
编者按:近年来,强化学习在游戏和机器人控制等领域取得了较大的进步。如何设计一种强化学习算法,使机器人或Agent能够在复杂环境中学习最优策略(Optimal Policy)并作出最优的决策,这成为一个重要课题。
我们今天为大家带来的这篇文章,作者指出可以通过设计并训练Q-learning算法来解决强化学习中的服务器托管网决策问题。
作者首先以Frozen Lake游戏为例导入问题。然后详细介绍Q-learning的设计思路,包括构建Q-table、定义value更新公式、设置reward机制、添加epsilon-greedy探索策略等方法。最后作者通过代码示例详细展示了如何从零开始实现Q-learning算法,并取得不错的实验效果。
本文内容详实,示例代码易于理解,对于读者学习和应用强化学习算法具有一定的参考价值。
作者 | Maxime Labonne
编译|岳扬
欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
本文的目标是教会人工智能如何使用强化学习算法解决❄️Frozen Lake游戏环境。我们将从头开始,尝试自己重新创建Q-learning算法。我们不仅要了解它是如何工作的,更重要的是,懂得为什么要这样设计。
我们希望通过本文让读者能够掌握Q-learning算法,并能够将其应用于其他实际问题。这是一个很有趣的迷你项目,能够帮助我们更好地理解强化学习的工作原理,并希望能够激发读者产生更多有创意的产品灵感。
我们首先需要安装Frozen Lake游戏环境,并导入以下必要的库:用于模拟游戏环境的gym、用于生成随机数的random和用于数学运算的numpy。
!pip install-q gym
!pip install-q matplotlib
importgym
importrandom
importnumpyasnp
01 ❄️ Frozen Lake
现在,让我们来谈一谈在本教程中要用算法解决的游戏。Frozen Lake是一个由方块组成的简单游戏环境,AI必须从起始方块移动到目标方块。
- 方块可以代表安全的冰面✅,也可以代表洞❌,一旦掉进洞中就会永远被困住。
- AI或agent可以执行4种动作:向左移动◀️,向下移动,向右移动▶️,或向上移动。
- agent必须学会避开洞,以最少的动作次数到达目标方块。
- 默认情况下, 游戏环境的配置始终保持不变。
在游戏环境的代码中,每个方块都用一个字母表示,如下所示:
S F F F(S:starting point,safe)
F H F H(F:frozen surface,safe)
F F F H(H:hole,stuck forever)
H F F G(G:goal,safe)

我们可以尝试手动解决上述例子,以帮助我们理解这个游戏。看看下面这一系列动作是否是一种正确的解法:向右移动→向右移动→向右移动→向下移动→向下移动→向下移动。agent从方块S开始,所以我们向右移动还是在冰面上✅,然后再次向右移动✅,再次向右移动✅,然后再向下移动就会掉入洞❌中。
其实,要找到几种正确的解法并不难:向右移动→向右移动→向下移动→向下移动→向下移动→向右移动就是一种简单的解法。但是我们也可以制定一连串的动作,绕着某一个洞转10圈,然后再到达目标方块。这个agent的动作路径是有效的,但它不符合游戏的要求:agent需要以最少的操作次数达到目标方块。在这个例子中,完成该局游戏的最少动作次数是6次。我们需要记住这个结论,以便检查agent是否真正掌握了Frozen Lake游戏。
让我们借助gym库来初始化游戏环境。这个游戏有两个版本:一个是冰面湿滑的版本,在这个版本中,游戏指令有一定的概率被agent忽略;另一个是不湿滑的版本,在这个版本中,游戏指令不会被忽略。本文首先使用不湿滑的版本,因为这个版本更容易理解。
environment=gym.make("FrozenLake-v1",is_slippery=False)
environment.reset()
environment.render()
FFF
FHFH
FFFH
HFFG
我们可以看到,所创建的这局游戏环境与前文示例的游戏配置完全一致。agent的位置用一个红色矩形表示。可以使用一个简单的脚本和if…else条件判断来解决这局游戏,这种方法有助于将我们的人工智能与更简单的方法进行对比。然而,我们想尝试一种更有趣的解决方案:强化学习。
02 Q-table
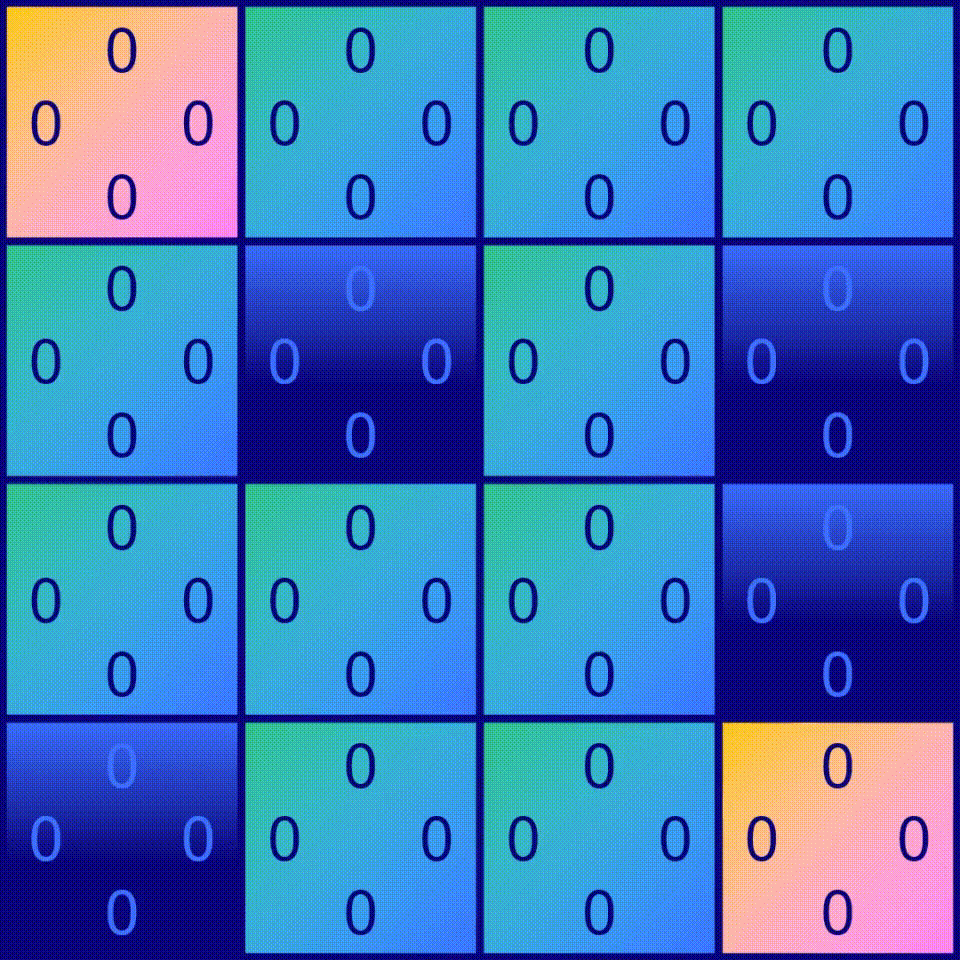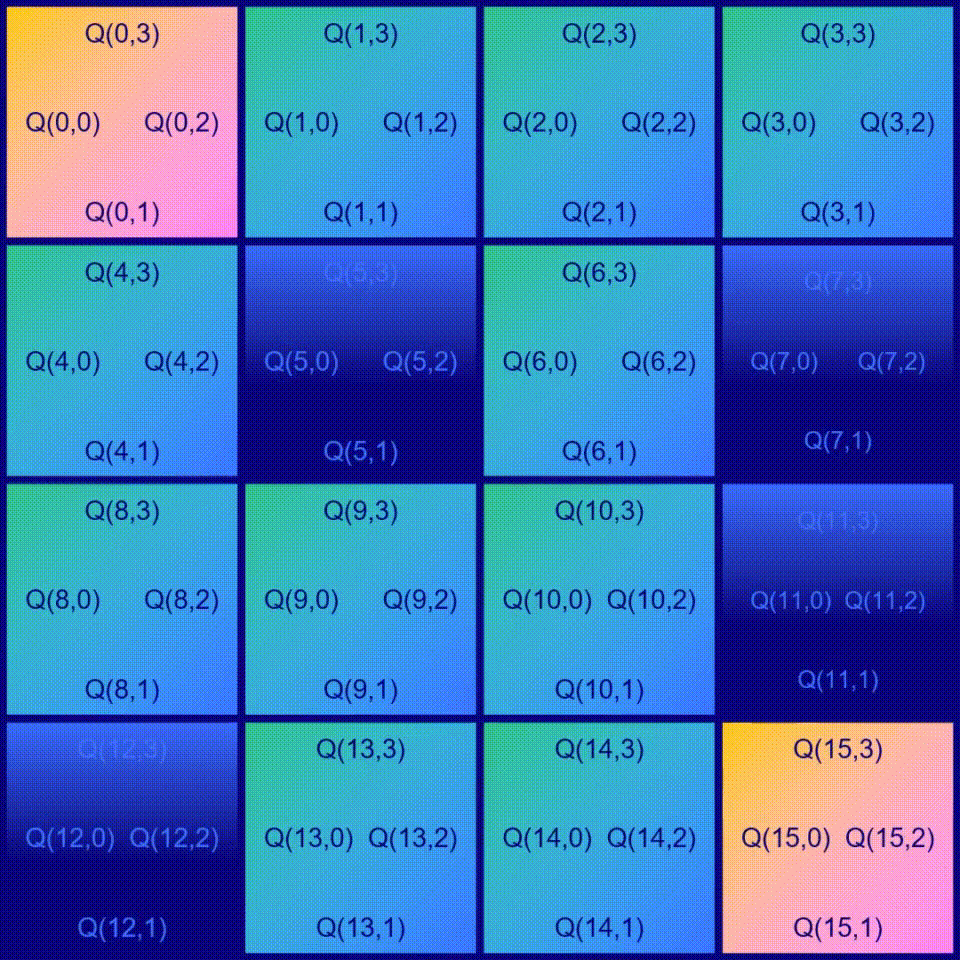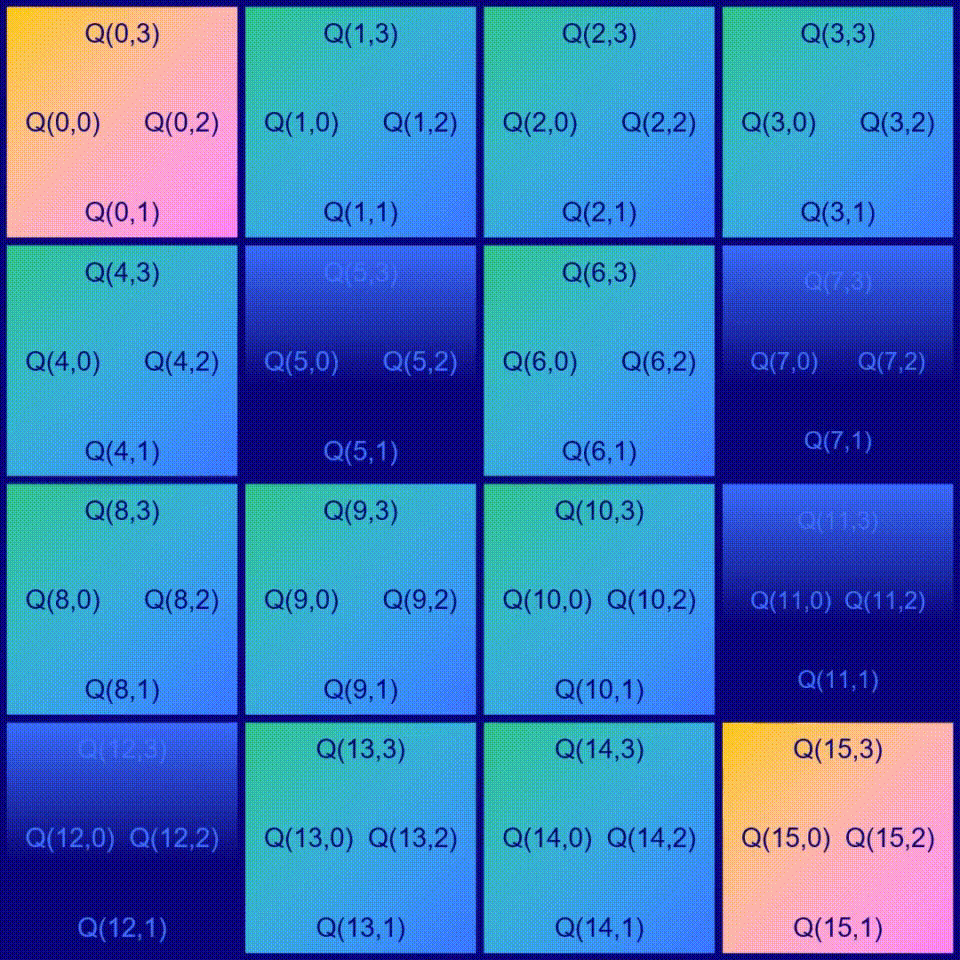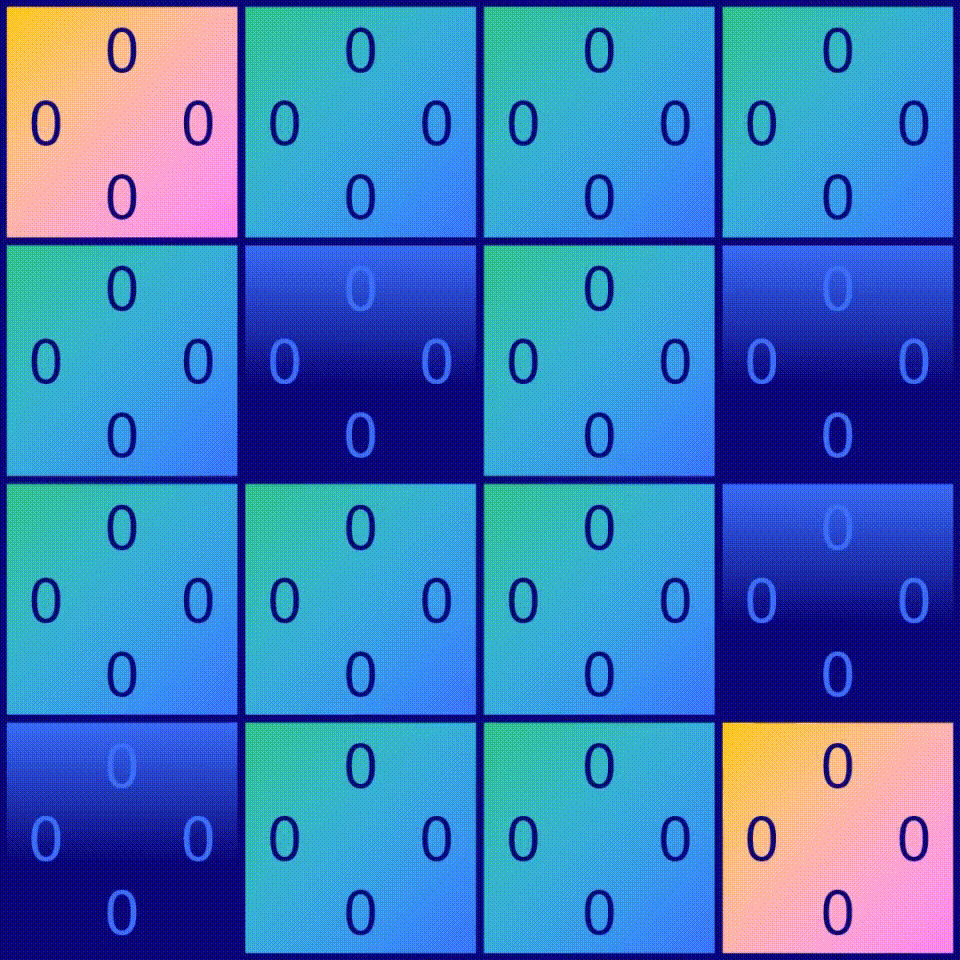
在Frozen Lake游戏中,有16个方块,这意味着agent可以处于16个不同的位置,这些位置也称为状态(states),也就是说有16个可能的状态。对于每个状态,都有4种可能的动作可供选择:向左移动◀️,向下移动,向右移动▶️和向上移动。学习如何玩Frozen Lake游戏就像学习在每个状态下应该选择哪个动作。为了确定在给定状态下哪个动作是最优的,我们需要为动作分配一个质量值。 有16个状态和4种动作,因此需要计算出16 x 4=64个质量值。
一种很好的表示方法是使用一个称为Q-table的表格,其中行表示状态s,列表示动作a。在这个Q-table中,每个单元格都会包含一个值Q(s,a),表示状态s中动作a的质量值(如果是当前状态的最佳动作,质量值则为1,如果是当前状态的最差动作,质量值则为0)。 当agent处于某个特定的状态s时,它只需查看这个表格,看看哪个动作具有最高的质量值。选择具有最高质量值的动作是合理的选择,但是我们稍后会看到,我们可以设计出更好的解决方案…
S◀️LEFTDOWN▶️RIGHTUP
0Q(0,◀️)Q(0,)Q(0,▶️)Q(0,)
1Q(1,◀️)Q(1,)Q(1,▶️)Q(1,)
2Q(2,◀️)Q(2,)Q(2,▶️)Q(2,)
... ... ... ... ...
14Q(14,◀️)Q(14,)Q(14,▶️)Q(14,)
GQ(15,◀️)Q(15,)Q(15,▶️)Q(15,)
Q-table的一个简单示例。其中每个单元格都包含给定状态s(行)下行动a(列)的值Q(a,s)。
先创建一个 Q-table,然后在表中所有单元格都填入0,因为暂时还不知道每个状态下每个操作的值。
#Our table has the following dimensions:
#(rows x columns)=(states x actions)=(16 x 4)
qtable=np.zeros((16, 4))
#Alternatively,the gym library can also directly g
#give us the number of states and actions using
#"env.observation_space.n"and"env.action_space.n"
nb_states=environment.observation_space.n#=16
nb_actions=environment.action_space.n#=4
qtable=np.zeros((nb_states,nb_actions))
#Let's see how it looks
print('Q-table=')
print(qtable)
Q-table=
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
太好了!现在按照预期,我们已经拥有了一个16行(16个状态)和4列(4种动作)的Q-table。接下来我们应该怎么做:Q-table的每个值都为0,因此还没有任何信息可供使用。假设agent随机选择了一种动作:向左移动◀️,向下移动,向右移动▶️或向上移动。
我们可以使用random库的choice方法来随机选择一个动作。
random.choice(["LEFT", "DOWN", "RIGHT", "UP"])
'LEFT'
不过,当前agent处于初始方块S,意味着只有两种动作可行:向右移动▶️和向下移动。agent也可以选择向上移动和向左移动◀️,但实际上agent并不能移动:因为它的状态不会改变。因此,我们不对可选择的动作进行任何限制,agent会自然而然地理解其中一些动作没有实际效果。
我们可以继续使用random.choice(),但gym库已经具备一种随机选择动作的方法。可能可以为我们省去一些麻烦,所以让我们试试吧。
environment.action_space.sample()
0
哎呀……得到的随机动作是数字。我们可以去阅读gym的文档[1],但遗憾的是,文档内容很少。不过不用担心,我们可以在GitHub上查看源代码[2],来了解这些数字的含义。这其实非常简单明了:
◀️LEFT= 0
DOWN= 1
▶️RIGHT= 2
UP= 3
好的,既然现在已经了解 gym如何将数字与方向联系起来,让我们开始尝试用gym将agent向右移动▶️。这次,我们可以使用step(action)方法来实现。可以尝试直接使用与选择的方向(右)相对应的数字2,然后检查agent是否移动。
environment.step(2)
environment.render()
(Right)
SFF
FHFH
FFFH
HFFG
好极了!代码成功运行了。红色方块从初始位置S向右移动了。我们与环境交互所需的全部信息如下:
- 如何使用action_space.sample()随机选择一种动作;
- 如何使用step(action)执行这种动作,并让agent移动到指定的方向。
为了完整了解具体环境情况,我们还可以添加以下内容:
- 如何使用render()方法显示当前地图,来查看当前游戏环境情况;
- 当agent掉入洞或到达目标G时,如何使用reset()方法重新开始游戏。
现在我们了解了如何与gym环境进行交互,开始回到本文要讲述的Q-learning算法。在强化学习中,当agent完成预定的目标时,游戏环境会给agent提供奖励。 在Frozen Lake 游戏中,只有当agent到达状态G时才会获得奖励(请参阅源代码)。我们无法控制这种奖励,它是由环境设定的:当agent到达G时,奖励值为1,没有到达G时,为0。
让我们在每次执行动作时打印出奖励值。奖励内容由step(action)方法给出:
action=environment.action_space.sampl服务器托管网e()
#2.Implement this action and move the agent in the desired direction
new_state,reward,done,info=environment.step(action)
#Display the results(reward and map)
environment.render()
print(f'Reward={reward}')
(Left)
FFF
FHFH
FFFH
HFFG
Reward= 0.0
奖励值确实是0…哇,我想我们陷入困境了,因为整个游戏中只有一个状态能给我们带来正面的奖励。如果我们只有在游戏结束时才能验证,那么我们怎么能在一开始就选择正确的方向呢?如果我们希望奖励值为1,就需要足够幸运,在偶然的机会下找到正确的操作顺序。不幸的是,这正是它的工作原理……在agent随机到达目标G之前,Q-table 中一直都是0。
如果能够在中间过程获得较小的奖励来引导agent朝着目标G的路径前进,问题将变得简单得多。然而,这实际上是强化学习的主要问题之一:这种现象被称为稀疏奖励(sparse rewards),使得agent在只有经过一系列长时间的动作之后才能获得奖励的问题上非常难以训练。 有一些技术可以缓解这个问题,但我们将在以后讨论这些技术。
03 Q-learning
让我们回到要讨论的问题上来。现在我们需要足够幸运才能意外地找到目标G。但一旦找到了,如何将信息反向传播到初始状态呢?Q-learning算法为这个问题提供了一个巧妙的解决方案。需要更新 state-action pairs(Q-table中的每个单元格)的值,更新时要考虑(1)到达下一个状态的奖励值,以及(2)下一个状态的最大可能值。

我们知道,当agent移动到目标方块G时会获得奖励(数值为1)。正如我们刚才所说的,通过奖励,与G相邻状态(我们称其为G-1)的值会增加。好了,剧情结束:agent赢了,重新开始游戏。当下一次agent到达G-1旁边的状态时,它将使用与到达G-1相关的操作,来增加这个状态的值(我们称之为G-2)。agent下一次处于G-2旁边的状态时,也会做同样的事情。如此反复,直到到达初始状态S。
让我们试着找出一个相关的公式,将数值从状态G反向传播到状态S。请记住:该数值表示特定状态下动作的质量(如果是该状态下的最糟糕动作,则数值为0;如果是该状态下的最佳动作,则数值为1)。需要更新状态sₜ(当agent处于初始状态S时,sₜ=0)中动作aₜ(例如,如果动作是向左,则aₜ=0)的值。这个值只是Q-table 中的一个单元格,对应于行号sₜ和列号aₜ的值,即Q(sₜ,aₜ)。
如前所述,我们需要使用(1)下一个状态的奖励值(表示为rₜ)和(2)下一个状态的最大可能值(表示为maxₐQ(sₜ₊₁,a))来更新它。因此,更新公式应如下所示:
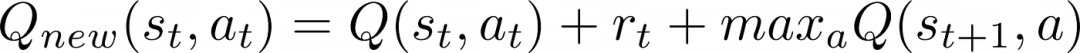
新的值是当前值加上奖励值再加上下一个状态中最高的值。我们可以手动验证该公式是否正确:假设agent第一次处于目标G旁边的状态G-1,我们可以用以下方法更新G-1状态中获胜操作所对应的值:
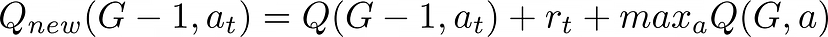
初始时,Q(G-1,aₜ)=0,maxₐQ(G,a)=0,因为Q-table 为空,而rₜ=1,因为在游戏环境中只获得了唯一的奖励,然后得到Q{new}(G-1,aₜ)=1。下一次,当agent处于与此状态(G-2)相邻的状态时,我们也使用该公式进行更新,并得到相同的结果:Q{new}(G-2,aₜ)=1。最后,我们从G向S在Q-table中进行反向传播。这样确实可以工作,但结果是二元的:要么是错误的state-action pair,要么是最佳的state-action pair。 我们希望能有更多的细微差别……
实际上,我们已经接近找到真正的 Q-learning算法更新公式,但我们还需要添加两个参数:
- 是学习率(介于0和1之间),表示原始的Q(sₜ,aₜ)值的变化程度。 如果=0,值永远不会改变,但如果=1,值会变化得非常快。在上文的示例中,学习率没有被限制,因此=1。但在实际情况中,这样太快了:奖励值和下一个状态中的最大值很快就会超过当前值。我们需要找到一个平衡点。
- 是折扣因子(介于0和1之间),它决定了agent对未来奖励与当前奖励的关心程度(俗话说,“一鸟在手胜过双鸟在林”)。 如果=0,agent只关注即时奖励,但如果=1,任何潜在的未来奖励与及时奖励具有相同的价值。在❄️Frozen Lake中,由于游戏仅在结尾才会产生奖励,我们需要使用较高的折扣因子。
在真正的Q-learning算法中,新值的计算公式如下:
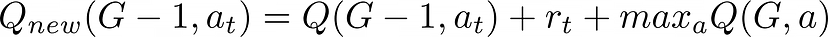
好呀,让我们先试试这个新公式,然后再来使用它。再次假设 agent第一次处于目标G旁边的状态。可以使用该公式更新state-action pair,以便在游戏中取得胜利:Q{new}(G-1,aₜ)=0+-(1+-0-0)。我们可以任意赋值给和来计算结果。当=0.5和=0.9时,将得到Q{new}(G-1,aₜ)=0+0.5-(1+0.9-0-0)=0.5。agent第二次处于这种状态时,会得到Q{new}(G-1,aₜ)=0.5+0.5-(1+0.9-0-0.5)=0.75,然后是0.875、0.9375、0.96875等等。

使用代码训练agent意味着:
- 如果当前状态所有动作的数值都为零,则随机选择一个动作(使用action_space.sample())。否则,使用np.argmax()函数选择当前状态中数值最高的动作。
- 使用step(action)函数执行所选择的动作,即朝着期望的方向移动。
- 使用新状态的信息和step(action)给出的奖励值,用所选择的动作更新原始状态的数值。
- 不断重复这三个步骤,直到agent坠入冰窟中或到达目标方块G。 当发生这种情况后,使用reset()函数重置游戏环境,并开始一个新的游戏回合,直到达到1,000个游戏回合。此外,我们可以绘制每次agent运行的游戏结果(如果未达到目标则为失败,否则为成功),以观察进展。
importmatplotlib.pyplotasplt
plt.rcParams['figure.dpi'] = 300
plt.rcParams.update({'font.size': 17})
#We re-initialize the Q-table
qtable=np.zeros((environment.observation_space.n,environment.action_space.n))
#Hyperparameters
episodes= 1000 #Total number of episodes
alpha= 0.5 #Learning rate
gamma= 0.9 #Discount factor
#List of outcomes to plot
outcomes= []
print('Q-table before training:')
print(qtable)
#Training
for_in range(episodes):
state=environment.reset()
done= False
#By default,we consider our outcome to be a failure
outcomes.append("Failure")
#Until the agent gets stuck in a hole or reaches the goal,keep training it
while notdone:
#Choose the action with the highest value in the current state
ifnp.max(qtable[state]) > 0:
action=np.argmax(qtable[state])
#If there's no best action(only zeros),take a random one
else:
action=environment.action_space.sample()
#Implement this action and move the agent in the desired direction
new_state,reward,done,info=environment.step(action)
#Update Q(s,a)
qtable[state,action] =qtable[state,action] +
alpha* (reward+gamma*np.max(qtable[new_state]) -qtable[state,action])
#Update our current state
state=new_state
#If we have a reward,it means that our outcome is a success
ifreward:
outcomes[-1] = "Success"
print()
print('===========================================')
print('Q-table after training:')
print(qtable)
#Plot outcomes
plt.figure(figsize=(12, 5))
plt.xlabel("Run number")
plt.ylabel("Outcome")
ax=plt.gca()
ax.set_facecolor('#efeeea')
plt.bar(range(len(outcomes)),outcomes,color="#0A047A",width=1.0)
plt.show()
Q-table before training:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
===========================================
Q-table after training:
[[0. 0. 0.59049 0. ]
[0. 0. 0.6561 0. ]
[0. 0.729 0. 0. ]
[0. 0. 0. 0. ]
[0. 0.02050313 0. 0. ]
[0. 0. 0. 0. ]
[0. 0.81 0. 0. ]
[0. 0. 0. 0. ]
[0. 0. 0.17085938 0. ]
[0. 0. 0.49359375 0. ]
[0. 0.9 0. 0. ]
[0. 0. 0. 0. ]
[0. 0. 0. 0. ]
[0. 0. 0. 0. ]
[0. 0. 1. 0. ]
[0. 0. 0. 0. ]]
这个agent已经训练好了!图中的每条蓝色条纹都代表agent在一局游戏中获胜,因此我们可以看到在训练刚开始时,agent很难到达目标方块,但是当agent连续几次到达目标方块后,就能够稳定地取得游戏胜利了。经过训练后的Q-table也非常有用:这些值表示agent学习到的到达目标方块的最佳动作序列。
现在,通过让agent完成100回合游戏来评估其表现。目前可以认为agent的训练已经结束,所以不需要再更新Q-table了。为了了解agent在❄️Frozen Lake游戏环境中的表现,可以计算它成功到达目标方块的次数百分比(成功率)。
episodes= 100
nb_success= 0
#Evaluation
for_in range(100):
state=environment.reset()
done= False
#Until the agent gets stuck or reaches the goal,keep training it
while notdone:
#Choose the action with the highest value in the current state
ifnp.max(qtable[state]) > 0:
action=np.argmax(qtable[state])
#If there's no best action(only zeros),take a random one
else:
action=environment.action_space.sample()
#Implement this action and move the agent in the desired direction
new_state,reward,done,info=environment.step(action)
#Update our current state
state=new_state
#When we get a reward,it means we solved the game
nb_success+=reward
#Let's check our success rate!
print (f"Success rate={nb_success/episodes*100}%")
Success rate=100.0%
这个agent不仅已经训练好了,而且它的成功率达到了100%。干得漂亮!不湿滑版本的Frozen Lake游戏已经被我们解决了!
通过执行下面的代码,我们可以看到agent在地图上移动,并打印它所采取的动作序列,以检查是否是最佳动作序列。
fromIPython.displayimportclear_output
importtime
state=environment.reset()
done= False
sequence= []
while notdone:
#Choose the action with the highest value in the current state
ifnp.max(qtable[state]) > 0:
action=np.argmax(qtable[state])
#If there's no best action(only zeros),take a random one
else:
action=environment.action_space.sample()
#Add the action to the sequence
sequence.append(action)
#Implement this action and move the agent in the desired direction
new_state,reward,done,info=environment.step(action)
#Update our current state
state=new_state
#Update the render
clear_output(wait=True)
environment.render()
time.sleep(1)
print(f"Sequence={sequence}")
(Right)
SFFF
FHFH
FFFH
HFF
Sequence= [2, 2, 1, 1, 1, 2]
agent可以学习到多种正确的动作序列,例如[2,2,1,1,1,2]、[1,1,2,2,1,2]等等。从上面的输出结果可以看出,agent学习到的动作序列中只有6个动作,就是我们在文章开头计算出的最短动作序列长度:这意味着agent学会了以最优的方式解决❄️Frozen Lake游戏。输出结果[2,2,1,1,1,2]对应的动作序列是RIGHT→RIGHT→DOWN→DOWN→DOWN→RIGHT,正是我们在文章一开始预测的序列。
04 -贪心算法
在上文使用的方法中,agent总是选择具有最高数值的动作。因此,一旦state-action pair开始具有非零值,agent就会始终选择这个动作。其他动作将永远不会被选择,也不会更新这些动作的值…但是,如果其中一种动作比agent经常选择的动作更优呢?难道我们不应该鼓励agent不时尝试新的方法,看看是否能有所改进吗?
换句话说,我们希望允许agent进行以下这些操作之一:
- 选择具有最高值的动作(利用已经学到的知识来做出最优的决策);
- 选择一种随机动作,尝试找到更好的动作(探索是否有更优的动作)。
这两种操作之间的权衡非常重要:如果agent只专注于第一种操作,它就无法尝试新的解决方案,从而无法再学习。另一方面,如果agent只能够采取随机动作,那么它的训练就会毫无意义,因为没有使用Q-table。因此,我们希望随着时间的推移改变这个参数:在训练开始时,希望尽可能多地探索游戏环境。但是随着agent已经了解了每种可能的state-action pairs,探索就会变得越来越无趣。这个参数表示agent在动作选择时的随机程度。
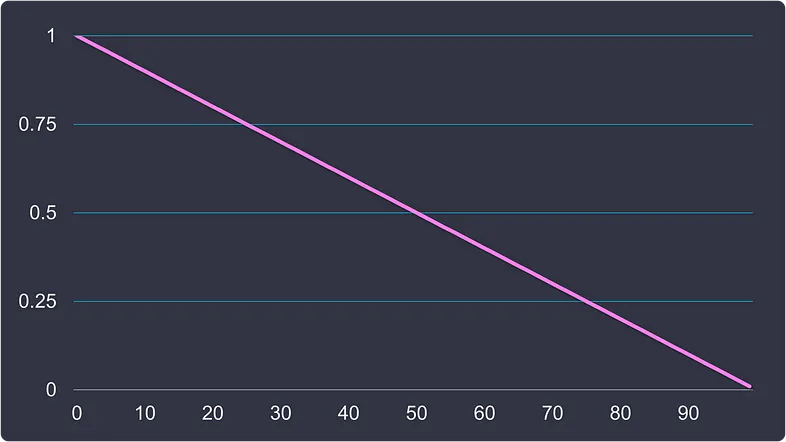
这种技术通常被称为-贪心算法,其中是一种参数。这是一种简单但极其有效的方法,可以找到帮助我们设定一个折中的方案。每当agent需要选择一个动作来进入下一个方块时,它就有概率选择一种随机的动作,有1-的概率选择具有最高数值的动作。 我们可以通过固定的数值(即线性衰减)或基于当前的值(即指数衰减)来在每次游戏结束时减小的值。
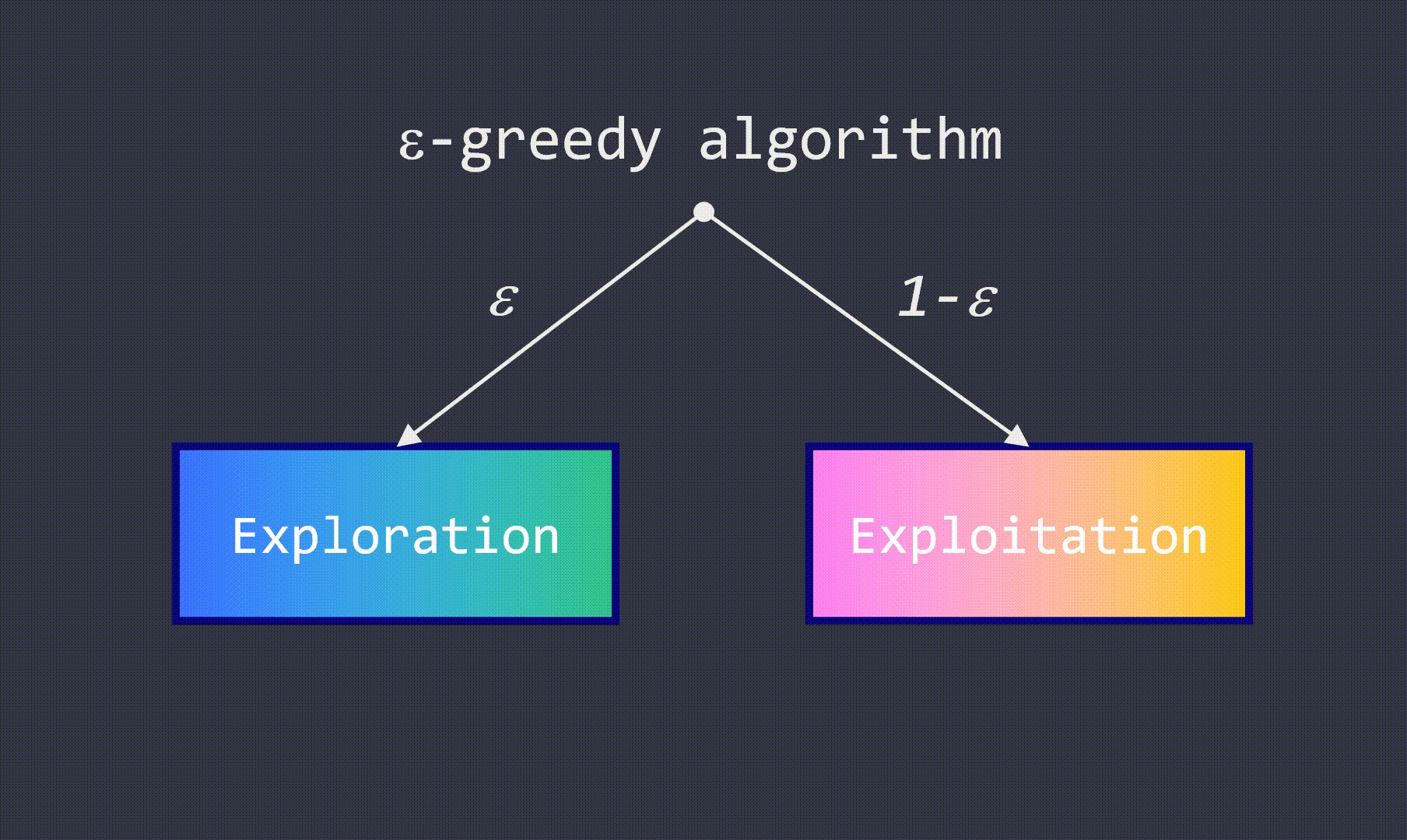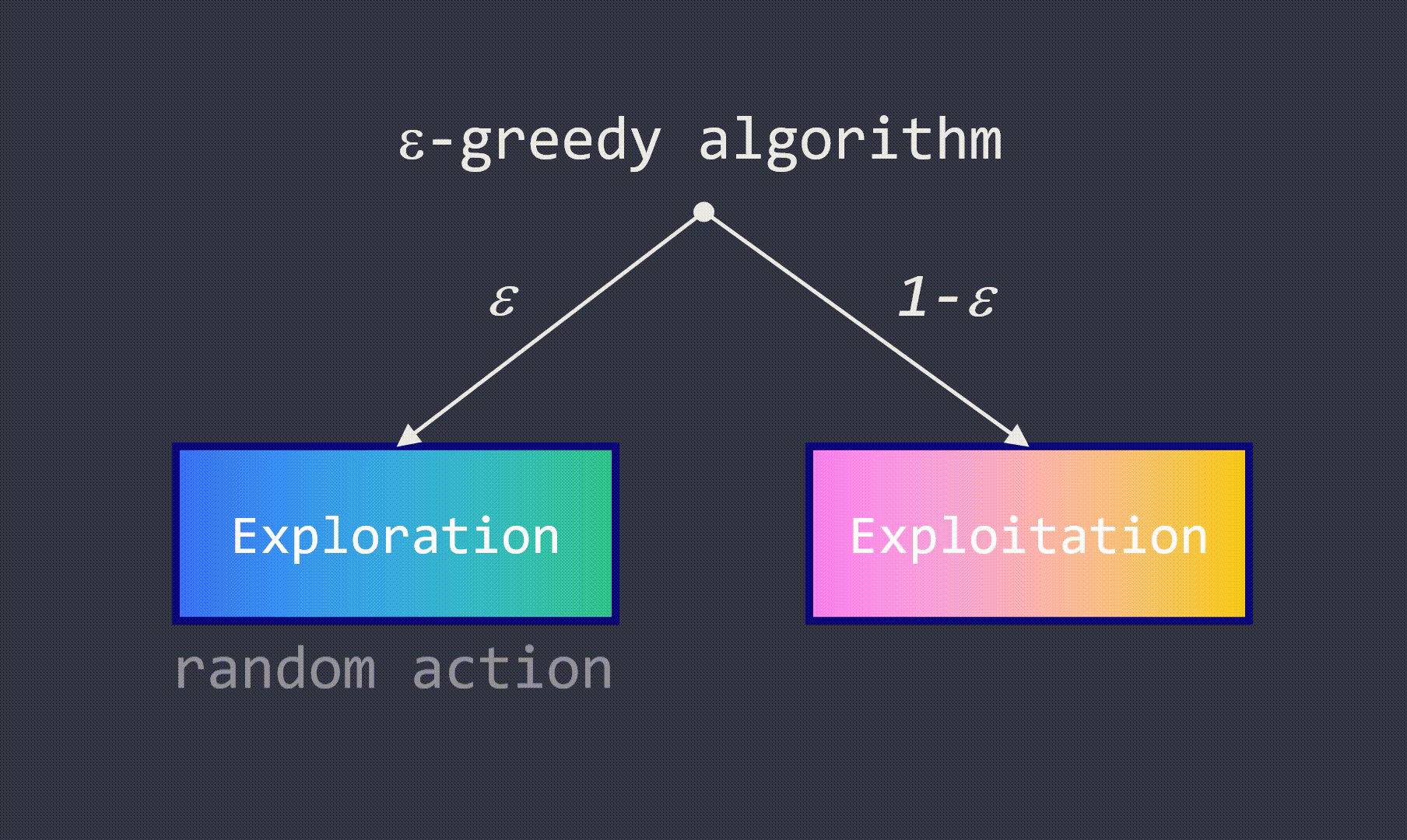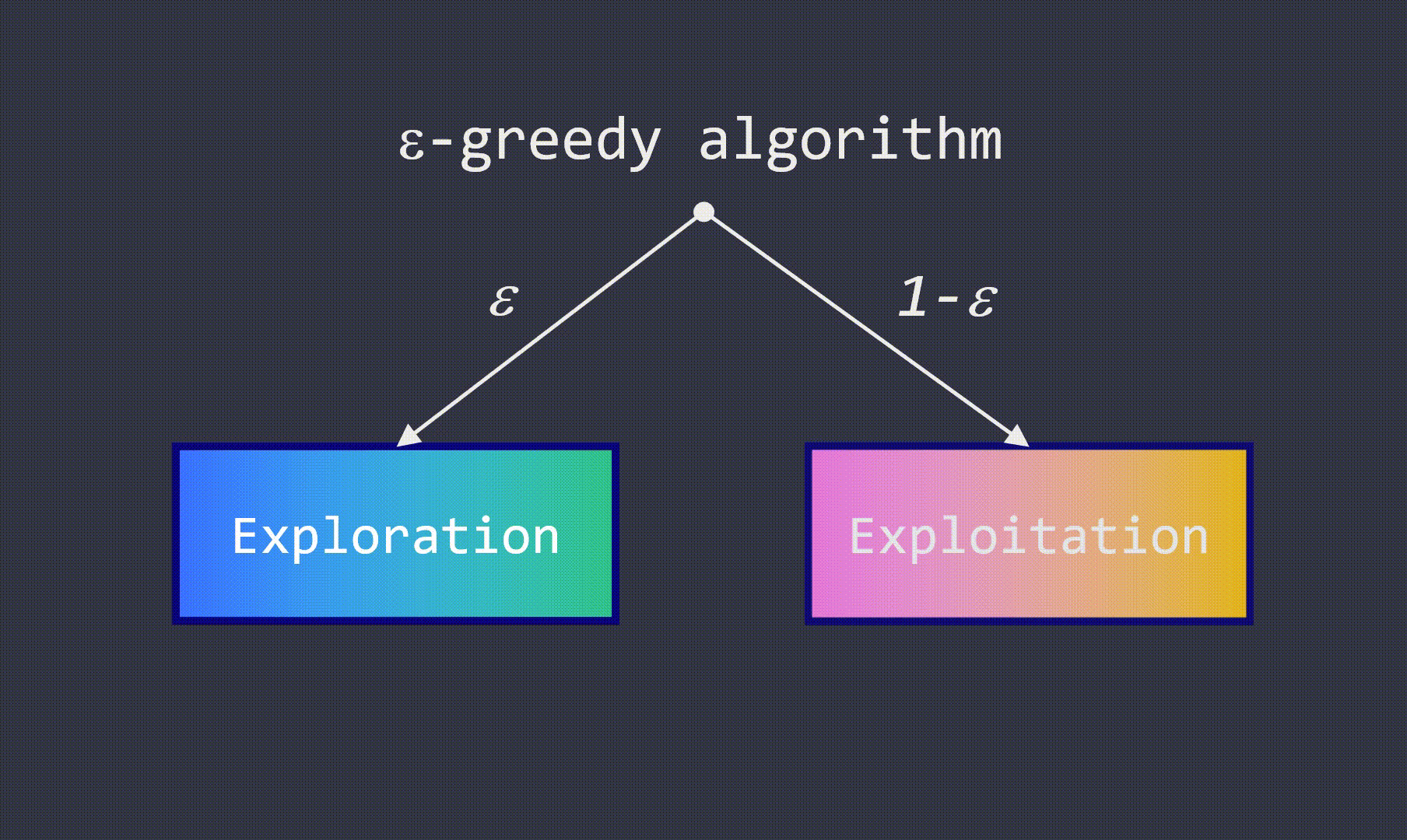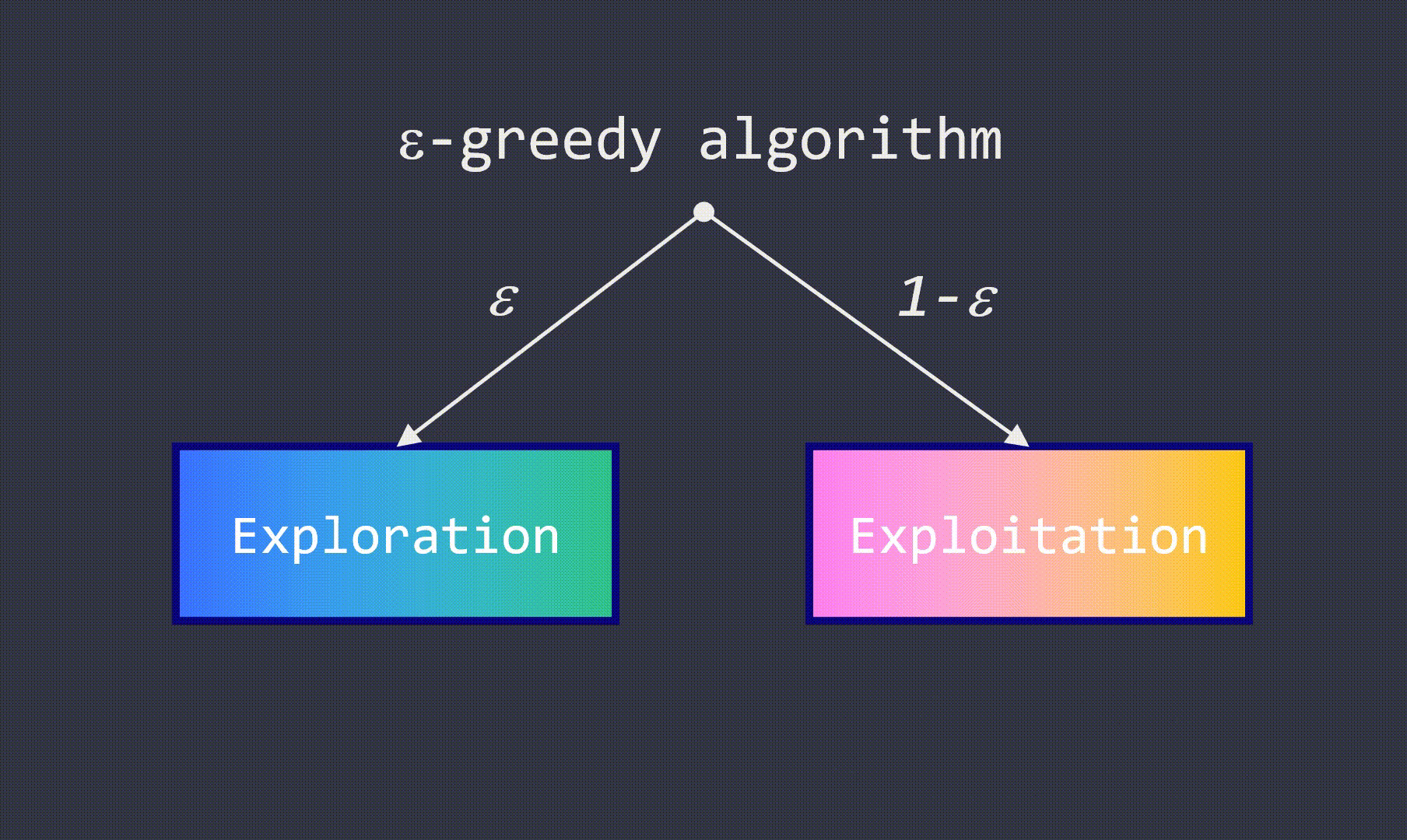
先选择线性衰减的方案。在此之前,让我们来看看任意参数下的曲线是什么样子的。从=1开始,进入完全探索模式,并在每个游戏回合后将该值减少0.001。
现在我们对该方案有了一个较为清晰的理解,可以开始真正实施该方案,并观察它如何改变agent的行为。
qtable=np.zeros((environment.observation_space.n,environment.action_space.n))
#Hyperparameters
episodes= 1000 #Total number of episodes
alpha= 0.5 #Learning rate
gamma= 0.9 #Discount factor
epsilon= 1.0 #Amount of randomness in the action selection
epsilon_decay= 0.001 #Fixed amount to decrease
#List of outcomes to plot
outcomes= []
print('Q-table before training:')
print(qtable)
#Training
for_in range(episodes):
state=environment.reset()
done= False
#By default,we consider our outcome to be a failure
outcomes.append("Failure")
#Until the agent gets stuck in a hole or reaches the goal,keep training it
while notdone:
#Generate a random number between 0 and 1
rnd=np.random.random()
#If random numberQ-table before training:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
===========================================
Q-table after training:
[[0.531441 0.59049 0.59049 0.531441 ]
[0.531441 0. 0.6561 0.56396466]
[0.58333574 0.729 0.56935151 0.65055117]
[0.65308668 0. 0.33420534 0.25491326]
[0.59049 0.6561 0. 0.531441 ]
[0. 0. 0. 0. ]
[0. 0.81 0. 0.65519631]
[0. 0. 0. 0. ]
[0.6561 0. 0.729 0.59049 ]
[0.6561 0.81 0.81 0. ]
[0.72899868 0.9 0. 0.72711067]
[0. 0. 0. 0. ]
[0. 0. 0. 0. ]
[0. 0.81 0.9 0.729 ]
[0.81 0.9 1. 0.81 ]
[0. 0. 0. 0. ]]

现在,agent需要花费更多时间训练才能持续赢得游戏!而且,Q-table中的非零值也比之前多得多,这说明agent已经学会了多种行动序列来到达目标方块。这也是可以理解的,因为这个新agent不得不探索新的state-action pairs,而非一味地使用非零值对应的行为。
让我们看看它是否能像前一个agent一样成功地到达目标方块。在评估模式下,我们不再需要agent进入探索模式,因为agent已经经过训练了。
episodes= 100
nb_success= 0
#Evaluation
for_in range(100):
state=environment.reset()
done= False
#Until the agent gets stuck or reaches the goal,keep training it
while notdone:
#Choose the action with the highest value in the current state
action=np.argmax(qtable[state])
#Implement this action and move the agent in the desired direction
new_state,reward,done,info=environment.step(action)
#Update our current state
state=new_state
#When we get a reward,it means we solved the game
nb_success+=reward
#Let's check our success rate!
print (f"Success rate={nb_success/episodes*100}%")
Success rate=100.0%
哇,又是100%的成功率!并没有降低模型的性能。这种方法在这个例子中的好处可能不太明显,但我们的模型不再是一成不变的,而是更加灵活。它学会了从S方块到G方块的不同路径(动作序列),而不是像之前的方法,只学习到一条路径。 agent进行更多的探索可能会降低性能,但对于训练能够适应新环境的agent来说这是必要的。
05 ❄️ 挑战:地面湿滑版本的Frozen Lake
我们并没有解决整个Frozen Lake游戏环境的问题:只是在地面非湿滑版本的游戏环境中训练了一个agent,在初始化时参数设置为is_slippery=False。在地面湿滑版本的游戏环境中,agent选择的动作只有33%的成功几率。如果失败,将随机选择其它三种动作中的一种。这个特性增加了训练的随机性,对于agent来说,学习解决这个问题更加困难。看看之前的代码在这个新的游戏环境中的表现如何…
environment=gym.make("FrozenLake-v1",is_slippery=True)
environment.reset()
#We re-initialize the Q-table
qtable=np.zeros((environment.observation_space.n,environment.action_space.n))
#Hyperparameters
episodes= 1000 #Total number of episodes
alpha= 0.5 #Learning rate
gamma= 0.9 #Discount factor
epsilon= 1.0 #Amount of randomness in the action selection
epsilon_decay= 0.001 #Fixed amount to decrease
#List of outcomes to plot
outcomes= []
print('Q-table before training:')
print(qtable)
#Training
for_in range(episodes):
state=environment.reset()
done= False
#By default,we consider our outcome to be a failure
outcomes.append("Failure")
#Until the agent gets stuck in a hole or reaches the goal,keep training it
while notdone:
#Generate a random number between 0 and 1
rnd=np.random.random()
#If random numberQ-table before training:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
===========================================
Q-table after training:
[[0.06208723 0.02559574 0.02022059 0.01985828]
[0.01397208 0.01425862 0.01305446 0.03333396]
[0.01318348 0.01294602 0.01356014 0.01461235]
[0.01117016 0.00752795 0.00870601 0.01278227]
[0.08696239 0.01894036 0.01542694 0.02307306]
[0. 0. 0. 0. ]
[0.09027682 0.00490451 0.00793372 0.00448314]
[0. 0. 0. 0. ]
[0.03488138 0.03987256 0.05172554 0.10780482]
[0.12444437 0.12321815 0.06462294 0.07084008]
[0.13216145 0.09460133 0.09949734 0.08022573]
[0. 0. 0. 0. ]
[0. 0. 0. 0. ]
[0.1606242 0.18174032 0.16636549 0.11444442]
[0.4216631 0.42345944 0.40825367 0.74082329]
[0. 0. 0. 0. ]]

Success rate=17.0%
呀!这种方法不太好。但是,你能通过调整前文讨论过的不同参数来改善模型性能吗?我鼓励你接受这个小挑战,自己尝试亲自实践强化学习,验证一下自己对本文的理解。 为什么不对-贪婪算法也进行指数衰减呢?在本文介绍这个小案例的过程中,你可能会意识到稍微修改超参数就会完全改变运行结果。 这是强化学习的另一个“怪处”:它的超参数非常敏感,如果你想调整它们,理解它们的含义是很重要的。尝试、测试新的技术组合总是有好处的,可以帮助我们建立算法直觉,提高效率。祝你好运,玩得愉快!
06 Conclusion
Q-learning是一种简单而强大的算法,是强化学习的核心。在本文中:
- 我们可以学习如何与gym环境进行交互、选择动作和移动agent;
- 本文介绍了Q-table的概念,其中行代表状态,列代表动作,每个单元格代表给定状态下动作的数值;
- 为了解决稀疏奖励问题,本文通过实验重新定义了Q-learning算法的更新公式;
- 本文实现了完整的模型训练和评估过程,并以100%的成功率解决了Frozen Lake游戏环境;
- 实现了著名的-贪婪算法,以在(1)探索未知的state-action pairs和(2)利用最成功的state-action pairs两种方案之间进行权衡。
Frozen Lake是一个非常简单的游戏环境,但其他环境的状态和行为可能非常多,以至于无法在内存中存下Q-table。尤其是在事件不是离散而是连续的环境中(如《超级马里奥兄弟》或Minecraft) ,情况更加复杂。当面临这些挑战时,常用的解决方案是训练深度神经网络来模拟Q-table。 这种方法会增加一些复杂度,因为神经网络不是太稳定。
欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
END
参考资料
[1]https://gym.openai.com/docs/
[2]https://github.com/openai/gym/blob/master/gym/envs/toy_text/frozen_lake.py#L10
原文链接:
https://towardsdatascience.com/q-learning-for-beginners-2837b777741
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
