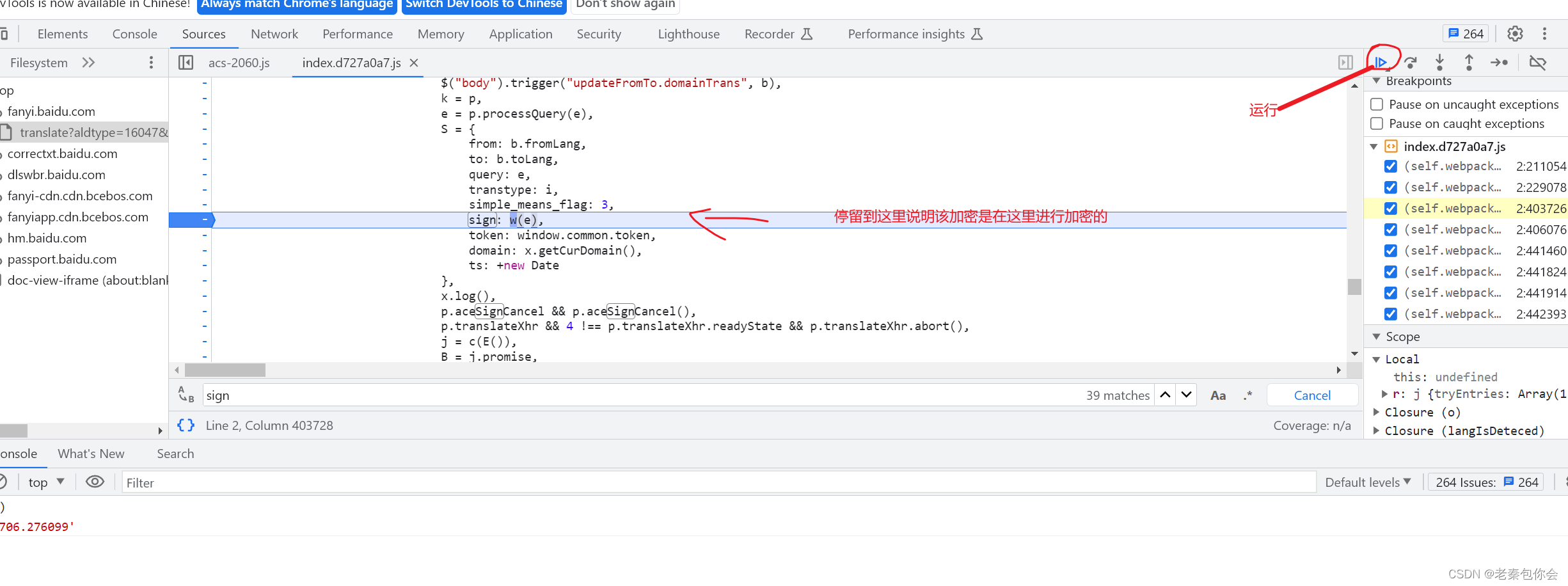
第七步:
我们要好好分析一下

第八步点击进去会有一下的提示

第九步:
第十步:找到对应的js代码:
function n(t, e) {
for (var n = 0; n >> r : t 30 && (t = "".concat(t.substr(0, 10)).concat(t.substr(Math.floor(a / 2) - 5, 10)).concat(t.substr(-10, 10)))
} else {
for (var s = t.split(/[uD800-uDBFF][uDC00-uDFFF]/), c = 0, l = s.length, u = []; c 30 && (t = u.slice(0, 10).join("") + u.slice(Math.floor(p / 2) - 5, Math.floor(p / 2) + 5).join("") + u.slice(-10).join(""))
}
r='320305.131321201'
for (var d = "".concat(String.fromCharCode(103)).concat(String.fromCharCode(116)).concat(String.fromCharCode(107)), h = (null !== r ? r : (r = window[d] || "") || "").split("."), f = Number(h[0]) || 0, m = Number(h[1]) || 0, g = [], y = 0, v = 0; v > 6 | 192 : (55296 == (64512 & _) && v + 1 > 18 | 240,
g[y++] = _ >> 12 & 63 | 128) : g[y++] = _ >> 12 | 224,
g[y++] = _ >> 6 & 63 | 128),
g[y++] = 63 & _ | 128)
}
for (var b = f, w = "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(97)) + "".concat(String.fromCharCode(94)).concat(String.fromCharCode(43)).concat(String.fromCharCode(54)), k = "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(51)) + "".concat(String.fromCharCode(94)).concat(String.fromCharCode(43)).concat(String.fromCharCode(98)) + "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(102)), x = 0; x 结果:

这里我们不要高兴得太早,因为我们只完成了js,还有python代码没完成
利用python代码执行js
安装python模块PyExecjs
pip install PyExecJSjs文件:
function n(t, e) {
for (var n = 0; n >> r : t 30 && (t = "".concat(t.substr(0, 10)).concat(t.substr(Math.floor(a / 2) - 5, 10)).concat(t.substr(-10, 10)))
} else {
for (var s = t.split(/[uD800-uDBFF][uDC00-uDFFF]/), c = 0, l = s.length, u = []; c 30 && (t = u.slice(0, 10).join("") + u.slice(Math.floor(p / 2) - 5, Math.floor(p / 2) + 5).join("") + u.slice(-10).join(""))
}
r='320305.131321201'
for (var d = "".concat(String.fromCharCode(103)).concat(String.fromCharCode(116)).concat(String.fromCharCode(107)), h = (null !== r ? r : (r = window[d] || "") || "").split("."), f = Number(h[0]) || 0, m = Number(h[1]) || 0, g = [], y = 0, v = 0; v > 6 | 192 : (55296 == (64512 & _) && v + 1 > 18 | 240,
g[y++] = _ >> 12 & 63 | 128) : g[y++] = _ >> 12 | 224,
g[y++] = _ >> 6 & 63 | 128),
g[y++] = 63 & _ | 128)
}
for (var b = f, w = "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(97)) + "".concat(String.fromCharCode(94)).concat(String.fromCharCode(43)).concat(String.fromCharCode(54)), k = "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(51)) + "".concat(String.fromCharCode(94)).concat(String.fromCharCode(43)).concat(String.fromCharCode(98)) + "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(102)), x = 0; x py文件:
ef get_js_function(js_path,js_function,js_args=None):
with open(js_path,"r",encoding="utf-8")as f:
js=f.read()
#编译js文件
ret=execjs.compile(js)
#执行js中的函数
dem=ret.call(js_function,js_args)
print(dem)
return dem
# get_js_function("./demo.js","arr","你好")
execjs.compile(js)可以理解为创建一个对象
call(js的函数名,传入js函数的参数)
下面我再来一个例子:
https://ggzyfw.fujian.gov.cn/business/list/
由于前面我已经讲过了,小可爱可以套用,我们直接来到js加密


可以看出来这里加密的不是sign,而是response返回的数据进行了加密,
如果细心的小可爱也发现了,


这两个不一样,会造成我们访问失败,所以我们在遇见有Data的时候,post 请求就用data来接收,遇见Request就用json接收例如:requests.post(url,headers=header,json=data)
下面我写了一些代码爬取加密文件的:

请求头加密了
返回结果加密了
思路:加密发送请求头,解密获取数据
python文件:
import requests
import execjs
import time
from jsonpath import jsonpath
def main():
"""主要的业务逻辑"""
# url
url="https://ggzyfw.fujian.gov.cn/FwPortalApi/Trade/TradeInfo"
data={
'AREACODE':"",
'BeginTime':"2022-12-07 00:00:00",
'EndTime':"2023-06-07 23:59:59",
'GGTYPE':"1",
'KIND':"GCJS",
'M_PROJECT_TYPE':"",
'PROTYPE':"",
'createTime':[],
'pageNo':3,
'pageSize':20,
'timeType':"6",
'total':3537,
'ts':int(time.time()*1000)
}
def js_parth(js_path, js_function, js_args=None):
with open(js_path, "r", encoding="utf-8")as f:
js = f.read()
# 编译js文件
js_pa = execjs.compile(js,cwd=r"C:Users32288WebstormProjectsuntitlednode_modulescrypto-js")
# 运行js的函数
resuit = js_pa.call(js_function, js_args)
return resuit
ps = js_parth("./02.js", "d", data)
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Host": "ggzyfw.fujian.gov.cn",
"Origin": "https://ggzyfw.fujian.gov.cn",
"Referer": "https://ggzyfw.fujian.gov.cn/business/list/",
"Portal-Sign":ps,
"Content-Type": "application/json;charset=UTF-8",
"Accept": "application/json, text/plain, */*"
}
response=requests.post(url,headers=header,json=data)
# print(response.json())
# 创建一个json对象
path=jsonpath(response.json(),"$..Data")[0]
print(path)
data_html=js_parth("./jiemi.js","b",path)
print(data_html)
# 发送请求获取响应
# 数据的提取
# 保存
if __name__ == '__main__':
main()js文件(加密版):
//导入
const CrypyoJS=require("crypto-js");
// import CryptoJS from "crypto-js";
data={
'AREACODE':"",
'BeginTime':"2022-12-07 00:00:00",
'EndTime':"2023-06-07 23:59:59",
'GGTYPE':"1",
'KIND':"GCJS",
'M_PROJECT_TYPE':"",
'PROTYPE':"",
'createTime':[],
'pageNo':3,
'pageSize':20,
'timeType':"6",
'total':3537,
'ts':new Date().getTime()//时间戳
}
//57e776a8c23455410734cca06cd62a38
//0f3aa7843dfec2c0ac67e2c66d1d6418
//4ff85b173651722cc354ce032b2de64d
// 7ca9c7f6af67a6c3585984c61c49b0a1
function u(t, e) {
return t.toString().toUpperCase() > e.toString().toUpperCase() ? 1 : t.toString().toUpperCase() == e.toString().toUpperCase() ? 0 : -1
}
function l(t) {
for (var e = Object.keys(t).sort(u), n = "", a = 0; a js解密版:
const CryptoJS=require("crypto-js")
function b(t) {
var e = CryptoJS.enc.Utf8.parse('BE45D593014E4A4EB4449737660876CE')
, n =CryptoJS.enc.Utf8.parse('A8909931867B0425')
, a = CryptoJS.AES.decrypt(t, e, {
iv: n,
mode:CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
return a.toString(CryptoJS.enc.Utf8)
}运行最终结果:

下面我来讲解一下问题所在:
1.当我们发送请求时如果没有响应,一般都会增加发送请求头的数量,在python文件中可以看出加了许多的请求头
2.execjs.complied(js,cwd=js文件中导入的模块的下载的文件路径)
3.要学会打断点
4.要知道页面的js文件有AES等字眼的一般都是加密算法,需要我们寻找对应的加密和解密
5.js的导入为:const CrypyoJS=require(“crypto-js”);
// import CryptoJS from “crypto-js”;
这两个的其中一个
6.js时间戳的写法:
new Date().getTime()
7.还有一个python文件执行的js的老问题就是编码问题
以上就是我的介绍js逆向的内容了,
总结:我们懂得JS逆向的思路,js执行js代码进行加密和解密(这个过程需要我们一步步找问题,解决问题,),利用python代码运行js文件,利用返回的结果进行发送请求或者提取数据进行保存
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 机器学习算法实战(scikit-learn版本)—线性回归文章目标:
目录 文章目标: 1,导入库 2,导入数据集 3,缩放/归一化训练数据 4,创建并拟合回归模型 5,查看参数 6,预测 7,可视化 有一个开源的、商业上可用的机器学习工具包,叫做[scikit-learn](https://scikit-learn.org…
